论文名:ECA-Net: Effificient Channel Attention for Deep Convolutional Neural Networks
论文:https://arxiv.org/abs/1910.03151
开源代码:https://github.com/BangguWu/ECANet
首先上结果图,看着真香!!!

如图1 纵坐标为准确性,横坐标为模型参数量(类似空间复杂度)
0.论文摘要
最近,通道注意力机制被证明在改善深度卷积神经网络(CNNs)的性能方面具有巨大的潜力。然而,现有的方法大多致力于开发更复杂的注意力模块,以实现更好的性能,这不可避免地增加了模型的复杂性。为了克服性能和复杂性之间的矛盾,本文提出了一种有效的通道关注(ECA)模块,该模块只增加了少量的参数,却能获得明显的性能增益。通过对SENet中通道注意模块的分析,作者的经验表明避免降维对于学习通道注意力非常重要,适当的跨信道交互可以在显著降低模型复杂度的同时保持性能。因此,作者提出了一种不降维的局部跨信道交互策略,该策略可以通过一维卷积有效地实现。进一步,作者又提出了一种自适应选择一维卷积核大小的方法,以确定局部跨信道交互的覆盖率。 实验证明,本文提出的ECA模块是高效的(上图)。
本文模块(ECA)相对于ResNet50的主干的参数和计算分别是80M比24.37M和4.7e-4 GFLOPs比3.86 GFLOPs,并且性能在Top-1精度方面提升超过2%。本文以ResNets和MobileNetV2为骨干,利用提出的ECA模块在图像分类、目标检测和实例分割方面进行了广泛的评估。实验结果表明,该模块在性能上优于其他模块,且具有较高的效率。
ECA模块与其他注意力模块的比较:这里以ResNets作为骨干模型来进行分类精度,网络参数和FLOPs的比较,以圆来表示。从上图可以看出
一.论文简介(introduction)
深度卷积神经网络(CNNs)在计算机视觉领域得到了广泛的应用,在图像分类、目标检测和语义分割等领域取得了很大的进展。从开创性的AlexNet开始,为了进一步提高深度cnn的性能,不断推出新的CNN模型。近年来,将通道注意力引入卷积块引起了人们的广泛关注,在性能改进方面显示出巨大潜力。其中代表性的方法是SENet,它可以学习每个卷积块的通道注意力,对各种深度CNN架构带来明显的性能增益。SENet主要是 squeeze 和 excitation 两大操作,最近,一些研究通过捕获更复杂的通道依赖或结合额外的空间注意来改进SE块。这些方法虽然取得了较高的精度,但往往带来较高的模型复杂度和较大的计算负担。与前面提到的以更高的模型复杂度为代价来获得更好性能的方法不同,本文转而关注一个问题:能否以更有效的方式学习有效的通道注意力?
为了回答这个问题,我们首先回顾一下SENet中的通道注意模块。具体来说,在给定输入特征的情况下,SE块首先对每个通道单独使用全局平均池化,然后使用两个具有非线性的完全连接(FC)层,然后使用一个Sigmoid函数来生成通道权值。两个FC层的设计是为了捕捉非线性的跨通道交互,其中包括降维来控制模型的复杂性。虽然该策略在后续的通道注意模块中得到了广泛的应用,但作者的实验研究表明,降维对通道注意预测带来了副作用,捕获所有通道之间的依赖是低效的,也是不必要的。
SE-net:

由上图可知:第一个FC层进行降维(通道数从C--->C/r),第二个FC层又进行了升维(通道数从C/r---->C)
因此,本文提出了一种针对深度CNN的高效通道注意(ECA)模块,该模块避免了降维,有效捕获了跨通道交互的信息。如下图2所示:
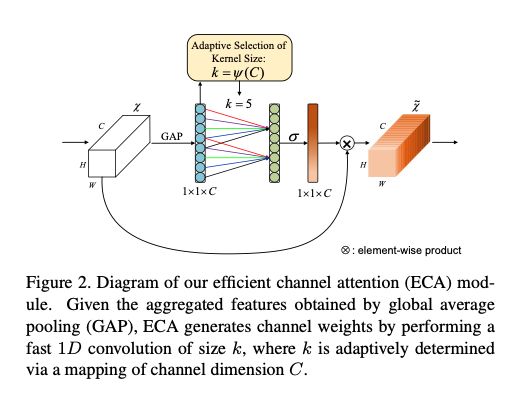
本文在全局平均池化之后不降低通道的维数,通过考虑每个通道及其k个邻居进行局部跨通道交互信息。实践证明,该方法保证了模型效率和计算效果。需要注意的是,ECA可以通过大小为k的快速1D卷积来有效实现,其中卷积核大小为k代表了局部跨信道交互的覆盖率,即,该通道附近有多少邻居参与了这个信道的注意力预测,为了避免通过交叉验证对k进行手动调优,本文提出了一种方法来自适应地确定k,其中交互的覆盖率(即卷积核大小 k)与通道维数成正比。
本文的贡献如下:
- 对SE模块进行了剖析,并分别证明了避免降维和适当的跨通道交互对于学习高性能和高效率的通道注意力是重要的。
- 在以上分析的基础上,提出了一种高效通道注意模块(ECA),在CNN网络上提出了一种极轻量的通道注意力模块,该模块增加的模型复杂度小,提升效果显著。
- 在ImageNet-1K和MS COCO上的实验结果表明,本文提出的方法具有比目前最先进的CNN模型更低的模型复杂度,与此同时,本文方法却取得了非常有竞争力的结果。
二.提出的方法
在本节中,我们首先重新回顾SENet[14]中的通道注意模块(即SE块)。然后,我们通过分析降维和跨通道交互作用的影响,对SE块进行了实验判断。这促使我们提出我们的ECA模块。此外,我们还开发了一种自适应确定ECA参数的方法,并最后展示了如何将其用于深度cnn。
SE模块的通道注意力通过如下式1计算:

接下来介绍一下ECA的模块,首先由公式2:
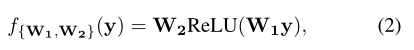
为了验证它的效果,作者比较了原始SE块和它的三个变体(即 SE-Var1, SE-Var2和SE-Var3),所有这些都没有进行降维操作。具体效果如下表2所示:
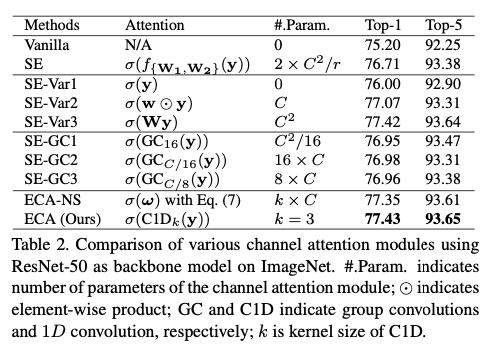
表2 SE以及ECA结果图
对SE进行探索
2.1Avoiding Dimensionality Reduction(避免降维)
为了验证其效果,我们将原始的SE块与它的三个变体(即SE-Var1、SE-Var2和SE-Var3)进行了比较,所有这些变体都不执行维度回归。如上表2所示,没有参数的SE-Var1仍然优于原始网络,说明通道注意能够提高深度cnn的性能。同时,SE-Var2可以独立学习各通道的权重,略优于SE块。这可能表明:通道及其权重需要直接对应,同时避免双敏感性降低比考虑非线性信道依赖性更重要。此外,使用一个单一FC层的SEVar3比在SE块中降维的两个FC层性能更好。以上所有的结果都清楚地表明,避免降维有助于学习有效的通道注意,提高准确度。
2.2Local Cross-Channel Interaction(局部跨通道交互)

对于SE-Var2、SE-Var3,权重式分别为:

