一、现代硬件中的并发性
1、什么是并发?
function foo() { ... }
function bar() { ... }
function main() {
t1 = startThread(foo)
t2 = startThread(bar)
// 在继续执行 main() 之前等待 t1 和 t2 完成
waitUntilFinished(t1)
waitUntilFinished(t2)
}在这个示例程序中,并发意味着 foo() 和 bar() 同时执行。CPU实际上是如何做到这一点的?
2、如何使用并发来使您的程序更快?
现代 CPU 可以同时执行多个指令流:
1、单个 CPU 内核可以执行多个线程:同时多线程(SMT),英特尔称之为超线程
2、当然CPU也可以有多个可以独立运行的核心
为了编程中获得最佳性能,编写多线程程序是必不可少的。为此,需要对硬件在并行编程环境中的行为方式有基本的了解。
大多数低级实现细节可以在英特尔架构软件开发人员手册和 ARM 架构参考手册中找到。
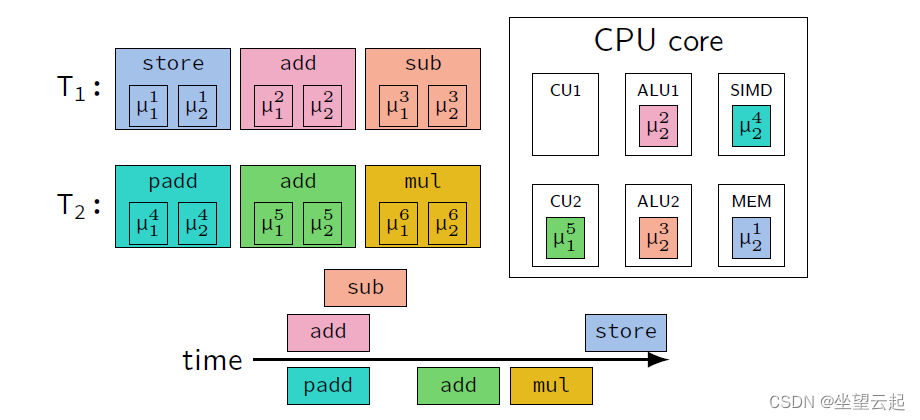
3、同时多线程 SMT
CPU 通过使用乱序执行来支持指令级并行
使用 SMT(Simultaneous Multi-Threading),CPU 还支持线程级并行
1、在单个 CPU 内核中,执行多个线程
2、许多硬件组件,如 ALU、SIMD 单元等,在线程之间共享
3、为每个线程复制其他组件,例如 控制单元获取和解码指令,寄存器文件
4、SMT的问题
使用 SMT 时,多个指令流共享部分 CPU 内核。
1、当一个流单独使用所有计算单元时,SMT 不会提高性能
2、内存带宽相同
3、有些单元可能只在内核上存在一次,因此 SMT 也会降低性能
4、当来自不相关进程的两个线程在同一个内核上运行时,这可能会导致安全问题! 类似于 Spectre 和 Meltdown 的安全问题。
5、缓存一致性

不同的内核可以同时访问同一个内存、多核可能共享缓存、缓存是包容性的
CPU 必须确保缓存与并发访问一致! 使用缓存一致性协议的 CPU 之间的通信
6、MESI 协议
CPU 和高速缓存始终以高速缓存行粒度(即 64 字节)读取和写入
通用 MESI 缓存一致性协议为每个缓存行分配以下四种状态之一:
Modified已修改:缓存行仅存储在一个缓存中,并在缓存中进行了修改,但尚未写回主存
Exclusive独占:缓存行仅存储在一个缓存中,供一个 CPU 独占使用
SharedShared:缓存行至少存储在一个缓存中,当前被 CPU 用于只读访问,尚未修改
Invalid无效:缓存行未加载或被另一个缓存独占使用
(1)MESI Example (1)

(2)MESI Example (2)
7、内存访问和并发
考虑以下示例程序,其中 foo() 和 bar() 将同时执行:
globalCounter = 0
function foo() {
repeat 1000 times:
globalCounter = globalCounter - 1
}
function bar() {
repeat 1000 times:
globalCounter = (globalCounter + 1) * 2
}该程序的机器代码可能如下所示:

最后 globalCounter 的值是多少?
