这篇文章详细阐述了Ray和Apache Arrow之间的集成。解决的主要问题是数据序列化。
查阅Wikipedia,序列化指:
将数据结构或对象状态转换为可以存储...或传输的格式的过程...以及稍后重建(可能在不同的计算机环境中) |
为什么需要上述的转换?
当你创建一个Python对象时,它可能指向其他Python对象,并且这些对象都分配在不同的内存区域中,并且所有这些都必须在另一台机器上的另一个进程上处理才有意义。 |
序列化和反序列化是并行和分布式计算的瓶颈,尤其是在具有大型对象和大量数据的机器学习应用程序中。
设计目标
由于Ray针对机器学习和AI应用程序进行了优化,因此我们将重点放在序列化和数据处理上,并具有以下设计目标:
对于大型数值数据(包括NumPy数组和Pandas DataFrames,以及递归包含Numpy数组和Pandas DataFrames的对象),它应该非常高效。
对于一般的Python类型,它应该和Pickle一样快。
它应该支持共享内存,允许多个进程使用相同的数据而不复制它。
反序列化应该非常快(如果可能,它不应该要求读取整个序列化对象)。
它应该是与语言无关的(最终我们希望Python worker能够使用Java或其他语言的worker创建的对象,反之亦然)。
方法和替代方案
Python中的首选序列化方法是pickle模块。 Pickle很通用,特别是如果你使用像cloudpickle这样的变种。 但是,它不满足要求1,3,4或5.像json这样的替代品满足5,但不满足1-4。
我们的方法:为了满足要求1-5,我们选择使用Apache Arrow格式作为基础数据表示。 与Apache Arrow团队合作,我们构建了用于将常规Python对象映射到Arrow格式和从Arrow格式映射的库。 这种方法的一些属性:
数据布局与语言无关(要求5)。
可以在恒定时间内计算序列化数据blob的偏移量而无需读取整个对象(要求1和4)。
Arrow支持零拷贝读取,因此对象可以自然地存储在共享内存中并由多个进程使用(要求1和3)。
对于我们无法处理的任何对象,我们自然可以回到使用pickle(要求2)。
Arrow的替代方案:我们可以构建在Protocol Buffers之上,但协议缓冲区确实不是为大数据设计的,而且这种方法不能满足1,3或4.建立在Flatbuffers之上的实际上可以做到,但它需要实现Arrow已经拥有的许多工具,我们更喜欢更适合大数据的列式数据布局。
加速比
在这里,我们展示了Python的pickle模块的一些性能改进。实验使用pickle.HIGHEST_PROTOCOL完成。生成这些图的代码包含在帖子的末尾。
使用NumPy数组:在机器学习和AI应用中,数据(例如,图像,神经网络权重,文本文档)通常表示为包含NumPy数组的数据结构。 使用NumPy数组时,加速速度非常重要。
Ray反序列化几乎没花时间,这不是一个错误。 这是支持零拷贝读取的结果(节省的主要原因是缺乏内存移动)。


请注意,最大的赢点是反序列化。 这里的加速比是多个数量级,并且随着NumPy数组变大而变得更好(归功于设计目标1,3和4)。 快速进行反序列化很重要,原因有两个。
1)对象可能只序列化一次而进行多次反序列化(例如,向所有worker广播的对象)。
2)一个常见的模式是许多对象并行序列化,然后在单个worker上一次聚合和反序列化,使反序列化成为瓶颈。
没有NumPy数组:当使用常规Python对象时,我们无法利用共享内存,结果则与pickle相差不多。


