容器的基本实现
DefaultListableBeanFactory是整个bean加载的核心部分,是Spring注册及加载bean的默认实现,
XmlBeanFactory继承自DefaultListableBeanFactory与DefaultListableBeanFactory,
二者不同的地方其实是在XmlBeanFactory中使用了自定义的XML读取器XmlBeanDefinitionReader,实现了自定义读取,
而DefaultListableBeanFactory继又承了AbstractAutowireCapableBeanFactory
并实现了ConfigURableListableBeanFactory以及BeanDefinitionRegistry接口。
1、DefaultListableBeanFactory的层次结构图如题所示:
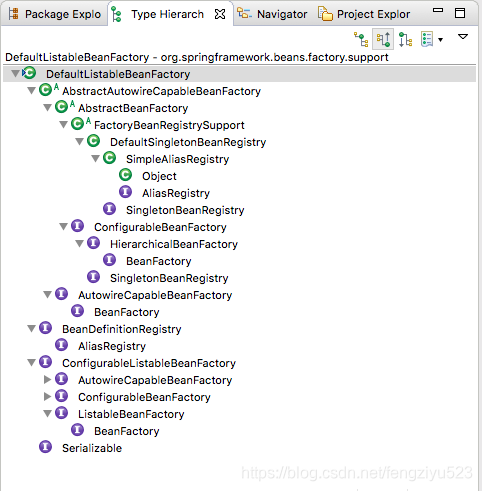
从上面的层次结构图,完全可以清晰的、全局的了解DefaultListableBeanFactory的脉络。
其中各个模块功能如下:
AliasRegistry:定义对alias的简单增删改等操作
SimpleAliasRegistry:主要使用map作为alias的缓存,并对接口AliasRegistry进行实现
SingletonBeanRegistry:定义对单例的注册及获取
BeanFactory:定义获取bean及bean的各种属性
DefaultSingletonBeanRegistry:对接口SingletonBeanRegistry各函数的实现
HierarchicalBeanFactory:继承BeanFactory,也就是在BeanFactory定义的功能的基础上增加了对parentFactory的支持
BeanDefinitionRegistry:定义对BeanDefinition的各种增删改操作
FactoryBeanRegistrySupport:在DefaultSingletonBeanRegistry基础上增加了对FactoryBean的特殊处理功能
ConfigurableBeanFactory:提供配置Factory的各种方法
ListableBeanFactory:根据各种条件获取bean的配置清单
AbstractBeanFactory:综合FactoryBeanRegistrySupport和ConfigurationBeanFactory的功能
AutowireCapableBeanFactory:提供创建bean、自动注入、初始化以及应用bean的后处理器
AbstractAutowireCapableBeanFactory:综合AbstractBeanFactory并对接口AutowireCapableBeanFactory进行实现
ConfigurableListableBeanFactory:BeanFactory配置清单,指定忽略类型及接口等
DefaultListableBeanFactory:综合上面所有功能,主要是对Bean注册后的处理
2、XmlBeanFactory对DefaultListableBeanFactory类进行了扩展,主要用于从XML文档中读取BeanDefinition,对于注册及获取Bean都是使用从父类DefaultListableBeanFactory继承的方法去实现。
与父类的不同就是增加了XmlBeanDefinitionReader类型的reader属性。在XmlBeanFactory中主要使用reader属性对资源文件进行读取和注册。如下:
public class XmlBeanFactory extends DefaultListableBeanFactory {
private final XmlBeanDefinitionReader reader = new XmlBeanDefinitionReader(this);整个XML配置文件读取的大致流程,在XmlBeanDefinitionReader中主要包含以下几步处理:
(1)通过继承自AbstractBeanDefinitionReader中的方法,来使用ResourceLoader将资源文件路径转换为对应的Resource文件
(2)通过DocumentLoader对Resource文件进行转换,将Resource文件转换为Document文件
(3)通过实现接口BeanDefinitionDocumentReader的DefaultBeanDefinitionDocumentReader类对Document进行解析,并使用BeanDefinitionParserDelegate对Element进行解析
3、容器的基础XmlBeanFactory
BeanFactory bf = new XmlBeanFactory(new ClassPathResource("beanFactoryTest.xml"));
BeanFactoryTest测试类开始,首先调用ClassPathResource的构造函数来构造Resource资源文件的实例对象,这样后续的资源处理就可以用Resource提供的各种服务来操作了
4、Spring的配置文件读取是通过ClassPathResource进行封装的,Spring对其内部使用到的资源实现了自己的抽象结构:Resource接口来封装底层资源
*/
public interface Resource extends InputStreamSource {
/**
* Determine whether this resource actually exists in physical form.
