1. 概述
Redis 是速度非常快的非关系型(NoSQL) 内存键值数据库,可以存储键和五种不同类型的值之间的映射。
键的类型只能为字符串,值支持的五种类型数据类型为:字符串、列表、集合、散列表、有序集合。
Redis 支持很多特性,例如将内存中的数据持久化到硬盘中,使用复制来扩展读性能,使用分片来扩展写性能。
2. 数据类型
| 数据类型 | 可以存储的值 | 操作 |
|---|---|---|
| STRING | 字符串、整数或者浮点数 | 对整个字符串或者字符串的其中一部分执行操作 对整数和浮点数执行自增或者自减操作 |
| LIST | 列表 | 从两端压入或者弹出元素 对单个或者多个元素进行修剪,只保留一个范围内的元素 |
| SET | 无序集合 | 添加、获取、移除单个元素、检查一个元素是否存在于集合中 计算交集、并集、差集、 从集合里面随机获取元素 |
| HASH | 包含键值对的无序散列表 | 添加、获取、移除单个键值对、 获取所有键值对、 检查某个键是否存在
扫描二维码关注公众号,回复:
6148941 查看本文章

|
| ZSET | 有序集合 | 添加、获取、删除元素、 根据分值范围或者成员来获取元素、 计算一个键的排名 |
2.1 STRING

> set hello world
OK
> get hello
"world"
> del hello
(integer) 1
> get hello
(nil)- set key value:成功返回OK
- get key:返回value,若不存在返回(nil)
- del key:删除这个键的值,成功返回(integer)1
2.2 LIST

> rpush list-key item
(integer) 1
> rpush list-key item2
(integer) 2
> rpush list-key item
(integer) 3
> lrange list-key 0 -1
1) "item"
2) "item2"
3) "item"
> lindex list-key 1
"item2"
> lpop list-key
"item"
> lrange list-key 0 -1
1) "item2"
2) "item"- rpush key value:存储一个键值对,一个key对应可以多个value,并且value可以重复。成功返回一个(integer)
- lrange key 0 -1:返回此key对应的所有value。重复的也都显示
- lindex key index:返回此key的第index个value。从0开始
- lpop key:取出此key对应的第一个value
2.3 SET

> sadd set-key item
(integer) 1
> sadd set-key item2
(integer) 1
> sadd set-key item3
(integer) 1
> sadd set-key item
(integer) 0
> smembers set-key
1) "item"
2) "item2"
3) "item3"
> sismember set-key item4
(integer) 0
> sismember set-key item
(integer) 1
> srem set-key item2
(integer) 1
> srem set-key item2
(integer) 0
> smembers set-key
1) "item"
2) "item3"- sadd key value:添加键值对,一个key可以对应多个value,但是value不可重复。添加成功返回(integer)1,失败返回(integer)0。
- smembers key:显示此key对应的所有value
- sismemeber key value:判断此key有没有这个value,无则返回(integer)0
- srem key value:移除此key对应的这个value,成功返回(integer)1,失败返回(integer)0。
2.4 HASH

> hset hash-key sub-key1 value1
(integer) 1
> hset hash-key sub-key2 value2
(integer) 1
> hset hash-key sub-key1 value1
(integer) 0
> hgetall hash-key
1) "sub-key1"
2) "value1"
3) "sub-key2"
4) "value2"
> hdel hash-key sub-key2
(integer) 1
> hdel hash-key sub-key2
(integer) 0
> hget hash-key sub-key1
"value1"
> hgetall hash-key
1) "sub-key1"
2) "value1"
- hset key key1 value1:将键值对key1,value1存入key,键值对不可重复。成功返回(integer)1,失败返回(integer)0。
- hgetall key:获得此key种所有的键值对
- hdel key key1:删除key中的key1及其value。成功返回(integer)1,失败返回(integer)0。
- hget key key1:获得此key中key1对应的value。
2.5 ZSET

