全景分割是一个计算机视觉问题,是许多现实世界AI应用的核心任务。由于其复杂性,以前的工作通常将全景分割分为语义分割(为图像中的每个像素分配语义标签,例如“人”和“天空”)和实例分割(仅识别和分割图像中的可数对象,例如“行人”和“汽车”),并将其进一步分为几个子任务。每个子任务单独处理,并应用额外的模块来合并每个子任务阶段的结果。这个过程不仅复杂,而且在处理子任务和组合不同子任务阶段的结果时,还引入了许多手工设计的先验。
——1——
掩码Transformer
最近,受Transformer和DETR的启发, MaX-DeepLab提出了一种使用掩码Transformer(用于生成分割掩码的 Transformer 架构的扩展)进行全景分割的端到端解决方案。该解决方案采用像素路径(由卷积神经网络或视觉Transformer组成)提取像素特征,内存路径(由转换器解码器模块组成)提取内存特征,以及双路径Transformer用于像素特征和内存之间的交互特征。
然而,利用交叉注意力的双路径Transformer,最初是为语言任务设计的,其中输入序列由几十个或几百个单词组成。尽管如此,当涉及到视觉任务,特别是分割问题时,输入序列由数万像素组成,这表明输入规模大得多。
在CVPR 2022上发表的 “ CMT-DeepLab: Clustering Mask Transformers for Panoptic Segmentation ”和将在ECCV 2022上发表的“ kMaX-DeepLab: k-means Mask Transformer ”中,Google建议从聚类视角(即将具有相同语义标签的像素分组在一起),更好地适应视觉任务。
CMT-DeepLab 建立在先前最先进的方法 MaX-DeepLab 之上,并采用像素聚类方法来执行交叉注意力机制,从而产生更密集和合理的注意力机制图。kMaX-DeepLab 进一步重新设计了交叉注意力机制,使其更像k-means 聚类算法,对激活函数进行简单的更改。Google证明了 CMT-DeepLab 实现了显著的性能改进,而 kMaX-DeepLab 不仅简化了修改,而且在没有增加测试时间的情况下进一步大幅提升了最先进的技术。Google也很高兴地宣布在DeepLab2 库中发布了Google性能最好的分割模型 kMaX-DeepLab 的开源版本。
——2——
kMaX-DeepLab Transformer
Google建议从聚类的角度重新解释它,而不是直接将交叉注意力应用于视觉任务而不进行修改。具体来说,Google注意到掩码 Transformer 对象查询可以被认为是聚类中心(旨在对具有相同语义标签的像素进行分组),交叉注意力的过程类似于 k-means 聚类算法,采用迭代过程