* <p>This method performs a definitive existence check, whereas the
* existence of a {@code Resource} handle only guarantees a valid
* descriptor handle.
*/
boolean exists();
/**
* Indicate whether the contents of this resource can be read via
* {@link #getInputStream()}.
* <p>Will be {@code true} for typical resource descriptors;
* note that actual content reading may still fail when attempted.
* However, a value of {@code false} is a definitive indication
* that the resource content cannot be read.
* @see #getInputStream()
*/
boolean isReadable();
/**
* Indicate whether this resource represents a handle with an open stream.
* If {@code true}, the InputStream cannot be read multiple times,
* and must be read and closed to avoid resource leaks.
* <p>Will be {@code false} for typical resource descriptors.
*/
boolean isOpen();
/**
* Return a URL handle for this resource.
* @throws IOException if the resource cannot be resolved as URL,
* i.e. if the resource is not available as descriptor
*/
URL getURL() throws IOException;
/**
* Return a URI handle for this resource.
* @throws IOException if the resource cannot be resolved as URI,
* i.e. if the resource is not available as descriptor
* @since 2.5
*/
URI getURI() throws IOException;
/**
* Return a File handle for this resource.
* @throws IOException if the resource cannot be resolved as absolute
* file path, i.e. if the resource is not available in a file system
*/
File getFile() throws IOException;
/**
* Determine the content length for this resource.
* @throws IOException if the resource cannot be resolved
* (in the file system or as some other known physical resource type)
*/
long contentLength() throws IOException;
/**
* Determine the last-modified timestamp for this resource.
* @throws IOException if the resource cannot be resolved
* (in the file system or as some other known physical resource type)
*/
long lastModified() throws IOException;
/**
* Create a resource relative to this resource.
* @param relativePath the relative path (relative to this resource)
* @return the resource handle for the relative resource
* @throws IOException if the relative resource cannot be determined
*/
Resource createRelative(String relativePath) throws IOException;
/**
* Determine a filename for this resource, i.e. typically the last
* part of the path: for example, "myfile.txt".
* <p>Returns {@code null} if this type of resource does not
* have a filename.
*/
String getFilename();
/**
* Return a description for this resource,
* to be used for error output when working with the resource.
* <p>Implementations are also encouraged to return this value
* from their {@code toString} method.