> zadd zset-key 728 member1
(integer) 1
> zadd zset-key 982 member0
(integer) 1
> zadd zset-key 982 member0
(integer) 0
> zrange zset-key 0 -1 withscores
1) "member1"
2) "728"
3) "member0"
4) "982"
> zrangebyscore zset-key 0 800 withscores
1) "member1"
2) "728"
> zrem zset-key member1
(integer) 1
> zrem zset-key member1
(integer) 0
> zrange zset-key 0 -1 withscores
1) "member0"
2) "982"- zadd key value1.1 value1.2:添加一条记录
- zrange key 0 -1 withscores:按成绩排序,输出所有记录
- zrangeby score key 0 800 withscores:输出成绩范围在0~800之间的数据,并按成绩排序
- zrem key value1.1:删除value1.1对应的那条记录,成功返回(integer)1,失败返回(integer)0。
2.6 应用场景
| 注 | 使用场景 | |
|---|---|---|
| STRING | value其实不仅是String,也可以是数字 | 常规key-value缓存应用。常规计数: 微博数, 粉丝数。 |
| LIST | Redis的list是每个子元素都是String类型的双向链表,可以通过push和pop操作从列表的头部或者尾部添加或者删除元素,这样List即可以作为栈,也可以作为队列。 | 消息队列系统、取最新N个数据的操作 |
| SET | set不是自动有序的,数据不可重复 | 交集,并集,差集;获取某段时间所有数据去重值 |
| HASH | 存储部分变更数据,如用户信息等。 | |
| ZSET | sorted set可以通过用户额外提供一个优先级(score)的参数来为成员排序,并且是插入有序的,即自动排序。 | 需要一个有序的并且不重复的集合列表, |
2.6.1 LIST使用场景的实现
① 消息队列系统
使用list可以构建队列系统,使用sorted set甚至可以构建有优先级的队列系统。
比如:将Redis用作日志收集器
实际上还是一个队列,多个端点将日志信息写入Redis,然后一个worker统一将所有日志写到磁盘。
② 取最新N个数据的操作
记录前N个最新登录的用户Id列表,超出的范围可以从数据库中获得。
//把当前登录人添加到链表里
ret = r.lpush("login:last_login_times", uid)
//保持链表只有N位
ret = redis.ltrim("login:last_login_times", 0, N-1)
//获得前N个最新登录的用户Id列表
last_login_list = r.lrange("login:last_login_times", 0, N-1)2.6.2 SET使用场景
① 交集,并集,差集
在微博应用中,可以将一个用户所有的关注人存在一个集合中,将其所有粉丝存在一个集合。
Redis还为集合提供了求交集、并集、差集等操作,可以非常方便的实现如共同关注、共同喜好、二度好友等功能。
对上面的所有集合操作,你还可以使用不同的命令选择将结果返回给客户端还是存集到一个新的集合中。
Set是集合,是String类型的无序集合,set是通过hashtable实现的,概念和数学中个的集合基本类似,可以交集,并集,差集等等。
set中的元素是没有顺序的。
实现方式:
set 的内部实现是一个 value永远为null的HashMap,实际就是通过计算hash的方式来快速排重的,这也是set能提供判断一个成员是否在集合内的原因。
//book表存储book名称
set book:1:name ”The Ruby Programming Language”
set book:2:name ”Ruby on rail”
set book:3:name ”Programming Erlang”
//tag表使用集合来存储数据,因为集合擅长求交集、并集
sadd tag:ruby 1
sadd tag:ruby 2
sadd tag:web 2
sadd tag:erlang 3
//即属于ruby又属于web的书?
inter_list = redis.sinter("tag.web", "tag:ruby")
//即属于ruby,但不属于web的书?
inter_list = redis.sdiff("tag.ruby", "tag:web")
//属于ruby和属于web的书的合集?
inter_list = redis.sunion("tag.ruby", "tag:web")② 获取某段时间所有数据去重值
这个使用Redis的set数据结构最合适了,只需要不断地将数据往set中扔就行了,set意为集合,所以会自动排重。
2.6.3 HASH应用场景举例
比如我们要存储一个用户信息对象数据,包含以下信息:用户ID为查找的key,存储的value用户对象包含姓名,年龄,生日等信息。
如果用普通的key/value结构来存储,主要有以下2种存储方式:

第一种方式将用户ID作为查找key,把其他信息封装成一个对象以序列化的方式存储。
这种方式的缺点是:
- 增加了序列化/反序列化的开销
- 在需要修改其中一项信息时,需要把整个对象取回,并且修改操作需要对并发进行保护,引入CAS等复杂问题。
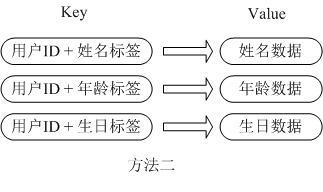
第二种方法是这个用户信息对象有多少成员就存成多少个key-value对。
用用户ID+对应属性的名称作为唯一标识来取得对应属性的值。
虽然省去了序列化开销和并发问题,但是用户ID为重复存储,如果存在大量这样的数据,内存浪费还是非常可观的。
那么Redis提供的Hash很好的解决了这个问题,Redis的Hash实际是内部存储的Value为一个HashMap,并提供了直接存取这个Map成员的接口,如下图:
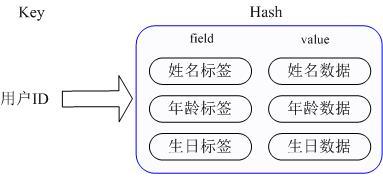
也就是说,Key仍然是用户ID,value是一个Map。
这个Map的key是成员的属性名,value是属性值。
这样对数据的修改和存取都可以直接通过其内部Map的Key(Redis里称内部Map的key为field),也就是通过 key(用户ID) + field(属性标签)就可以操作对应属性数据了,既不需要重复存储数据,也不会带来序列化和并发修改控制的问题。
很好的解决了问题。
Redis提供了接口(hgetall)可以直接取到全部的属性数据,但是如果内部Map的成员很多,那么涉及到遍历整个内部Map的操作,由于Redis单线程模型的缘故,这个遍历操作可能会比较耗时,而另其它客户端的请求完全不响应,这点需要格外注意。
2.6.4 ZSET使用场景
和Set相比,Sorted Set增加了一个权重参数score,使得集合中的元素能够按score进行有序排列。
比如一个存储全班同学成绩的Sorted Set,其集合value可以是同学的学号,而score就可以是其考试得分。这样在数据插入集合的时候,就已经进行了天然的排序。
另外还可以用Sorted Set来做带权重的队列,比如普通消息的score为1,重要消息的score为2,然后工作线程可以选择按score的倒序来获取工作任务。让重要的任务优先执行。
实现方式:
Redis sorted set的内部使用HashMap和跳跃表(SkipList)来保证数据的存储和有序:
- HashMap里放的是成员到score的映射,
- 跳跃表里存放的是所有的成员
- 排序依据是HashMap里存的score
- 使用跳跃表的结构可以获得比较高的查找效率,并且在实现上比较简单。