目录
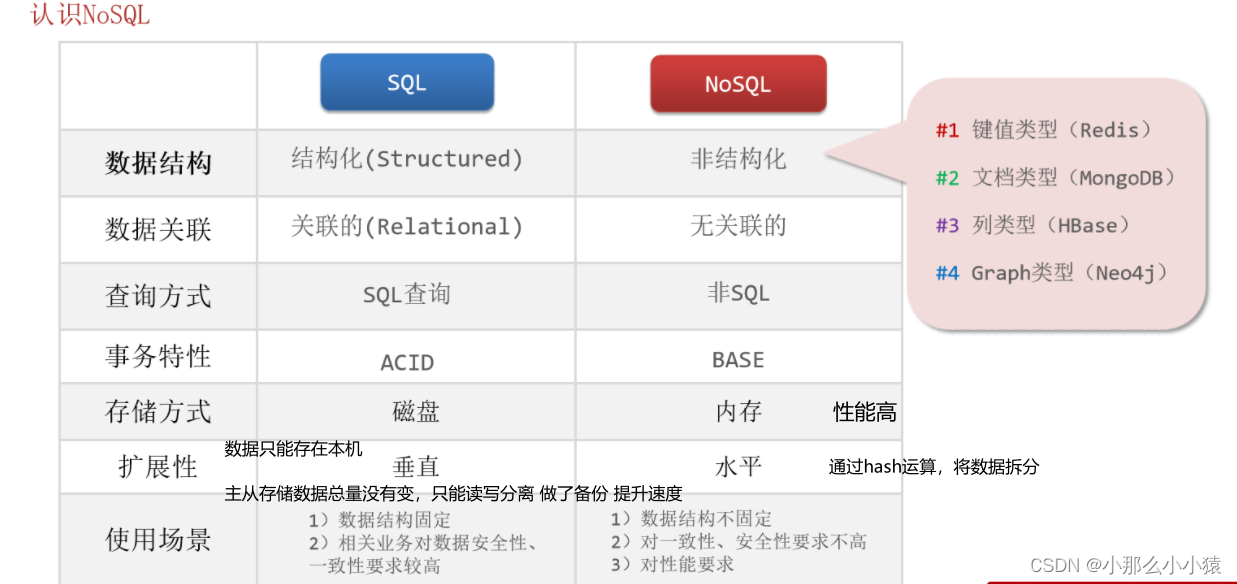
SQL与 NoSQL
- 数据结构
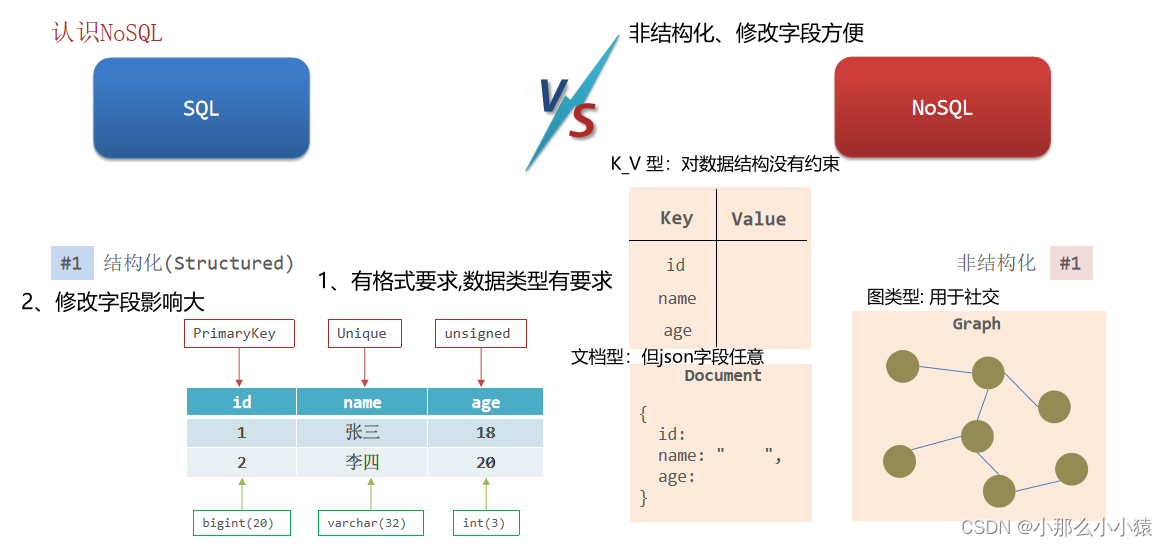
Sql : 表结构固定、插入数据格式有严格规定,修改字段对业务影响很大
NoSql:结构松散、数据格式没有很强要求 。并且有多种类型存储方式:如 k_v 型、图类型、文档型 。修改影响小,
2. 数据关联性
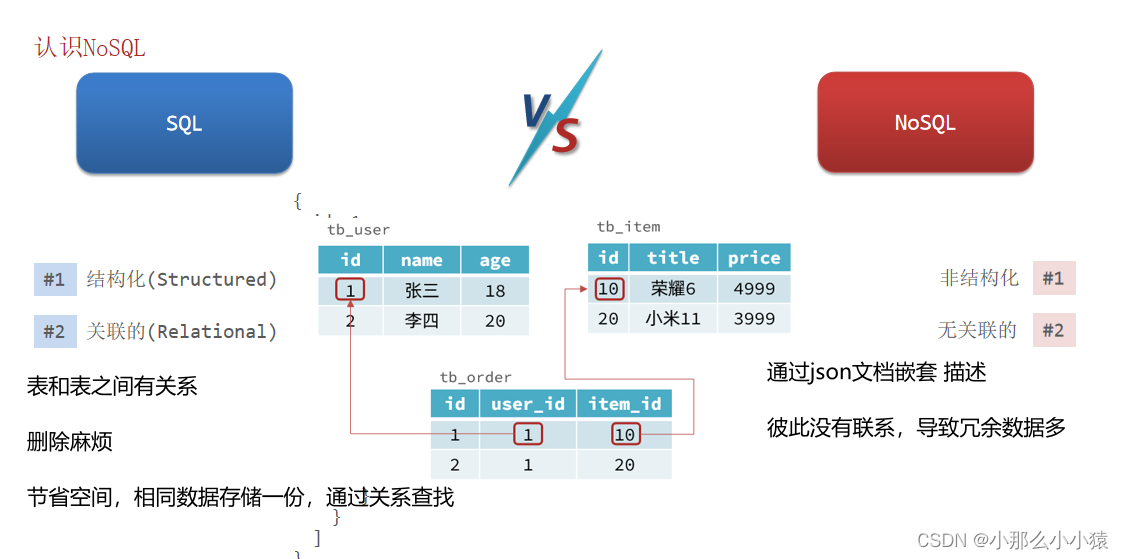
-
查询方式
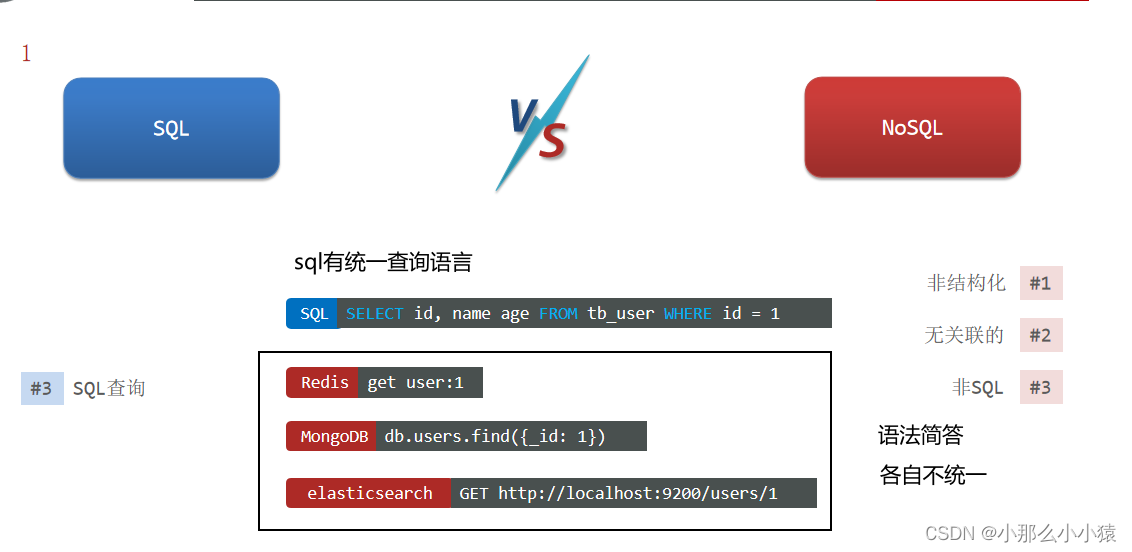
-
事务特性