* @see Object#toString()
*/
String getDescription();Resource接口抽象了所有Spring内部使用到的底层资源:File、URL、Classpath等。首先,它定义了3个判断当前资源状态的方法:存在性(exists)、可读性(isReadable)、是否处于打开状态(isOpen)。另外,Resource接口还提供了不同资源到URL、URI、File类型的转换,以及获取lastModified属性、文件名(不带路径信息的文件名,getFilename())的方法,为了便于操作,Resource还提供了基于当前资源创建一个相对资源的方法:createRelative(),还提供了getDescription()方法用于在错误处理中的打印信息。
XmlBeanFactory的初始化有若干办法,Spring提供了很多的构造函数,在这里分析的是使用Resource实例作为构造函数参数的办法,代码如下:
public XmlBeanFactory(Resource resource, BeanFactory parentBeanFactory) throws BeansException {
super(parentBeanFactory);
this.reader.loadBeanDefinitions(resource);
}函数中的代码this.reader.loadBeanDefinitions(resource)才是资源加载的真正实现。在XmlBeanDefinitionReader加载数据前还有一个调用父类构造函数初始化的过程:super(parentBeanFactory),跟踪代码到父类AbstractAutowireCapableBeanFactory的构造函数中:
public AbstractAutowireCapableBeanFactory() {
super();
ignoreDependencyInterface(BeanNameAware.class);
ignoreDependencyInterface(BeanFactoryAware.class);
ignoreDependencyInterface(BeanClassLoaderAware.class);
}ignoreDependencyInterface的主要功能是忽略给定接口的自动装配功能,目的是:实现了BeanNameAware接口的属性,不会被Spring自动初始化。自动装配时忽略给定的依赖接口,典型应用是通过其他方式解析Application上下文注册依赖,类似于BeanFactory通过BeanFactoryAware进行注入或者ApplicationContext通过ApplicationContextAware进行注入。
5、加载Bean
如上面介绍,在XmlBeanFactory构造函数中调用了XmlBeanDefinitionReader类型的reader属性提供的方法this.reader.loadBeanDefinitions(resource),这句代码则是整个资源加载的入口。
public int loadBeanDefinitions(Resource resource) throws BeanDefinitionStoreException {
return loadBeanDefinitions(new EncodedResource(resource));
}
/**
* Load bean definitions from the specified XML file.
* @param encodedResource the resource descriptor for the XML file,
* allowing to specify an encoding to use for parsing the file
* @return the number of bean definitions found
* @throws BeanDefinitionStoreException in case of loading or parsing errors
*/
public int loadBeanDefinitions(EncodedResource encodedResource) throws BeanDefinitionStoreException {
Assert.notNull(encodedResource, "EncodedResource must not be null");
if (logger.isInfoEnabled()) {
logger.info("Loading XML bean definitions from " + encodedResource.getResource());
}
Set<EncodedResource> currentResources = this.resourcesCurrentlyBeingLoaded.get();
if (currentResources == null) {
currentResources = new HashSet<EncodedResource>(4);
this.resourcesCurrentlyBeingLoaded.set(currentResources);
}
if (!currentResources.add(encodedResource)) {
throw new BeanDefinitionStoreException(
"Detected cyclic loading of " + encodedResource + " - check your import definitions!");
}
try {
InputStream inputStream = encodedResource.getResource().getInputStream();
try {
InputSource inputSource = new InputSource(inputStream);
if (encodedResource.getEncoding() != null) {
inputSource.setEncoding(encodedResource.getEncoding());
}
return doLoadBeanDefinitions(inputSource, encodedResource.getResource());
}
finally {
inputStream.close();
}
}
catch (IOException ex) {
throw new BeanDefinitionStoreException(
"IOException parsing XML document from " + encodedResource.getResource(), ex);
}
finally {
currentResources.remove(encodedResource);
if (currentResources.isEmpty()) {
this.resourcesCurrentlyBeingLoaded.remove();
}
}
}分三步:(1)封装资源文件。当进入XmlBeanDefinitionReader后首先对参数Resource使用EncodedResource类进行封装
(2)获取输入流。从Resource中获取对应的InputStream并构造InputSource
(3)通过构造的InputSource实例和Resource实例继续调用函数doLoadBeanDefinitions,
其中核心处理部分doLoadBeanDefinitions(inputSource,encodedResource.getResource())
/**
* Actually load bean definitions from the specified XML file.