8、Memory Order
乱序执行和同时多处理导致内存加载和存储指令的意外执行
所有执行的指令最终都会完成
但是,内存指令(即读取和写入)的影响可能会以不确定的顺序变得可见
CPU 供应商定义了如何允许读取和写入交错! 记忆顺序
通常:单个线程中的相关指令总是按预期工作:
store $123, A
load A, %r1如果 A 处的内存位置仅由该线程访问,则 r1 将始终包含 123
(1)Weak and Strong Memory Order
CPU 架构通常具有弱内存顺序(例如 ARM)或强内存顺序(例如 x86)
弱记忆顺序:
只要尊重依赖关系,内存指令及其效果就可以重新排序
不同的线程将看到不同顺序的写入
强记忆顺序:
在一个线程内,只允许在后续加载后延迟存储,其他所有内容都不会重新排序
当两个线程在同一位置执行存储时,所有其他线程将以相同的顺序看到结果写入
所有其他线程将以相同的顺序看到来自一组线程的写入
For Both:
来自其他线程的写入可以重新排序
对同一位置的并发内存访问可以重新排序
(2)Example of Memory Order (1)
在此示例中,最初 A 处的内存包含值 1,B 处的内存包含值 2。
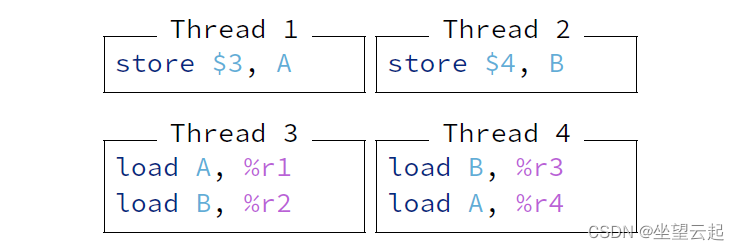
Weak memory order:
线程没有依赖指令
内存指令可以任意重新排序
r1 = 3, r2 = 2, r3 = 4, r4 = 1 是允许的
Strong memory order:
线程 3 和 4 必须以相同的顺序看到来自线程 1 和 2 的写入
不允许使用弱内存顺序的示例
r1 = 3, r2 = 2, r3 = 4, r4 = 3 是允许的
(3)Example of Memory Order (2)
弱记忆顺序示例的可视化:
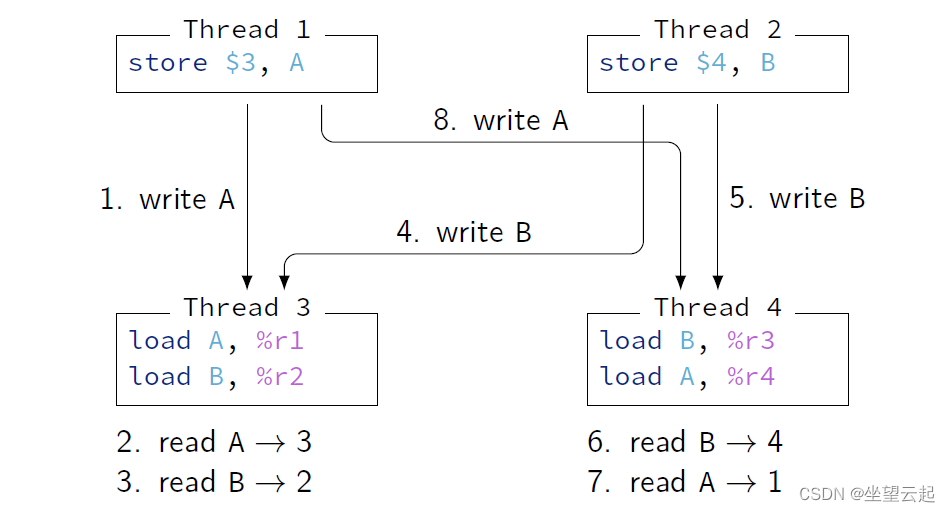
线程 3 在写入 B. (4.) 之前看到写入 A (1.)
线程 4 在写入 A. (8.) 之前看到写入 B (5.)
