目录
- 1 概述
- 2 系统架构
- 3 部署
- 3.1 后端部署
- 3.1.1 基础软件安装
- 3.1.2 创建部署用户
- 3.1.3 下载并解压
- 3.1.4 针对escheduler用户ssh免密配置
- 3.1.5 数据库初始化
- 3.1.6 修改部署目录权限及运行参数
- 3.1.7 执行脚本一键部署
- 3.1.8 dolphinscheduler后端服务启停
- 3.2 前端部署
- 3.2.1 下载并解压
- 3.2.2 执行自动化部署脚本
- 3.2.3 dolphinscheduler前端服务启停
- 3.1 后端部署
- 4 快速开始
- 5 Worker分组
- 6 添加数据源
- 7 实例
- 8 与 Azkaban 的对比
- 9 小节
1 概述
Apache DolphinScheduler(目前处在孵化阶段)是一个分布式、去中心化、易扩展的可视化DAG工作流任务调度系统,其致力于解决数据处理流程中错综复杂的依赖关系,使调度系统在数据处理流程中开箱即用。
DolphinScheduler是今年(2019年)中国易观公司开源的一个调度系统,在今年美国时间2019年8月29号,易观开源的分布式任务调度引擎DolphinScheduler(原EasyScheduler)正式通过顶级开源组织Apache基金会的投票决议,根据Apache基金会邮件列表显示,在包含11个约束性投票(binding votes)和2个无约束性投票(non-binding votes)的投票全部持赞同意见,无弃权票和反对票,投票顺利通过,这样便以全票通过的优秀表现正式成为了Apache孵化器项目!
1.1 背景
在2017年,易观在运营自己6.8Pb大小、6.02亿月活、每天近万个调度任务的大数据平台时,受到ETL复杂的依赖关系、平台易用性、可维护性及二次开发等方面掣肘,易观的技术团队渴望找到一个具有以下功能的数据调度工具:
- 易于使用,开发人员可以通过非常简单的拖拽操作构建ETL过程。不仅对于ETL开发人员,无法编写代码的人也可以使用此工具进行ETL操作,例如系统管理员和分析师;
- 解决“复杂任务依赖”问题,并且可以实时监视ETL运行状态;
- 支持多租户;
- 支持许多任务类型:Shell,MR,Spark,SQL(mysql,postgresql,hive,sparksql),Python,Sub_Process,Procedure等;
- 支持HA和线性可扩展性。
易观技术团队意识到现有开源项目没有能够达到他们要求的,因此决定自行开发这个工具。他们在2017年底设计了DolphinScheduler的主要架构;2018年5月完成第一个内部使用版本,后来又迭代了几个内部版本后,系统逐渐稳定下来。
这里介绍一下DolphinScheduler易观技术团队,他们是一支来自百度、阿里、百分点、Ptmind、热云等团队的“数据极客”,秉持易观“让数据能力平民化”的初心,积极拥抱开源,曾贡献过Presto Hbase Connector, Presto Kudu Connector等令开发者称赞的项目。这次他们在公司的支持下,积极地将自己开发的调度工具推动开源,旨在回馈开源的同时,助力打造一个更为强大的开源生态。如果跃跃欲试的想去贡献代码的,贡献流程可以参考这篇博客:分布式任务调度EasyScheduler贡献代码流程。
团队在2019年3月初,小范围(10多家公司)开放了DS的种子用户试用,得到了非常正能量的反馈,在4月初的正式对外开放源码后,很快就获得了许多开发人员的关注兴趣,目前github上的star现在已超过1700个,参与开发和使用的公司包括嘀嗒出行、雪球、凤凰金融、水滴互助、华润万家等,更详细的可以查看:Wanted: Who is using DolphinScheduler #57。
1.2 特点
DolphinScheduler提供了许多易于使用的功能,可加快数据ETL工作开发流程的效率。其主要特点如下:
- 通过拖拽以DAG 图的方式将 Task 按照任务的依赖关系关联起来,可实时可视化监控任务的运行状态;
- 支持丰富的任务类型;
- 支持工作流定时调度、依赖调度、手动调度、手动暂停/停止/恢复,同时支持失败重试/告警、从指定节点恢复失败、Kill 任务等操作;
- 支持工作流全局参数及节点自定义参数设置;
- 支持集群HA,通过 Zookeeper实现 Master 集群和 Worker 集群去中心化;
- 支持工作流运行历史树形/甘特图展示、支持任务状态统计、流程状态统计;
- 支持补数,并行或串行回填数据。
2 系统架构
2.1 名词解释
- 流程定义:通过拖拽任务节点并建立任务节点的关联所形成的可视化DAG
- 流程实例:流程实例是流程定义的实例化,可以通过手动启动或定时调度生成,流程定义每运行一次,产生一个流程实例
- 任务实例:任务实例是流程定义中任务节点的实例化,标识着具体的任务执行状态
- 任务类型: 目前支持有SHELL、SQL、SUB_PROCESS(子流程)、PROCEDURE、MR、SPARK、PYTHON、DEPENDENT(依赖),同时计划支持动态插件扩展,注意:其中子 SUB_PROCESS 也是一个单独的流程定义,是可以单独启动执行的
- 调度方式: 系统支持基于cron表达式的定时调度和手动调度。命令类型支持:启动工作流、从当前节点开始执行、恢复被容错的工作流、恢复暂停流程、从失败节点开始执行、补数、定时、重跑、暂停、停止、恢复等待线程。其中 恢复被容错的工作流 和 恢复等待线程 两种命令类型是由调度内部控制使用,外部无法调用
- 定时调度:系统采用 quartz 分布式调度器,并同时支持cron表达式可视化的生成
- 依赖:系统不单单支持 DAG 简单的前驱和后继节点之间的依赖,同时还提供任务依赖节点,支持流程间的自定义任务依赖
- 优先级 :支持流程实例和任务实例的优先级,如果流程实例和任务实例的优先级不设置,则默认是先进先出
- 邮件告警:支持 SQL任务 查询结果邮件发送,流程实例运行结果邮件告警及容错告警通知
- 失败策略:对于并行运行的任务,如果有任务失败,提供两种失败策略处理方式,继续是指不管并行运行任务的状态,直到流程失败结束。结束是指一旦发现失败任务,则同时Kill掉正在运行的并行任务,流程失败结束
- 补数:补历史数据,支持区间并行和串行两种补数方式
2.2 架构
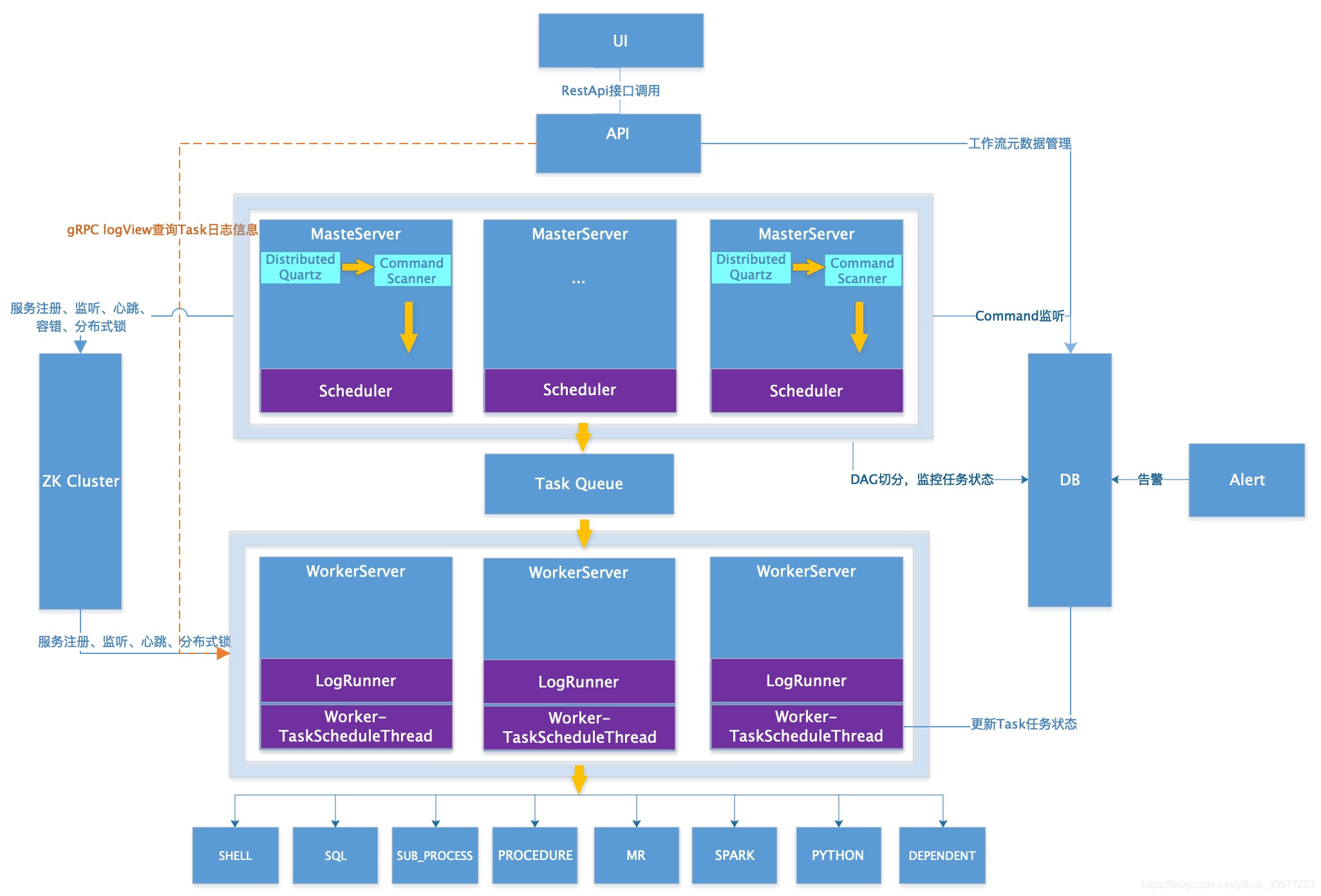
关于更详细的系统架构设计可以查看官方提供的刘小春(xiaochun.liu)一篇博客 DolphinScheduler系统架构设计。
3 部署
3.1 后端部署
后端有2种部署方式,分别为自动化部署和编译源码部署。下面主要介绍下载编译后的二进制包一键自动化部署的方式完成DolphinScheduler后端部署。
3.1.1 基础软件安装
- Mysql (5.5+) : 必装
- JDK (1.8+) : 必装
- ZooKeeper(3.4.6+) :必装
- Hadoop(2.6+) :选装, 如果需要使用到资源上传功能,MapReduce任务提交则需要配置Hadoop(上传的资源文件目前保存在Hdfs上)
- Hive(1.2.1) : 选装,hive任务提交需要安装
- Spark(1.x,2.x) : 选装,Spark任务提交需要安装
- PostgreSQL(8.2.15+) : 选装,PostgreSQL PostgreSQL存储过程需要安装
注意:EasyScheduler本身不依赖Hadoop、Hive、Spark、PostgreSQL,仅是会调用他们的Client,用于对应任务的运行。
3.1.2 创建部署用户
在所有需要部署调度的机器上创建部署用户(本次以node2、node3节点为例),因为worker服务是以 sudo -u {linux-user} 方式来执行作业,所以部署用户需要有 sudo 权限,而且是免密的。
# 1 创建用户
useradd escheduler
# 2 设置 escheduler 用户密码
passwd escheduler
# 3 赋予sudo权限。编辑系统 sudoers 文件
# 如果没有编辑权限,以root用户登录,赋予w权限
# chmod 640 /etc/sudoers
vi /etc/sudoers
# 大概在100行,在root下添加如下
escheduler ALL=(ALL) NOPASSWD: NOPASSWD: ALL
# 并且需要注释掉 Default requiretty 一行。如果有则注释,没有没有跳过
#Default requiretty
########### end ############
# 4 切换到 escheduler 用户
su escheduler
3.1.3 下载并解压
# 1 创建安装目录
sudo mkdir /opt/DolphinScheduler
# 2 将DolphinScheduler赋予给escheduler用户
sudo chown -R escheduler:escheduler /opt/DolphinScheduler
# 3 下载后端。简称escheduler-backend
cd /opt/DolphinScheduler
wget https://github.com/apache/incubator-dolphinscheduler/releases/download/1.1.0/escheduler-1.1.0-backend.tar.gz
# 4 解压
mkdir escheduler-backend
mkdir escheduler
tar -zxf escheduler-1.1.0-backend.tar.gz -C escheduler
cd escheduler/
# 5 目录介绍
[escheduler@node2 escheduler]$ tree -L 1
.