* @param inputSource the SAX InputSource to read from
* @param resource the resource descriptor for the XML file
* @return the number of bean definitions found
* @throws BeanDefinitionStoreException in case of loading or parsing errors
*/
protected int doLoadBeanDefinitions(InputSource inputSource, Resource resource)
throws BeanDefinitionStoreException {
try {
int validationMode = getValidationModeForResource(resource);
Document doc = this.documentLoader.loadDocument(
inputSource, getEntityResolver(), this.errorHandler, validationMode, isNamespaceAware());
return registerBeanDefinitions(doc, resource);
}
catch (BeanDefinitionStoreException ex) {
throw ex;
}
catch (SAXParseException ex) {
throw new XmlBeanDefinitionStoreException(resource.getDescription(),
"Line " + ex.getLineNumber() + " in XML document from " + resource + " is invalid", ex);
}
catch (SAXException ex) {
throw new XmlBeanDefinitionStoreException(resource.getDescription(),
"XML document from " + resource + " is invalid", ex);
}
catch (ParserConfigurationException ex) {
throw new BeanDefinitionStoreException(resource.getDescription(),
"Parser configuration exception parsing XML from " + resource, ex);
}
catch (IOException ex) {
throw new BeanDefinitionStoreException(resource.getDescription(),
"IOException parsing XML document from " + resource, ex);
}
catch (Throwable ex) {
throw new BeanDefinitionStoreException(resource.getDescription(),
"Unexpected exception parsing XML document from " + resource, ex);
}
}
其中的3个步骤支撑着Spring容器部分的实现基础:
(1)获取对XML文件的验证模式(int validationMode = getValidationModeForResource(resource))
1、 /**
* Gets the validation mode for the specified {@link Resource}. If no explicit
* validation mode has been configured then the validation mode is
* {@link #detectValidationMode detected}.
* <p>Override this method if you would like full control over the validation
* mode, even when something other than {@link #VALIDATION_AUTO} was set.
*/
protected int getValidationModeForResource(Resource resource) {
int validationModeToUse = getValidationMode();
if (validationModeToUse != VALIDATION_AUTO) {
return validationModeToUse;
}
int detectedMode = detectValidationMode(resource);
if (detectedMode != VALIDATION_AUTO) {
return detectedMode;
}
// Hmm, we didn't get a clear indication... Let's assume XSD,
// since apparently no DTD declaration has been found up until
// detection stopped (before finding the document's root tag).
return VALIDATION_XSD;
}
2、/**
* Detects which kind of validation to perform on the XML file identified
* by the supplied {@link Resource}. If the file has a <code>DOCTYPE</code>
* definition then DTD validation is used otherwise XSD validation is assumed.
* <p>Override this method if you would like to customize resolution
* of the {@link #VALIDATION_AUTO} mode.
*/
protected int detectValidationMode(Resource resource) {
if (resource.isOpen()) {
throw new BeanDefinitionStoreException(
"Passed-in Resource [" + resource + "] contains an open stream: " +
"cannot determine validation mode automatically. Either pass in a Resource " +
"that is able to create fresh streams, or explicitly specify the validationMode " +
"on your XmlBeanDefinitionReader instance.");
}
InputStream inputStream;
try {
inputStream = resource.getInputStream();
}
catch (IOException ex) {
throw new BeanDefinitionStoreException(
"Unable to determine validation mode for [" + resource + "]: cannot open InputStream. " +
"Did you attempt to load directly from a SAX InputSource without specifying the " +
"validationMode on your XmlBeanDefinitionReader instance?", ex);
}
try {
return this.validationModeDetector.detectValidationMode(inputStream);
}
catch (IOException ex) {
throw new BeanDefinitionStoreException("Unable to determine validation mode for [" +
resource + "]: an error occurred whilst reading from the InputStream.", ex);
}
}
4、 /**
* Detect the validation mode for the XML document in the supplied {@link InputStream}.
* Note that the supplied {@link InputStream} is closed by this method before returning.
* @param inputStream the InputStream to parse
* @throws IOException in case of I/O failure
* @see #VALIDATION_DTD
* @see #VALIDATION_XSD
*/
public int detectValidationMode(InputStream inputStream) throws IOException {
// Peek into the file to look for DOCTYPE.
BufferedReader reader = new BufferedReader(new InputStreamReader(inputStream));
try {
boolean isDtdValidated = false;
String content;
while ((content = reader.readLine()) != null) {
content = consumeCommentTokens(content);
if (this.inComment || !StringUtils.hasText(content)) {
continue;
}
if (hasDoctype(content)) {
isDtdValidated = true;
break;
}
if (hasOpeningTag(content)) {
// End of meaningful data...
break;
}
}
return (isDtdValidated ? VALIDATION_DTD : VALIDATION_XSD);
}
catch (CharConversionException ex) {
// Choked on some character encoding...
// Leave the decision up to the caller.
return VALIDATION_AUTO;
}
finally {
reader.close();
}
}
/**
* Does the content contain the the DTD DOCTYPE declaration?
*/
private boolean hasDoctype(String content) {
return content.contains(DOCTYPE);
}
Spring用来检测验证模式的办法就是判断是否包含DOCTYPE,如果包含就是DTD,否则就是XSD
(2)加载XML文件,获取Document(Document doc = this.documentLoader.loadDocument)
/**
* Load the {@link Document} at the supplied {@link InputSource} using the standard JAXP-configured
* XML parser.
*/
public Document loadDocument(InputSource inputSource, EntityResolver entityResolver,
ErrorHandler errorHandler, int validationMode, boolean namespaceAware) throws Exception {
DocumentBuilderFactory factory = createDocumentBuilderFactory(validationMode, namespaceAware);
if (logger.isDebugEnabled()) {
logger.debug("Using JAXP provider [" + factory.getClass().getName() + "]");
}
DocumentBuilder builder = createDocumentBuilder(factory, entityResolver, errorHandler);
return builder.parse(inputSource);
}
其中参数 EntityResolver entityResolver 获得方式
EntityResolver的接口声明为:
public interface EntityResolver {
/**
* Allow the application to resolve external entities.
*
* <p>The parser will call this method before opening any external
* entity except the top-level document entity. Such entities include
* the external DTD subset and external parameter entities referenced
* within the DTD (in either case, only if the parser reads external
* parameter entities), and external general entities referenced
* within the document element (if the parser reads external general
* entities). The application may request that the parser locate
* the entity itself, that it use an alternative URI, or that it
* use data provided by the application (as a character or byte
* input stream).</p>
*
* <p>Application writers can use this method to redirect external
* system identifiers to secure and/or local URIs, to look up
* public identifiers in a catalogue, or to read an entity from a
* database or other input source (including, for example, a dialog
* box). Neither XML nor SAX specifies a preferred policy for using
* public or system IDs to resolve resources. However, SAX specifies
* how to interpret any InputSource returned by this method, and that
* if none is returned, then the system ID will be dereferenced as
* a URL. </p>
*
* <p>If the system identifier is a URL, the SAX parser must
* resolve it fully before reporting it to the application.</p>
*
* @param publicId The public identifier of the external entity
* being referenced, or null if none was supplied.
* @param systemId The system identifier of the external entity
* being referenced.
* @return An InputSource object describing the new input source,
* or null to request that the parser open a regular
* URI connection to the system identifier.
* @exception org.xml.sax.SAXException Any SAX exception, possibly
* wrapping another exception.
* @exception java.io.IOException A Java-specific IO exception,
* possibly the result of creating a new InputStream
* or Reader for the InputSource.
* @see org.xml.sax.InputSource
*/
public abstract InputSource resolveEntity (String publicId,
String systemId)
throws SAXException, IOException;
}
/**
* Return the EntityResolver to use, building a default resolver
* if none specified.
*/
protected EntityResolver getEntityResolver() {
if (this.entityResolver == null) {
// Determine default EntityResolver to use.
ResourceLoader resourceLoader = getResourceLoader();
if (resourceLoader != null) {
this.entityResolver = new ResourceEntityResolver(resourceLoader);
}
else {
this.entityResolver = new DelegatingEntityResolver(getBeanClassLoader());
}
}
return this.entityResolver;
}
其中Spring使用DelegatingEntityResolver类作为this.entityResolver的实现类
/**
* Create a new DelegatingEntityResolver that delegates to
* a default {@link BeansDtdResolver} and a default {@link PluggableSchemaResolver}.
* <p>Configures the {@link PluggableSchemaResolver} with the supplied
* {@link ClassLoader}.
