重要的一些步骤
1.将下面的字典创建为DataFrame¶
data = {
"grammer":['Python', 'C', 'Java', 'GO', np.NaN, 'SQL', 'PHP', 'Python'],
"score":[1.0, 2.0, np.NaN, 4.0, 5.0, 6.0, 7.0, 10.0]}
df = pd.DataFrame(data)
df
| grammer | score | |
|---|---|---|
| 0 | Python | 1.0 |
| 1 | C | 2.0 |
| 2 | Java | NaN |
| 3 | GO | 4.0 |
| 4 | NaN | 5.0 |
| 5 | SQL | 6.0 |
| 6 | PHP | 7.0 |
| 7 | Python | 10.0 |
2.交换两列位置
#方法2
cols = df.columns[[1,0]]
df = df[cols]
df
| popularity | grammer | |
|---|---|---|
| 0 | 1.0 | Python |
| 1 | 2.0 | C |
| 2 | 3.0 | Java |
| 3 | 4.0 | GO |
| 4 | 5.0 | NaN |
| 5 | 6.0 | SQL |
| 6 | 7.0 | PHP |
| 7 | 10.0 | Python |
3.提取popularity列最大值所在行
df[df['popularity'] == df['popularity'].max()]
| popularity | grammer | |
|---|---|---|
| 7 | 10.0 | Python |
4. 随机生成20个0-100的随机整数:Numpy.random.randint()
np.random.randint(0, 100, 20)
array([72, 68, 6, 41, 22, 63, 27, 43, 55, 26, 60, 89, 29, 83, 23, 68, 37,
70, 42, 31])
5.生成20个0-100固定步长的数:Numpy.arange()
np.arange()函数分为一/两/三个参数三种情况:
- 一个参数时,参数值为终点,起点取默认值0,步长取默认值1。
- 两个参数时,第一个参数为起点,第二个参数为终点,步长取默认值1。
- 三个参数时,第一个参数为起点,第二个参数为终点,第三个参数为步长。其中步长支持小数
np.arange(0, 100, 5)
array([ 0, 5, 10, 15, 20, 25, 30, 35, 40, 45, 50, 55, 60, 65, 70, 75, 80,
85, 90, 95])
6. 生成20个指定分布(如标准正态分布)的数:Numpy.random.normal()
np.random.normal(0, 1, 20)
array([-0.20191223, 0.71407157, -0.9127828 , -0.65248936, 1.06513536,
0.31551879, -0.71842129, -0.75766808, 0.488825 , -1.15330714,
-0.50300377, -0.4937517 , -1.11488371, -0.70628642, -1.86134249,
-0.03509479, 0.20524998, 0.04379019, 0.39735111, -1.58616105])
7. 查看两列值相等的行号:Numpy.where()
- np.where()用法:
- np.where(condition, x, y): #
满足条件(condition),输出x,不满足输出y - np.where(condition):只有条件
(condition),没有x和y,则输出满足条件 (即非0) 元素的坐标
(等价于numpy.nonzero)。当条件成立时,where返回的是每个符合condition条件元素的坐标,返回的是以元组的形式。
df['cycle'] = [2.0, 3.0, 6.0, 3.0, 5.0, 2.0, 7.0, 5.0]
#方法一:值相等
df[df['score'] == df['cycle']].index
#方法二:np.where()
np.where(df.score == df.cycle)
(array([2, 4, 6]),)
8.查找第一列的局部最大值位置:Numpy.sign()
#思路:查找比它前一个和后一个数字都大数字
data = {
"grammer":['Python', 'C', 'Java', 'GO', 'css', 'SQL', 'PHP', 'Python'],
"score":[1.0, 2.0, 6.0, 4.0, 5.0, 6.0, 7.0, 10.0]}
tem = np.diff(np.sign(np.diff(df['score'])))
np.where(tem == -2)[0] + 1
array([2])
9. 计算两列欧式距离:Numpy.linalg.norm()
#方法一:公式法
import math as mt
mt.sqrt(sum((df['score']-df['cycle'])**2))
#方法二:numpy函数
np.linalg.norm(df['score'] - df['cycle'])
6.6332495807108
10. numpy其他一些统计基础函数
np.min([1,2,3]) # 最小值
np.mean([1,2,3]) # 均值
np.median([1,2,3]) # 中位数
np.var([1,2,3]) # 方差
np.max([1,2,3]) # 最大值
np.ptp([1,2,3]) # 极差
np.std([1,2,3]) # 标准差
np.cov([1,2,3]) # 协方差
np.log1p([1,2,3]) # log(x + 1)
np.log2([1,2,3]) # 以2为底的对数
np.expm1([1,2,3]) # e的x次幂-1
np.exp([1,2,3]) # e的次数幂
np.log([1,2,3]) # 取对数
np.sqrt([1,2,3]) # 开根号
np.exp2([1,2,3]) # 平方
array([2., 4., 8.])