├── bin # 基础服务启动脚本
├── conf # 项目配置文件
├── install.sh # 一键部署脚本
├── lib # 项目依赖jar包,包括各个模块jar和第三方jar
├── script # 集群启动、停止和服务监控启停脚本
└── sql # 项目依赖sql文件
5 directories, 1 file
3.1.4 针对escheduler用户ssh免密配置
# 1 配置SSH免密
# 1.1 node2 节点执行
# 有提示直接回车
ssh-keygen -t rsa
# 拷贝到node2和node3。提示输入密码时,输入 escheduler 用户的密码
ssh-copy-id -i ~/.ssh/id_rsa.pub escheduler@node2
ssh-copy-id -i ~/.ssh/id_rsa.pub escheduler@node3
# 1.2 node3 节点执行
# 有提示直接回车
ssh-keygen -t rsa
# 拷贝到node2和node3。提示输入密码时,输入 escheduler 用户的密码
ssh-copy-id -i ~/.ssh/id_rsa.pub escheduler@node2
ssh-copy-id -i ~/.ssh/id_rsa.pub escheduler@node3
3.1.5 数据库初始化
执行以下命令创建数据库和账号
CREATE DATABASE escheduler DEFAULT CHARACTER SET utf8 DEFAULT COLLATE utf8_general_ci;
-- 设置数据用户escheduler的访问密码为 escheduler,并且不对访问的ip做限制
-- 测试环境将访问设置为所有,如果是生产,可以限制只能子网段的ip才能访问('198.168.33.%')
GRANT ALL PRIVILEGES ON escheduler.* TO 'escheduler'@'%' IDENTIFIED BY 'escheduler';
flush privileges;
创建表和导入基础数据 修改vim /opt/DolphinScheduler/escheduler/conf/dao/data_source.properties中的下列属性
# 大概在第 4 行修改MySQL数据库的url
spring.datasource.url=jdbc:mysql://node1:3306/escheduler?characterEncoding=UTF-8
# URL
spring.datasource.url=jdbc:mysql://192.168.33.3:3306/escheduler?characterEncoding=UTF-8
# 用户名。
spring.datasource.username=escheduler
# 密码。填入上一步IDENTIFIED BY 后面设置的密码
spring.datasource.password=escheduler
执行创建表和导入基础数据脚本
# 前面已进入/opt/DolphinScheduler/escheduler-backend目录下,然后执行数据初始化脚本
# 最后看到 create escheduler success 表示数据库初始化成功
sh ./script/create_escheduler.sh
3.1.6 修改部署目录权限及运行参数
# 1 修改conf/env/目录下的 .escheduler_env.sh 环境变量
vim conf/env/.escheduler_env.sh
# 将对应的修改为自己的组件或框架的路径
export HADOOP_HOME=/opt/hadoop-3.1.2
export HADOOP_CONF_DIR=/opt/hadoop-3.1.2/etc/hadoop
export SPARK_HOME1=/opt/spark-2.3.4-bin-hadoop2.7
#export SPARK_HOME2=/opt/soft/spark2
#export PYTHON_HOME=/opt/soft/python
export JAVA_HOME=/usr/local/zulu8/
export HIVE_HOME=/opt/apache-hive-3.1.1-bin
#export PATH=$HADOOP_HOME/bin:$SPARK_HOME1/bin:$SPARK_HOME2/bin:$PYTHON_HOME:$JAVA_HOME/bin:$HIVE_HOME/bin:$PATH
export PATH=$HADOOP_HOME/bin:$SPARK_HOME1/bin:$JAVA_HOME/bin:$HIVE_HOME/bin:$PATH
# ==========
# CDH 版
# ==========
#export HADOOP_HOME=/opt/cloudera/parcels/CDH-6.2.0-1.cdh6.2.0.p0.967373/lib/hadoop
#export HADOOP_CONF_DIR=/etc/hadoop/conf.cloudera.yarn
#export SPARK_HOME1=/opt/cloudera/parcels/CDH-6.2.0-1.cdh6.2.0.p0.967373/lib/spark
