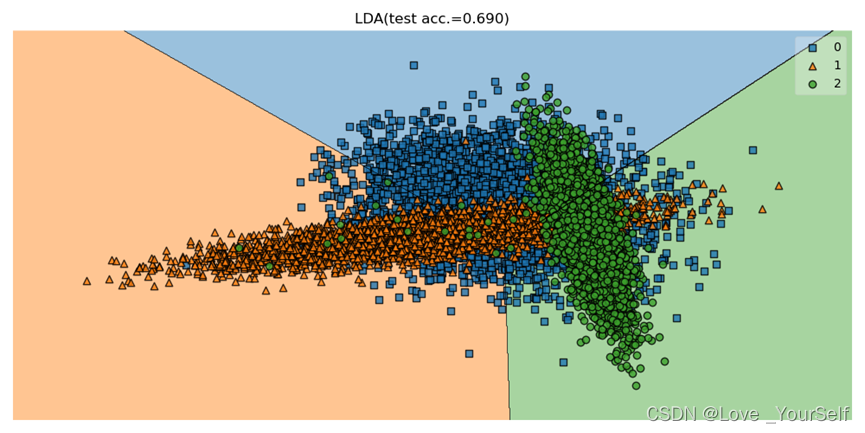
本文自建随机数据集进行演示PCA和LDA进行特征选择与提取
创建数据集
首先使用的是make_blobs函数,在pycharm中查看源码描述为Generate isotropic Gaussian blobs for clustering,就是用来生成数据集,make_blobs函数的第一个参数为n_samples,这个参数可以设置为一个整数或者是array-like也就是类似列表的参数,如果这里输入的整数类型则就是产生对应数量的样本,这个参数的默认值是100,也就是产生100个数据,这里设置的是1000,也就是产生1000个样本数据;第二个参数n_features表示样本的特征维数,默认值是2,本文设置的该参数为3,也就是每个样本包括3维的特征值;参数center可以接收的可以是一个整数或者一个列表类型的,源码描述为The number of centers to generate, or the fixed center locations,这个参数表示的为样本数据的中心点,本文设置的这个参数为一个4行3列的列表,也就是代表样本数据集要分为4个类别,这4个值就是每个类别的中心的特征值;参数cluster_std是代表了每个聚类样本数据的标准差,给出几个中心就要给出几个标准差,否则就会报错,这里我是实验过的,本文设置的这个参数是以列表形式给出的,每个对应每类的标准差;random_state是随机数种子,保证实验结果的可重现性,给定一个整数就行,本文这里设置的为9。
make_blobs函数调用后第一个返回值为样本数据,第二个返回参数为该样本数据的标签值,和之前使用的sklearn包中导入数据的函数返回值一样,这里是自动产生的规定好的数据,这里的X为数据,y为标签值也就是类别值。
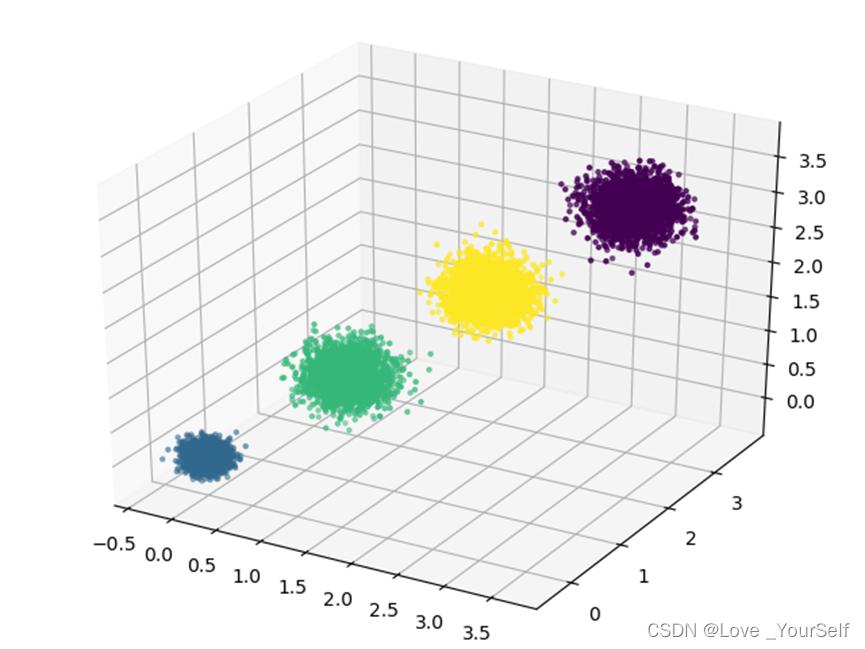
# X为样本特征,Y为样本簇类别, 共1000个样本,每个样本3个特征,共4个簇
X, y = datasets.make_blobs(n_samples=10000,