两者之间区别在于,SE-Var3考虑了不同通道之间的交互(全局跨通道交互),SE-Var2则没有(因为Wvar2是一个对角矩阵);但是SE-Var3的需要大量参数,这样复杂性较高。
作者为了综合上述两个方面的优点,将SE-Var2+SE-Var3→ 块对角矩阵。(如下所示 局部跨通道交互)
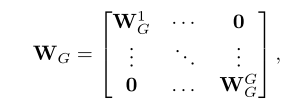
Wvar3相当于 W1G, W2G, W2G,........(局部跨通道交互,表2中SE-GC1,2,3系列)
其中,上式WG将通道C划分为G组,每个组包括C/G通道,并独立学习每个组中的通道注意,以局部方式进行跨通道交互。因此,它涉及到C^2/G个参数。从卷积的角度来看,SE-Var2,SEVar3和上式可以分别看作是一个深度可分离的卷积、一个FC层和组卷积(SE-GC)。然而,由上表2可以看出,(SE-GC1,2,3系列)这样做并没有给SE-Var2带来增益,表明它这样做局部通道交互不能捕获局部通道之间的相互作用,而且过多的组卷及将层架内存访问成本,从而降低计算效率。
SE-GC1,2,3系列不起作用的原因可能SE-GC完全抛弃了不同组之间的依赖关系。
2.3 ECA模块
为此我们探索了另一种捕获局部跨通道交互的方法(ECA模块),旨在保证信息效率和有效性。具体地说,我们使用了一个频带矩阵Wk来学习信道注意,而Wk已经有了(如下式6)

其中,Wk涉及K*C个参数,并且Wk避免了不同group的完全独立,正如在上表2中所示,本文提出的这种方法叫做ECA-NS,他比SE-GC性能要更优。对于yi对应的权重w11,w12....w1k,本文只考虑yi和它的k个邻居之间的信息交互,计算公式如下:

为了进一步提高性能,还可以让所有的通道共享权重信息,即:通过共享相同的学习参数,通过内核大小为k的1维卷积来实现通道之间的信息交互:(一维卷积和1 × 1 卷积是不同的,一维指的是1 × k 的卷积)
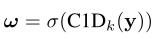
C1D代表一维卷积,这种方法称之为ECA模块,它只涉及K个参数信息,如上表2,当k=3时,ECA模块可以实现与SE-Var3同样的效果但却有更低的模型复杂度。因此,这种捕捉跨通道信息交互的方法保证了性能结果和模型效率。
2.4Coverage of Local Cross-Channel Interaction(局部跨通道交互覆盖)
ECA模块的k如何取值?
上述ECA模块旨在适当捕获局部跨道信息交互,因此需要确定通道交互信息的大致范围(即1D卷积的卷积核大小k)。虽然可以针对各种CNN架构中具有不同通道数的卷积块进行手动优化设置信息交互的最佳范围,但是通过手动进行交叉验证调整将花费大量计算资源。而且分组卷积已成功地用于改善CNN架构,在固定group数量的情况下,高维(低维)通道与长距离(短距离)卷积成正比。同理,跨通道信息交互作用的覆盖范围(即一维卷积的内核大小k)与通道维数C应该也是成正比的。换句话说,在k和C之间可能存在映射φ:

最简单的映射是一个线性函数,即φ(k)=γ∗k−b。然而,以线性函数为特征的关系就太有限了。另一方面,众所周知,通道维度C(即滤波器的数量)通常被设置为2的幂。因此,我们通过将线性函数φ(k)=γ∗k−b扩展到非线性函数,引入了一个可能的解,即,
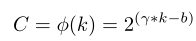
然后,给定通道维数C,核大小k可以自适应地确定
卷积尺寸K大小:
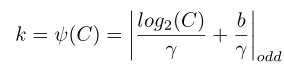
其中|t|奇数表示t的最接近奇数。在本文中,我们在所有实验中分别将γ和b设为2和1。显然,通过映射ψ,高维通道具有更长的相互作用,而低维通道通过使用非线性映射进行更短的相互作用。
不同注意力机制结合CNN的结果图:
作者分别在ImageNet和MS COCO数据集上,对提出的ECA模块在图像分类、目标检测和实例分割方面进行了实验评估,具体来说,首先评估卷积核大小对ECA模块的影响,并与ImageNet上最先进的模型进行了比较。然后,将网络模块分别结合Faster R-CNN、Mask R-CNN和RetinaNet验证了在MS COCO数据集上的有效性。
表3比较了不同的注意力方法在ImageNet数据集上的网络参数(param),浮点运算每秒(FLOPs),训练或推理速度(帧每秒,FPS), Top-1/Top-5的准确性(%)。