作业
STEP1: 按照下列要求创建数据框
已知10位同学的学号以及语数英三科成绩如下:(都是数值型数据)
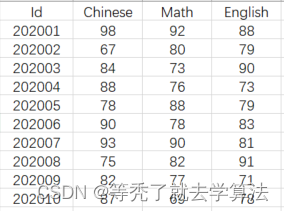
Id: [202001, 202002, 202003, 202004, 202005, 202006, 202007, 202008, 202009, 202010] Chinese: [98, 67, 84, 88, 78, 90, 93, 75, 82, 87] Math: [92, 80, 73, 76, 88, 78, 90, 82, 77, 69] English: [88, 79, 90, 73, 79, 83, 81, 91, 71, 78]
要求:计算出每位同学的总成绩(SumScore)、平均成绩(MeanScore),最高成绩(MaxScore)、最低成绩(MinScore)、最高成绩与最低成绩的极差(PtpScore)、成绩方差(VarScore);并将所有数据保存到score数据框中;将多列数据(包括学生的ID)合并到一列中,列名设置为answer,最终只保留索引id(从0到100)和answer两列,统一保留整数;
别人写的,挺好的
import pandas as pd
import numpy as np
data = {
'Id': ['202001','202002','202003','202004','202005','202006','202007','202008','202009','202010'],
'Chinese': ['98','67','84','88','78','90','93','75','82','87'],
'Math': ['92','80','73','76','88','78','90','82','77','69'],
'English': ['88','79','90','73','79','83','81','91','71','78']}
df = pd.DataFrame(data) # 字典转换为DF
df = df.astype('int') # object等格式转换为int
#运算
a = df[['Chinese', 'Math', 'English']].apply(np.sum, axis=1)
b = df[['Chinese', 'Math', 'English']].apply(np.mean, axis=1)
c = df[['Chinese', 'Math', 'English']].apply(np.max, axis=1)
d = df[['Chinese', 'Math', 'English']].apply(np.min, axis=1)
e = df[['Chinese', 'Math', 'English']].apply(np.ptp, axis=1)
f = df[['Chinese', 'Math', 'English']].var(axis='columns') # 查阅资料后得知,pandas df方差计算方法与numpy方差计算方法不一致
# 拼接共10列
df_concat = pd.concat([df['Id'], df['Chinese'], df['Math'], df['English'],a,b,c,d,e,f]) # 拼接列,series
df_concat = df_concat.astype('int')
print(df_concat)
df2 = pd.DataFrame() # 新建df2
df2['answer'] = df_concat # 新增列,数据来自拼接列
df2['id'] = range(len(df_concat)) # 新增列,并按照answer数量添加id
我写的,挺慢的
import numpy as np
import pandas as pd
data = {
"Id": [202001, 202002, 202003, 202004, 202005, 202006, 202007, 202008, 202009, 202010],
"Chinese": [98, 67, 84, 88, 78, 90, 93, 75, 82, 87],
"Math": [92, 80, 73, 76, 88, 78, 90, 82, 77, 69],
"English": [88, 79, 90, 73, 79, 83, 81, 91, 71, 78]}
mydata = pd.DataFrame(data)
mydata['SumScore'] = mydata.loc[:,mydata.columns[1:4]].sum(axis=1)
mydata['MeanScore'] = mydata.loc[:,mydata.columns[1:4]].sum(axis=1)/3
mydata['MaxScore'] = mydata.loc[:,mydata.columns[1:4]].max(axis=1)
mydata['MinScore'] = mydata.loc[:,mydata.columns[1:4]].min(axis=1)
mydata['PtpScore'] = np.ptp(mydata.loc[:,mydata.columns[1:4]],axis=1)
mydata['VarScore'] = mydata.loc[:,mydata.columns[1:4]].var(axis=1)
answer = pd.concat([mydata[c] for c in mydata.columns])
answer = answer.astype('int')
mydata1 = pd.DataFrame()
mydata1['answer'] = answer
mydata1['id'] = range(len(answer))
mydata1 = mydata1[['id','answer']]
print(mydata1)
mydata1.to_csv('answer_1.csv',index=False,encoding='utf-8-sig')
收获
- 在 Pandas 中,有三种方法可以用来索引和选择数据:[]、.iloc 和 .loc。
[] 是最基本的索引和选择数据的方法,它通常用于选择单个列或多个列。使用 [] 选择多个列时,需要将列名以列表的形式传递。
import pandas as pd
df = pd.DataFrame({
'A': [1, 2, 3],
'B': [4, 5, 6],
'C': [7, 8, 9]
})
# 选择单个列
df['A']
# 输出:0 1
# 1 2
# 2 3
# Name: A, dtype: int64
# 选择多个列
df[['A', 'B']]
# 输出: A B
# 0 1 4
# 1 2 5
# 2 3 6
- .iloc 是按照整数位置(从 0 开始)进行索引和选择数据的方法。使用 .iloc 可以选择单个元素、行、列或者一个区域。选择行和列时可以用整数位置或者切片。
import pandas as pd
df = pd.DataFrame({
'A': [1, 2, 3],
'B': [4, 5, 6],
'C': [7, 8, 9]
})
# 选择单个元素
df.iloc[0, 0]
# 输出:1
# 选择单个行
df.iloc[0]
# 输出:A 1
# B 4
# C 7
# Name: 0, dtype: int64
# 选择单个列
df.iloc[:, 0]
# 输出:0 1
# 1 2
# 2 3
# Name: A, dtype: int64
# 选择一个区域
df.iloc[0:2, 0:2]
# 输出: A B
# 0 1 4
# 1 2 5
.loc 是按照标签进行索引和选择数据的方法。使用 .loc 可以选择单个元素、行、列或者一个区域。选择行和列时必须使用标签。
import pandas as pd
df = pd.DataFrame({
'A': [1, 2, 3],
'B': [4, 5, 6],
'C': [7, 8, 9]
})
# 选择单个元素
df.loc[0, 'A']
# 输出:1
# 选择单个行
df.loc[0]
# 输出:A 1
# B 4
# C 7
# Name: 0, dtype: int64
# 选择单个列
df.loc[:, 'A']
# 输出:0 1
# 1 2
# 2 3
# Name: A, dtype: int64
# 选择一个区域
df.loc[0:1, ['A', 'B']]
# 输出: A B
# 0