这些只是有趣的Python对象的几个例子。 最重要的情况是NumPy数组嵌套在其他对象中的情况。 请注意,我们的序列化库适用于非常通用的Python类型,包括自定义Python类和深层嵌套对象。
The API
序列化库可以通过pyarrow直接使用,如下所示。 这里有更多文档。
x = [(1, 2), 'hello', 3, 4, np.array([5.0, 6.0])]
serialized_x = pyarrow.serialize(x).to_buffer()
deserialized_x = pyarrow.deserialize(serialized_x)它可以直接通过Ray API使用,如下所示。
x = [(1, 2), 'hello', 3, 4, np.array([5.0, 6.0])]
x_id = ray.put(x)
deserialized_x = ray.get(x_id)数据表示
我们使用Apache Arrow作为底层语言无关的数据布局。 对象存储在两个部分中:schema和blob数据。 在较高级别,blob数据大致是递归包含在对象中的所有数据值的扁平串联,并且schema定义数据blob的类型和嵌套结构。
技术细节:Python序列(例如,字典,列表,元组,集合)被编码为其他类型的Arrow UnionArrays(例如,bool,int,字符串,字节,浮点数,双精度数,date64s,tensor(即NumPy数组)),列表 ,元组,词组和集合)。 嵌套序列使用Arrow ListArrays进行编码。 收集所有tensor并将其附加到序列化对象的末尾,UnionArray包含对这些tensor的引用。
举一个具体的例子,考虑下列对象。
[(1, 2), 'hello', 3, 4, np.array([5.0, 6.0])]它将在Arrow中表示为以下结构。
UnionArray(type_ids=[tuple, string, int, int, ndarray],
tuples=ListArray(offsets=[0, 2],
UnionArray(type_ids=[int, int],
ints=[1, 2])),
strings=['hello'],
ints=[3, 4],
ndarrays=[<offset of numpy array>])Arrow使用Flatbuffers编码序列化schema。 仅使用schema,我们可以计算数据blob中每个值的偏移量,而无需扫描数据blob(与Pickle不同,这是实现快速反序列化的原因)。 这意味着我们可以避免在反序列化期间复制或以其他方式转换大型数组和其他值。 Tensor附加在UnionArray的末尾,可以使用共享内存进行有效共享和访问。
请注意,实际对象将在内存中分布,如下所示。
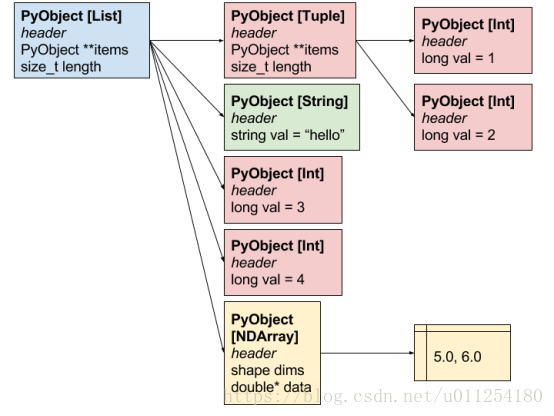
堆中Python对象的布局。 每个框分配在不同的内存区域,框之间的箭头表示指针。
Arrow序列化表示如下。

Arrow-序列化对象的内存布局。
再现上面所说的figures
作为参考,可以使用以下代码再现figures。 对ray.put和ray.get进行基准测试,而不是pyarrow.serialize和pyarrow.deserialize,但都得到相似的figures。
import pickle
import pyarrow
import matplotlib.pyplot as plt
import numpy as np
import timeit
def benchmark_object(obj, number=10):
# Time serialization and deserialization for pickle.
pickle_serialize = timeit.timeit(
lambda: pickle.dumps(obj, protocol=pickle.HIGHEST_PROTOCOL),
number=number)
serialized_obj = pickle.dumps(obj, pickle.HIGHEST_PROTOCOL)
pickle_deserialize = timeit.timeit(lambda: pickle.loads(serialized_obj),
number=number)
# Time serialization and deserialization for Ray.
ray_serialize = timeit.timeit(
lambda: pyarrow.serialize(obj).to_buffer(), number=number)
serialized_obj = pyarrow.serialize(obj).to_buffer()
ray_deserialize = timeit.timeit(
lambda: pyarrow.deserialize(serialized_obj), number=number)
return [[pickle_serialize, pickle_deserialize],
[ray_serialize, ray_deserialize]]
def plot(pickle_times, ray_times, title, i):
fig, ax = plt.subplots()
fig.set_size_inches(3.8, 2.7)
bar_width = 0.35
index = np.arange(2)
opacity = 0.6
plt.bar(index, pickle_times, bar_width,
alpha=opacity, color='r', label='Pickle')
plt.bar(index + bar_width, ray_times, bar_width,
alpha=opacity, color='c', label='Ray')
plt.title(title, fontweight='bold')
plt.ylabel('Time (seconds)', fontsize=10)
labels = ['serialization', 'deserialization']
plt.xticks(index + bar_width / 2, labels, fontsize=10)
plt.legend(fontsize=10, bbox_to_anchor=(1, 1))
plt.tight_layout()
plt.yticks(fontsize=10)
plt.savefig('plot-' + str(i) + '.png', format='png')
test_objects = [
[np.random.randn(50000) for i in range(100)],
{'weight-' + str(i): np.random.randn(50000) for i in range(100)},
{i: set(['string1' + str(i), 'string2' + str(i)]) for i in range(100000)},
[str(i) for i in range(200000)]
]
titles = [
'List of large numpy arrays',
'Dictionary of large numpy arrays',
'Large dictionary of small sets',
'Large list of strings'
]
for i in range(len(test_objects)):
plot(*benchmark_object(test_objects[i]), titles[i], i)