(1)将像素分配给聚类中心,其中可以将多个像素分配给单个聚类中心,并且某些聚类中心可能没有分配的像素
(2)通过平均分配给同一聚类中心的像素来更新聚类中心,如果没有为它们分配像素,则不会更新聚类中心)
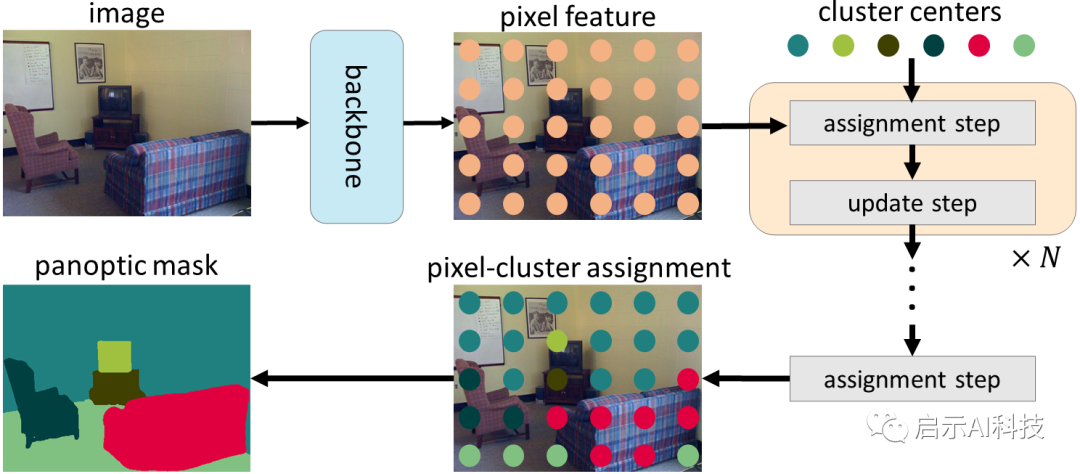
在 CMT-DeepLab 和 kMaX-DeepLab 中,Google从聚类的角度重新制定了交叉注意力机制,包括迭代聚类分配和聚类更新步骤。
鉴于 k-means 聚类算法的流行,在 CMT-DeepLab 中,Google重新设计了交叉注意力,以便空间方面的softmax操作(即沿图像空间分辨率应用的 softmax 操作)在 kMaX-DeepLab 中,Google进一步将空间方式的 softmax 简化为集群方式的softmax(即,沿集群中心应用 softmax 操作)
从聚类的角度重新构建掩码转换器的交叉注意力,显著提高了分割性能,并简化了复杂掩码Transformer管道,使其更具可解释性。首先,使用编码器-解码器结构从输入图像中提取像素特征。然后,使用一组聚类中心对像素进行分组,这些像素会根据聚类分配进一步更新。最后,迭代执行聚类分配和更新步骤,最后一个分配直接用作分割预测。
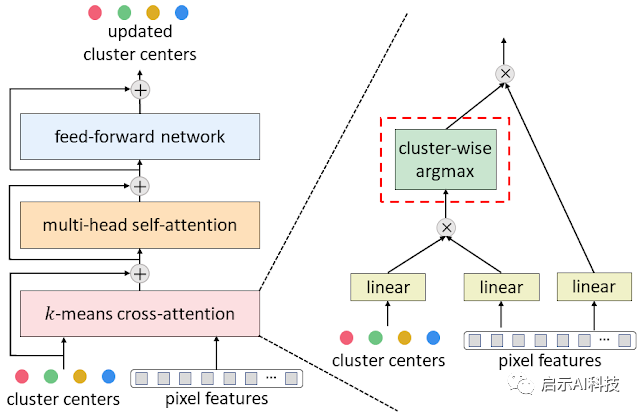