三.实验结果
k值的影响如下图表4,ResNet-50和ResNet-101为主干,对照SENet。可以看出,ECA-Net相较于SENet,准确率有了极大的提升。

当k在所有卷积块中都固定时,对于ResNet-50和ResNet-101, ECA模块分别在k = 9和k = 5处取得最佳结果。由于ResNet-101有更多的中间层来支配ResNet-101的性能,因此它可能更喜欢较小的卷积核。此外,这些结果表明,不同深度cnn具有不同的最优k值,k值对ECA-Net性能有明显影响。此外,ResNet-101的准确率波动(约0.5%)要大于ResNet-50的准确率波动(约0.15%),作者推测原因是更深层次的网络比更浅层次的网络对固定的卷积核大小更敏感。此外,由映射ψ函数自适应确定的卷积核K大小通常优于固定的卷积核大小,但可以避免通过交叉验证手动调整参数k。以上结果证明了本文的自适应选择卷积核大小是可以取得较好且稳定的结果。最后,不同k个数的ECA模块始终优于SE block,验证了避免降维和局部跨通道交互对学习通道注意力是有积极作用的。
与不同的CNN对比:

如上表4所示,ECA-Net101的性能优于ResNet-200,这表明ECA-Net可以用更少的计算成本提高深度CNNs的性能。同时,ECA-Net101与ResNeXt-101相比具有更强的竞争力,而ResNeXt-101使用了更多的卷积滤波器和昂贵的群卷积。此外,ECA-Net50可与DenseNet-264 (k=32)、DenseNet-161 (k=48)和 Inception-v3相媲美,但模型复杂度较低。以上结果表明,ECA-Net在性能上优于最先进的CNNs,同时具有更低的模型复杂度。ECA也有很大的潜力来进一步提高CNN模型的性能。
本文还使用Faster R-CNN[26]、Mask R-CNN[10]和RetinaNet[22]在目标检测任务上评估ECA-Net。主要将ECA-Net结合骨干ResNet和SENet结合骨干ResNet进行比较。所有的CNN模型都是在ImageNet上预先训练好的,然后通过在MS COCO数据集上进行微调。具体实验效果如下所示:

四.总结
本篇论文作者提出了一种有效的通道注意力(ECA)模块,该模块通过快速的一维卷积产生通道注意,其核大小可以通过通道维数的非线性映射自适应地确定。实验结果表明,我们的ECA是一个非常轻量级的即插即用块,可以提高各种深度CNN架构的性能,包括广泛使用的ResNets和轻量级的MobileNetV2。此外,我们的ECA-Net在目标检测和实例分割任务中表现出良好的泛化能力。
五.ECA模块的代码实现
import torch
from torch import nn
from torch.nn.parameter import Parameter
class eca_layer(nn.Module):
"""Constructs a ECA module.
Args:
channel: Number of channels of the input feature map
k_size: Adaptive selection of kernel size
"""
def __init__(self, channel, k_size=3):
super(eca_layer, self).__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.conv = nn.Conv1d(1, 1, kernel_size=k_size, padding=(k_size - 1) // 2, bias=False)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
# x: input features with shape [b, c, h, w]
b, c, h, w = x.size()
# feature descriptor on the global spatial information
y = self.avg_pool(x)
# Two different branches of ECA module
y = self.conv(y.squeeze(-1).transpose(-1, -2)).transpose(-1, -2).unsqueeze(-1)
# Multi-scale information fusion
y = self.sigmoid(y)
return x * y.expand_as(x)