介绍几篇使用Transformer结构做医学图像分割的论文:CASTformer(NeuralPS2022),PHNet(arXiv2023)。
Class-Aware Adversarial Transformers for Medical Image Segmentation, NeuralPS2022
解读:NeuraIPS 2022 | 最新类别感知对抗Transformer分割网络CASTformer - 掘金 (juejin.cn)
NeurIPS 2022 | 用于医学图像分割的生成对抗Transformer模型 - 知乎 (zhihu.com)
论文:https://arxiv.org/abs/2201.10737
https://openreview.net/pdf?id=aqLugNVQqRw
代码:未找到
背景介绍: Transformer在医学图像分析领域的建模长距离依赖方面取得了明显进步。
现存问题: 当前基于transformer的模型具有几个缺点:(1)由于naive tokens方案,导致现有方法无法捕获重要特征; (2)模型遭受信息丢失的影响,因为它们仅考虑单尺度特征表示; (3)由于没有考虑丰富的语义环境和解剖学上下文,模型生成的分割图还不够准确。
解决方法: 论文提出CASTformer,一种新型的生成对抗transformer,用于2D医疗图像分割。首先,利用金字塔结构来构建多尺度表示并处理多尺度变化。然后,设计了一种新颖的多尺度transformer模块,以更好地学习具有语义结构的对象区域。最后,采用了一种对抗性训练策略,该策略提高了分割精度,并相应地允许基于transformer的判别器捕获高级语义特征和低级解剖学特征。
CASTformer网络:

CASTformer是基于生成对抗方式训练的,包含一个生成器Generator和一个判别器Discriminator。其中,Generator 是一个基于 Transformer 网络的标准 Encoder-Decoder 架构,包含四个组件:①编码器(特征提取器)模块;②类感知Transformer模块;③Transformer编码器模块;④解码器模块。其中,生成器G共包含四个阶段和四个并行子网,所有阶段共享一个相似的架构,其中包含补丁嵌入层、类感知层以及多个 Transformer 编码器层。
编码器模块。采用CNN-Transformer混合模型设计。这样的设置提供了两个优点:(1)使用卷积主干有助于transformer在下游视觉任务中表现更好;(2)它提供了具有多分辨率特征图,以帮助提高更好的表示。通过这种方式,可以为transformer构造特征金字塔,并利用多尺度特征图用于下游医疗分割任务。借助不同分辨率的特征图,能够对多分辨率的空间局部上下文进行建模。
分层特征表示。深度学习中,浅层特征注重空间细节,高层特征注重语义信息。考虑分层式的特征表示架构,可以获取不同层级所需的上下文。
类感知的transformer模块。