##export SPARK_HOME2=/opt/soft/spark2
##export PYTHON_HOME=/opt/soft/python
#export JAVA_HOME=/usr/local/zulu8/
#export HIVE_HOME=/opt/cloudera/parcels/CDH-6.2.0-1.cdh6.2.0.p0.967373/lib/hive
##export PATH=$HADOOP_HOME/bin:$SPARK_HOME1/bin:$SPARK_HOME2/bin:$PYTHON_HOME:$JAVA_HOME/bin:$HIVE_HOME/bin:$PATH
#export PATH=$HADOOP_HOME/bin:$SPARK_HOME1/bin:$JAVA_HOME/bin:$HIVE_HOME/bin:$PATH
修改 install.sh中的各参数,替换成自身业务所需的值,这里只列出了重要的修改项,其它默认不用改即可。
# mysql配置
# mysql 地址,端口
mysqlHost="192.168.33.3:3306"
# mysql 数据库名称
mysqlDb="escheduler"
# mysql 用户名
mysqlUserName="escheduler"
# mysql 密码
# 注意:如果有特殊字符,请用 \ 转移符进行转移
mysqlPassword="escheduler"
# conf/config/install_config.conf配置
# 注意:安装路径,不要当前路径(pwd)一样。一键部署脚本分发到其它节点时的安装路径
installPath="/opt/DolphinScheduler/escheduler-backend"
# 部署用户
# 注意:部署用户需要有sudo权限及操作hdfs的权限,如果开启hdfs,根目录需要自行创建
deployUser="escheduler"
# zk集群
zkQuorum="192.168.33.3:2181,192.168.33.6:2181,192.168.33.9:2181"
# 安装hosts
# 注意:安装调度的机器hostname列表,如果是伪分布式,则只需写一个伪分布式hostname即可
ips="192.168.33.6,192.168.33.9"
# conf/config/run_config.conf配置
# 运行Master的机器
# 注意:部署master的机器hostname列表
masters="192.168.33.6"
# 运行Worker的机器
# 注意:部署worker的机器hostname列表
workers="192.168.33.6,192.168.33.9"
# 运行Alert的机器
# 注意:部署alert server的机器hostname列表
alertServer="192.168.33.6"
# 运行Api的机器
# 注意:部署api server的机器hostname列表
apiServers="192.168.33.6"
# 用到邮箱发送邮件时务必配置上邮件服务,否则执行结果发送时会提示失败
# cn.escheduler.server.worker.runner.TaskScheduleThread:[249] - task escheduler # failure : send mail failed!
java.lang.RuntimeException: send mail failed!
# alert配置
# 邮件协议,默认是SMTP邮件协议
mailProtocol="SMTP"
# 邮件服务host。以网易邮箱为例。QQ邮箱的服务为 smtp.qq.com
mailServerHost="smtp.163.com"
# 邮件服务端口。SSL协议端口 465/994,非SSL协议端口 25
mailServerPort="465"
# 发送人。
# 网易邮箱在 客户端授权密码 获取,具体可以看下图
mailSender="*******[email protected]"
# 发送人密码
mailPassword="yore***"
# 下载Excel路径
xlsFilePath="/home/escheduler/xls"
#是否启动监控自启动脚本
# 开关变量,在1.0.3版本中增加,控制是否启动自启动脚本(监控master,worker状态,如果掉线会自动启动)
# 默认值为"false"表示不启动自启动脚本,如果需要启动改为"true"
monitorServerState="true"
# 资源中心上传选择存储方式:HDFS,S3,NONE
resUploadStartupType="HDFS"
# 如果resUploadStartupType为HDFS,defaultFS写namenode地址,支持HA,需要将core-site.xml和hdfs-site.xml放到conf目录下
# 如果是S3,则写S3地址,比如说:s3a://escheduler,注意,一定要创建根目录/escheduler
defaultFS="hdfs://192.168.33.3:8020"
# resourcemanager HA配置,如果是单resourcemanager,这里为yarnHaIps=""
yarnHaIps="192.168.33.3"
