pandans数据结构、数据查询、数据处理
一、Pandas数据结构
| 维数 | 名称 | 描述 |
|---|---|---|
| 1 | Series | 带标签的一维同构数组 |
| 2 | DateFrame | 带标签的,大小可变的,二维异构表格 |
1.1 Series
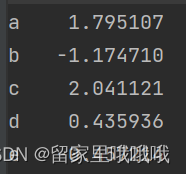
# data为多维数组
s=pd.Series(np.random.randn(5),index=['a','b','c','d','e'])
pd.Series(np.random.randn(6)) #左边索引,右边数据
print(s)
结果显示:
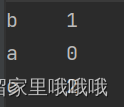
# data为字典,使用Python字典创建Series
d = {
'b': 1, 'a': 0, 'c': 2}
s = pd.Series(d)
print(s)
结果显示:
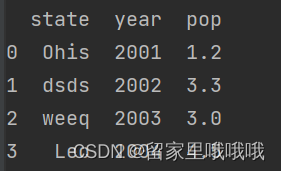
1.2 DataFrame
data ={
'state':['Ohis','dsds','weeq','Leo'],
'year':[2001,2002,2003,2004],
'pop':[1.2,3.3,3,4.5]
}
df = pd.DataFrame(data)
print(df)
结果显示:
1.2.1 查看DataFrame的规格
df.shape
结果显示的是(行,列)
二、数据查询
从DateFrame查询出Series——如果查询多列、多行,返回的是pd.DataFram,如果是一行、一列,返回的就是pd.Series
2.1 查询行/列
print(df['year']) #查询某列
print(df[['year','pop']]) #查询多列
print(df.loc[1]) #查询到第二行的数据与列名
print(df.loc[1:3]) #查询多行
2.2 查看前几行数据
print(df.head(2)) # 查看前几行数据,默认五行
2.2.1 df.loc查询方法
# 前一个是索引值,后一个是要查的数据
df.loc[index, '列名'] #单个label值查询数据
df.loc[index, ['列名1','列名2']] #得到一个Series
# 使用值列表批量查询
df.loc[[index1,index2],'列名']
# 使用数值区间进行范围查询,有按行区间与列区间或两者结合
# 如print(df.loc[0.351:0.672,'no1':'no3'])
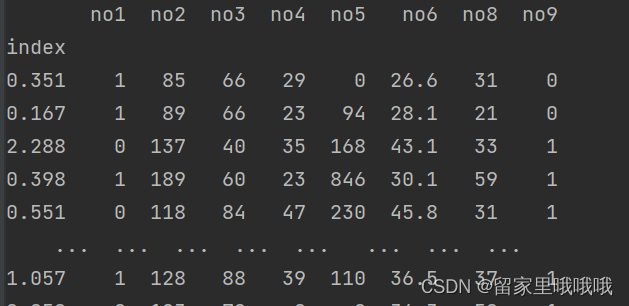
2.2.2 使用条件表达式查询
组合条件用&符号合并,每一个条件判断都得带括号
print(df.loc[df['no1'] <= 1, :]) # 观察df['no1']<=1这个条件
2.2.3 调用函数查询
#直接写lambda表达式
print(df.loc[lambda df: (df['no1'] >= 8) & (df['no3'] >= 15), :])
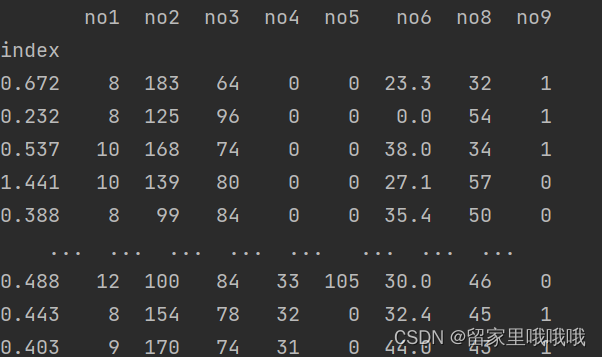
2.2.4 编写自己的函数,查询9月份,空气质量好的数据
def query_my_func(df):
return df.index.str.startswith('2022-09') & df['qi'] == 1
# df.index.str.startswith(pat)语句用来查看元素是否以pat开头
print(df.loc[query_my_func, :])
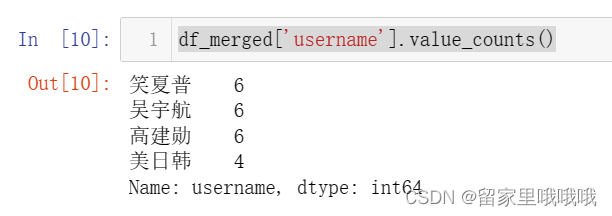
2.3查看某一列不同值的数量
三、Pandas数据处理
3.1 分组求平均值、最大值、最小值
g=data.groupby('药物').mean()
g=data.groupby('药物').apply(lambda t: t[t.剂量==t.剂量.max()])
g=data.groupby('药物').apply(lambda t: t[t.剂量==t.剂量.min()])
3.2 去除重复的行
#以m列名为标准
b=df.drop_duplicates('m',keep='first')
print(b)
3.3 合并两个DataFrame/融合两个表
pd.concat([df1,df2],ignore_index=True)
#使用ignore_index=True忽略原来的索引,使用join="inner"过滤掉不匹配的列
import pandas as pd
left = pd.read_excel('./data/表1.xlsx')
right = pd.read_excel('./data/表2.xlsx')
rel= pd.merge(left,right,how='left')
rel.to_excel('./data/1.xlsx')
3.4 数据列按照逗号进行分行处理
#归经处理分析
medical = pd.read_excel('./data/处方药物属性.xlsx')
#去除多余的字符,然后分割列
df_test = medical["归经"].str.split(',',expand=True)
# 行转列
df_test = df_test.stack()
#重置索引
df_test = df_test.reset_index(level = 1,drop = True).rename("归经")
# 合并
df = medical.drop(['归经'],axis=1).join(df_test)
3.5 数据排序
df.sort_values(by='频次',inplace=True)
3.6 删除多列/行
指定了哪一个axis,就是这个axis要动起来(类似被fro遍历)
#axis=1,删除列
df = df.drop(['归经','五味','药物拼音','剂量'],axis=1)
#axis=0,删除行,index=1的值删除
df.drop(1,axis=0)
3.7 添加一/多列Series
#添加一列Series
s1 = pd.Series(list(range(5)),name='F')
s2 = df1.apply(lambda x:x['A']+'_GG',axis=1) #A这一列统一加上后缀_GG
s2.name="G"
pd.concat([df1,s1,s2],axis=1)
3.8 两变量如何取消绑定
import copy
medical =['NO.', 'Outlook', 'temperature', 'humidity', 'windy', 'play']
newlabel = copy.deepcopy(medical)
medical.remove('NO.')
print(medical)
print(newlabel)
结果为:[ ‘Outlook’, ‘temperature’, ‘humidity’, ‘windy’, ‘play’]
[‘NO.’, ‘Outlook’, ‘temperature’, ‘humidity’, ‘windy’, ‘play’]
如果只是单纯的newlabel = medical,则结果为:
[ ‘Outlook’, ‘temperature’, ‘humidity’, ‘windy’, ‘play’]
[ ‘Outlook’, ‘temperature’, ‘humidity’, ‘windy’, ‘play’]