视觉激光融合——VLOAM / LIMO算法解析
视觉激光融合——VLOAM / LIMO算法解析
在激光SLAM领域,LOAM、Lego-LOAM属于纯激光领域,除此之外还衍生处理视觉激光结合、激光IMU结合,甚至三者结合的算法,本篇博客介绍的VLOAM和LIMO算法就是属于视觉和激光结合的算法,其中VLOAM算法更偏向于是一种激光SLAM算法,而LIMO算法更偏向于是一种视觉SLAM算法,具体地如下:
1. VLOAM算法
VLOAM算法是在2015年ICRA上提出的,但至今在KITTI榜的Odometry数据集上成绩仍然靠前
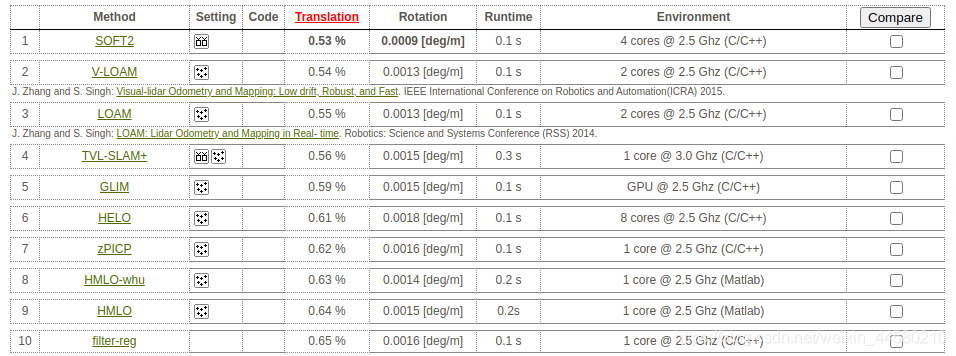
VLOAM原论文名为《Visual-lidar Odometry and Mapping: Low-drift, Robust, and Fast》,作者并没有对代码进行开源,复现的版本有两个,分别是YukunXia/VLOAM-CMU-16833和Jinqiang/demo_lidar,其中,前者是在去年CMU的几位大佬在A-LOAM代码基础上进行改进的,并通过报告对结果进行了详细的分析,本博客就是在此基础上VLOAM的原理和代码进行简单总结。
对A-LOAM还不了解的同学可以参考下博客学习LOAM笔记——特征点提取与匹配
1.1 总体框架
VLOAM算法的总体框架如下:
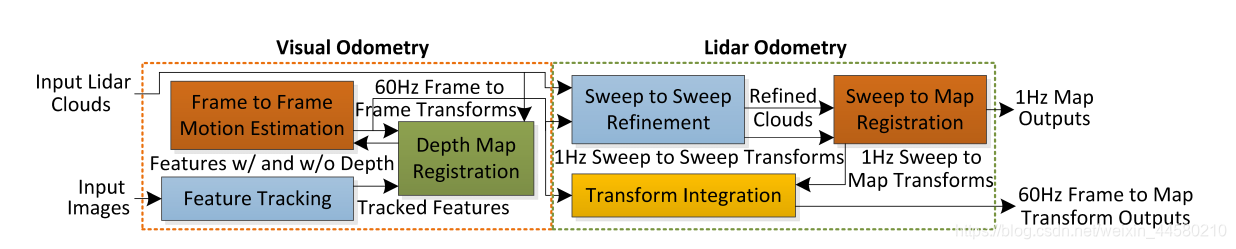
VLOAM算法整体分为视觉里程计VO和激光里程计LO两部分,视觉里程计以60HZ的频率运行,视觉里程计通过激光获一部分视觉特征点的深度,其输出位姿变换积分后为帧间变换估计(Sweep to Sweep Refinement)提供先验,而激光里程计以1HZ进行帧间变换估计以及帧到地图的位姿估计(Sweep to Map Registraion),并最终融合视觉里程计的60Hz输出和激光里程计的1Hz输出作为最终的60Hz输出,可看出来,VLOAM主要有如下特点:
- 核心其实以LOAM为基础的激光里程计,视觉里程计仅仅是提供了先验,视觉里程计完全可以由IMU或者其他高频里程计代替;
- 视觉里程计的优势是可以提供高频输出,但是没有尺度且对于光照、纹理等要求比较强,激光里程计的优势是对环境要求较低并可以构建地图,但是输出频率较低,因此从某种成都上说VLOAM算法正式很好地利用了他们的特点进行了互补才达到相对较好的效果;
下面具体分析下各个部分的算法
1.2 视觉里程计
VLOAM视觉里程计中追踪部分没啥特别的,使用光流法或者特征点匹配都可以,较为特别的一点是VLOAM使用激光来恢复视觉特征点的深度(在图像系下寻找最近的三个激光点拟合平面或者求均值,在后面LIMO算法中详细介绍),从而获得了具备深度的特征点 X i k = [ x i k , y i k , z i k ] T \mathbf{X}_{i}^{k}=\left[\begin{array}{lll}x_{i}^{k}, & y_{i}^{k}, & z_{i}^{k}\end{array}\right]^{T} Xik=[xik,yik,zik]T以及不具备深度的特征点 X ^ i k = [ x ^ i k , y ^ i k , z ^ i k ] T \hat{\mathbf{X}}_{i}^{k}=\left[\begin{array}{lll}\hat{x}_{i}^{k}, & \hat{y}_{i}^{k}, & \hat{z}_{i}^{k}\end{array}\right]^{T} X^ik=[x^ik,y^ik,z^ik]T两种类型,前后帧匹配特征点均满足变换方程 X i k + 1 = R X i k + T \mathbf{X}_{i}^{k+1}=\mathbf{R} \mathbf{X}_{i}^{k}+\mathbf{T} Xik+1=RXik+T
对于具备深度的点:
对于前一帧有深度的点,下一帧未必有深度,因此我们可以总是假设下一帧该点无法通过激光获得该点深度,有 X i k + 1 = d i k + 1 X ^ i k + 1 \mathbf{X}_{i}^{k+1}=d_{i}^{k+1} \hat{\mathbf{X}}_{i}^{k+1} Xik+1=dik+1X^ik+1,其中 d i k + 1 d_{i}^{k+1} dik+1是下一帧该点假设深度,通过联立该方程和变换方程, 并消除 d i k + 1 d_{i}^{k+1} dik+1就可以获得如下方程组 ( z ^ i k + 1 R 1 − x ^ i k + 1 R 3 ) X i k + z ^ i k + 1 T 1 − x ^ i k + 1 T 3 = 0 \left(\hat{z}_{i}^{k+1} \mathbf{R}_{1}-\hat{x}_{i}^{k+1} \mathbf{R}_{3}\right) \mathbf{X}_{i}^{k}+\hat{z}_{i}^{k+1} T_{1}-\hat{x}_{i}^{k+1} T_{3}=0 (z^ik+1R1−x^ik+1R3)Xik+z^ik+1T1−x^ik+1T3=0 ( z ^ i k + 1 R 2 − y ^ i k + 1 R 3 ) X i k + z ^ i k + 1 T 2 − y ^ i k + 1 T 3 = 0 \left(\hat{z}_{i}^{k+1} \mathbf{R}_{2}-\hat{y}_{i}^{k+1} \mathbf{R}_{3}\right) \mathbf{X}_{i}^{k}+\hat{z}_{i}^{k+1} T_{2}-\hat{y}_{i}^{k+1} T_{3}=0 (z^ik+1R2−y^ik+1R3)Xik+z^ik+1T2−y^ik+1T3=0其中 R 1 R 2 , R 3 \mathbf{R}_{1}\,\mathbf{R}_{2},\mathbf{R}_{3} R1R2,R3分别为旋转矩阵的第一、第二和第三行, T 1 , T 2 , T 3 T_{1},T_{2},T_{3} T1,T2,T3分别为平移向量的第一、第二和第三行。
对于不具备深度的点
我们有 d i k X ^ i k d_{i}^{k} \hat{\mathbf{X}}_{i}^{k} dikX^ik和 d i k + 1 X ^ i k + 1 d_{i}^{k+1} \hat{\mathbf{X}}_{i}^{k+1} dik+1X^ik+1,其中 d i k d_{i}^{k} dik和 d i k + 1 d_{i}^{k+1} dik+1为当前帧和下一帧该点假设深度,我们同样将该方程与变换方程联立,通过消除 d i k d_{i}^{k} dik和 d i k + 1 d_{i}^{k+1} dik+1得到 [ − y ^ i k + 1 T 3 + z ^ i k + 1 T 2 − x ^ i k + 1 T 3 − z ^ i k + 1 T 1 − x ^ i k + 1 T 2 + y ^ i k + 1 T 1 ] R X ^ i k = 0 \left[\begin{array}{c} -\hat{y}_{i}^{k+1} T_{3}+\hat{z}_{i}^{k+1} T_{2} \\ -\hat{x}_{i}^{k+1} T_{3}-\hat{z}_{i}^{k+1} T_{1} \\ -\hat{x}_{i}^{k+1} T_{2}+\hat{y}_{i}^{k+1} T_{1} \end{array}\right] \mathbf{R} \hat{\mathbf{X}}_{i}^{k}=0 ⎣⎡−y^ik+1T3+z^ik+1T2−x^ik+1T3−z^ik+1T1−x^ik+1T2+y^ik+1T1⎦⎤RX^ik=0在论文中推导的都是解析解的计算方式,而在基于Ceres复现的代码中分别实现了3D-3D,3D-2D,2D-3D,2D-2D四种特征点基于优化的求解运算并在报告中做了对比,对于具备深度的点,也就是3D-2D的情况,残差构建就是将前一帧具备深度的点变换到后一帧坐标系下,并在归一化平面上构建X方向和Y方向的残差,如下:
struct CostFunctor32
{
// 32 means 3d - 2d observation pair
CostFunctor32(double observed_x0, double observed_y0, double observed_z0, double observed_x1_bar,
double observed_y1_bar)
: // TODO: check if const & is necessary
observed_x0(observed_x0)
, observed_y0(observed_y0)
, observed_z0(observed_z0)
, // 3
observed_x1_bar(observed_x1_bar)
, observed_y1_bar(observed_y1_bar)
{
} // 2
template <typename T>
bool operator()(const T* const angles, const T* const t, T* residuals) const
{
T X0[3] = {
T(observed_x0), T(observed_y0), T(observed_z0) };
T observed_x1_bar_T = T(observed_x1_bar);
T observed_y1_bar_T = T(observed_y1_bar);
T R_dot_X0[3];
ceres::AngleAxisRotatePoint(angles, X0, R_dot_X0);
R_dot_X0[0] += t[0];
R_dot_X0[1] += t[1];
R_dot_X0[2] += t[2];
residuals[0] = R_dot_X0[0] - R_dot_X0[2] * observed_x1_bar_T;
residuals[1] = R_dot_X0[1] - R_dot_X0[2] * observed_y1_bar_T;
return true;
}
对于不具备深度的点,也就是2D-2D的情况,残差构建就是将前一帧不具备深度点变换到后一帧后构建一维投影残差(点积),这和我们平常求解基础矩阵后者本质矩阵的方法是不太一样的,为啥这样做呢,我的理解是需要和具备深度点求解的变换保证在同一尺度下?我不是特别确定,具体如下:
struct CostFunctor22
{
// 22 means 2d - 2d observation pair
CostFunctor22(double observed_x0_bar, double observed_y0_bar, double observed_x1_bar, double observed_y1_bar)
: // TODO: check if const & is necessary
observed_x0_bar(observed_x0_bar)
, observed_y0_bar(observed_y0_bar)
, // 2
observed_x1_bar(observed_x1_bar)
, observed_y1_bar(observed_y1_bar)
{
} // 2
template <typename T>
bool operator()(const T* const angles, const T* const t, T* residuals) const
{
T observed_X0_bar_T[3] = {
T(observed_x0_bar), T(observed_y0_bar), T(1.0) };
T observed_X1_bar_T[3] = {
T(observed_x1_bar), T(observed_y1_bar), T(1.0) };
T observed_X0_bar_T_to1[3];
ceres::AngleAxisRotatePoint(angles, observed_X0_bar_T, observed_X0_bar_T_to1);
T t_cross_observed_X0_bar_T_to1[3];
ceres::CrossProduct(t, observed_X0_bar_T_to1, t_cross_observed_X0_bar_T_to1);
residuals[0] = ceres::DotProduct(observed_X1_bar_T, t_cross_observed_X0_bar_T_to1);
return true;
}
static ceres::CostFunction* Create(const double observed_x0_bar, const double observed_y0_bar,
const double observed_x1_bar, const double observed_y1_bar)
{
return (new ceres::AutoDiffCostFunction<CostFunctor22, 1, 3, 3>(
new CostFunctor22(observed_x0_bar, observed_y0_bar, observed_x1_bar, observed_y1_bar)));
}
double observed_x0_bar, observed_y0_bar, observed_x1_bar, observed_y1_bar;
// TODO: check if the repeated creations of cost functions will decreases the performance?
};
1.3 激光里程计
VLOAM激光里程计和LOAM是几乎一致的,在作者的代码实现中也是直接复用了A-LOAM的代码,唯一可能有一些区别的是在Sweep to Sweep Refinement的频率是1Hz,并且是使用视觉里程计积分获得先验。
1.4 实验结果
在复现代码的报告中也对算法精度进行了详细的评估, 如下表所示:
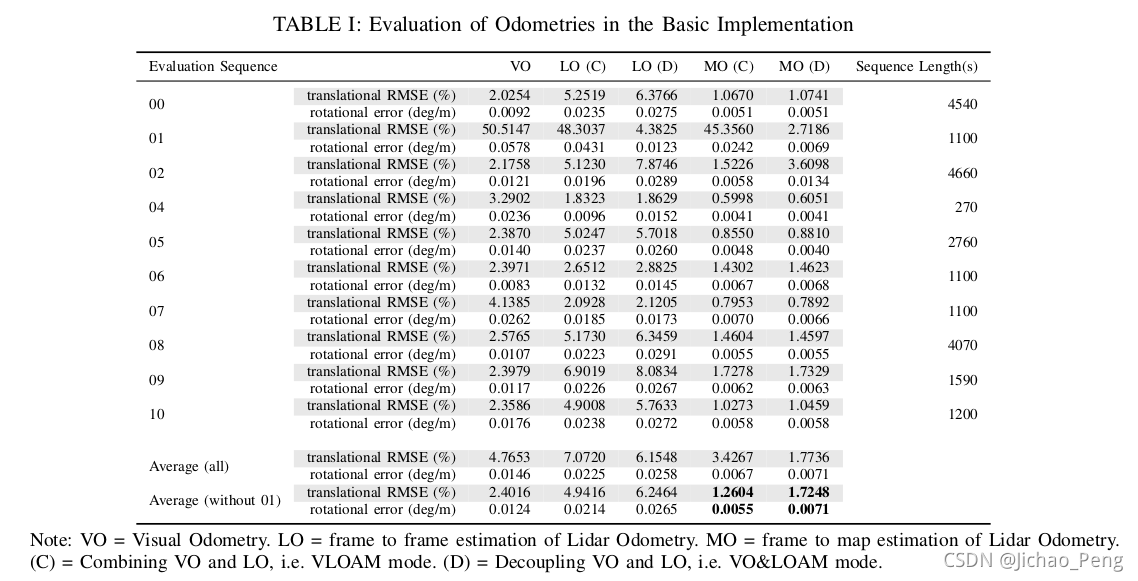
上表中,LO表示只是通过Sweep to Sweep Refinement计算激光里程计,MO表示Sweep to Map计算激光里程计,(D)表示不使用视觉里程计作为激光里程计的先验,(D)表示使用视觉里程计作为激光里程计的先验,也就是VLOAM算法,从表中平均值可以看到VLOAM算法的确是所有算法里误差最小的,但是,01数据集上也有例外,在视觉里程计失效的情况下整个VLOAM算法也会失效,这也是VLOAM算法的弊端,以上就是对VLOAM算法的简单总结,对该算法感兴趣的同学推荐读一下原Paper以及复现代码的报告。
2. LIMO算法