为了将典型的掩码 Transformer 解码器(由交叉注意力机制、多头自注意力机制和前馈网络组成)转换为Google提出的 k-means 交叉注意力机制,只需将空间方式的 softmax 替换为集群方式。
kMaX-DeepLab 的架构由三个组件组成:像素编码器、增强像素解码器和 kMaX 解码器。像素编码器是网络主干,用于提取图像特征。增强的像素解码器包括用于增强像素特征的Transformer编码器,以及用于生成更高分辨率特征的上采样层。一系列 kMaX 解码器将聚类中心转换为 掩码嵌入向量,其与像素特征相乘以生成预测掩码,以及每个掩码的类别预测。

kMaX-DeepLab 的元架构
结果在两个最具挑战性的全景分割数据集COCO和Cityscapes上得到了显著的效果

从聚类的角度设计,kMaX-DeepLab 不仅具有更高的性能,而且还可以更合理地可视化注意力图以了解其工作机制。在下面的示例中,kMaX-DeepLab 迭代地执行聚类分配和更新,从而逐渐提高掩码质量。
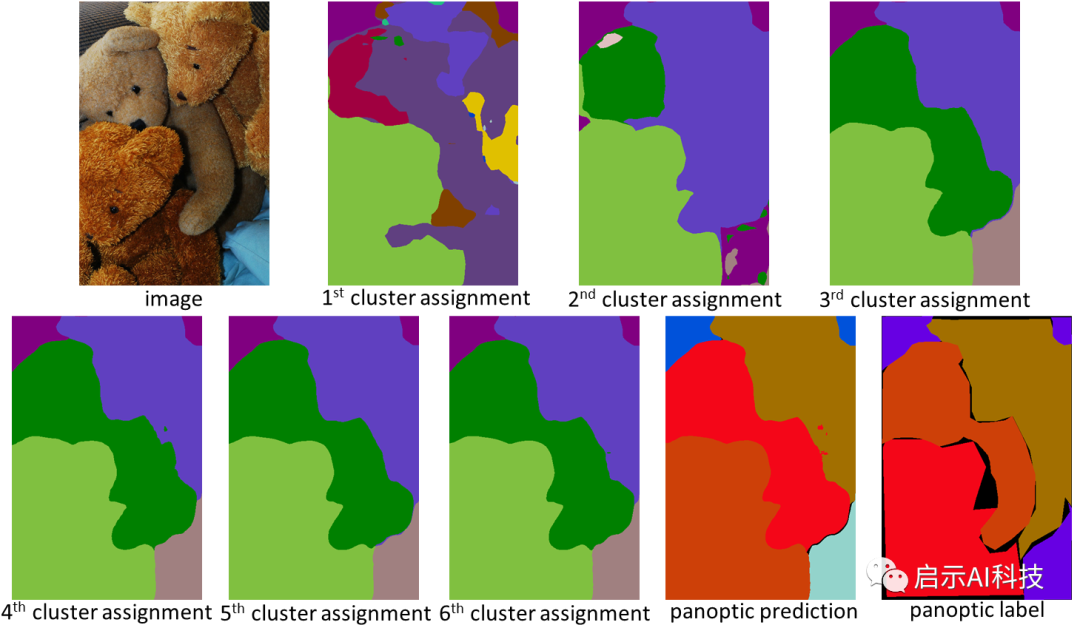