类感知的transformer模块(CAT)旨在适应物体的有用区域(例如,基本的解剖特征和结构信息)。CAT模块具有以下特点:(1)使用4个独立的transformer编码器模块(TEM),将在下面介绍;(3)将M个 CAT模块合并到多尺度表示上,以允许解剖特征的上下文信息传播到表示中。
类感知的transformer模块属于一种迭代优化过程,其原理如下:
- 获取
token序列,其中(n×n) 和 M 是每个特征图上的样本数和总迭代次数;
- 对于给定的给定特征图
,通过将它们与最后一步的估计偏移向量相加来迭代更新其采样位置;
- 采用双线性插值获取最终的采样特征;
最后,再同中间特征一同作为 Transfomer 模块的输入,输出结构化特征序列。
Transformer 编码器模块(TEM).旨在通过从输入图像块嵌入的完整序列中聚合全局上下文信息来对远程上下文信息进行建模。在具体的实现中,Transformer 编码器模块遵循原始 ViT 中的架构,由多头自注意力(MSA)和多层感知机(MLP)块组成。
解码器模块。旨在基于不同分辨率的四个输出特征图生成分割掩码。在实施中,结合了轻量级的全MLP解码器,而这样简单的设计能够更有效地产生强大的表示。解码器包括以下设置:1)多尺度特征的通道维度通过MLP层统一;3)利用MLP层融合串联特征,然后从融合特征中预测多类别分割掩码Y'。
判别网络。将在ImageNet上的预训练R50+VIT-B/16混合模型作为判别器设计的初始化,在这种情况下,使用预训练的策略来有效地学习有限的尺寸目标任务数据。然后,只需应用两层多层感知器(MLP)就可以预测类感知图像的真假。
判别器试图在真实样本和假样本之间进行分类,Generator 和 Discrimitor 通过试图达到 minimax 博弈的平衡点来相互竞争。使用这种结构使鉴别器能够对远距离上下文依赖性进行建模,从而更好地评估医学图像的保真度,这也从本质上赋予了模型对解剖视觉模态(分类特征)的更全面的理解。
损失函数。主要包含两部分,生成器部分是一个标准的医学图像分割网络,同样的也应用了 CE + Dice 损失的组合方式。对抗训练则应用了 WGAN-GP loss。
BCE loss 主要问题是会受到样本不均衡的影响;而 Dice loss 比较适用于样本极度不均的情况,但是在一般的情况下,使用 Dice 损失会对反向传播造成不利的影响,反而容易使训练变得不稳定。因此,通常都会结合两者一起使用。
实验:


A Permutable Hybrid Network for Volumetric Medical Image Segmentation, arXiv2023
解读:2023 港科大医学图像分割新作 | PHNet: 当MLP与CNN巧妙结合会擦出什么火花? - 知乎 (zhihu.com)
论文:https://arxiv.org/abs/2303.13111
代码:未找到
近年来,VIT(Vision Transformer)在3D医学图像分割中取得了实质性进展,多层感知器MLP(Multi-Layer Perceptron)网络由于其与VIT具有相当性的结果而重新受到研究人员的青睐。本文提出了一种用于3D医学图像分割的混合网络PHNet,它利用了卷积神经网络CNN和MLP的优点,通过利用2D和3D CNN提取局部信息,解决了3D volume 数据内在的各向同性问题;此外,本文还提出了一种高效的多层置换感知器模块MLPP,它通过保留位置信息来增强原始的MLP,并获得长程距离依赖。

Transformer的使用取得显著的效果,但计算代价太大, MLP也可以实现特征间的信息交流,以捕获输入数据中的长远距离依赖。然而,MLP在3D医学图像分割方面的有效性仍然缺乏研究。
本文将CNN和MLP相结合,提出了一种新的混合网络PHNet,以实现准确的3D医学图像分割。PHNet采用编码器-解码器结构,其中编码器利用2.5D CNN结构,可以利用医学图像固有的等向性,并通过捕获不同方向上体积医学图像的变化信息密度来避免浅层损失信息。论文进一步提出了MLPP,一种可以在计算效率高的情况下保持位置信息并集成全局相互依赖性的多层排列感知器模块。为了提高计算效率,引入了令牌token组操作,可以高效地在令牌级别上聚合特征映射,从而减少所需的计算量。本文首次提出将CNN和MLP进行结合,并应用于3D医学图像分割。
PHNet架构:

PHNet总体思路:采用编码器-解码器架构,编码器由两个主要组件组成:2.5D卷积模块和多层置换感知器(MLPP)模块。2.5D卷积阶段提取局部特征,输出的特征图传递给MLPP模块以学习全局特征。解码器对分层特征进行处理以进行最终预测。
2.5D Convolution:
本文通过引入卷积层来提取局部特征,3D体积图像如CT和MRI扫描常常由于其厚切片扫描而受到各向异性问题的影响,导致高面内IP分辨率和低面外TP分辨率,这种差异在COVID-19-20中特别明显,其IP分辨率平均为0.74mm,而TP分辨率仅为5mm。为了解决这一问题,本文使用2D卷积块来捕获IP信息,直到特征在三个轴面(横断、冠状和矢状)上形成近似均匀的分辨率,然后使用3D卷积块来处理体素信息。每个编码器层由两个残差卷积块组成,每个块包括两个顺序的Conv-IN-ReLU操作。
Multi-Layer Permute Perceptron (MLPP)
尽管卷积神经网络(CNN)通过深层堆叠卷积层能够建模长距离依赖关系,但研究表明:基于多层感知器MLP的网络在学习全局上下文方面更有效。 因此本文设计了MLPP模块用以提取深层的全局信息。MLPP模块按顺序分解平面内IP特征和垂直方向TP特征的训练。作者分别将这两个块称为IP-MLP和TP-MLP。为了实现跨轴令牌之间的通信,作者还在IP-MLP中提出了一个辅助注意力分支,称为AA-MLP。

