前言
李沐大神源代码是用Jupyter写的,笔者想用Pycharm实现并仅作为学习笔记,如有侵权,请联系笔者删除。
一、Dropout丢弃法
Dropout,通过在层之间加入噪音,达到正则化的目的,一般作用在隐藏全连接层的输出上,通过将输出项随机置0来控制模型复杂度,如下图。需要注意的是,并不是把节点删掉,因为下一次迭代很有可能置0的项又会被重启。
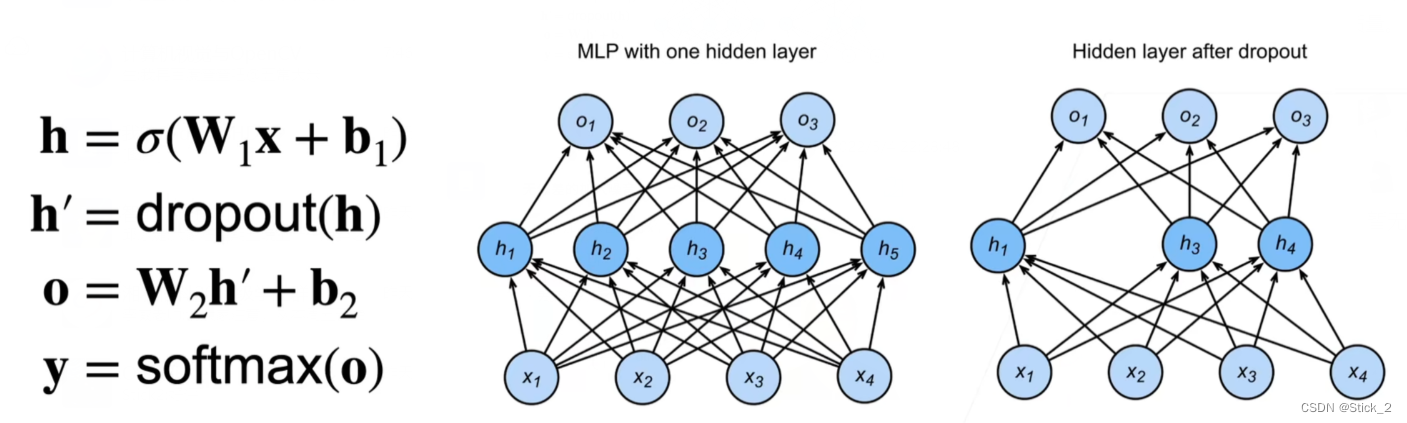
如何实现Dropout如下,下面的x为一层到下一层之间的输出,因为要在层之间加入噪音,但又不希望改变数据的期望,所以不被置0的项需要除以(1-p),这里的丢弃概率p是一个超参数,推导在下图沐神手写的公式中。

二、Dropout的实现
python版本:3.8.6
torch版本:1.11.0
d2l版本:0.17.5
import torch
from torch import nn
from d2l import torch as d2l
def dropout_layer(X, dropout):
assert 0 <= dropout <= 1
# 在本情况中,所有元素都被丢弃
if dropout == 1:
return torch.zeros_like(X)
# 在本情况中,所有元素都被保留
if dropout == 0:
return X
mask = (torch.rand(X.shape) > dropout).float() # 意思就是
return mask * X / (1.0 - dropout)
num_inputs, num_outputs, num_hiddens1, num_hiddens2 = 784, 10, 256, 256
# 网络各层分布为:784*256*256*10,两个隐藏层大小都是256
dropout1, dropout2 = 0.2, 0.5
# 创建网络
class Net(nn.Module):
def __init__(self, num_inputs, num_outputs, num_hiddens1, num_hiddens2,
is_training = True):
super(Net, self).__init__()
self.num_inputs = num_inputs
self.training = is_training
self.lin1 = nn.Linear(num_inputs, num_hiddens1)
self.lin2 = nn.Linear(num_hiddens1, num_hiddens2)
self.lin3 = nn.Linear(num_hiddens2, num_outputs)
self.relu = nn.ReLU()
def forward(self, X):
H1 = self.relu(self.lin1(X.reshape((-1, self.num_inputs))))
# 只有在训练模型时才使用dropout
if self.training == True:
# 在第一个全连接层之后添加一个dropout层
H1 = dropout_layer(H1, dropout1) # dropout1=0.2
H2 = self.relu(self.lin2(H1))
if self.training == True:
# 在第二个全连接层之后添加一个dropout层
H2 = dropout_layer(H2, dropout2) # dropout2=0.5
out = self.lin3(H2)
return out
net = Net(num_inputs, num_outputs, num_hiddens1, num_hiddens2)
num_epochs, lr, batch_size = 10, 0.5, 256
loss = nn.CrossEntropyLoss(reduction='none') # 交叉熵损失函数
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size) # 训练数据和测试数据都是256的大小
trainer = torch.optim.SGD(net.parameters(), lr=lr) # 随机梯度下降
d2l.train_ch3(net, train_iter, test_iter, loss, num_epochs, trainer)
d2l.plt.show()
上面网络结构中两个隐藏层后面都有Dropout层,Dropout1的丢失概率为0.2,Dropout2的丢失概率0.5
二、Dropout不同丢失概率的结果对比
2.1 原始输入,Dropout1=0.2,Dropout2=0.5:
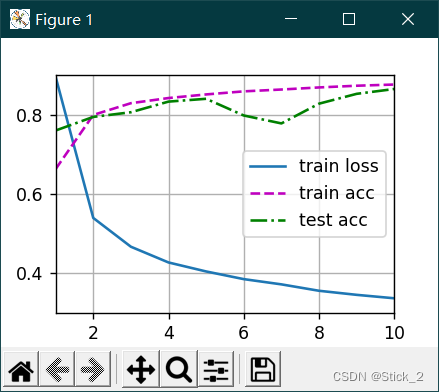
2.2 Dropout1=0,Dropout2=0,就是相当于没有添加Dropout:

与上一结果对比可以看到,不用Dropout时,训练损失虽然低一些,但测试准确率也低一些,说明Dropout有起到防止过拟合的作用。
2.3 Dropout1=0.9,Dropout2=0.9

结果竟然报错,那让我们来看看玄机,跳转到 torch.py 中一看究竟:

可以发现,torch设置了异常处理,当训练损失小于0.5时才会继续往下,否则中止程序,并且抛出当前训练损失,现在看一下之前的训练损失:
竟然有1.98!!!,触发了异常开关,当然是报错了。那原因我也在沐神的QA环节中大概找到了,就是:比较大的丢弃概率适用于那些特别复杂的(相比于数据)模型,这里可能说模型对于数据不是那么的复杂,所以丢弃概率高了之后,模型很难收敛,也就训练不下去了。