不同点总结:
redis简介
redis 全称 Remote Dictionary Server 远程字典服务器 诞生在2009年
特点
- 键值(key-value)型,value支持多种不同数据结构,功能丰富
- 单线程,每个命令具备原子性
- 低延迟,速度快(基于内存 比磁盘快多倍、IO多路复用、良好的编码 C语言)。
- 支持数据持久化 解决内存断电情况,确保磁盘安全性
- 支持主从集群(数据备份 提升安全性、读写分离提升效率)、分片集群(提升存储容量,水平扩展)
- 支持多语言客户端
redis安装
redis没有官方win版
centos安装步骤
- 确保具有gcc环境
yum install -y gcc tcl
- 选择一个安装目录 ,将redis安装包上传后 解压
tar -xzf redis-6.2.6.tar.gz
- 解压完成进入 软件目录
cd redis-6.2.6
- 开始编译
make && make install
安装完成
修改配置文件
启动 ./redis-server
默认前台启动(页面关闭即服务停止)、无法远程连接 、没有密码
修改配置文件 redis.conf,并以配置文件启动 ./redis-server ./redis.config
# 允许访问的地址,默认是127.0.0.1,会导致只能在本地访问。修改为0.0.0.0则可以在任意IP访问,生产环境不要设置为0.0.0.0
bind 0.0.0.0
# 守护进程,修改为yes后即可后台运行
daemonize yes
# 密码,设置后访问Redis必须输入密码
requirepass 1234
======================================非必要修改==============================================
# 监听的端口
port 6379
# 工作目录,默认是当前目录,也就是运行redis-server时的命令,日志、持久化等文件会保存在这个目录
dir .
# 数据库数量,设置为1,代表只使用1个库,默认有16个库,编号0~15
databases 3
# 设置redis能够使用的最大内存
maxmemory 1024mb
# 日志文件,默认为空,不记录日志,可以指定日志文件名 会产生在工作目录
logfile "redis.log"
redis客户端
redis提供三种使用方式
-
命令行
在安装目录下:./redis-cli -h (ip 地址 默认 127.0.0.1) -p (端口号 默认 6379) -a (密码 可通过AUTH 后期添加) -
图形化界面
可以使用resp -
编程语言
key的命名
【项目名】:【业务名】:【类型】:【key名】
五大数据类型
redis 是一种key-value型数据库 ,key为String ,但Value的类型很多 。一个库中 key不能重复

