参考链接:深度学习-经典网络——归纳总结
参考链接:手把手教你搭建LeNet-5网络模型
卷积神经网络(Convolutional Neural Network,CNN)
CNN的组成部分
卷积神经网络CNN(Convolutional Neural Network),是一类深度神经网络,最常用于分析视觉图像。一个卷积神经网络通常包括输入输出层和多个隐藏层,隐藏层通常包括卷积层和RELU层(即激活函数)、池化层、全连接层和归一化层等。
1. 输入层
CNN的输入一般是二维向量,可以有高度,比如,RGB图像。
2.卷积层
卷积层是CNN的核心,层的参数由一组可学习的滤波器(filter)或内核(kernels)组成,它们具有小的感受野,延伸到输入容积的整个深度。卷积层的作用是对输入层进行卷积,提取更高层次的特征。
3.池化层
池化层(又称为下采样),它的作用是减小数据处理量同时保留有用信息,使网络结构需要更少的参数就能处理图像,池化层的作用可以描述为模糊图像,丢掉了一些不是那么重要的特征。池化层一般包括均值池化、最大池化、高斯池化、可训练池化等。
4.激活层
激活层主要是把卷积层输出结果做非线性映射,常用的激活函数有ReLU、sigmoid、tanh、LeakyReLU等。
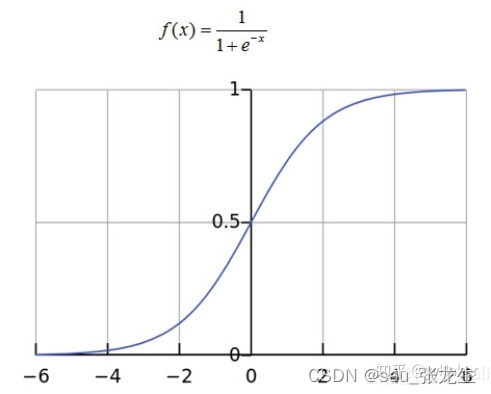
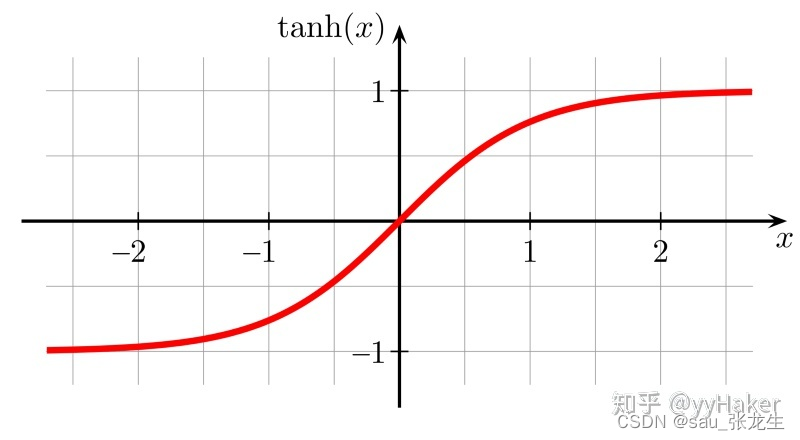
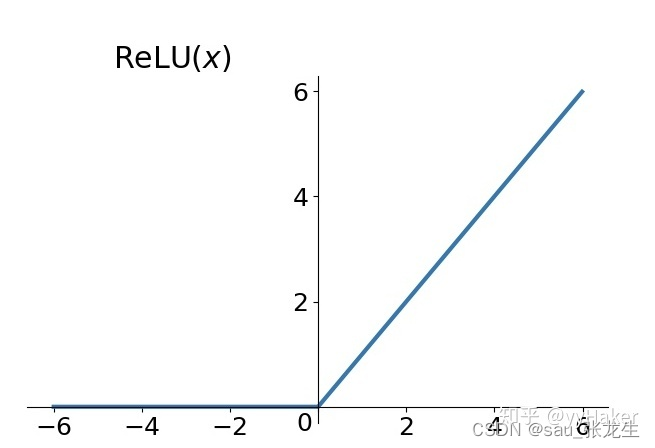
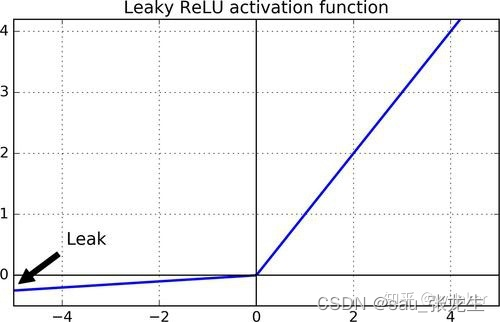
5.全连接层
全连接层是一个常规的神经网络,它的作用是对经过多次卷积层和多次池化层所得出来的高级特征进行全连接(全连接就是常规神经网络的性质),算出最后的预测值。
6.输出层
输出层输出对结果的预测值,一般会加一个softmax层。
LeNet-5
LeNet5结构
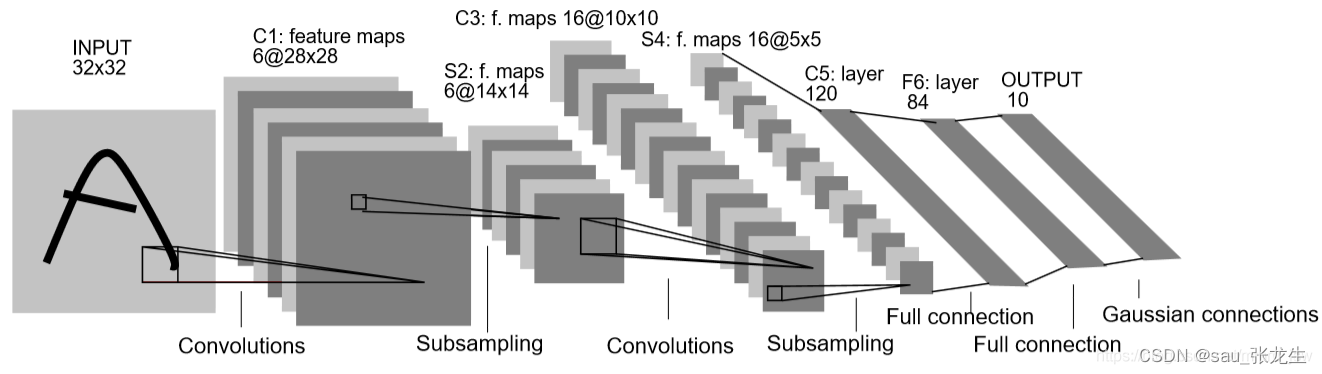
LeNet5网络结构很小,但同样具有深度学习的基本模块:卷积层、池化层、全连接层。LeNet5共有七层,不包含输入,每层都包含可训练参数,每个层有多个Feature Map,每个Feature Map通过一种卷积滤波器提取输入的一种特征,然后每Feature Map有多个神经元。
输入: 32 ∗ 32 32*3232∗32的手写字体图片,这些手写字体包含0-9数字,也就是相当于10个类别的图片。
输出: 分类结果,0-9之间的一个数(softmax)
典型的LeNet-5结构包含卷积层(CONV layer),池化层(POOL layer)和全连接层(FC layer),排列顺序一般为CONV layer ⟹POOL layer ⟹CONV layer POOL layer ⟹FC layer ⟹FC layer ⟹OUTPUT layer。一个或多个卷积层后面跟着一个池化层的模式至今仍十分常用。
各层结构及参数
import torch
from torch import nn
# 定义一个网络模型
class MyLeNet5(nn.Module):
# 初始化网络
def __init__(self):
super(MyLeNet5, self).__init__()
self.c1 = nn.Conv2d(in_channels=1, out_channels=6, kernel_size=5, padding=2)
self.Sigmoid = nn.Sigmoid()
self.s2 = nn.AvgPool2d(kernel_size=2, stride=2)
self.c3 = nn.Conv2d(in_channels=6, out_channels=16, kernel_size=5)
self.s4 = nn.AvgPool2d(kernel_size=2, stride=2)
self.c5 = nn.Conv2d(in_channels=16, out_channels=120, kernel_size=5)
self.flatten = nn.Flatten()
self.f6 = nn.Linear(120, 84)
self.output = nn.Linear(84, 10)
def forward(self, x):
x = self.Sigmoid(self.c1(x))
x = self.s2(x)
x = self.Sigmoid(self.c3(x))
x = self.s4(x)
x = self.c5(x)
x = self.flatten(x)
x = self.f6(x)
x = self.output(x)
return x
if __name__ == "__main__":
x = torch.rand(1, 1, 28, 28)
model = MyLeNet5()
y = model(x)
c1(卷积层)
选取5∗5卷积核(不包含偏置),得到6通道特征图,每个特征图的大小为32 − 5 + 1 = 28 。
s2(池化层)
池化层是一个下采样层,有6个14∗14 的特征图,特征图中的每个单元与C1中相对应特征图的2∗2邻域连接。S2层每个单元对应C1中4个求和,乘以一个可训练参数,再加上一个可训练偏置。
c3(卷积层)
卷积核大小为5∗5,得到新的特征图大小为10∗10
S4(池化层)
窗口大小为2 ∗ 2 2*22∗2,有16个特征图
C5(卷积层)
总共120个feature map,每个feature map与S4层所有的feature map相连接,卷积核大小为5∗5
F6(全连接层)
F6相当于MLP(Multi-Layer Perceptron,多层感知机)中的隐含层,有84个节点。
Output(输出层)
全连接层,共有10个节点
train.py
import torch
from torch import nn
from lenet import MyLeNet5
from torch.optim import lr_scheduler
from torchvision import datasets, transforms
import os
# 数据转化为tensor格式
data_transform = transforms.Compose([
transforms.ToTensor()
])
# 加载训练的数据集
train_dataset = datasets.MNIST(root="./data", train=True, transform=data_transform, download=True)
train_dataloader = torch.utils.data.DataLoader(dataset=train_dataset, batch_size=16, shuffle=True)
# 加载测试数据集
test_dataset = datasets.MNIST(root="./data", train=False, transform=data_transform, download=True)
test_dataloader = torch.utils.data.DataLoader(dataset=test_dataset, batch_size=16, shuffle=True)
# 如果有显卡,可以转到GPU
device = "cuda" if torch.cuda.is_available() else "cpu"
# 调用lenet里的模型,将模型数据转到GPU
model = MyLeNet5().to(device)
# 定义一个损失函数(交叉熵损失)
loss_fn = nn.CrossEntropyLoss()
# 定义一个优化器,随机梯度下降
optimizer = torch.optim.SGD(model.parameters(), lr=1e-3, momentum=0.9)
# 学习率每隔10轮,变为原来的0.1
lr_scheduler = lr_scheduler.StepLR(optimizer, step_size=10, gamma=0.1)
# 定义训练函数
def train(dataloader, model, loss_fn, optimizer):
loss, current, n = 0.0, 0.0, 0
for batch, (X, y) in enumerate(dataloader):
# 前向传播
X, y = X.to(device), y.to(device)
output = model(X)
cur_loss = loss_fn(output, y)
_, pred = torch.max(output, axis=1)
cur_acc = torch.sum(y == pred) / output.shape[0]
optimizer.zero_grad()
cur_loss.backward()
optimizer.step()
loss += cur_loss.item()
current += cur_acc.item()
n = n + 1
print("train_loss" + str(loss / n))
print("train_acc" + str(current / n))
def val(dataloader, model, loss_fn):
model.eval()
loss, current, n = 0.0, 0.0, 0
with torch.no_grad():
for batch, (X, y) in enumerate(dataloader):