* @param classLoader the ClassLoader to use for loading
* (can be {@code null}) to use the default ClassLoader)
*/
public DelegatingEntityResolver(ClassLoader classLoader) {
this.dtdResolver = new BeansDtdResolver();
this.schemaResolver = new PluggableSchemaResolver(classLoader);
}
@Override
public InputSource resolveEntity(String publicId, String systemId) throws SAXException, IOException {
if (systemId != null) {
if (systemId.endsWith(DTD_SUFFIX)) {
return this.dtdResolver.resolveEntity(publicId, systemId);
}
else if (systemId.endsWith(XSD_SUFFIX)) {
return this.schemaResolver.resolveEntity(publicId, systemId);
}
}
return null;
}
结论清楚明了,DTD用BeansDtdResolver,schema用PluggableSchemaResolver
其中DTD解析为:
public class BeansDtdResolver implements EntityResolver {
private static final String DTD_EXTENSION = ".dtd";
private static final String[] DTD_NAMES = {"spring-beans-2.0", "spring-beans"};
private static final Log logger = LogFactory.getLog(BeansDtdResolver.class);
@Override
public InputSource resolveEntity(String publicId, String systemId) throws IOException {
if (logger.isTraceEnabled()) {
logger.trace("Trying to resolve XML entity with public ID [" + publicId +
"] and system ID [" + systemId + "]");
}
if (systemId != null && systemId.endsWith(DTD_EXTENSION)) {
int lastPathSeparator = systemId.lastIndexOf("/");
for (String DTD_NAME : DTD_NAMES) {
int dtdNameStart = systemId.indexOf(DTD_NAME);
if (dtdNameStart > lastPathSeparator) {
String dtdFile = systemId.substring(dtdNameStart);
if (logger.isTraceEnabled()) {
logger.trace("Trying to locate [" + dtdFile + "] in Spring jar");
}
try {
Resource resource = new ClassPathResource(dtdFile, getClass());
InputSource source = new InputSource(resource.getInputStream());
source.setPublicId(publicId);
source.setSystemId(systemId);
if (logger.isDebugEnabled()) {
logger.debug("Found beans DTD [" + systemId + "] in classpath: " + dtdFile);
}
return source;
}
catch (IOException ex) {
if (logger.isDebugEnabled()) {
logger.debug("Could not resolve beans DTD [" + systemId + "]: not found in class path", ex);
}
}
}
}
}
// Use the default behavior -> download from website or wherever.
return null;
}
@Override
public String toString() {
return "EntityResolver for DTDs " + Arrays.toString(DTD_NAMES);
}
}
Schema解析器为
public PluggableSchemaResolver(ClassLoader classLoader) {
this.classLoader = classLoader;
this.schemaMappingsLocation = DEFAULT_SCHEMA_MAPPINGS_LOCATION;
}
/**
* Loads the schema URL -> schema file location mappings using the given
* mapping file pattern.
* @param classLoader the ClassLoader to use for loading
* (can be {@code null}) to use the default ClassLoader)
* @param schemaMappingsLocation the location of the file that defines schema mappings
* (must not be empty)
* @see PropertiesLoaderUtils#loadAllProperties(String, ClassLoader)
*/
public PluggableSchemaResolver(ClassLoader classLoader, String schemaMappingsLocation) {
Assert.hasText(schemaMappingsLocation, "'schemaMappingsLocation' must not be empty");
this.classLoader = classLoader;
this.schemaMappingsLocation = schemaMappingsLocation;
}
@Override
public InputSource resolveEntity(String publicId, String systemId) throws IOException {
if (logger.isTraceEnabled()) {
logger.trace("Trying to resolve XML entity with public id [" + publicId +
"] and system id [" + systemId + "]");
}
if (systemId != null) {
String resourceLocation = getSchemaMappings().get(systemId);
if (resourceLocation != null) {
Resource resource = new ClassPathResource(resourceLocation, this.classLoader);
try {
InputSource source = new InputSource(resource.getInputStream());
source.setPublicId(publicId);
source.setSystemId(systemId);
if (logger.isDebugEnabled()) {
logger.debug("Found XML schema [" + systemId + "] in classpath: " + resourceLocation);
}
return source;
}
catch (FileNotFoundException ex) {
if (logger.isDebugEnabled()) {
logger.debug("Couldn't find XML schema [" + systemId + "]: " + resource, ex);
}
}
}
}
return null;
}
/**
* Load the specified schema mappings lazily.