n_features=3,
centers=[[3, 3, 3], [0, 0, 0],
[1, 1, 1], [2, 2, 2]],
cluster_std=[0.2, 0.1, 0.2, 0.2],
random_state=9)
PCA降维
然后对数据进行降维操作,这里使用到的是PCA变换,这个变换把数据变换到一个新的坐标系统中,使得任何数据投影的第一大方差在第一个坐标(称为第一主成分)上,第二大方差在第二个坐标(第二主成分)上,依次类推。这个函数的第一个参数为n_components,在pycharm上描述为Number of components to keep,也就是将数据进行降维操作后,保留几维特征,这里传入的参数为为2,也就是把3维特征降为只有两个特征。PCA降维使用的方法是通过计算数据矩阵的协方差矩阵,然后得到协方差矩阵的特征值特征向量,选择特征值最大(即方差最大)的k个特征所对应的特征向量组成的矩阵。这样就可以将数据矩阵转换到新的空间当中,实现数据特征的降维。
# 降维
pca = PCA(n_components=2)
pca.fit(X)
降维之后将其显示在matplotlib上,只保留显示选取后的两个维度的信息。
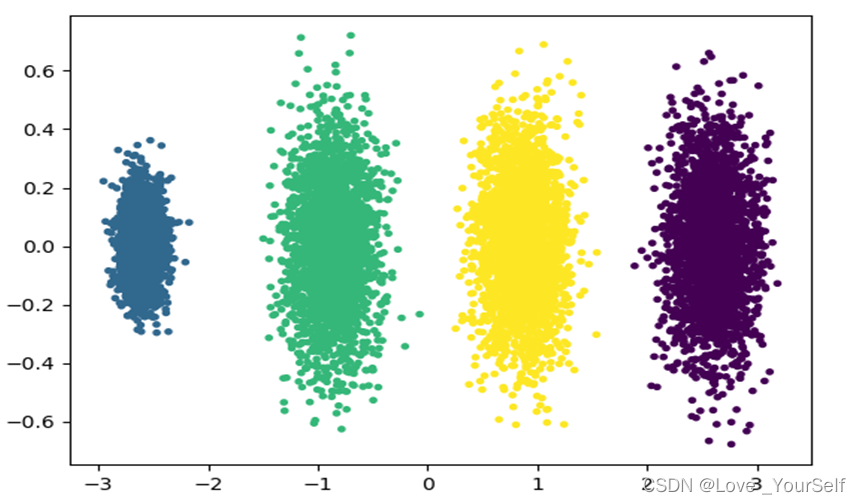
这是在降维之前的数据集的分布,这样看并没有太好的区分性,而将其进行降维之后,区分度更明显。
LDA降维
因为PCA没有利用类别信息,也就是在降维的时候忽视了样本特征和类别信息的关联,而LDA相当于有监督的降维,在降维的时候考虑到类别信息,通过LDA降维后特征值和类别信息的关联性能够得到保存,所以针对这个自己设置生成的有标签的数据,LDA降维后的特征空间中,样本的分布比PCA好,区分度更高。
# LDA降维
lda = LinearDiscriminantAnalysis(n_components=2)
lda.fit(X,y)
X_lda = lda.transform(X)
运行结果为: