如果我们输入的是:
python tools/train.py --model cfa --config src/anomalib/models/cfa/config.yaml也就是说,我们搞CFA,怎么办呢?
下面是train.py的代码。
"""Anomalib Training Script.
This script reads the name of the model or config file from command
line, train/test the anomaly model to get quantitative and qualitative
results.
"""
# Copyright (C) 2022 Intel Corporation
# SPDX-License-Identifier: Apache-2.0
import logging
import warnings
from argparse import ArgumentParser, Namespace
from pytorch_lightning import Trainer, seed_everything
from anomalib.config import get_configurable_parameters
from anomalib.data import get_datamodule
from anomalib.data.utils import TestSplitMode
from anomalib.models import get_model
from anomalib.utils.callbacks import LoadModelCallback, get_callbacks
from anomalib.utils.loggers import configure_logger, get_experiment_logger
logger = logging.getLogger("anomalib")
def get_args() -> Namespace:
"""Get command line arguments.
Returns:
Namespace: List of arguments.
"""
parser = ArgumentParser()
parser.add_argument("--model", type=str, default="padim", help="Name of the algorithm to train/test")
parser.add_argument("--config", type=str, required=False, help="Path to a model config file")
parser.add_argument("--log-level", type=str, default="INFO", help="<DEBUG, INFO, WARNING, ERROR>")
args = parser.parse_args()
return args
def train():
"""Train an anomaly classification or segmentation model based on a provided configuration file."""
args = get_args()
configure_logger(level=args.log_level)
if args.log_level == "ERROR":
warnings.filterwarnings("ignore")
config = get_configurable_parameters(model_name=args.model, config_path=args.config)
if config.project.get("seed") is not None:
seed_everything(config.project.seed)
datamodule = get_datamodule(config)
model = get_model(config)
experiment_logger = get_experiment_logger(config)
callbacks = get_callbacks(config)
trainer = Trainer(**config.trainer, logger=experiment_logger, callbacks=callbacks)
logger.info("Training the model.")
trainer.fit(model=model, datamodule=datamodule)
logger.info("Loading the best model weights.")
load_model_callback = LoadModelCallback(weights_path=trainer.checkpoint_callback.best_model_path)
trainer.callbacks.insert(0, load_model_callback) # pylint: disable=no-member
if config.dataset.test_split_mode == TestSplitMode.NONE:
logger.info("No test set provided. Skipping test stage.")
else:
logger.info("Testing the model.")
trainer.test(model=model, datamodule=datamodule)
if __name__ == "__main__":
train()
一、关于配置文件信息
看看,train函数,里面的内容:
args = get_args()
configure_logger(level=args.log_level)根据输入,实际上我们的log_level取的是默认值,INFO
下面这句话,是重头戏:
config = get_configurable_parameters(model_name=args.model, config_path=args.config)这里的config就被赋予了args.model和args.config指定的重要信息。
def get_configurable_parameters(
model_name: str | None = None,
config_path: Path | str | None = None,
weight_file: str | None = None,
config_filename: str | None = "config",
config_file_extension: str | None = "yaml",
) -> DictConfig | ListConfig:
"""Get configurable parameters.
Args:
model_name: str | None: (Default value = None)
config_path: Path | str | None: (Default value = None)
weight_file: Path to the weight file
config_filename: str | None: (Default value = "config")
config_file_extension: str | None: (Default value = "yaml")
Returns:
DictConfig | ListConfig: Configurable parameters in DictConfig object.
"""
if model_name is None is config_path:
raise ValueError(
"Both model_name and model config path cannot be None! "
"Please provide a model name or path to a config file!"
)
if config_path is None:
config_path = Path(f"src/anomalib/models/{model_name}/{config_filename}.{config_file_extension}")
config = OmegaConf.load(config_path)
# keep track of the original config file because it will be modified
config_original: DictConfig = config.copy()
# if the seed value is 0, notify a user that the behavior of the seed value zero has been changed.
if config.project.get("seed") == 0:
warn(
"The seed value is now fixed to 0. "
"Up to v0.3.7, the seed was not fixed when the seed value was set to 0. "
"If you want to use the random seed, please select `None` for the seed value "
"(`null` in the YAML file) or remove the `seed` key from the YAML file."
)
config = update_datasets_config(config)
config = update_input_size_config(config)
# Project Configs
project_path = Path(config.project.path) / config.model.name / config.dataset.name
if config.dataset.format == "folder":
if "mask" in config.dataset:
warn(
DeprecationWarning(
"mask will be deprecated in favor of mask_dir in config.dataset in a future release."
)
)
config.dataset.mask_dir = config.dataset.mask
if "path" in config.dataset:
warn(DeprecationWarning("path will be deprecated in favor of root in config.dataset in a future release."))
config.dataset.root = config.dataset.path
# add category subfolder if needed
if config.dataset.format.lower() in ("btech", "mvtec", "visa"):
project_path = project_path / config.dataset.category
# set to False by default for backward compatibility
config.project.setdefault("unique_dir", False)
if config.project.unique_dir:
project_path = project_path / f"run.{_get_now_str(time.time())}"
else:
project_path = project_path / "run"
warn(
"config.project.unique_dir is set to False. "
"This does not ensure that your results will be written in an empty directory and you may overwrite files."