# 如果是单 resourcemanager,只需要配置一个主机名称,如果是resourcemanager HA,则默认配置就好
singleYarnIp="192.168.33.3"
# common 配置
# 程序路径
programPath="/opt/DolphinScheduler/escheduler-backend"
#下载路径
downloadPath="/tmp/escheduler/download"
# 任务执行路径
execPath="/tmp/escheduler/exec"
# SHELL环境变量路径
shellEnvPath="$installPath/conf/env/.escheduler_env.sh"
# 资源文件的后缀
resSuffixs="txt,log,sh,conf,cfg,py,java,sql,hql,xml"
# api 配置
# api 服务端口
apiServerPort="12345"
如果使用hdfs相关功能,需要拷贝hdfs-site.xml和core-site.xml到conf目录下
cp $HADOOP_HOME/etc/hadoop/hdfs-site.xml conf/
cp $HADOOP_HOME/etc/hadoop/core-site.xml conf/
网易云邮箱服务客户端用户名和密码获取,开启客户端授权码,并获取。
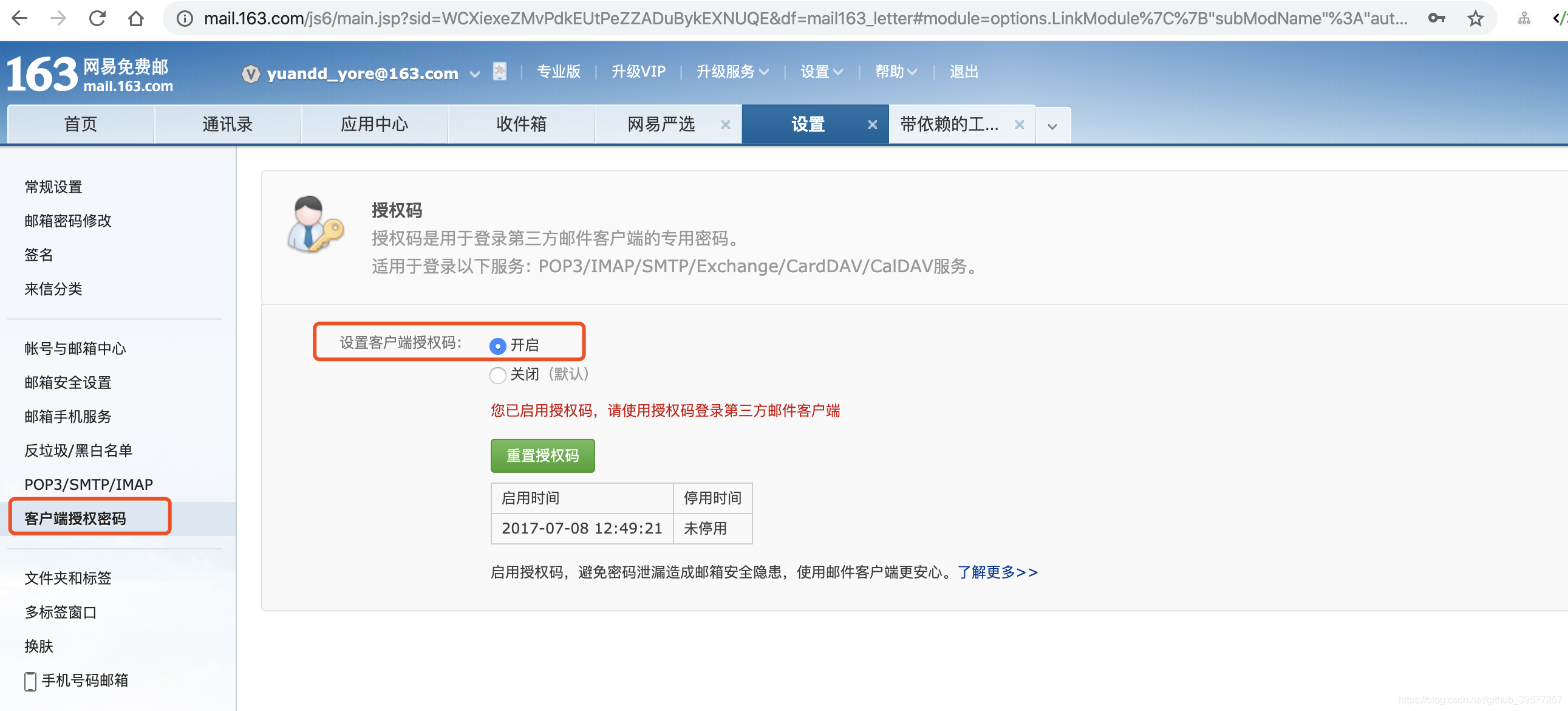
如果 DolphinScheduler 已经安装,则可以通过设置部署的后端服务下的conf/alert.properties文件
#alert type is EMAIL/SMS
alert.type=EMAIL
# mail server configuration
mail.protocol=SMTP
# 以网易邮箱为例
mail.server.host=smtp.163.com
# SSL协议端口 465/994,非SSL协议端口 25
mail.server.port=465
mail.sender=*******[email protected]
mail.passwd=yore***
# TLS
mail.smtp.starttls.enable=false
# SSL
mail.smtp.ssl.enable=true
#xls.file.path=/home/escheduler/xls
xls.file.path=/home/escheduler/xls
# Enterprise WeChat configuration
enterprise.wechat.corp.id=xxxxxxxxxx
enterprise.wechat.secret=xxxxxxxxxx
enterprise.wechat.agent.id=xxxxxxxxxx
enterprise.wechat.users=xxxxx,xxxxx
enterprise.wechat.token.url=https://qyapi.weixin.qq.com/cgi-bin/gettoken?corpid=$corpId&corpsecret=$secret
enterprise.wechat.push.url=https://qyapi.weixin.qq.com/cgi-bin/message/send?access_token=$token
enterprise.wechat.team.send.msg={\"toparty\":\"$toParty\",\"agentid\":\"$agentId\",\"msgtype\":\"text\",\"text\":{\"content\":\"$msg\"},\"safe\":\"0\"}
enterprise.wechat.user.send.msg={\"touser\":\"$toUser\",\"agentid\":\"$agentId\",\"msgtype\":\"markdown\",\"markdown\":{\"content\":\"$msg\"}}
3.1.7 执行脚本一键部署
# 1 一键部署并启动
sh install.sh
# 2 查看日志
[escheduler@node2 escheduler-backend]$ tree /opt/DolphinScheduler/escheduler/logs
/opt/DolphinScheduler/escheduler/logs
├── escheduler-alert.log
├── escheduler-alert-server-node-b.test.com.out
├── escheduler-alert-server.pid
├── escheduler-api-server-node-b.test.com.out
├── escheduler-api-server.log
├── escheduler-api-server.pid
├── escheduler-logger-server-node-b.test.com.out
├── escheduler-logger-server.pid
├── escheduler-master.log