# 前向传播
X, y = X.to(device), y.to(device)
output = model(X)
cur_loss = loss_fn(output, y)
_, pred = torch.max(output, axis=1)
cur_acc = torch.sum(y == pred) / output.shape[0]
loss += cur_loss.item()
current += cur_acc.item()
n = n + 1
print("val_loss" + str(loss / n))
print("val_acc" + str(current / n))
return current/n
# 开始训练
epoch = 50
min_acc = 0
for t in range(epoch):
print(f"epoch{t + 1}\n----------------")
train(train_dataloader, model, loss_fn, optimizer)
a = val(test_dataloader, model, loss_fn)
# 保存最好的模型权重
if a > min_acc:
folder = "save_model"
if not os.path.exists(folder):
os.mkdir("save_model")
min_acc = a
print("save best model")
torch.save(model.state_dict(), "save_model/best_model.pth")
print("Done!")
test.py
import torch
from lenet import MyLeNet5
from torch.autograd import Variable
from torchvision import datasets, transforms
from torchvision.transforms import ToPILImage
# 数据转化为tensor格式
data_transform = transforms.Compose([
transforms.ToTensor()
])
# 加载训练的数据集
train_dataset = datasets.MNIST(root="./data", train=True, transform=data_transform, download=True)
train_dataloader = torch.utils.data.DataLoader(dataset=train_dataset, batch_size=16, shuffle=True)
# 加载测试数据集
test_dataset = datasets.MNIST(root="./data", train=False, transform=data_transform, download=True)
test_dataloader = torch.utils.data.DataLoader(dataset=test_dataset, batch_size=16, shuffle=True)
# 如果有显卡,可以转到GPU
device = "cuda" if torch.cuda.is_available() else "cpu"
# 调用lenet里的模型,将模型数据转到GPU
model = MyLeNet5().to(device)
model.load_state_dict(torch.load("D:/Program Files/pyTorch_project/Classic Network/LeNet-5/save_model/best_model.pth"))
# 获取结果
classes = [
"0", "1", "2", "3", "4", "5", "6", "7", "8", "9",
]
# 把tensor转换成图片,方便可视化
show = ToPILImage()
# 进入验证
for i in range(5):
X, y = test_dataset[i][0], test_dataset[i][1]
show(X).show()
X = Variable(torch.unsqueeze(X, dim=0).float(), requires_grad=False).to(device)
with torch.no_grad():
pred = model(X)
predicted, actual = classes[torch.argmax(pred[0])], classes[y]
print(f'predicted:"{predicted}", actual:"{actual}"')
测试结果