kMaX-DeepLab 注意力图可以直接可视化为全景分割,这为模型工作机制提供了更好的合理性,kMaX-DeepLab已经展示了一种更好地设计用于视觉任务的掩模transformer的方法。通过简单的修改,CMT-DeepLab 和 kMaX-DeepLab 重新构建了交叉注意力机制,使其更像一种聚类算法。因此,所提出的模型在具有挑战性的 COCO 和 Cityscapes 数据集上实现了最先进的性能。DeepLab2 库中 kMaX-DeepLab 开源版本可以帮助开发者更好的提高实例分割性能的研究。
Transormer模型重点介绍了encoder与decoder,有6个编码器与6个解码器组成,其Transormer模型主要应用在NLP领域,但是随着Transormer模型的大火,其模型成功应用在了CV计算机视觉领域,其Transormer模型,Vision Transormer模型,SWIN Transormer模型都会在如下专栏进行详细动画分享
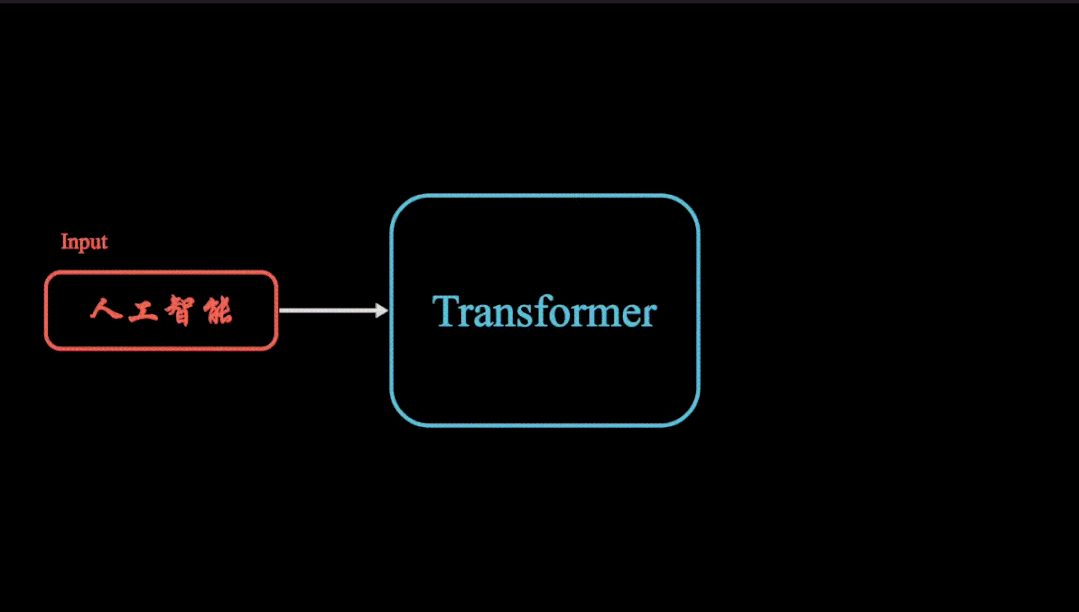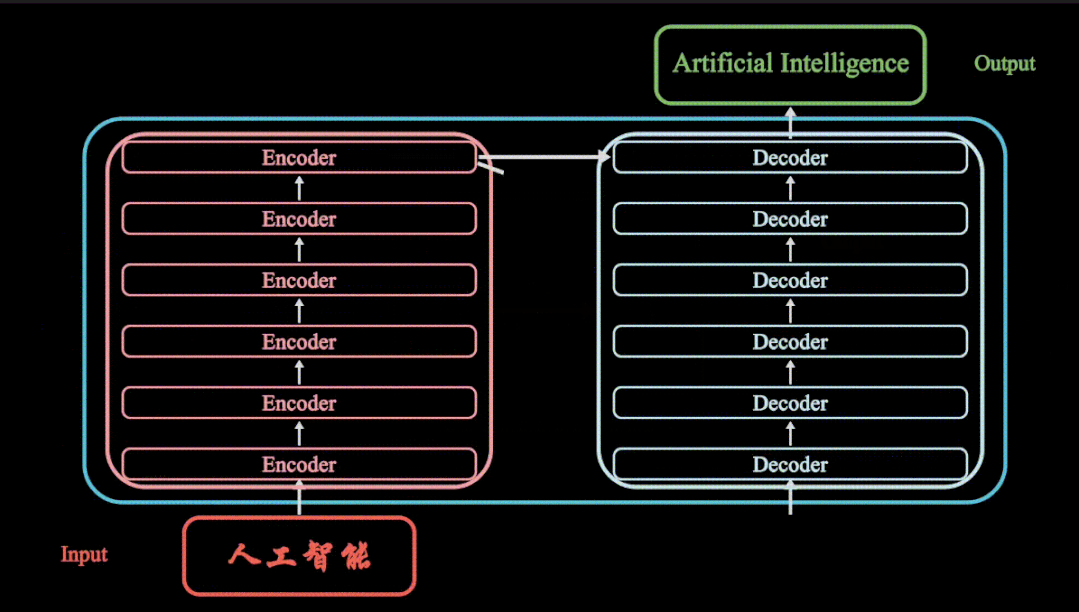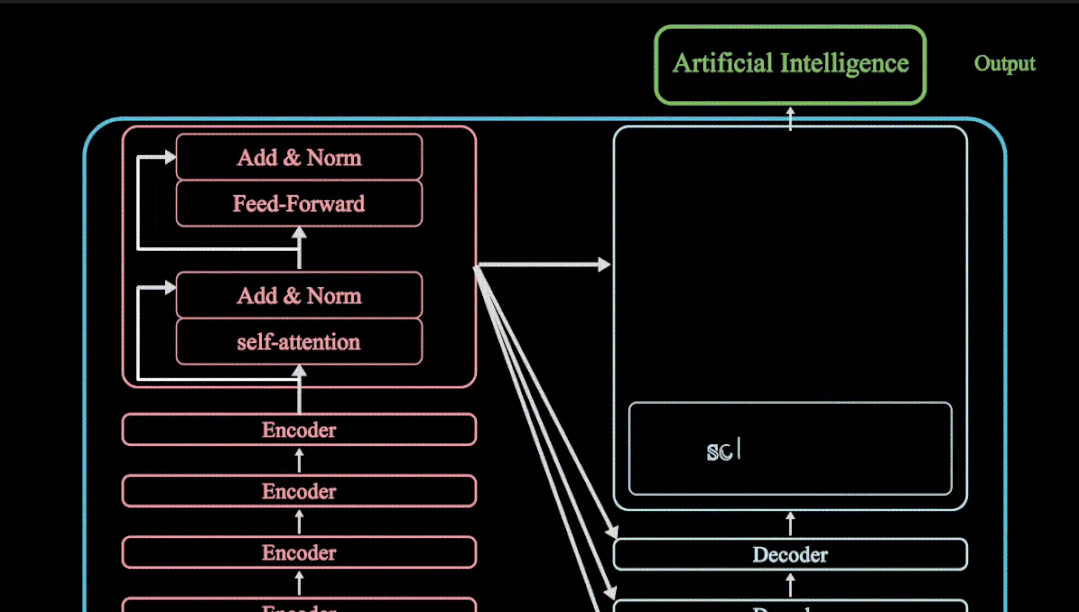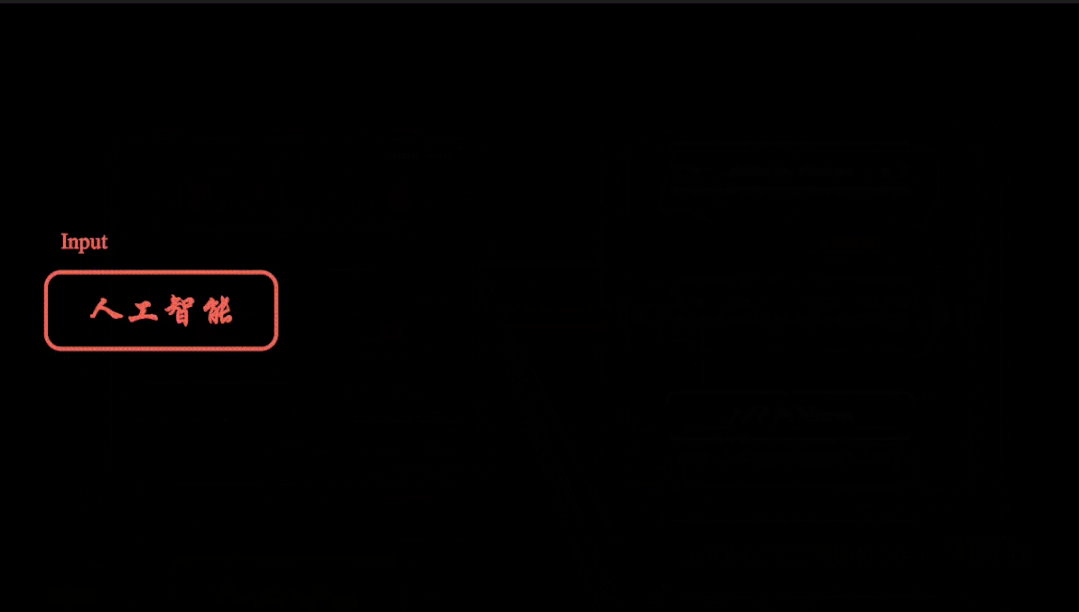
-
更多transformer模型教程 参考 同名头条号 人工智能研究所
VX搜索小程序:AI人工智能工具,体验不一样的AI工具