通用命令
适用于任何数据类型
- keys :查看符合模板的所有key

- del 【key…】:删除一个key 支持同时传多个key

- exists 【key…】: 判断key是否存在

- expire 【key】【time】 :给key设置有效期,到期自动删除、释放内存空间
只能给已存在的key设置

- ttl 【key】:查询key存活剩余时间

String类型
最简单的数据类型 ,值虽然也为String 但分为三类

String 类型常见命令
- set 【key】【value】 存放一个键值对,如果存在则修改
- get 【key】获取一个key的值
- mset 【key】【value】… 支持同时存放多个键值对
- mget【key…】同时获取多个key的值
- incr 【key】 使得 int类型的值自增1
- incrby【key】【value】使得 int类型的值每次自增 value value可以为负数,从而变为自减

- incryByFloat 【key】【value】:同incryBy 前者用于整数类型,此用来float类型

- setnx【key】【value】:存放一个键值对 。但key之前不能存在
- setex 【key】【time】【value】:在设置key时 为其指定过期时间
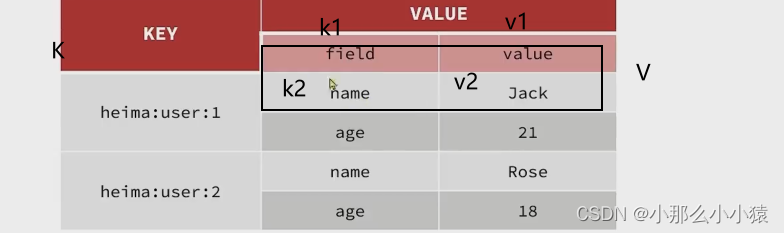
Hash类型 H
value为类似一种hashMap结构。redis是一种k_v的模型,v中在放置着一个HashMap结构
解决问题:
结构

Hash常用命令:
-
hSet 【k】【【filed1】【v1】…】:添加或修改(存在则修改)v中的 多 个键值对

-
hGet 【k】【filed】:获取单个K的V中 包含的某个K的V

-
hmSet 【k】【【fiked1】【v1】…】:测试发现和hset功能相同,都是同时在一个key中添加多个键值对

-
hmGet 【K】【filed】:取出单个K中 某个filed对应的值

-
hGetAll 【k】:获取一个key中value (value 包含所有filed和value)
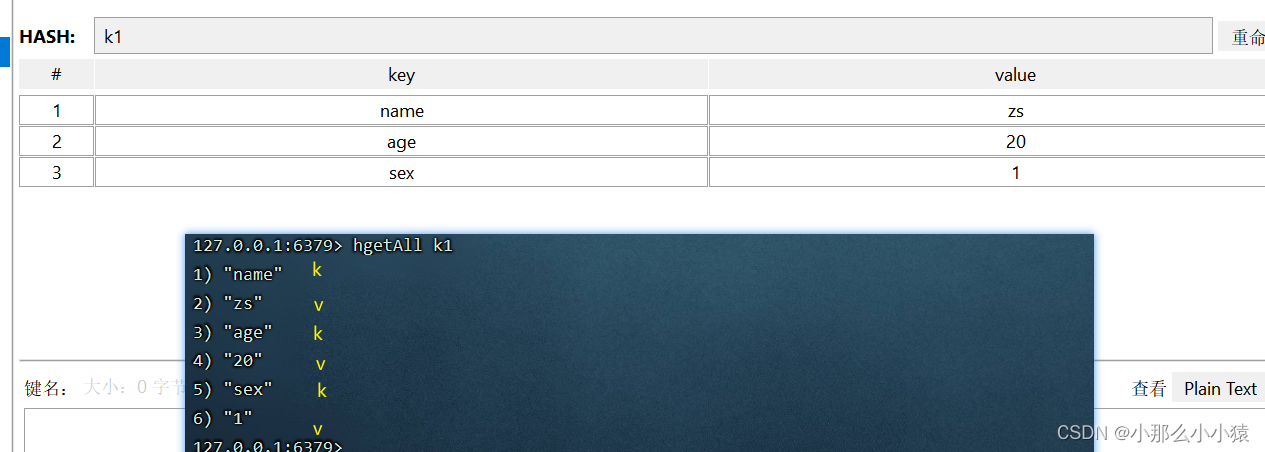
- hKeys 【K】:获取一个key中所有的 filed

- hVals 【K】:获取一个key中所有 filed对应的value

- hKeys 【K】:获取一个key中所有的 filed
-
hIncrBy:【k】【filed】【步长】

-
hSetNX 【k】【【filed】【value】…】:只有filed不存在才会创建 (key可以存在)