├── escheduler-master-server-node-b.test.com.out
├── escheduler-master-server.pid
├── escheduler-worker.log
├── escheduler-worker-server-node-b.test.com.out
├── escheduler-worker-server.pid
└── {processDefinitionId}
└── {processInstanceId}
└── {taskInstanceId}.log
# 3 查看Java进程
# 3.1 node2
# jps -l | grep escheduler
[escheduler@node2 escheduler-backend]$ jps
31651 WorkerServer # worker服务
31784 ApiApplicationServer # api服务
31609 MasterServer # master服务
31743 AlertServer # alert服务
31695 LoggerServer # logger服务
# 3.2 node3
[escheduler@cdh3 DolphinScheduler]$ jps
26678 WorkerServer
26718 LoggerServer
错误1:如果查看/opt/DolphinScheduler/escheduler/logs/escheduler-api-server-*.out日志报如下错误
nohup: failed to run command ‘/bin/java’: No such file or directory
解决:将JAVA_HOME/bin下的java软连接到/bin下。(每个dolphinscheduler节点都执行)
ln -s $JAVA_HOME/bin/java /bin/java
3.1.8 dolphinscheduler后端服务启停
# 启动
/opt/DolphinScheduler/escheduler/script/start_all.sh
# 停止
/opt/DolphinScheduler/escheduler/script/stop_all.sh
3.2 前端部署
前端有3种部署方式,分别为自动化部署,手动部署和编译源码部署。这里主要使用自动化脚本方式部署DolphinScheduler前端服务。
3.2.1 下载并解压
# 1 下载 UI 前端。简称escheduler-ui
# 在node2节点下的 /opt/DolphinScheduler
wget https://github.com/apache/incubator-dolphinscheduler/releases/download/1.1.0/escheduler-1.1.0-ui.tar.gz
# 2 解压
mkdir escheduler-ui
tar -zxf escheduler-1.1.0-ui.tar.gz -C escheduler-ui
cd escheduler-ui
3.2.2 执行自动化部署脚本
执行自动化部署脚本。脚本会提示一些参数,根据提示完成安装。
[escheduler@cdh2 escheduler-ui]$ sudo ./install-escheduler-ui.sh
欢迎使用easy scheduler前端部署脚本,目前前端部署脚本仅支持CentOS,Ubuntu
请在 escheduler-ui 目录下执行
linux
请输入nginx代理端口,不输入,则默认8888 :8888
请输入api server代理ip,必须输入,例如:192.168.xx.xx :192.168.33.6
请输入api server代理端口,不输入,则默认12345 :12345
=================================================
1.CentOS6安装
2.CentOS7安装
3.Ubuntu安装
4.退出
=================================================
请输入安装编号(1|2|3|4):2
……
Complete!
port option is needed for add
FirewallD is not running
setenforce: SELinux is disabled
请浏览器访问:http://192.168.33.6:8888
使用自动化部署脚本会检查系统环境是否安装了Nginx,如果没有安装则会通过网络自动下载Nginx包安装,通过引导设置后的Nginx配置文件为/etc/nginx/conf.d/escheduler.conf。但生产环境一般法法访问外网,此时可以通过手动离线安装Nginx,然后进行一些配置即可。
# 1 下载 Nginx 离线安装包
# 例如下载 Cento7 CPU指令为 x86版本的
wget http://nginx.org/packages/mainline/centos/7/x86_64/RPMS/nginx-1.17.6-1.el7.ngx.x86_64.rpm
# 2 安装
rpm -ivh nginx-1.17.6-1.el7.ngx.x86_64.rpm