在强记忆中,5. 不允许在 8 之前发生。
9、Memory Barriers
多核 CPU 具有特殊的内存屏障(也称为内存栅栏)指令,可以执行更严格的内存顺序要求
这对于内存顺序较弱的架构特别有用
x86 有以下屏障指令:
lfence: 较早的加载不能在此指令之外重新排序,以后的加载和存储不能在此指令之前重新排序
sfence:在此指令之后不能重新排序早期的存储,在此指令之前不能重新排序以后的商店
mfence:不能在此指令之后或之前重新排序加载或存储
ARM 具有支持不同模式的数据存储器屏障指令:
dmb ishst:在该指令之前在该线程中可见或由该线程引起的所有写入将在该指令之后的来自存储的任何写入之前对所有线程可见
dmb ish:在该线程中可见或由该线程引起的所有写入以及该指令之前的相关读取将在该指令之后的任何读取和写入之前对所有线程可见
为了额外控制乱序执行,ARM 提供了数据同步屏障指令:dsb ishst、dsb ish
10、Atomic Operations
内存顺序只关心内存加载和存储
对同一内存位置的并发存储没有任何内存顺序限制! 顺序可能是不确定的
为了允许确定性并发修改,大多数架构都支持原子操作
原子操作通常是一个序列:加载数据、修改数据、存储数据
也称为读-修改-写 (RMW)
CPU 确保所有 RMW 操作都以原子方式执行,即中间不允许其他并发加载和存储
通常仅支持单个算术和按位指令

11、Compare-And-Swap Operations (1)
在 x86 上,RMW 指令可能会锁定内存总线
为避免性能问题,仅存在很少的 RMW 指令
为了促进更复杂的原子操作,可以使用 Compare-And-Swap (CAS) 原子操作
ARM不支持锁定内存总线,所以所有RMW操作都是用CAS实现的
一条 CAS 指令具有三个参数:内存位置 m、期望值 e 和期望值 d
CAS 操作在概念上的工作原理如下:

注意:CAS 操作可能会失败,例如由于并发修改
12、Compare-And-Swap Operations (2)
因为 CAS 操作可能会失败,所以它们通常在循环中使用,步骤如下:
1. 从内存位置加载值到本地寄存器
2. 假设没有其他线程会修改内存位置,使用本地寄存器进行计算
3. 为内存位置生成新的期望值
4.以本地寄存器中的值作为期望值对内存位置进行CAS操作
5.如果CAS操作失败,从头开始循环
请注意,步骤 2 和 3 可以包含任意数量的指令,并且不限于 RMW 指令!
13、Compare-And-Swap Operations (3)
使用 CAS 的典型循环如下所示:
success = false
while (not success) { (Step 5)
expected = load(A) (Step 1)
desired = non_trivial_operation(expected) (Steps 2, 3)
success = CAS(A, expected, desired) (Step 4)
}使用这种方法,可以对内存位置执行任意复杂的原子操作
但是,失败的可能性会增加,花费在非常规操作上的时间越多
此外,非常规的操作可能比必要的执行频率更高
二、并行编程
多线程程序通常包含许多共享资源
数据结构
操作系统句柄(例如文件描述符)
单独的内存位置
需要控制对共享资源的并发访问
不受控制的访问导致竞争条件
竞争条件通常以不一致的程序状态结束
其他结果,例如无声数据损坏也是可能的
同步可以通过不同的方式实现
操作系统支持,例如 通过互斥锁
硬件支持,尤其是通过原子操作
1、互斥(1)
从链表中同时删除元素
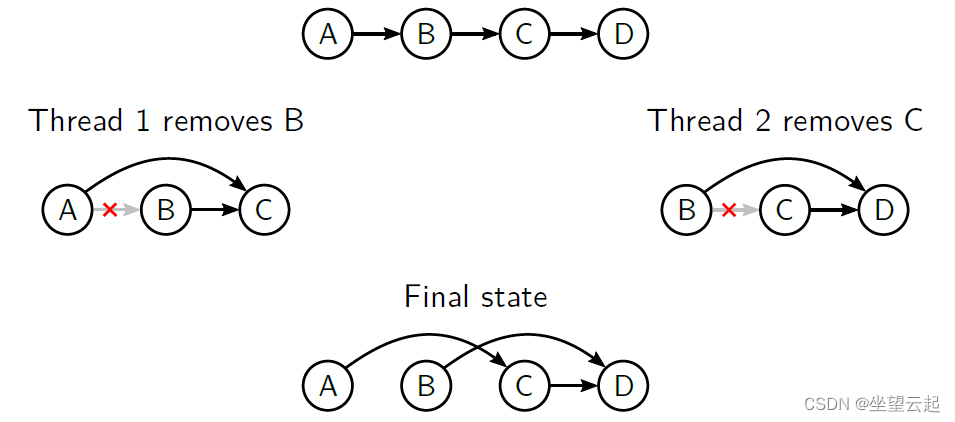
观察结果
C 实际上并没有被删除
线程也可能在删除后释放节点内存
2、互斥 (2)
通过仅允许在关键部分内进行访问来保护共享资源
一次只有一个线程可以进入临界区