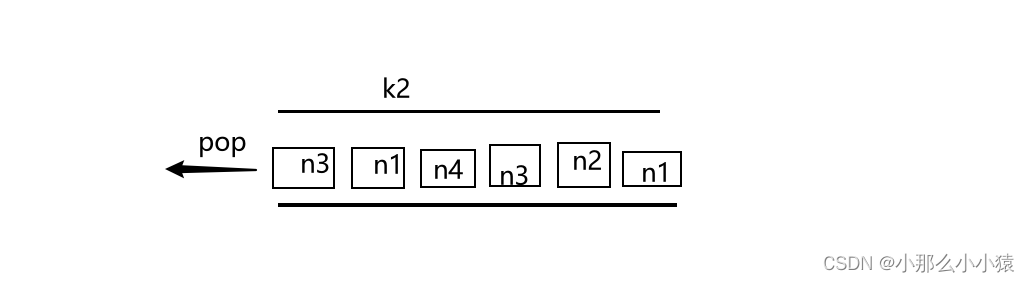
List类型 L R
value的值 是一个list 集合,底层类似于一个双向链表
value值 特点:
先后有序: 由于底层类似于双向链表,数据进行有先后顺序
数据可重复:对进入的值没有处理
插入和删除速度快,查询较慢:底层双向链表结构 ,插入、删除只需改变周围节点指向 而查询需要遍历节点
应用场景:对先后顺序有要求
常用命令:
-
Lpush 【key】【value…】:向左侧插入多个数据


-
Lpop 【key】:移除并返回左侧第一个元素

-
Rpush 【K】【value…】: 从右侧放入数据
-
Rpop 【K】



- Lrange 【key】【start】【end】: 返回指定范围数据
- 、
- Lrange 【key】0 , -1 表示获取key中所有元素

- BLpop 【key】【time】 & BRpop 【key】【time】 :与Lpop 和Rpop相似 但当数据被移空时,会按设置时间等待 而不是直接返回(nil)


问题:
- 如何利用List结构模拟一个栈?
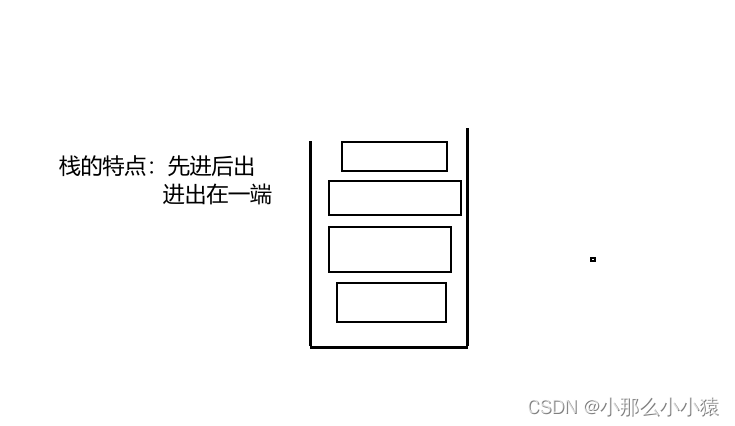
在redis 的List类型中,使用从哪里进,从哪里出 即可
Rpush 和 Rpop 一组 Lpush 和Lpop 一组
2. 如何利用List结构模拟出一个队列
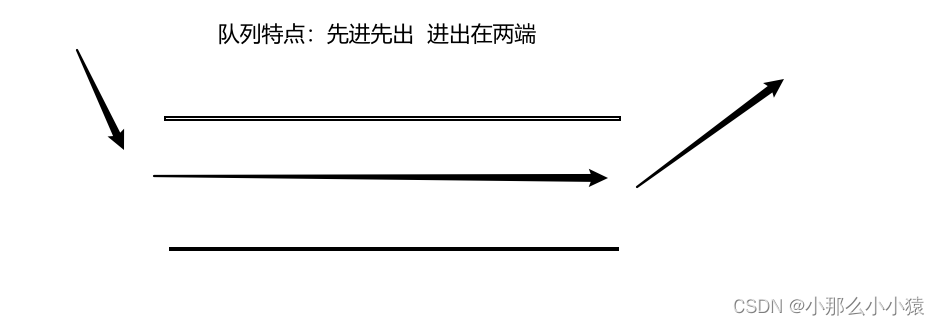
Rpush 和 Lpop 一组 、 Lpush 和Rpop 一组
3. 模拟阻塞队列
在队列的基础上,加上没有则等待特点
Rpush和BLpop一组、Lpush和BRpop 一组
Set类型 S
V中的值 可以看做没有value 只有key(不可重复、无序)的hashMap
特点:(hashMap中key的特点)
无序:用hash计算角标元素不可重复查找速度快:具有hash表支持 交集、并集、差集
常用命令:
-
sAdd 【K】【value…】:一次插入一个或多个数据
-
sRem 【K】【value】:移除一个或多个Key中指定元素

-
Scard 【Key】:计算key中元素个数

-
SisMember 【key】【value】:判断key中 某个value是否存在

运算命令 -
Sinter 【key1】【key2…】:求两个或多个集合间的
交集

-
Sdiff 【key1】【key2…】:求两个或多个集合间的
差集 -
Sunion 【key1】【key2…】:求两个或多个集合间的
并集
命令练习案例

SortedSet类型 Z
可排序的Set集合 。每个元素带有一个score属性,根据score进行排序(底层是通过跳表) 默认是升序(从小到大)
特点:
可排序:可排序的Set
继承的set特点:查询数据快数据不重复支持 交集、并集、差集
使用场景:排行榜
常用命令
-
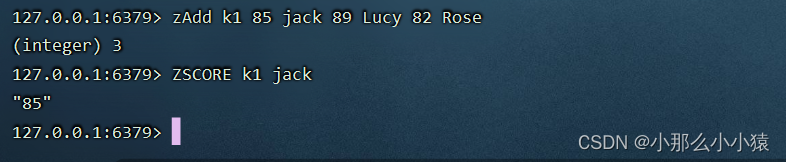
Zadd 【key】【【score】【value】…】:向key中 添加数据{score:value}


-
Zrem 【key】【value】 :根据key中 value进行删除

-
Zscore 【key】【value】:查找key中value对用score值
-
-
Zrank 【key】【value】:获取key中指定value的排名

-
Zcard 【key】:获取key中元素个数
-
Zcount 【key】【分数min】【分数max】:按照score排序
分数范围,统计个数 -
Zrange 【key】【排名min】【排名max】:按照score排序
排名范围,获取元素 -
ZrangeByScore 【key】【分数 min】【分数max】:按照score
分数范围,获取元素 -
ZincrBy 【key】【步长】【value】:在key中找到value 将其Score 加上指定数值

降序排名(从大到小)
在所以命令Z后加上REV
运算命令
- Zinter 【key1】【key2…】:求两个或多个集合间的
交集 - Zdiff 【key1】【key2…】:求两个或多个集合间的
差集 - Zunion 【key1】【key2…】:求两个或多个集合间的
并集
练习:

其他数据类型
Stream
redis5.0 引入的新数据类型,一个功能完善的消息队列 。通常用于异步处理任务
生产者常用命令:
- xAdd 【队列的key】* 【【key】【value】…】
每添加一次,即使有多个k_v对,也算一条消息

- xLen 【队列的key】 查看队列中消息的数量
消费者常用命令: - Xread count 【一次读取条数】block 【阻塞时间】 strames 【队列的key…】 $ 读取阻塞等待读取最新的消息

Geo
用来存储和处理地理位置信息,本质是一个SortedSet
常用命令:
- GeoAdd 【key】【【经度】【维度】【点的名称】…】 添加多个位置 点(通过经纬度确定)


- GeoDist 【key】【点1的名称】【点2的名称】(【单位 km】默认为m):查询两点间的距离
- GeoHash 【key】【点的名称】: 将点的信息以hash字符串的形式,方便储存

- GeoPos 【key】【点的名字】:显示key中某个点的经纬度
- GeoSearch 【key】fromLonLat 【中心的经度】【中心的维度】ByRadius 【距离值】【单位 m/ km 】(withDist 带上距离) :查询距离中心【形状 如圆形,方形】距离小于多少【距离值】【单位】的所有点,默认升序
6.2版本出现
bitMap
储存多个二进制信息,多用于签到
常用命令:
-
setBit 【key】【要设置第几位】【置为 1 or 0】 :将key的第几个位置存入一个 0 或 1 。默认为0 (
常用于签到)

-
getBit 【key】【要获取第几位】:获取key的第几位的bit值 (
判断哪天有没有签到) -
BitCount 【key】:统计key中1的个数 (
查看一个月签到了多少天) -
BitField 【key】【操作类型 GET】【是否有符号 i:有符号 u:无符号】【读取位数】【从哪里开始读取】:常用无符号的一次读取多个位数的bit位 (
常用获取具体的签到结果)

-
BitOp【key】:将bitMap的结果记性运算
-
bitOps【key】【0 or1】 :查找给定的bit值第一次出现的位置

HyperLogLog
常用于进行UV统计。特点:可以记录统计亿级别的流量,而最大占用空间永远不超过16K。不能统计重复数据,且统计有有小于0.81%的误差
- PfAdd 【key】 【value…(大量)】
- PfCount 【key】统计key中的不重复的元素个数
- PfMerge 【【key1】【key2】…】:将其他hyperLogLog类型的key进行
合并。例如 每天统计访问用户数,最后合并可求出一个月的有多少个访问的用户数
 h
h
redis编程客户端
java语言推荐三种客户端
-
jedis:- 以命令作为方法名称,简单实用,学习成本低
- 线程不安全 ,多线程需要基于连接池
-
lettuce(spring官方默认兼容):- 基于Netty实现,支持同步,异步和响应式编程 吞吐能力强
- 线程安全
- 支持redis哨兵模式、集群模式、管道模式
-
Redisson:
- 不在于操作,基于redis实现的分布式
springDateRedis 可兼容 jedis(额外导入jar包)和lettuce(默认兼容)
- 不在于操作,基于redis实现的分布式
jedis使用
使用前 确保redis开启远程连接
导入依赖
jedis 依赖
<dependency>
<groupId>redis.clients</groupId>
<artifactId>jedis</artifactId>
<version>3.7.0</version>
</dependency>
测试需要的:
<!--单元测试-->
<dependency>
<groupId>org.junit.jupiter</groupId>
<artifactId>junit-jupiter</artifactId>
<version>5.7.0</version>
<scope>test</scope>
</dependency>
普通方式
2. 获取Jedis对象 ,创建连接(ip,port),进行测试
public class JedisTest {
private Jedis jedis;
// 所有测试方法运行前初始化
@BeforeEach
void setUp(){
String host="192.168.83.100";
int port=6379;
String password="1234";
jedis=new Jedis(host,port);
jedis.auth(password);
jedis.select(0);
}
// 所有测试方法运行后 执行
@AfterEach
void connectDown(){
if(jedis!=null){
jedis.close();
}
}
@Test
void testString(){
jedis.set("name","jedis test!");
System.out.println(jedis.get("name"));
}
}

连接池方式
例:
使用jedis完成

由于Jedis线程不安全,并发环境需要使用 线程池 (频繁创建 销毁 消耗性能)由连接池创建对象
连接池工厂类
public class JedisConnectFactory {
private static final JedisPool jedisPool;
static {
JedisPoolConfig poolConfig = new JedisPoolConfig();
String host="192.168.83.100";
int port=6379;
String password="1234";
int timeout=1000;
// 设置总连接数
poolConfig.setMaxTotal(8);
// 最大空闲连接 即使没有数据库连接时依然可以保持8个空闲的连接,而不被清除,随时处于待命状态
poolConfig.setMaxIdle(8);
// 最小空闲连接
poolConfig.setMinIdle(0);
jedisPool= new JedisPool(poolConfig,host,port,timeout,password);
}
public static Jedis getJedis(){
return jedisPool.getResource();
}
}
连接对象创建
private Jedis jedis;
@BeforeEach
void setUp(){
jedis= JedisConnectFactory.getJedis();
}
springDataRedis使用
特点:
- 整合了 Lettuce和jedis
- 提供 redisTemplate 封装形成统一API 底层来操作不同客户端
- 支持 基于JDK,JSON,String的数据序列化(将对象变成 字符串 或 字节)和反序列化
- 支持Redis哨兵 和 Redis集群
- 支持Redis 发布订阅模型

使用方式:
引入springBoot依赖
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>2.5.7</version>
<relativePath/> <!-- lookup parent from repository -->
</parent>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>
<!--common-pool-->
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-pool2</artifactId>
</dependency>
额外功能
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
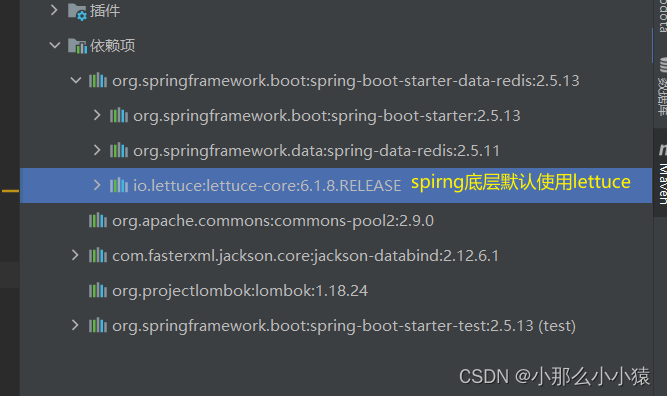
- 进行配置
spring:
redis:
host: 192.168.83.100
port: 6379
password: 1234
# 如果不配置连接池 连接池将不会生效
lettuce:
pool:
max-active: 8 #最大连接
max-idle: 8 #最大空闲连接
min-idle: 0 #最小空闲连接
max-wait: 100ms #连接等待时间
- 获取
RedisTemplate对象进行操作
@Autowired
private RedisTemplate redisTemplate;
@Test
public void testString(){
redisTemplate.opsForValue().set("name","spring-data-redis-string");
}

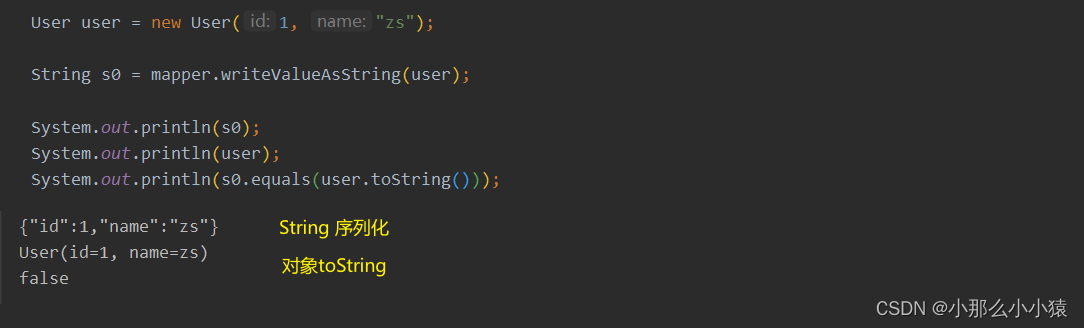
问题:
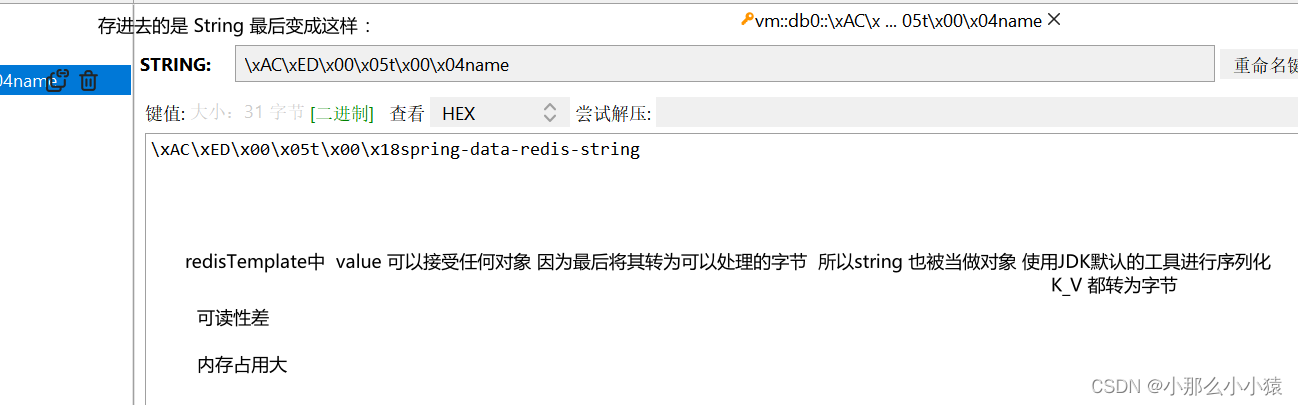