下面在手动再Nginx中添加一个DolphinSchedule 服务配置。因为在 /etc/nginx/nginx.conf(Nginx默认加载的配置文件)中有include /etc/nginx/conf.d/*.conf ;,所以我们可以在 /etc/nginx/conf.d/ 下创建一个 conf后缀的配置文件,配置文件的文件名随意,例如叫 escheduler.conf。这里需要特别注意的是在 /etc/nginx/nginx.conf 配置文件中前面有一个配置 user nginx 如果启动Nginx的用户不是 nginx,一定要修改为启动Nginx的用户,否则代理的服务会报 403 的错误。这里我们在/etc/nginx/conf.d/escheduler.conf配置如下内容,重点在 server 中配置 listen(DolphinSchedule Web UI 的端口)、**root **(解压的escheduler-ui 中的 dist 路径 )、proxy_pass (DolphinSchedule后台接口的地址)等信息。最后重启Nginx执行命令 systemctl restart nginx。
server {
listen 8888; # 访问端口
server_name localhost;
#charset koi8-r;
#access_log /var/log/nginx/host.access.log main;
location / {
root /opt/DolphinScheduler/escheduler-ui/dist; # 上面前端解压的dist目录地址(自行修改)
index index.html index.html;
}
location /escheduler {
proxy_pass http://192.168.33.6:12345; # 接口地址(自行修改)
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header x_real_ipP $remote_addr;
proxy_set_header remote_addr $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_http_version 1.1;
proxy_connect_timeout 4s;
proxy_read_timeout 30s;
proxy_send_timeout 12s;
proxy_set_header Upgrade $http_upgrade;
proxy_set_header Connection "upgrade";
}
#error_page 404 /404.html;
# redirect server error pages to the static page /50x.html
#
error_page 500 502 503 504 /50x.html;
location = /50x.html {
root /usr/share/nginx/html;
}
}
问题1:上传文件大小限制
编辑配置文件 vim /etc/nginx/nginx.conf
# 更改上传大小
client_max_body_size 1024m
3.2.3 dolphinscheduler前端服务启停
# 1 启动
systemctl start nginx
# 2 状态
systemctl status nginx
# 3 停止
#nginx -s stop
systemctl stop nginx
4 快速开始
浏览器访问http://192.168.33.6:8888,如下图所示。
在上述页面登陆默认的管理员用户。成功登陆有主页面如下所示
- 用户名:admin
- 密码: escheduler123
创建一个队列。队列管理 -> 创建队列 -> 输入名称和队列值 -> 提交。
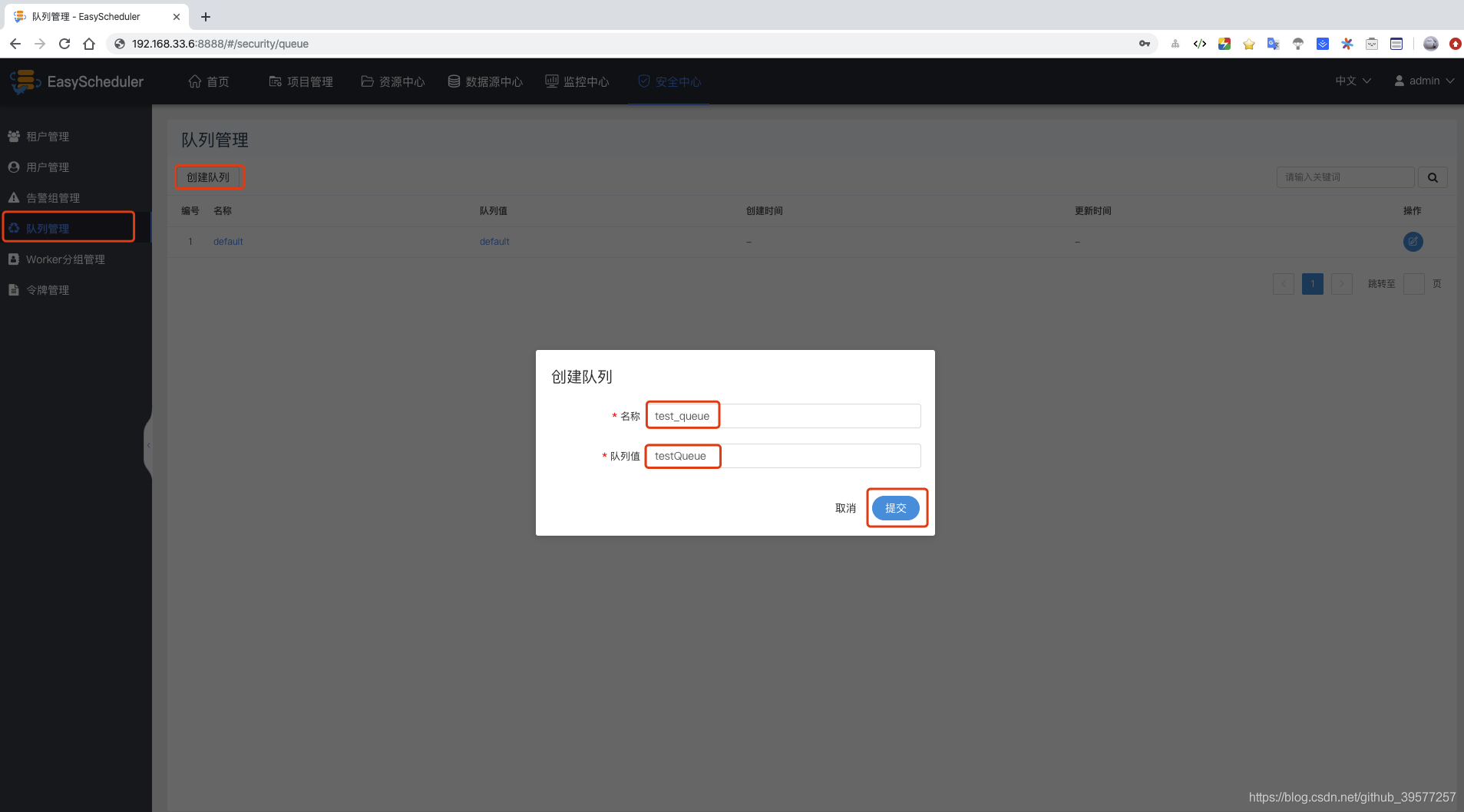
创建租户。租户管理 -> 创建租户 -> 输入租户编码、租户名称和队列值 -> 提交。
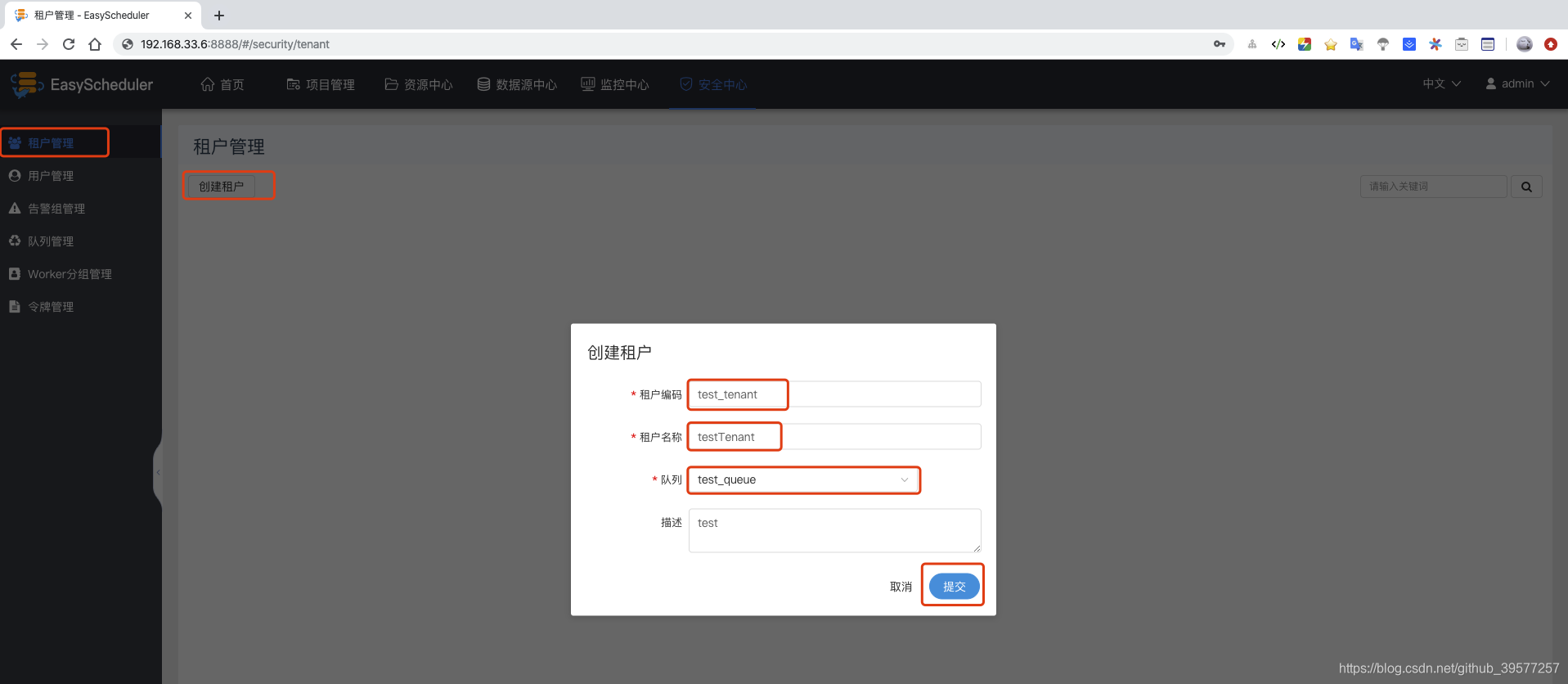
创建普通用户。用户管理 -> 创建用户 -> 输入用户名称、密码、租户名和邮箱,手机号选填 -> 提交。
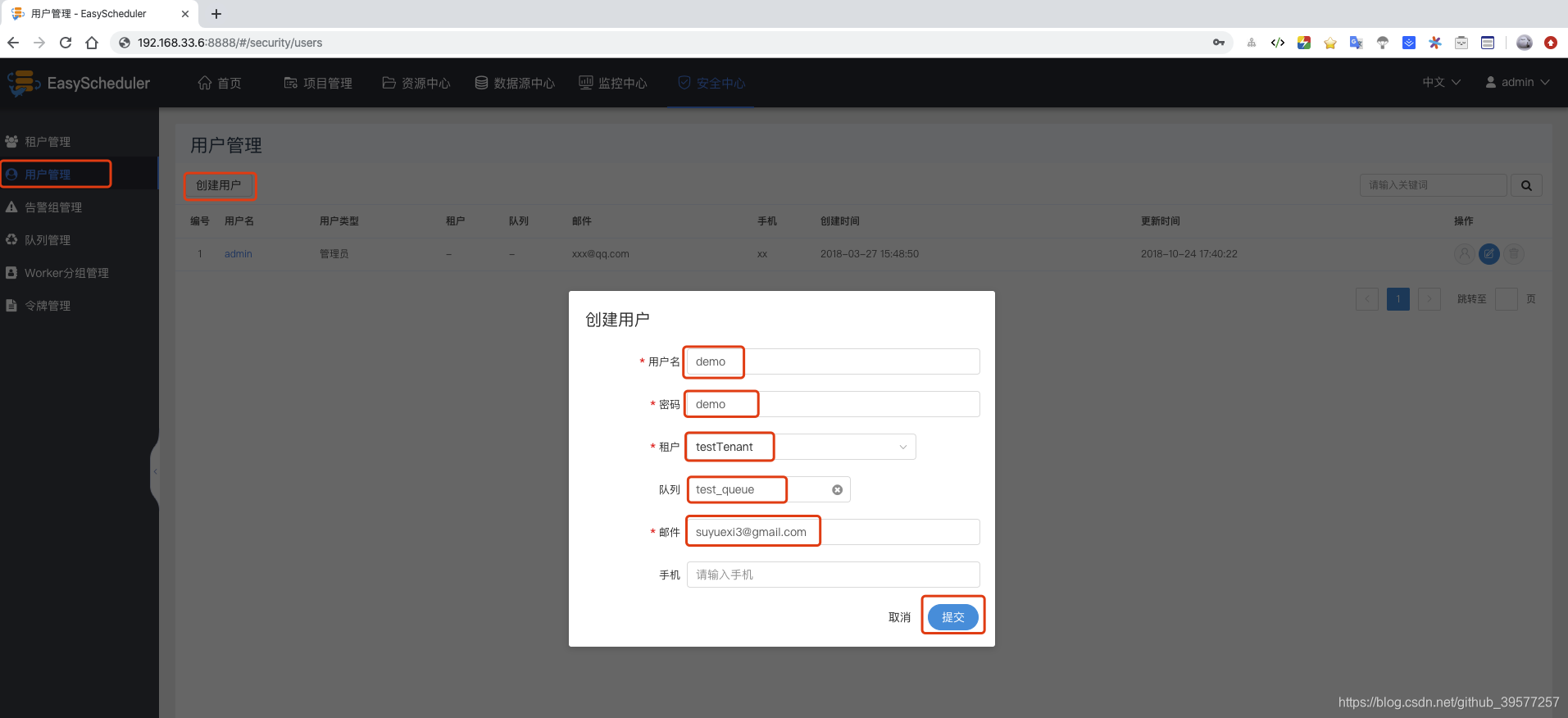
创建警告组。警告组管理 -> 创建警告组 -> 输入组名称、组类型(邮件、短信)-> 提交。
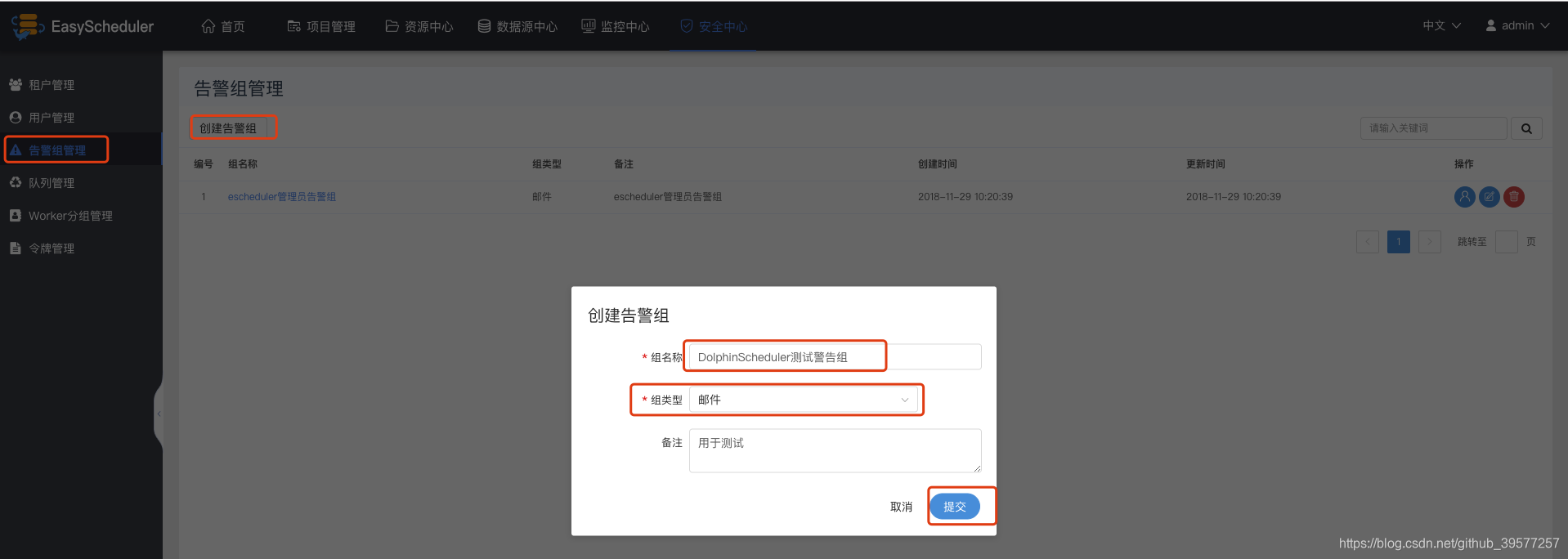
使用普通用户登录(用户名和密码都是demo)。点击右上角用户名“退出”,重新使用普通用户登录。登陆成功的首页如下。
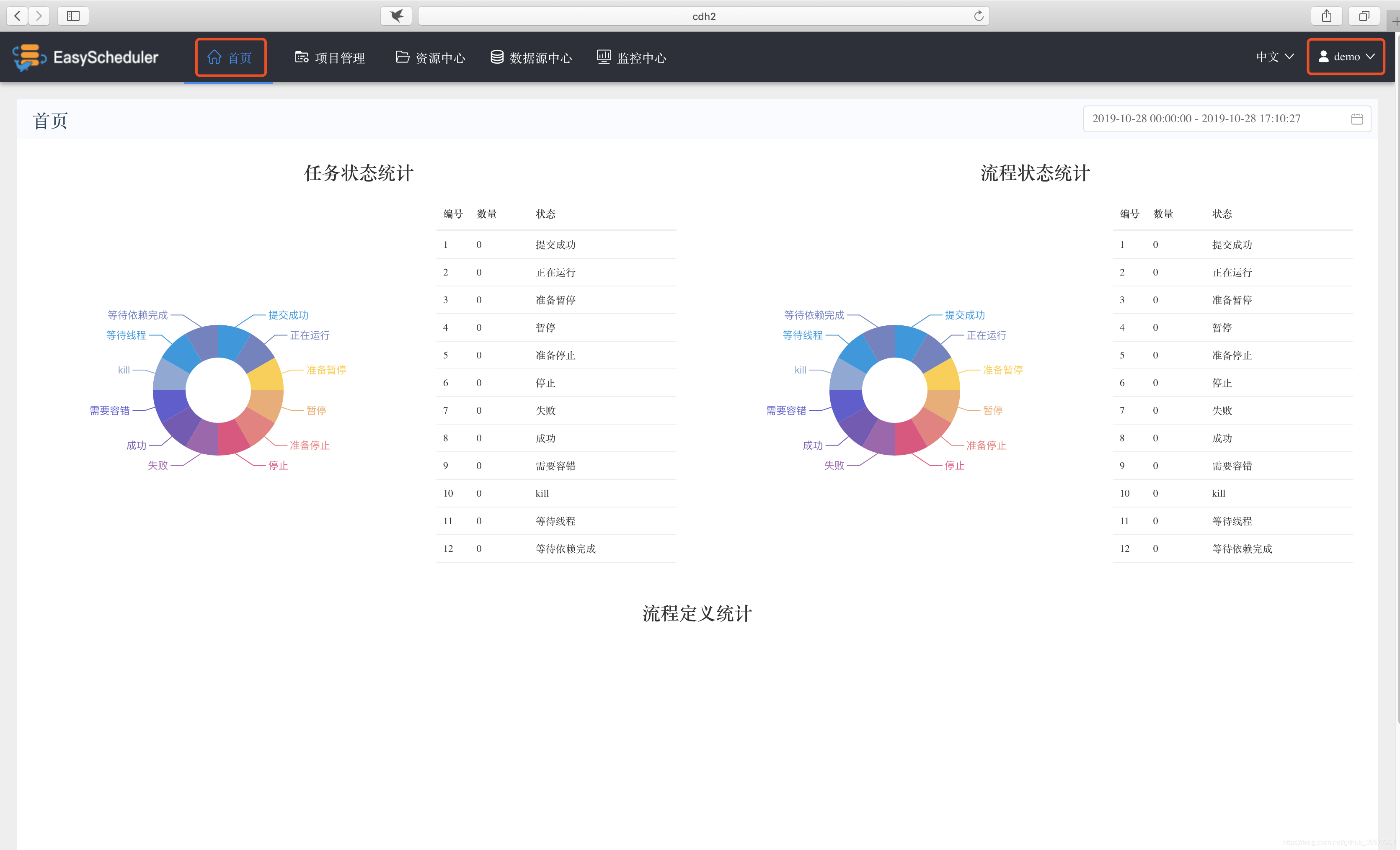
创建一个项目。点击页面头部的项目管理,进入项目页面,再点击创建项目,创建一个DolphinScheduler任务调度项目,在弹出的框中输入项目名称和描述,例如这里创建一个hello_dolphinScheduler名称的项目,最后点击提交。
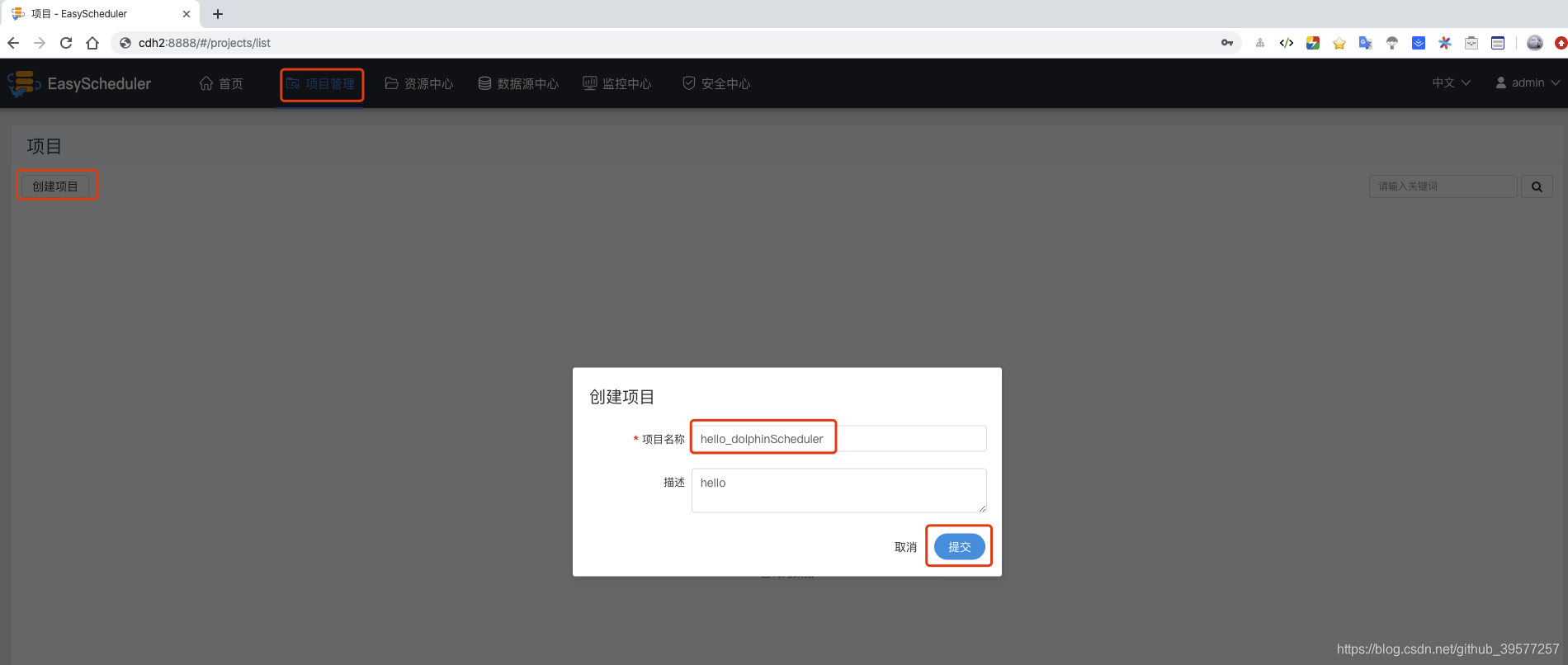
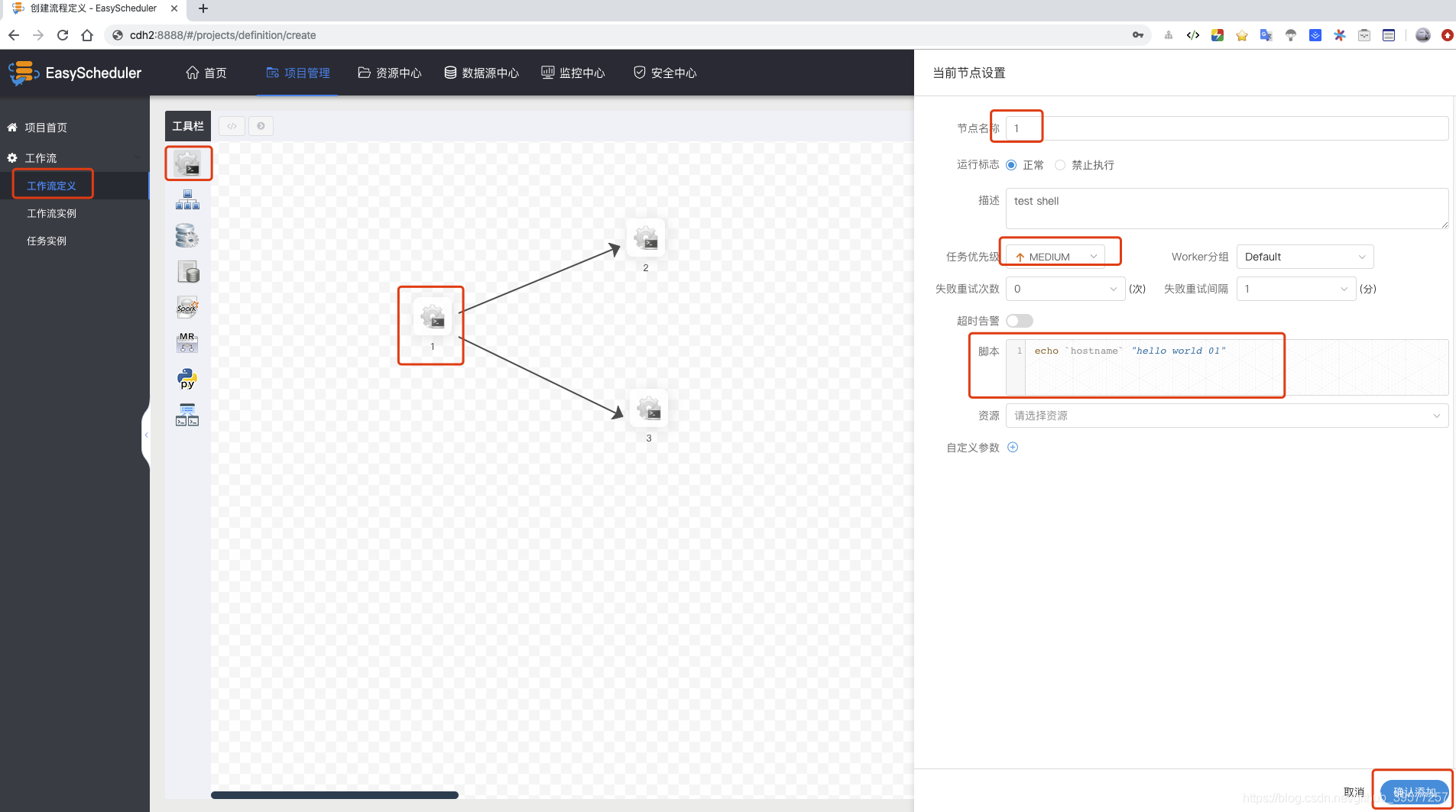
