顺序搜索法:
补充:循环首次适应算法介绍
每次为进程分配空间的时候,从上一次刚分配过的空闲区的下一块开始寻找,比如,初始化的内存空闲区是用户输入的max大小,没有进行回收之前之前必定是只有最后一块是空闲的,但是经过回收之后,你设定的表(这里是设定了一张表,也可以用俩张,但是一张就可以解决的没必要俩张),从是空闲区的区号开始分配之后,标记此块,下次分配从标记的这一块开始向下寻找,符合就分配,然后标记分配的空闲区区号,与首次适应算法的区别就在这
一、最先(首次)适应算法(first fit,FF)
通俗来讲就是:把进程尽量往低地址空闲区域放,放不下的话在更加地址慢慢升高。
每一次存放,都从最低地址开始寻找满足的空闲区域,直至最高地址。即每次存放都从0开始。
特点
- 算法优先使用 低地址 部分空闲区,在低址空间造成许多小的空闲区,在高地址空间保留大的空闲区。
- 选取满足申请长度要求且起始地址最小的空闲区域。
- 空闲区域按照 起始地址 从小到大 的次序以此记录在空闲区域表中。
优点
- 尽量使用低地址空间,使在高地址可能形成较大的空闲区域。为以后到达的大作业分配大的内存空间创造了条件。
缺点
- 可能会分隔位于低地址的较大空闲区域。
- 低址部分不断被划分,会留下许多难以利用的,很小的空闲分区,称为碎片。
二、下次适应算法(next fit,NF)
该算法是在FF算法的基础上进行改进的,大体上与FF算法相似,而不同点就是:
FF算法每次存储都是从0开始寻找符合要求的空闲区域;
NF算法每次存储都是接着上次分配区域的下一个地址;
特点
- 该算法是对FF算法的一种改进。
- 自上次分配空闲空间区域的下一个位置开始,选取第一个可满足的空闲区域。
优点
- 空闲区域分布和分配更加均匀。
缺点
- 可能会分隔大的空闲区域,导致以后到达的大作业无较大的空闲区域。
三、最佳适应算法(best fit,BF)
该算法和FF算法相似,每当进程申请空间的时候,系统都是从头部开始查找。
空闲区域是从小到大记录的,每次查找都从最小的开始,直到查找的满足要求的最小空闲区域。
特点
- 在分配内存空间时取满足申请要求且长度最小的空闲区域。
- 空闲区域按照长度“由小到大”的次序以此记录于空闲区域表中。
优点
- 尽量不分割大的空闲区域。
缺点
- 可能会形成许多非常小以致以后无法使用的的空闲空间,即外部碎片。
四、最坏适应算法(worst fit,WF)
该算法与BF算法相反,BF是用最小的空闲区域来存储东西,而WF是用最大的空闲区域来存储。
特点
- 在分配空间时选取满足申请要求且长度“最大”的空闲区域。
- 空闲区域按照长度“由大到小”的次序以此记录于空闲区域表中。
优点
- 避免形成外部碎片
缺点
- 会分隔大的空闲区域,可能当遇到较长存储空间的进程时无法满足其要求。
例题
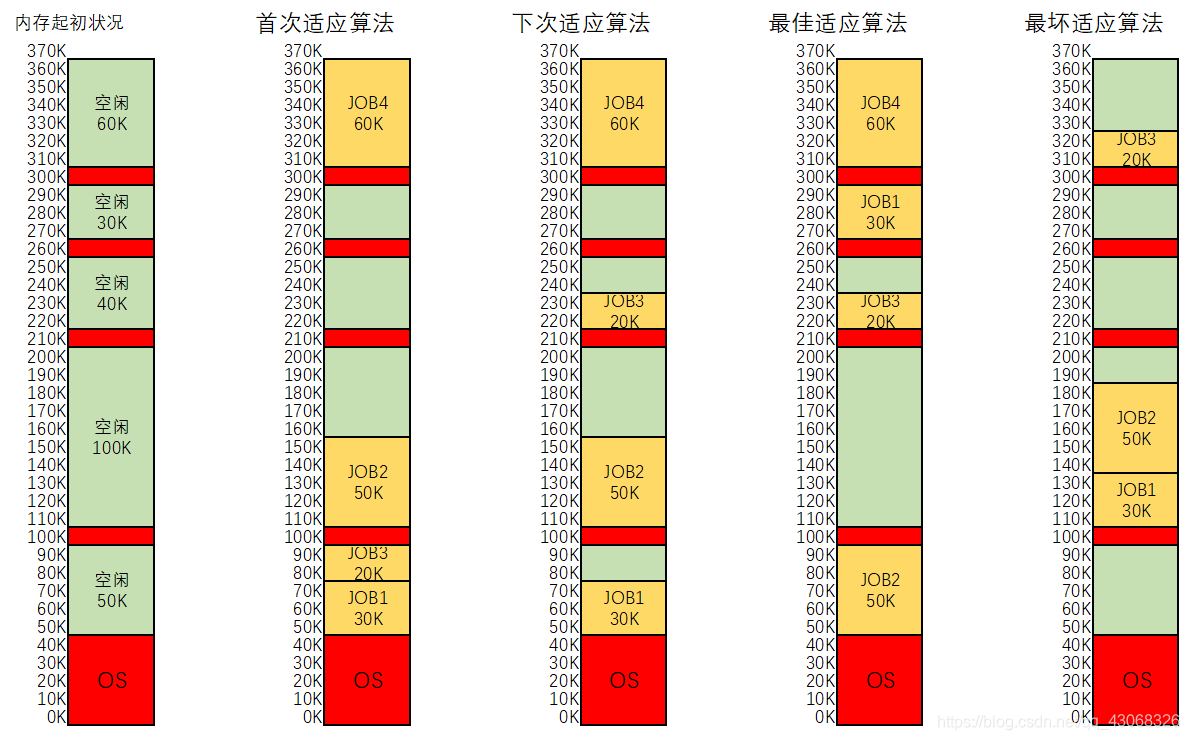
下图中,最左边的是内存的初始情况,现在需要将4个进程依次放入输入井中,等待系统放入内存。
JOB1 30K
JOB2 50K
JOB3 20K
JOB4 60K
红色:已经占用的空间。
绿色:空闲空间。
黄色:上述4个进程占用的空间。