如果正确使用,确保程序状态始终保持一致
非确定性(但一致)的程序行为仍然是可能的
实现互斥有多种可能性
原子测试和设置操作
通常需要自旋,这可能很危险
操作系统支持
例如。 Linux 中的互斥锁
3、锁
通过获取互斥对象上的锁来实现互斥
一次只有一个线程可以获取互斥锁
尝试在已锁定的互斥锁上获取锁将阻塞线程,直到互斥锁再次可用
阻塞的线程可以被内核挂起以释放计算资源
可以使用多个互斥对象来表示单独的临界区
一次只能有一个线程进入同一个临界区,但线程可以同时进入不同的临界区
允许更细粒度的同步
需要仔细实施以避免死锁
4、共享锁
严格的互斥并不总是必要的
对同一共享资源的常见并发只读访问不会相互干扰
使用严格互斥会引入不必要的瓶颈,因为读取时也会相互阻塞
我们只需要确保写访问不能与其他写或读访问同时发生
共享锁提供了一个解决方案
线程可以获取互斥锁上的独占锁或共享锁
如果互斥锁没有被独占锁定,多个线程可以同时获取互斥锁上的共享锁
如果互斥锁没有以任何其他方式(独占或共享)锁定,则一次一个线程可以获得互斥锁的独占锁
5、互斥问题(1)
死锁
多个线程各自等待其他线程释放锁
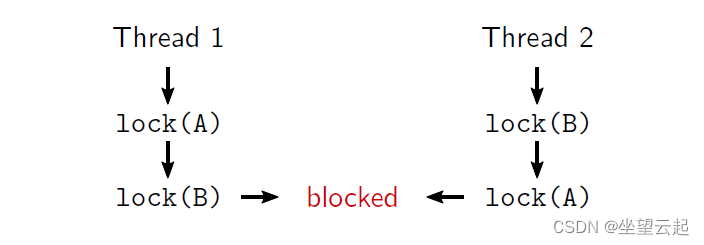
避免死锁
如果可能,线程不应该获取多个锁
如果无法避免,则必须始终以全局一致的顺序获取锁
6、互斥问题(2)
饥饿
互斥量的高争用可能导致某些线程没有进展
可以通过使用限制较少的锁定方案来部分缓解
高延迟
如果互斥量竞争激烈,某些线程会长时间阻塞
可能导致系统性能显着降低
性能甚至可能低于单线程性能
优先级反转
高优先级线程可能被低优先级线程阻塞
由于优先级差异,可能不允许低优先级的线程
足够的计算资源来快速释放锁
7、硬件辅助同步
使用互斥锁通常相对昂贵
每个互斥体都需要一些状态(16 到 40 个字节)
获取锁可能需要系统调用,这可能需要数千个周期或更长时间
因此,互斥锁最适合粗粒度锁定
例如。 锁定整个数据结构而不是其中的一部分
如果只有很少的线程竞争互斥锁上的锁就足够了
如果受互斥锁保护的关键部分更多,就足够了
比获取锁的(潜在)系统调用昂贵
互斥锁的性能在高竞争下迅速下降
特别是锁获取的延迟急剧增加
这甚至发生在我们只获取互斥锁上的共享锁时
我们可以利用硬件支持来实现更有效的同步
8、乐观锁定 (1)
通常,对资源的只读访问比写访问更常见
因此,我们应该针对只读访问的常见情况进行优化
特别是,许多线程的并行只读访问应该是有效的
共享锁不适合这个
乐观锁可以提供高效的读写器同步
将版本与共享资源关联
写入仍然必须获得某种排他锁
这确保了一次只有一个作者可以访问资源
在其关键部分的末尾,作者自动增加版本
读取只需验证版本
在其关键部分的开头,读取以原子方式读取当前版本
在其关键部分的末尾,读取验证版本没有更改
否则,发生并发写入并重新启动临界区
9、乐观锁定 (2)
示例(伪代码)
writer(optLock) {
lockExclusive(optLock.mutex) // begin critical section
// modify the shared resource
storeAtomic(optLock.version, optLock.version + 1)
unlockExclusive(optLock.mutex) // end critical section
}
reader(optLock) {
while(true) {
current = loadAtomic(optLock.version); // begin critical section
// read the shared resource
if (current == loadAtomic(optLock.version)) // validate
return; // end critical section
}
}10、乐观锁定 (3)
为什么乐观锁定有效?