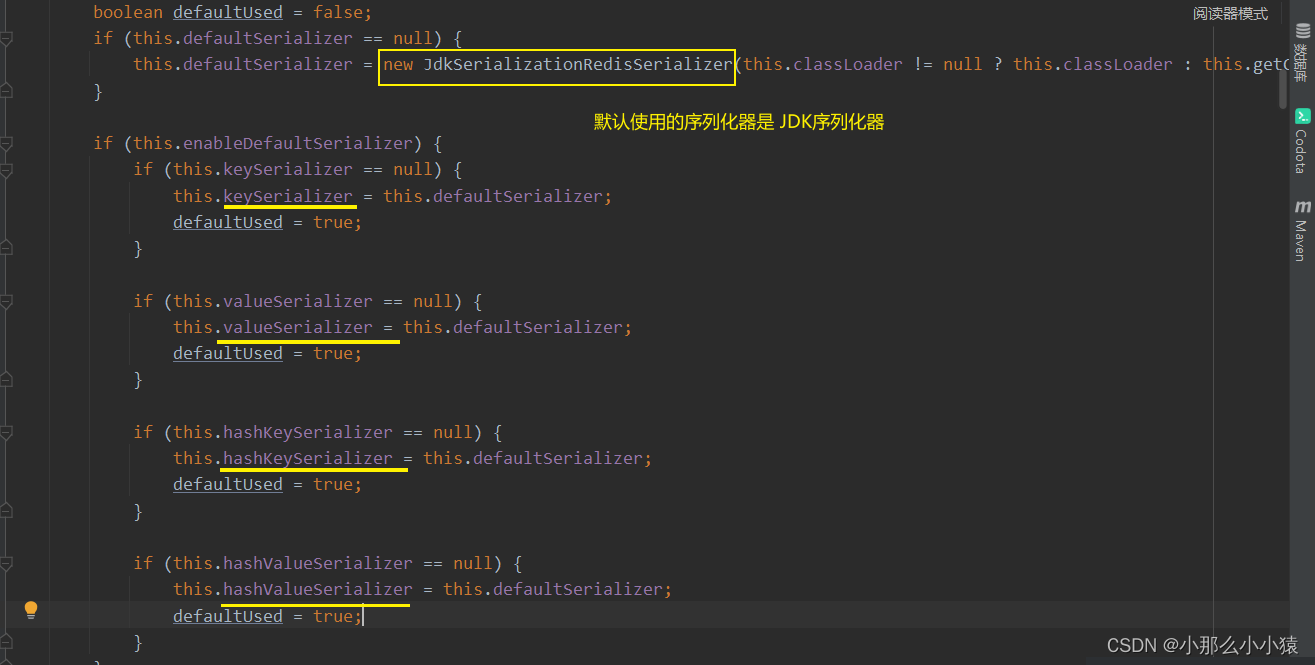
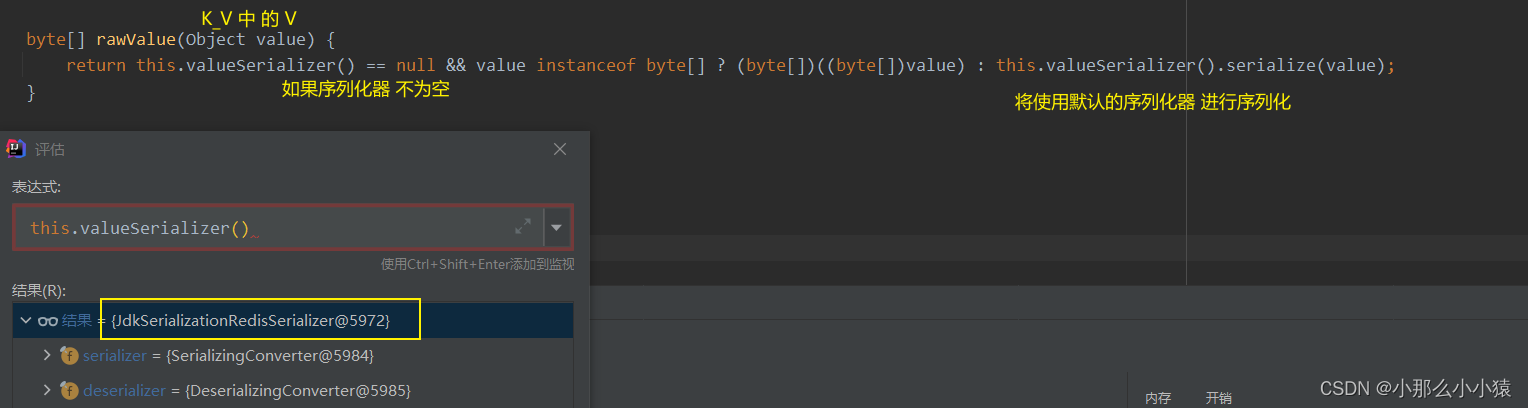
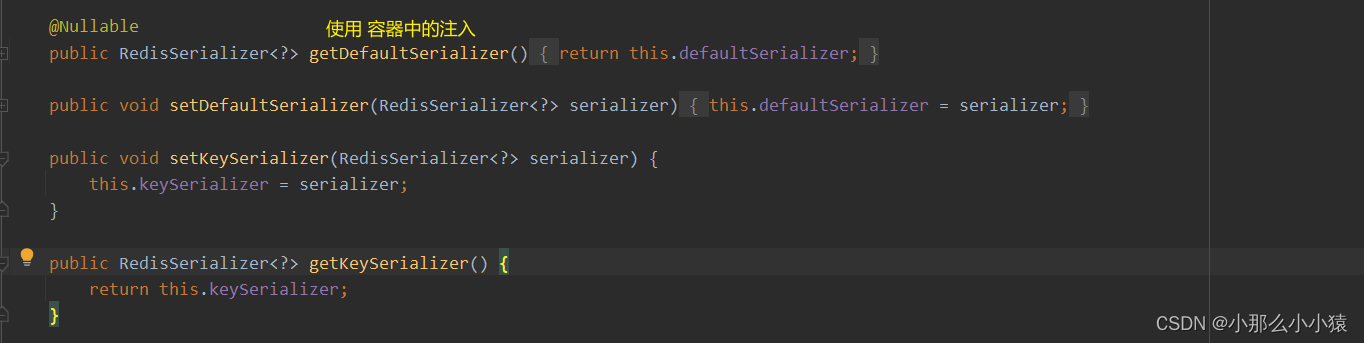