)
(project_path / "weights").mkdir(parents=True, exist_ok=True)
(project_path / "images").mkdir(parents=True, exist_ok=True)
# write the original config for eventual debug (modified config at the end of the function)
(project_path / "config_original.yaml").write_text(OmegaConf.to_yaml(config_original))
config.project.path = str(project_path)
# loggers should write to results/model/dataset/category/ folder
config.trainer.default_root_dir = str(project_path)
if weight_file:
config.trainer.resume_from_checkpoint = weight_file
config = update_nncf_config(config)
# thresholding
if "metrics" in config.keys():
# NOTE: Deprecate this once the new CLI is implemented.
if "adaptive" in config.metrics.threshold.keys():
warn(
DeprecationWarning(
"adaptive will be deprecated in favor of method in config.metrics.threshold in a future release"
)
)
config.metrics.threshold.method = "adaptive" if config.metrics.threshold.adaptive else "manual"
if "image_default" in config.metrics.threshold.keys():
warn(
DeprecationWarning(
"image_default will be deprecated in favor of manual_image in config.metrics.threshold in a future "
"release."
)
)
config.metrics.threshold.manual_image = (
None if config.metrics.threshold.adaptive else config.metrics.threshold.image_default
)
if "pixel_default" in config.metrics.threshold.keys():
warn(
DeprecationWarning(
"pixel_default will be deprecated in favor of manual_pixel in config.metrics.threshold in a future "
"release."
)
)
config.metrics.threshold.manual_pixel = (
None if config.metrics.threshold.adaptive else config.metrics.threshold.pixel_default
)
(project_path / "config.yaml").write_text(OmegaConf.to_yaml(config))
return config可以从上面代码看出来,主要干了这几件事:
1、设置config_path
2、update_datasets_config,用来Updates the dataset section of the config
3、update_input_size_config,用来:
Update config with image size as tuple, effective input size and tiling stride. Convert integer image size parameters into tuples, calculate the effective input size based on image size and crop size, and set tiling stride if undefined.
4、设置project_path,
project_path = Path(config.project.path) / config.model.name / config.dataset.name

5、metrics相关设置
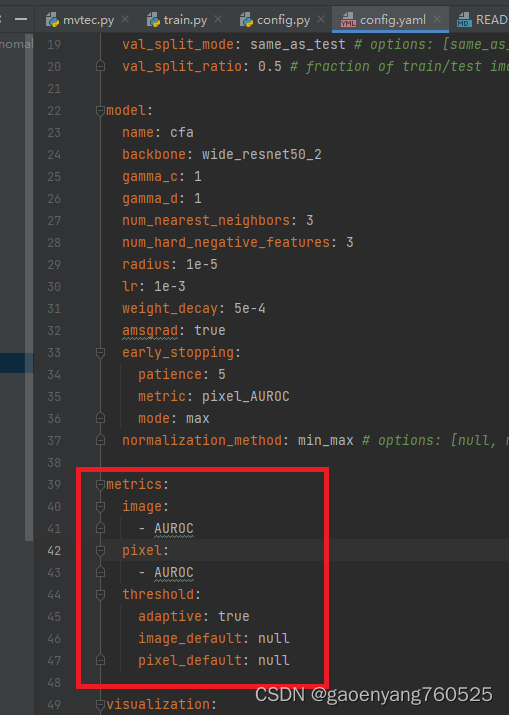
二、关于get_datamodule
root=config.dataset.path,
category=config.dataset.category,
image_size=(config.dataset.image_size[0], config.dataset.image_size[1]),
center_crop=center_crop,
normalization=config.dataset.normalization,
train_batch_size=config.dataset.train_batch_size,
eval_batch_size=config.dataset.eval_batch_size,
num_workers=config.dataset.num_workers,
task=config.dataset.task,
transform_config_train=config.dataset.transform_config.train,
transform_config_eval=config.dataset.transform_config.eval,
test_split_mode=config.dataset.test_split_mode,
test_split_ratio=config.dataset.test_split_ratio,
val_split_mode=config.dataset.val_split_mode,
val_split_ratio=config.dataset.val_split_ratio,
三、关于get_model
model_list: list[str] = [
"cfa",
"cflow",
"csflow",
"dfkde",
"dfm",
"draem",
"fastflow",
"ganomaly",
"padim",
"patchcore",
"reverse_distillation",
"rkde",
"stfpm",
]
model: AnomalyModule
if config.model.name in model_list:
module = import_module(f"anomalib.models.{config.model.name}")
model = getattr(module, f"{_snake_to_pascal_case(config.model.name)}Lightning")(config)
else:
raise ValueError(f"Unknown model {config.model.name}!")
if "init_weights" in config.keys() and config.init_weights:
model.load_state_dict(load(os.path.join(config.project.path, config.init_weights))["state_dict"], strict=False)
return model