IP-MLP:常见MLP方法将输入特征图直接展平成一维向量,会导致卷积特征中的空间信息丢失。为解决这个问题,作者提出一种称为轴向分解的方法,在水平轴、垂直轴和通道轴上分别对输入特征进行单独处理,从而在编码某个轴向信息时保留其他轴向的精确位置信息。

AA-MLP:提出的IP-MLP模块有两个限制,可能会损害分割性能。首先,轴向分解截断了不在相同水平或垂直位置的令牌之间的直接交互。其次,与vanilla MLP相比,令牌分割操作的局部接收字段较小。为了解决这些限制,作者设计了一个辅助分支,以实现轴内令牌通信,并通过轻量级但有效的类MLP架构充当注意力函数。

TP-MLP:通过IP-MLP获取了平面内的信息后,使用TP-MLP来捕捉长期的沿平面垂直方向的特征。

Decoder:
本文的解码器采用纯CNN架构,使用转置卷积逐渐上采样特征映射以匹配输入图像分辨率。在上采样过程之后,使用残差卷积块来细化特征映射。为了进一步提高分割准确性,作者在编码器和解码器之间包括跳跃连接,允许保留low-level的细节信息。
实验:
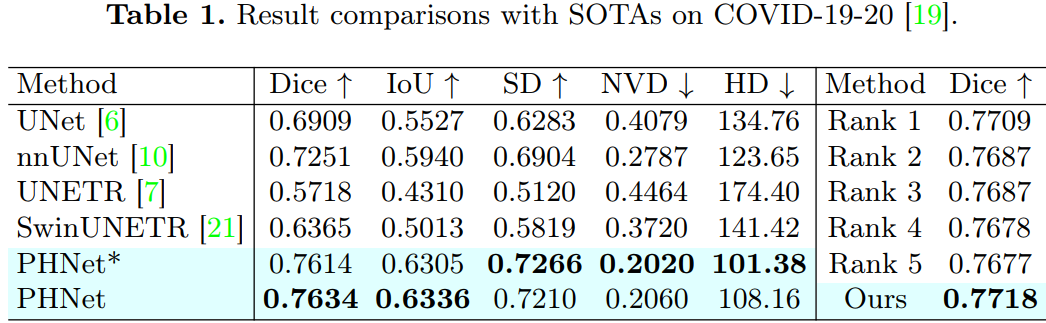


(a)不同结构组合的性能比较,包括在浅层和深层使用 Conv、Attention 和 MLP 的不同组合。在浅层使用 Conv 和在深层使用 MLP 的组合可以获得最佳性能,这与作者的论点相符,即 Conv 擅长提取局部特征,而 MLP 更有效地模拟长程依赖。
(b)比较不同 MLP 设计的性能,包括 MLP-Mixer(M),ShiftMLP(S) 和 WaveMLP(W)。
(c)不同分段长度 L 对性能的影响。将分段长度设置为宽度(W)的不同比例,即 1、1/2、1/3 和 1/4。这有利于不同大小的感兴趣区域(ROI)。当 L = 1/2 W 时,性能最佳。
(d) MLP 层数的影响。在 MLP 层数为 2 时,性能最佳。