解决方式:
方案一 自动序列化:
使用自定义的RedisTemplate K使用string序列化 V使用json序列化
@Configuration
public class RedisConfig {
@Bean
public RedisTemplate<String, Object> redisTemplate(RedisConnectionFactory connectionFactory){
// 创建RedisTemplate对象
RedisTemplate<String, Object> template = new RedisTemplate<>();
// 设置连接工厂
template.setConnectionFactory(connectionFactory);
// 创建JSON序列化工具
GenericJackson2JsonRedisSerializer jsonRedisSerializer = new GenericJackson2JsonRedisSerializer();
// 设置Key的序列化
template.setKeySerializer(RedisSerializer.string());
template.setHashKeySerializer(RedisSerializer.string());
// 设置Value的序列化
template.setValueSerializer(jsonRedisSerializer);
template.setHashValueSerializer(jsonRedisSerializer);
// 返回
return template;
}
}
注意:使用json序列化 需要导入 jackson-databind依赖 但springMv依赖会包含
效果:
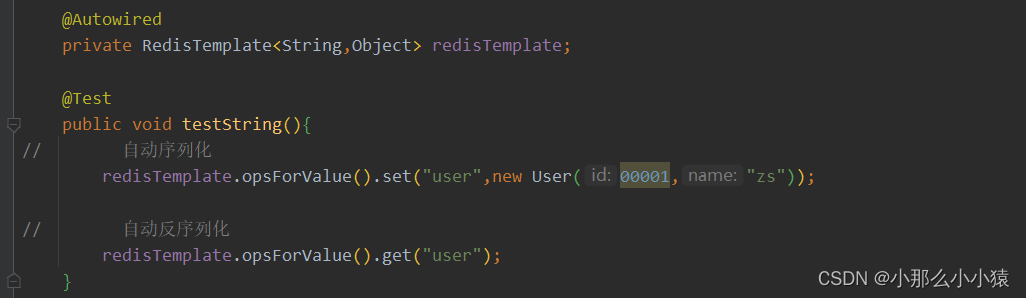

方式二 :手动序列化
与方式一不同 ,V也要采用使用String序列化
但不用自己制定,spring专门提供了将K_V都转为 String的 StringRedisTemplate

效果
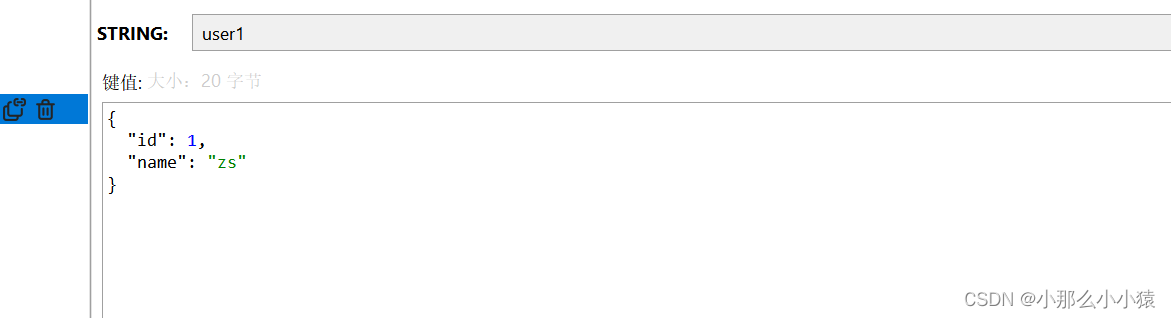
注意