LIMO算法2018年发表在IROS会议,原论文名为《LIMO: LiDAR-Monocular Visual Odometry》,该论文是有开源的johannes-graeter/limo,该算法我并没有阅读源码,而是通过其他论文博客对该算法进行了一些初步了解,简单总结如下
2.1 总体框架
LIMO算法的总体框架如下:

从上图中可以看出,LIMO算法框架主要包括特征提取、特征预处理、帧间运动估计、尺度估计、BA和回环检测,整体上就是一个完整的VSLAM的算法框架,区别较大的地方就是接入了激光进行尺度估计,原论文中也指出,作者是想要组合激光准确的深度估计和相机的强大特征追踪能力,换句话说,LIMO就是一种激光深度增强的VSLAM算法。
下面我主要简单介绍下LIMO是如何进行尺度估计以及后端优化的
2.2 尺度估计
所谓尺度估计就是指通过激光来恢复视觉特征点的深度
首先将激光点云投影到对应的相机坐标系中,然后对每个特征点,执行如下步骤:
- 首先寻找该特征点周围的矩形框内的激光点;
- 然后对这些激光点按照深度进行划分;
- 寻找最靠近该特征点的深度区间的点云,拟合平面;
- 我们认为该特征点位于该平面上,根据光心和特征点的连线与平面的交点记为该特征点的深度;
- 检测估计深度的准确性:光心和特征点连线与平面的夹角必须小于某个阈值,并拒绝深度高于30m的特征点。
对于地面上的特征点进行特殊处理。首先从激光点云中提取地面,然后直接利用地面点云拟合平面,而不需要第2和第3步。该方法和VLOAM应该是大同小异。
2.3 帧间估计与后端优化
LIMO的帧间估计和VLOAM中的视觉里程计类似,也是将特征点分为具备深度的特征点和不具备深度的特征点,整体的
残差计算公式如下: argmin x , y , z , α , β , γ ∑ i ρ 3 d → 2 d ( ∥ φ i , 3 d → 2 d ∥ 2 2 ) + ρ 2 d → 2 d ( ∥ φ i , 2 d → 2 d ∥ 2 2 ) \underset{x, y, z, \alpha, \beta, \gamma}{\operatorname{argmin}} \sum_{i} \rho_{3 d \rightarrow 2 d}\left(\left\|\varphi_{i, 3 d \rightarrow 2 d}\right\|_{2}^{2}\right)+\rho_{2 d \rightarrow 2 d}\left(\left\|\varphi_{i, 2 d \rightarrow 2 d}\right\|_{2}^{2}\right) x,y,z,α,β,γargmini∑ρ3d→2d(∥φi,3d→2d∥22)+ρ2d→2d(∥φi,2d→2d∥22)其中 φ i , 3 d → 2 d = p ˉ i − π ( p i , P ( x , y , z , α , β , γ ) ) \varphi_{i, 3 d \rightarrow 2 d}=\bar{p}_{i}-\pi\left(p_{i}, P(x, y, z, \alpha, \beta, \gamma)\right) φi,3d→2d=pˉi−π(pi,P(x,y,z,α,β,γ)) φ i , 2 d → 2 d = p ˉ i F ( x z , y z , α , β , γ ) p ~ i \varphi_{i, 2 d \rightarrow 2 d}=\bar{p}_{i} F\left(\frac{x}{z}, \frac{y}{z}, \alpha, \beta, \gamma\right) \tilde{p}_{i} φi,2d→2d=pˉiF(zx,zy,α,β,γ)p~i通过公式看出来,具备深度的特征点构建的PnP问题,即将前一帧三维空间点投影到后一帧二维平面上,并与对应特征点构建距离残差,而不具备深度的特征点构建的极线约束问题,即通过基本矩阵约束,这和前面提到VLOAM中构建的方法不同也更为常见。
对于后端优化,实际上就是构建了一个基于滑窗的BA问题,具体形式为: argmin P j ∈ P , l i ∈ L , d i ∈ D w 0 ∥ ν ( P 1 , P 0 ) ∥ 2 2 + ∑ i ∑ j w 1 ρ ϕ ( ∥ ϕ i , j ( l i , P i ) ∥ 2 2 ) + w 2 ρ ξ ( ∥ ξ i , j ( l i , P j ) ∥ 2 2 ) \operatorname{argmin}_{P_{j} \in \mathcal{P}, l_{i} \in \mathcal{L}, d_{i} \in \mathcal{D}} w_{0}\left\|\nu\left(P_{1}, P_{0}\right)\right\|_{2}^{2}+\sum_{i} \sum_{j} w_{1} \rho_{\phi}\left(\left\|\phi_{i, j}\left(l_{i}, P_{i}\right)\right\|_{2}^{2}\right)+w_{2} \rho_{\xi}\left(\left\|\xi_{i, j}\left(l_{i}, P_{j}\right)\right\|_{2}^{2}\right) argminPj∈P,li∈L,di∈Dw0∥ν(P1,P0)∥22+i∑j∑w1ρϕ(∥ϕi,j(li,Pi)∥22)+w2ρξ(∥ξi,j(li,Pj)∥22)第一项 ν ( P 1 , P 0 ) = ∥ translation ( P 0 − 1 P 1 ) ∥ 2 2 − s \nu\left(P_{1}, P_{0}\right)=\| \text { translation }\left(P_{0}^{-1} P_{1}\right) \|_{2}^{2}-s ν(P1,P0)=∥ translation (P0−1P1)∥22−s表达是滑窗中最旧的两帧之间的平移不能变化过大, s s s为该两帧优化前的平移值
第二项 ϕ i , j ( l i , P j ) = l ˉ i , j − π ( l i , P j ) \phi_{i, j}\left(l_{i}, P_{j}\right)=\bar{l}_{i, j}-\pi\left(l_{i}, P_{j}\right) ϕi,j(li,Pj)=lˉi,j−π(li,Pj)指的是滑窗中的特征点在图像上的重投影误差
第三项 ξ i , j ( l i , P j ) = d ^ i , j − [ 0 0 1 ] τ ( l i , P j ) \xi_{i, j}\left(l_{i}, P_{j}\right)=\hat{d}_{i, j}-\left[\begin{array}{lll} 0 & 0 & 1 \end{array}\right] \tau\left(l_{i}, P_{j}\right) ξi,j(li,Pj)=d^i,j−[001]τ(li,Pj)即对于有深度的点进行深度约束,即优化后的点的深度和估计的深度差距不能过大,以上就是帧间约束和后端优化的基本介绍
2.4 实验结果
在原论文中,对算法效果进行了评估对比:

通过对比可以看到,加入激光进行深度估计的相对原始的视觉里程计在效果上确实有明显提升,但是算法整体精度相对VLOAM并没那么高,毕竟是基于视觉的里程计算法,在KITTI的Odometry榜上排在40+
以上就完成VLOAM和LIMO两种视觉激光融合的定位算法的介绍,就我目前了解,除了VLOAM(如果算)之外,目前还没有特别成熟视觉和激光的紧耦合框架,如果有知道的小伙伴欢迎评论区交流
此外,对其他SLAM算法感兴趣的同学可以看考我的博客SLAM算法总结——经典SLAM算法框架总结