*/
private Map<String, String> getSchemaMappings() {
if (this.schemaMappings == null) {
synchronized (this) {
if (this.schemaMappings == null) {
if (logger.isDebugEnabled()) {
logger.debug("Loading schema mappings from [" + this.schemaMappingsLocation + "]");
}
try {
Properties mappings =
PropertiesLoaderUtils.loadAllProperties(this.schemaMappingsLocation, this.classLoader);
if (logger.isDebugEnabled()) {
logger.debug("Loaded schema mappings: " + mappings);
}
Map<String, String> schemaMappings = new ConcurrentHashMap<String, String>(mappings.size());
CollectionUtils.mergePropertiesIntoMap(mappings, schemaMappings);
this.schemaMappings = schemaMappings;
}
catch (IOException ex) {
throw new IllegalStateException(
"Unable to load schema mappings from location [" + this.schemaMappingsLocation + "]", ex);
}
}
}
}
return this.schemaMappings;
}
@Override
public String toString() {
return "EntityResolver using mappings " + getSchemaMappings();
}
}
对不同的验证模式,Spring使用了不同的解析器解析,比如加载DTD类型的BeansDtdResolver的resolveEntity是直接截取systemId最后的xx.dtd然后去当前路径下寻找,而加载XSD类型的PluggableSchemaResolver类的resolveEntity是默认到META-INF/Spring.schemas文件中找到systemId所对应的XSD文件并加载
(3)根据返回的Document注册Bean信息(解析及注册 return registerBeanDefinitions(doc, resource)
当把文件转换成Document后,接下来就是对bean的提取及注册,当程序已经拥有了XML文档文件的Document实例对象时,就会被引入下面这个方法
/**
* Register the bean definitions contained in the given DOM document.
* Called by <code>loadBeanDefinitions</code>.
* <p>Creates a new instance of the parser class and invokes
* <code>registerBeanDefinitions</code> on it.
* @param doc the DOM document
* @param resource the resource descriptor (for context information)
* @return the number of bean definitions found
* @throws BeanDefinitionStoreException in case of parsing errors
* @see #loadBeanDefinitions
* @see #setDocumentReaderClass
* @see BeanDefinitionDocumentReader#registerBeanDefinitions
*/
public int registerBeanDefinitions(Document doc, Resource resource) throws BeanDefinitionStoreException {
// Read document based on new BeanDefinitionDocumentReader SPI.
BeanDefinitionDocumentReader documentReader = createBeanDefinitionDocumentReader();
int countBefore = getRegistry().getBeanDefinitionCount();
documentReader.registerBeanDefinitions(doc, createReaderContext(resource));
return getRegistry().getBeanDefinitionCount() - countBefore;
}
调用
public class DefaultBeanDefinitionDocumentReader implements BeanDefinitionDocumentReader
public void registerBeanDefinitions(Document doc, XmlReaderContext readerContext) {
this.readerContext = readerContext;
logger.debug("Loading bean definitions");
Element root = doc.getDocumentElement();
BeanDefinitionParserDelegate delegate = createHelper(readerContext, root);
preProcessXml(root);
parseBeanDefinitions(root, delegate);
postProcessXml(root);
}解析:BeanDefinitionDocumentReader是一个接口,而实例化的工作是在createBeanDefinitionDocumentReader()中完成的,而通过此方法,BeanDefinitionDocumentReader真正的类型其实已经是DefaultBeanDefinitionDocumentReader了,进入DefaultBeanDefinitionDocumentReader后,发现这个方法的重要目的之一就是提取root,以便于再次将root作为参数继续BeanDefinition的注册
至此已经分析了容器的基本实现,
具体标签的解析过程后续讲解( parseBeanDefinitions(root, delegate);)