读取只需执行两条原子加载指令
这比获取共享锁便宜得多
但要求很少修改,否则读取不得不频繁重启
需要仔细执行阅读器
共享资源可能会在读者访问它时被修改
我们不能假设我们从一致的状态读取
更复杂的读取操作可能需要额外的中间验证
11、超越互斥
在很多情况下,一开始就不需要严格的互斥
例如。 并行插入链表
我们不关心插入的顺序
我们只需要保证所有的插入都反映在最终状态中
这可以通过使用原子操作(伪代码)有效地实现
threadSafePush(linkedList, element) {
while (true) {
head = loadAtomic(linkedList.head)
element.next = head
if (CAS(linkedList.head, head, element))
break;
}
}12、非阻塞算法
不依赖锁的算法或数据结构称为非阻塞
例如。 上面的threadSafePush 函数
线程之间的同步通常使用原子操作来实现
能够更有效地实现许多常见算法和数据结构
这样的算法可以提供不同级别的进度保证
等待自由:完成每个操作所需的步骤数有一个上限
在实践中很难达到
无锁:如果程序运行足够的时间,至少有一个线程取得进展
通常非正式地(并且在技术上不正确)用作非阻塞的同义词
13、A-B-A 问题 (1)
非阻塞数据结构需要谨慎实现
我们不再拥有临界区的奢侈了
线程可以在数据结构上并行执行不同的操作(例如插入和删除)
包含这些复合操作的单个原子操作可以任意交错
这可能导致难以调试的异常,例如丢失更新或 A-B-A 问题
通常可以通过确保仅并行执行相同的操作(例如插入)来避免问题
例如。 在第一步中并行插入元素,在第二步中并行删除它们
14、A-B-A 问题 (2)
考虑以下简单的基于链表的堆栈(伪代码)
threadSafePush(stack, element) {
while (true) {
head = loadAtomic(stack.head)
element.next = head
if (CAS(stack.head, head, element))
break;
}
}
threadSafePop(stack) {
while (true) {
head = loadAtomic(stack.head)
next = head.next
if (CAS(stack.head, head, next))
return head
}
}15、A-B-A Problem (3)
考虑以下堆栈的初始状态,两个线程在该初始状态上并行执行一些操作
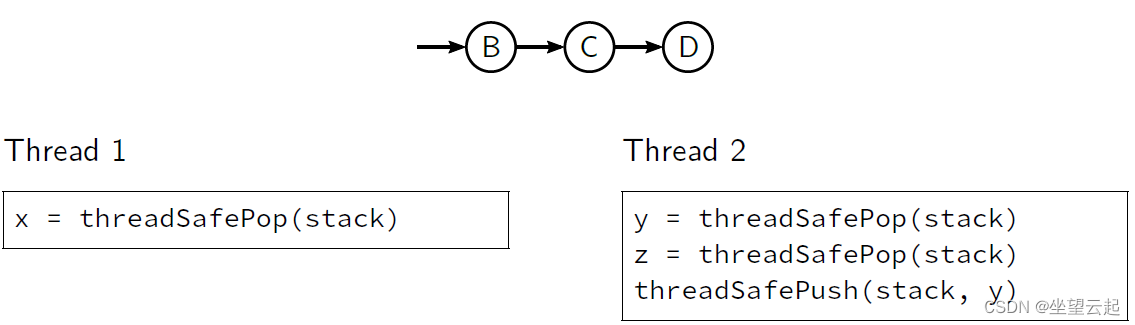
我们的实现将允许执行交错如下
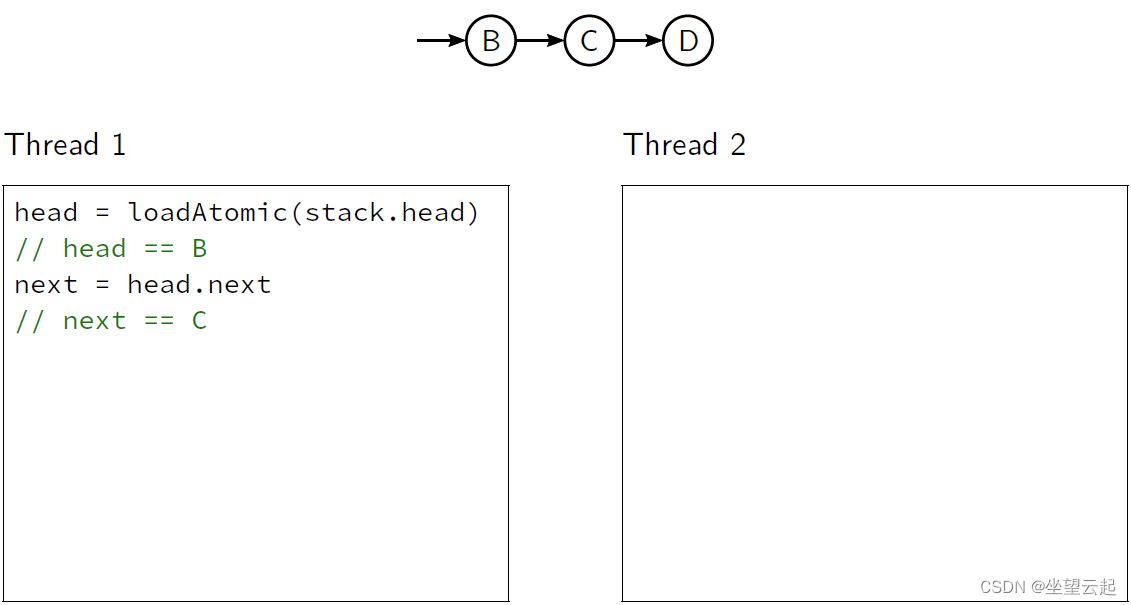




16、自旋的危险 (1)
可以实现一个“更好”的互斥体,它需要更少的空间并且不使用
使用原子操作进行系统调用:
互斥体以单个原子整数表示
解锁时为0,锁定时为1
要锁定互斥锁,只有使用 CAS 将值原子地更改为 0 时才将其更改为 1
只要另一个线程持有互斥锁,CAS就会重复
function lock(mutexAddress) {
while (CAS(mutexAddress, 0, 1) not sucessful) {
<noop>
}
}
function unlock(mutexAddress) {
atomicStore(mutexAddress, 0)
}17、自旋的危险 (2)
使用这个 CAS 循环作为互斥体,也称为自旋锁,有几个缺点:
1、它没有公平性,即不保证线程最终会获得锁
2、CAS循环消耗CPU周期(浪费能源和资源)
3、容易导致优先级倒置
操作系统的调度器认为自旋线程需要大量的CPU时间
旋转的线程实际上根本没有任何有用的工作
在最坏情况下,调度程序会占用持有锁的线程的CPU时间,以将其交给正在旋转的线程
4、自旋需要旋转更长的时间,这使情况变得更糟
3、可能的解决方案:
旋转有限的次数(例如多少次的迭代)
如果无法获得锁,则回退到“真正的”互斥锁。
实际上已经是互斥锁通常的实现方式(比如Java中的偏向锁 轻量级锁 重量级锁,偏向锁好像在最新的版本也被取消了)。
下面是使用C++11 atomics的基本自旋锁的完整实现
struct spinlock {
std::atomic<bool> lock_ = {0};
void lock() noexcept {
for (;;) {
// 乐观地假设锁在第一次尝试时是空闲的
if (!lock_.exchange(true, std::memory_order_acquire)) {
return;
}
// 等待释放锁而不产生缓存未命中
while (lock_.load(std::memory_order_relaxed)) {
// 发出 X86 PAUSE 或 ARM YIELD 指令以减少超线程(hyper-threads)之间的争用
__builtin_ia32_pause();
}
}
}
bool try_lock() noexcept {
// 首先做一个简单的加载来检查锁是否空闲,以防止在有人这样做时不必要的缓存未命中 while(!try_lock())
return !lock_.load(std::memory_order_relaxed) &&
!lock_.exchange(true, std::memory_order_acquire);
}
void unlock() noexcept {
lock_.store(false, std::memory_order_release);
}
};
自旋锁 的目的是防止多个线程同时访问共享数据结构。与互斥锁相比,线程将忙于等待并浪费 CPU 周期,而不是将 CPU 让给另一个线程。除非您确定自己了解后果,否则不要使用自定义的自旋锁而是用各种语言提供的原子变量。