项目创建完毕后,在项目管理页面点击我们创建的项目,进入该项目的管理页面。点击工作流定义 -> 创建工作流 -> 在左侧工具栏可以选择(SHELL、USB_PROCESS、PROCEDURE、SQL、SPARK、MapReduce、PYTHON、DEPENDENT)。拖拽SHELL节点到画布,新增一个Shell任务,填写 节点名称、描述、脚本 字段;选择 任务优先级 ,级别高的任务在执行队列中会优先执行,相同优先级的任务按照先进先出的顺序执行;超时告警, 填写 超时时长 ,当任务执行时间超过超时时长可以告警并且超时失败。(注意:这里的节点不是机器的节点,而应该是工作流的节点)
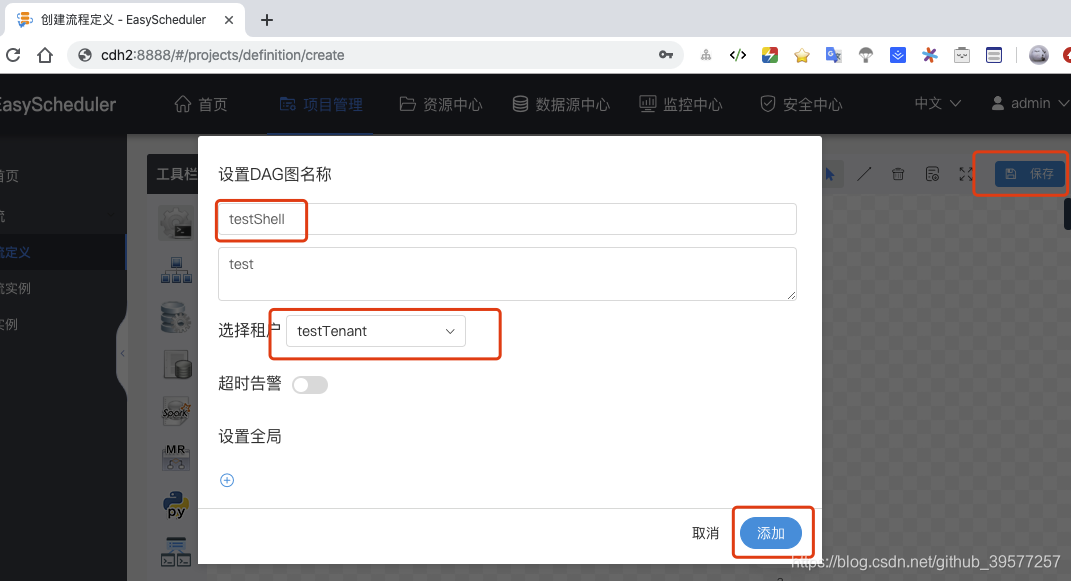
确认修改完毕后,点击保存,此时设置DAG图名称,选择组租户,最后添加。
未上线状态的工作流定义可以编辑,但是不可以运行,所以要执行工作流,需要先上线工作流
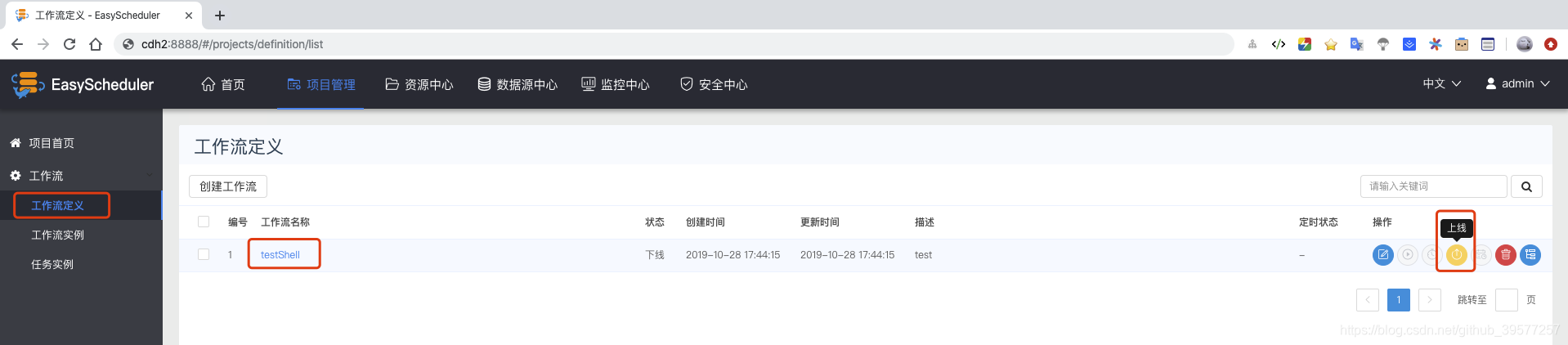
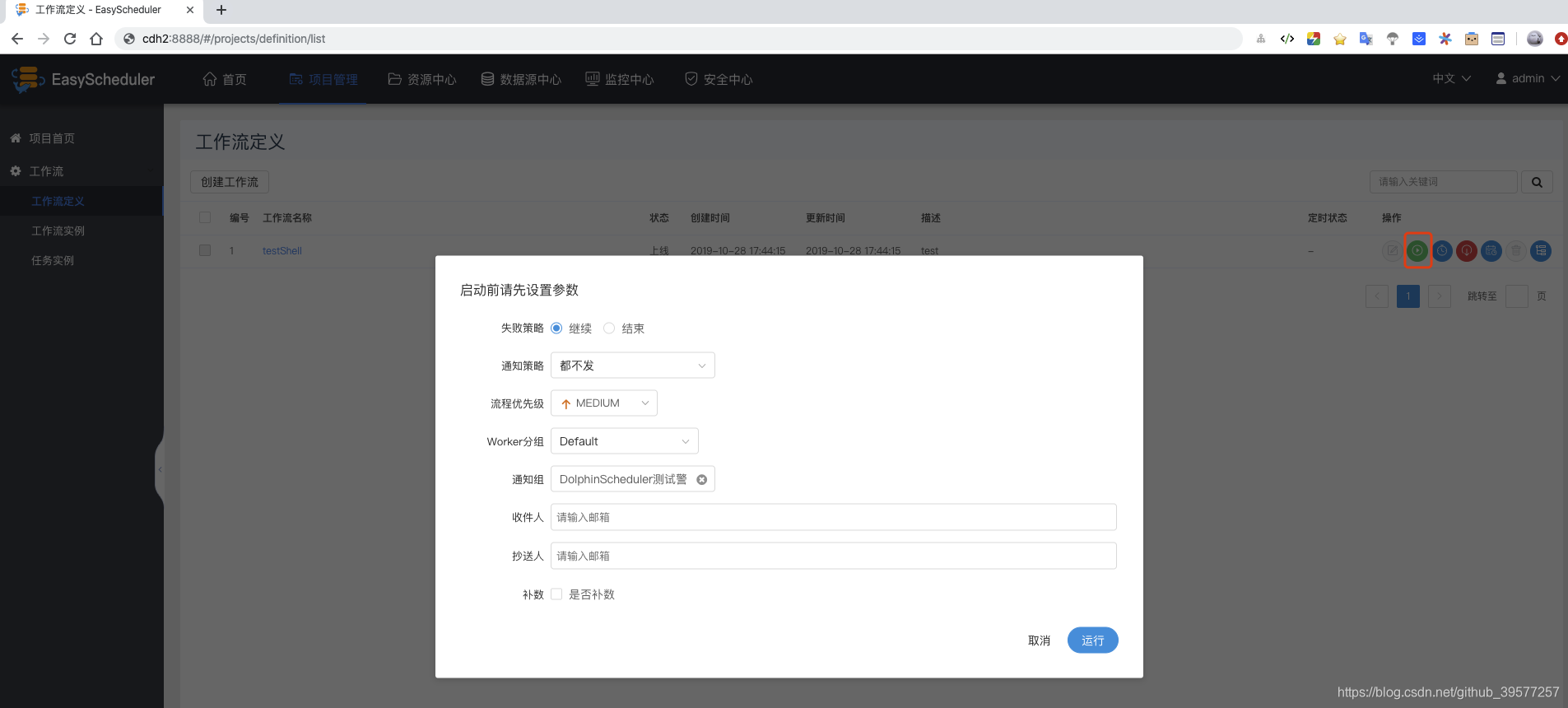
点击”运行“,执行工作流。运行参数说明:
- 失败策略:当某一个任务节点执行失败时,其他并行的任务节点需要执行的策略。”继续“表示:其他任务节点正常执行,”结束“表示:终止所有正在执行的任务,并终止整个流程。
- 通知策略:当流程结束,根据流程状态发送流程执行信息通知邮件。
- 流程优先级:流程运行的优先级,分五个等级:最高(HIGHEST),高(HIGH),中(MEDIUM),低(LOW),最低(LOWEST)。级别高的流程在执行队列中会优先执行,相同优先级的流程按照先进先出的顺序执行。
- worker分组: 这个流程只能在指定的机器组里执行。默认是Default,可以在任一worker上执行。
- 通知组: 当流程结束,或者发生容错时,会发送流程信息邮件到通知组里所有成员。
- 收件人:输入邮箱后按回车键保存。当流程结束、发生容错时,会发送告警邮件到收件人列表。
- 抄送人:输入邮箱后按回车键保存。当流程结束、发生容错时,会抄送告警邮件到抄送人列表。
点击任务实例可以查看每个任务的列表信息,点击操作栏,可以看到任务执行的日志信息。

5 Worker分组和数据源添加
worker分组,提供了一种让任务在指定的worker上运行的机制。管理员创建worker分组,在任务节点和运行参数中设置中可以指定该任务运行的worker分组,如果指定的分组被删除或者没有指定分组,则该任务会在任一worker上运行。worker分组内多个ip地址(不能写别名),以英文逗号分隔。
用管理员用户(admin)登陆Web页面,点击 安全中心 -> Worker分组管理,如下图所示。
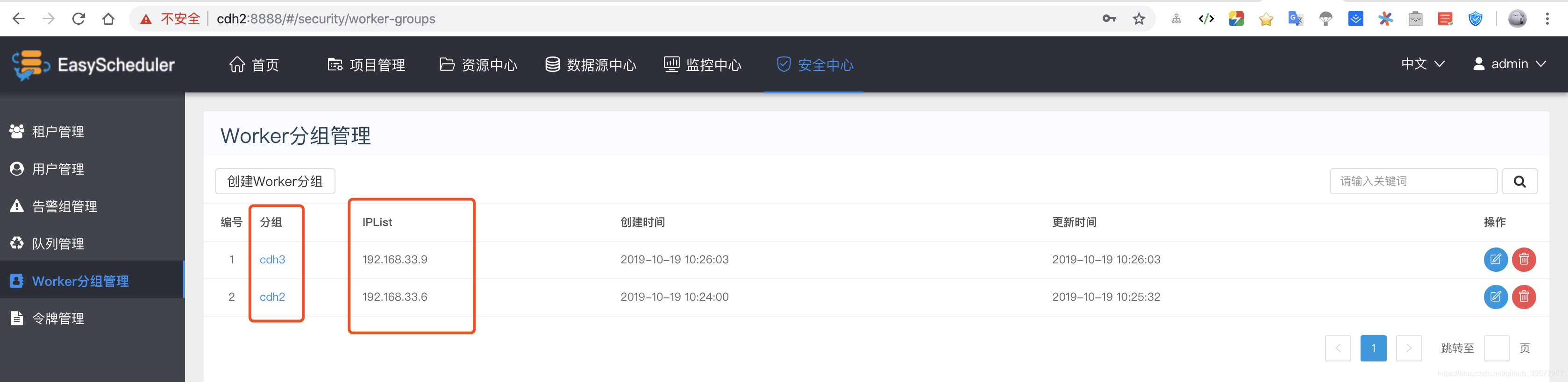
创建Worker分组。填写组名称和IP,IP可以是多个,用英文逗号分割即可。

例如下图,我们将Worker的IP分为了两组。
6 添加数据源
脚本(一般是SQL脚本)执行时可能会用到一些数据源,例如MySQL、PostgreSQL、Hive、Impala、Spark、ClickHouse、Oracle、SQL Server,通过添加数据源在DolphinScheduler页面编写Job时直接选择,不用再指定驱动、连接、用户名和密码等信息,可以快速创建一个SQL脚本的工作流Job,同时这个数据源时用户隔离的,每个用户添加的数据源相互独立(admin用户除外,管理员用户可以看到所有用户添加的数据源)。
下面我们以Impala为例,选择页面头部的 数据源中心 -> 添加数据源,会弹出下图 编辑数据源 弹窗,主要填写如下几项。因为Impala没有设置密码,用户为必填可以任意添加一个,在jdbc连接参数中必须添加 {"auth":"noSasl"}参数,否则会一直等待确认认证。
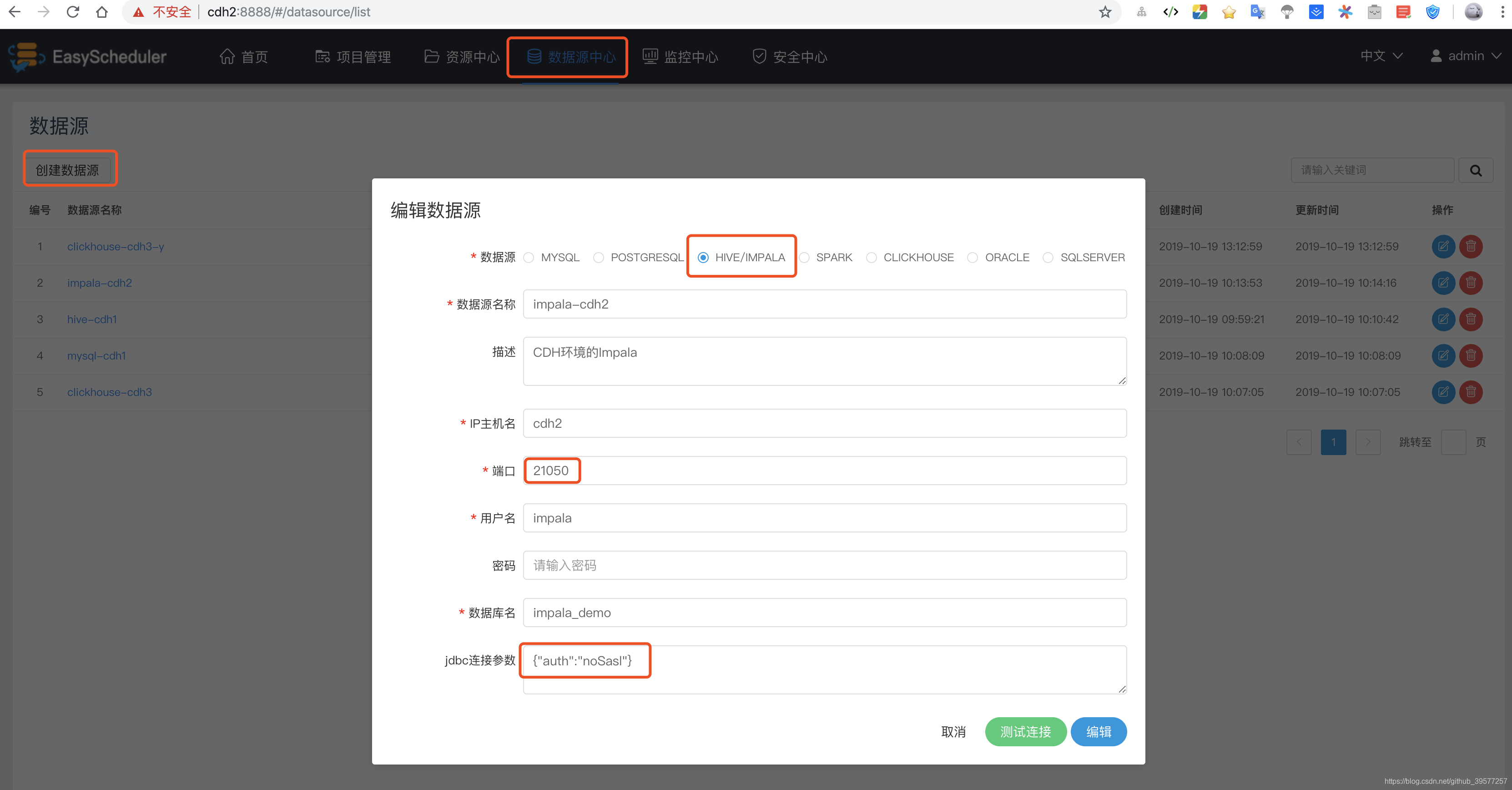
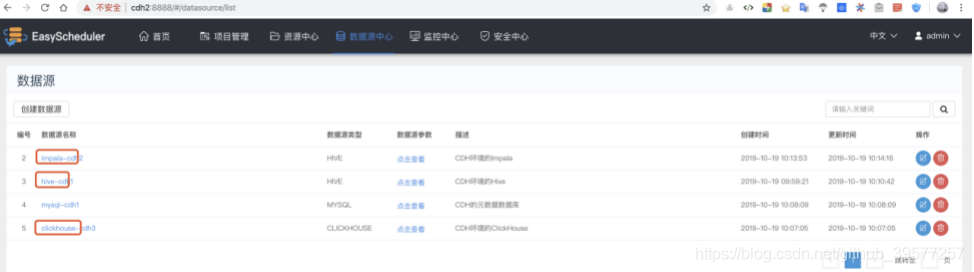
其它数据源类似,例如我们添加如下几个数据源,后面会用到ClickHouse(详见我的另一篇博客 ClickHouse的安装(含集群方式)和使用)。
7 实例
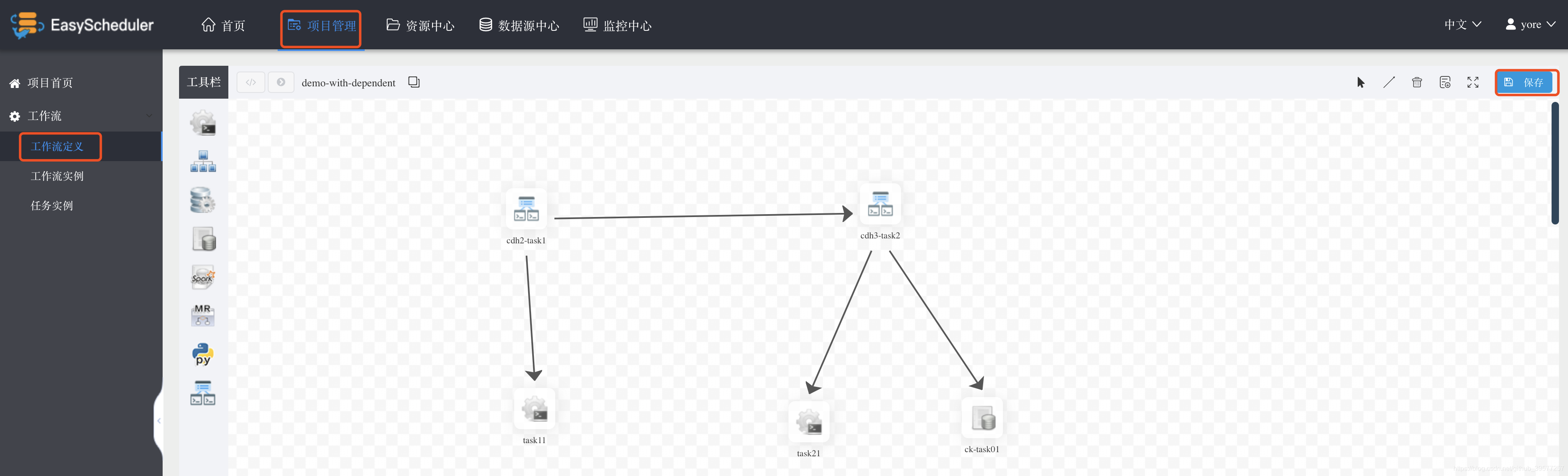
在项目管理下,点击工作流定义,在工具栏处选择最后一行的DEPENDENT定义一个带依赖的工作流Job,拖动到编辑面板,设置task的节点名为cdh2-task1,在 Worker分组 中选择执行的Worker节点为cdh2,编辑完这个Task后选择 确认添加。选择执行的Worker分组名,这里选择前面设置的cdh2组,确认添加,如下图所示。同样的方式设置第二个依赖Task,将其Worker分组设置到cdh3节点,并添加依赖为 且。

接下来设置两个Shell执行脚本,cdh2-task11上执行task11,主要是在cdh2上执行一个hostname命令,打印执行节点的HostName。同样的方式,在依赖节点cdh3-task21上设置在cdh3执行,也是执行hostname命令。最后再在依赖节点cdh3-task21上添加一个SQL脚本,查询我们的豆瓣电影数据,具体操作如下
- 在工具栏拖拽添加一个SQL脚本Task节点;
- 节点名称可以叫:
ck-task01,并添加描述信息; - Worker分组:
cdh3; - 数据源:
CLICKHOUSEclickhouse-cdh3; - sql类型选择查询。
√表格; - 邮件信息:填写主题。收件人邮箱、抄送人邮箱;
- sql语句:
SELECT m.id,m.movie_name,m.rating_num,m.rating_people,q.rank,q.quote FROM movie m
LEFT JOIN quote q
ON q.id=m.id
ORDER BY m.rating_num DESC,m.rating_people DESC LIMIT 10;
各个task编写完毕后,选择右上角的 选择线条连接,工作流编写完毕后如下图,最后点击保存,输入DAG图名称,并选择租户,选择添加保存。
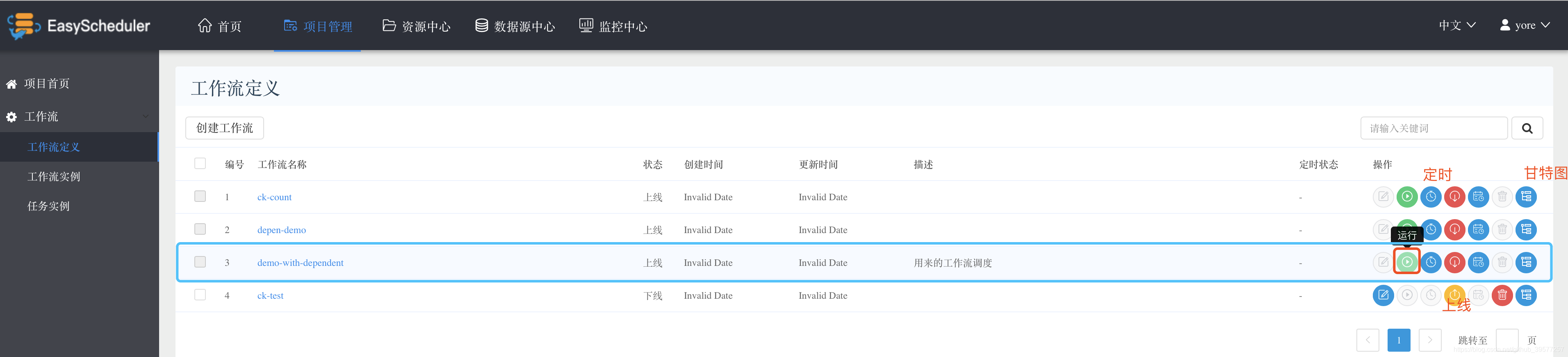
回到工作流定义,可以看到新添加的当前用户的所有工作流列表,点击右侧的操作栏的 上线,然后点击 运行 执行我们的工作流。当然这里也可以添加 定时 调度。
点击运行后,可以在 工作流实例 页面看到当前运行的Job的状态信息。每个工作可能会有多个Task构成,查看Task的执行信息可以在 任务实例 页面查看,操作栏可以查看这个task的执行日志信息。如果执行成功后,可以选择工作流的甘特图,在时间轴上查看执行状况。

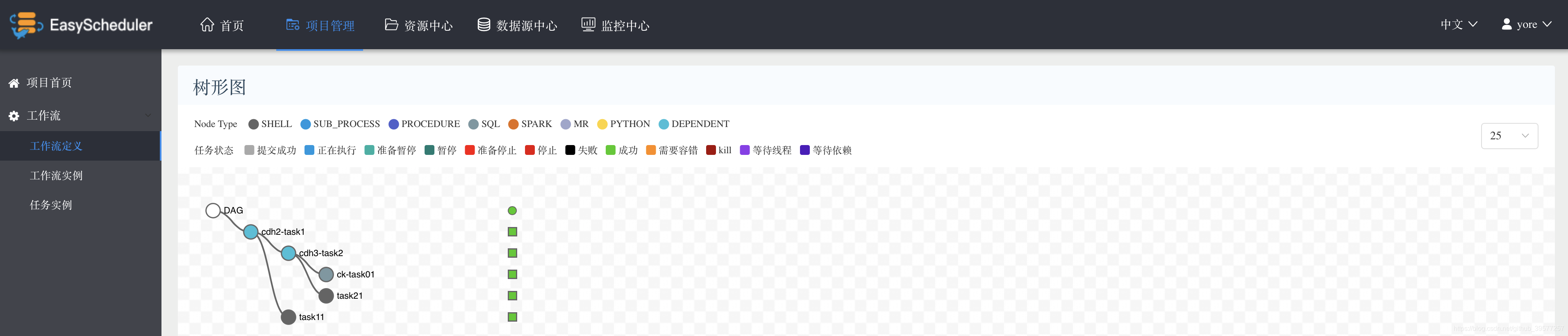
也可以查看工作流的执行的树形图信息,如下图。
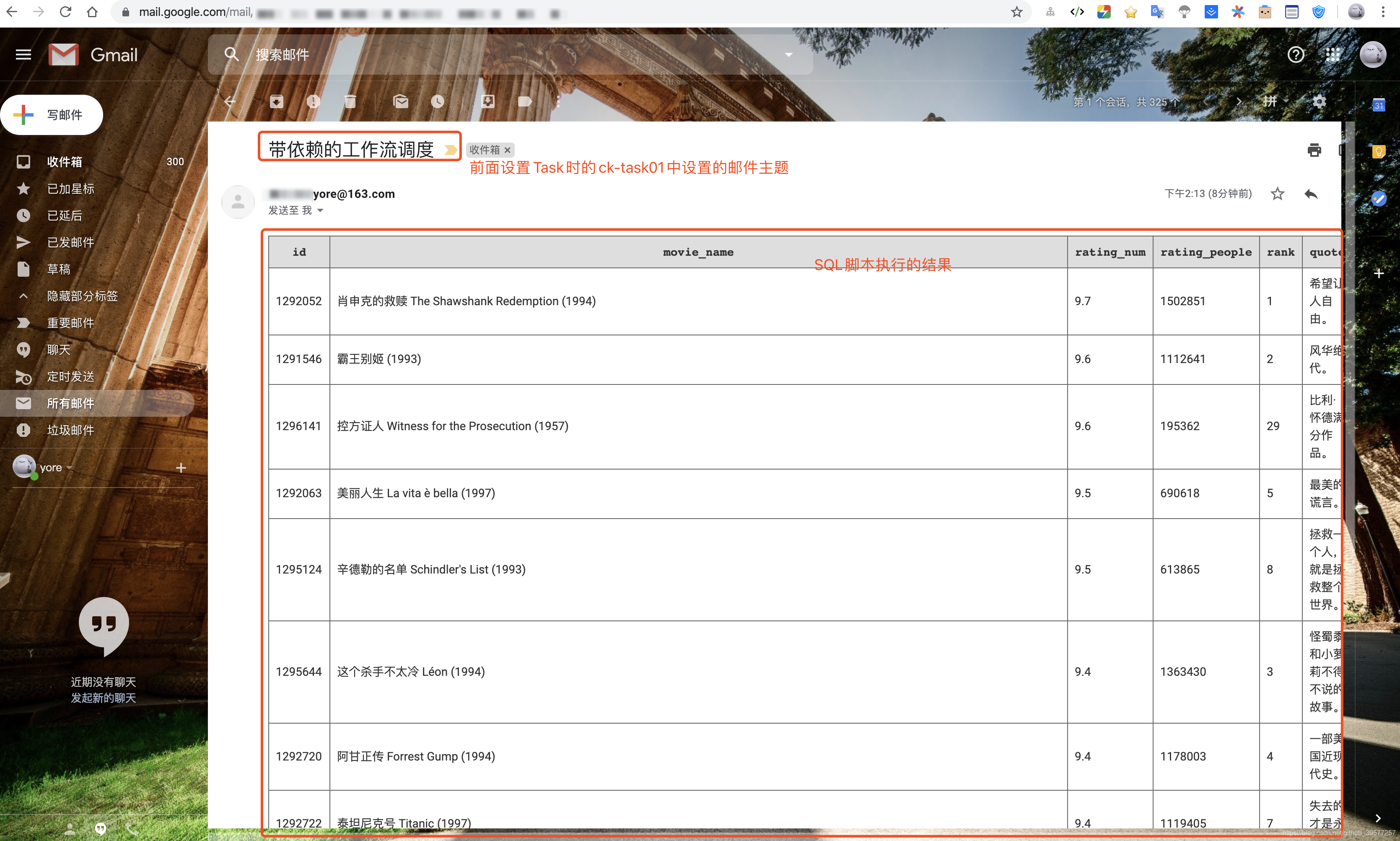
运行成功后填写的收件箱会接收到执行结果的一封邮件,这封邮件中包含了脚本执行的结果。
8 与 Azkaban 的对比
| Class | Item | DolphinScheduler | Azkaban |
|---|---|---|---|
| 稳定性 | 单点故障 | 去中心化的多 Master 和多 Worker | 是,单个 Web 和调度程序组合节点 |
| HA额外要求 | 不需要(本身就支持HA) | DB | |
| 过载处理 | 任务队列机制,单个机器上可调度的任务数量可以灵活配置,当任务过多时会缓存在任务队列里,不会造成机器卡死 | 任务太多会卡死服务器 | |
| 易用性 | DAG监控界面 | 任务状态、任务类型、重试次数、任务运行机器、可视化变量等关键信息一目了然 | 只能看到任务状态 |
| 可视化流程定义 | 是,所有流程定义操作都是可视化的,通过拖拽任务来绘制DAG,配置数据源及资源,同时对于第三方系统提供API方式的操作 | 否,通过自定义DSL绘制DAG打包上传 | |
| 快速部署 | 一键部署 | 集群化部署,复杂 | |
| 功能 | 是否能暂停和恢复 | 支持暂停、恢复操作 | 否,只能先将工作流杀死再重新运行 |
| 是否支持多租户 | 支持。DolphinScheduler上的用户可以通过租户和Hadoop用户实现多对一或一对一的映射关系,这对于大数据作业上的调度是非常重要的 | 否 | |
| 任务类型 | 支持传统的shell任务,同时支持大数据平台任务调度MR、Spark、SQL(MySQL、PostgreSQL、Hive、SparkSQL、Impala、ClickHouse、Oracle)、Python、Procedure、Sub_Process | shell、gobblin、hadoopJava、Java、Hive、Pig、Spark、hdfsToTeradata、teradataToHdfs | |
| 契合度 | 支持大数据作业Spark、Hive、MR的调度,同时由于支持多租户,于大数据业务更加契合 | 由于不支持多租户,在大数据平台业务使用上不够灵活 | |
| 扩展性 | 是否支持自定义任务类型 | 是 | 是 |
| 是否支持集群扩展 | 是,调度器使用分布式调度,整体的调度能力会随着集群的规模线性增长,Master和Worker支持动态上下线 | 是,但是复杂,Executor水平扩展 |
9 小节
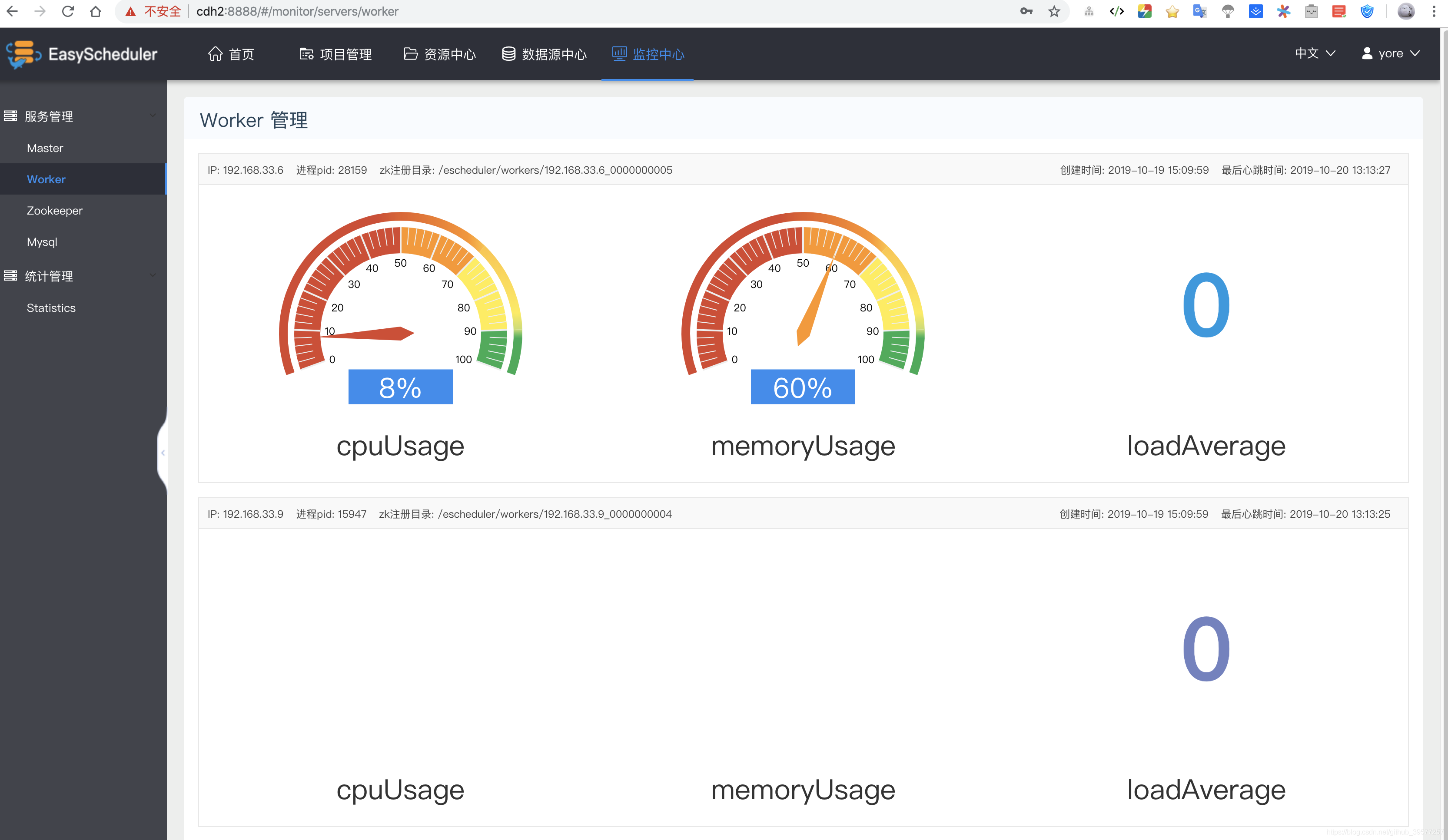
Apache DolphinScheduler是一个分布式、去中心化、易扩展的可视化DAG工作流任务调度系统,从上面的安装可以看到这个调度系统集成了ZooKeeper,很好的实现了去中心化,每个角色的服务可以起多个,从znode上可以看到masters和workers的一些元信息都注册在了上面,交由ZK去选举,当然它也是一个分布式的。如果某个服务挂了,ZooKeeper会在剩下的其它节点进行选举,例如当某些节点的Worker服务挂了,我们不用做任何处理,DolphinScheduler上依然可以正常提交和执行工作,在它的监控中心的页面可以看到,系统自动选举出了一个新的Work节点。
# znode上的信息
[zk: localhost:2181(CONNECTED) 1] ls /escheduler
[tasks_queue, dead-servers, masters, lock, workers, tasks_kill]
尤其可以多Worker进行分组以及添加数据源的功能,可以指定Wroker节点,直接指定改用户下的数据,执行SQL脚本,同时页面增加的监控中心、任务状态统计、流程状态统计、流程定义统计等也能很好的帮助我们管理和查看任务执行的信息和集群的状态。
