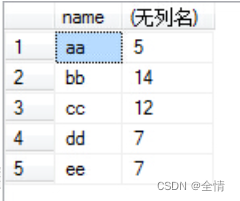
去重是指把多条数据变为1条数据
1.明确一点,聚集函数不具备去重作用
如果是单行的聚集函数,如lower,则返回的结果仍然是每一条记录
如果是多行的聚集函数,多条记录得到一个结果,这时候如果别的字段是没有意义的,如:
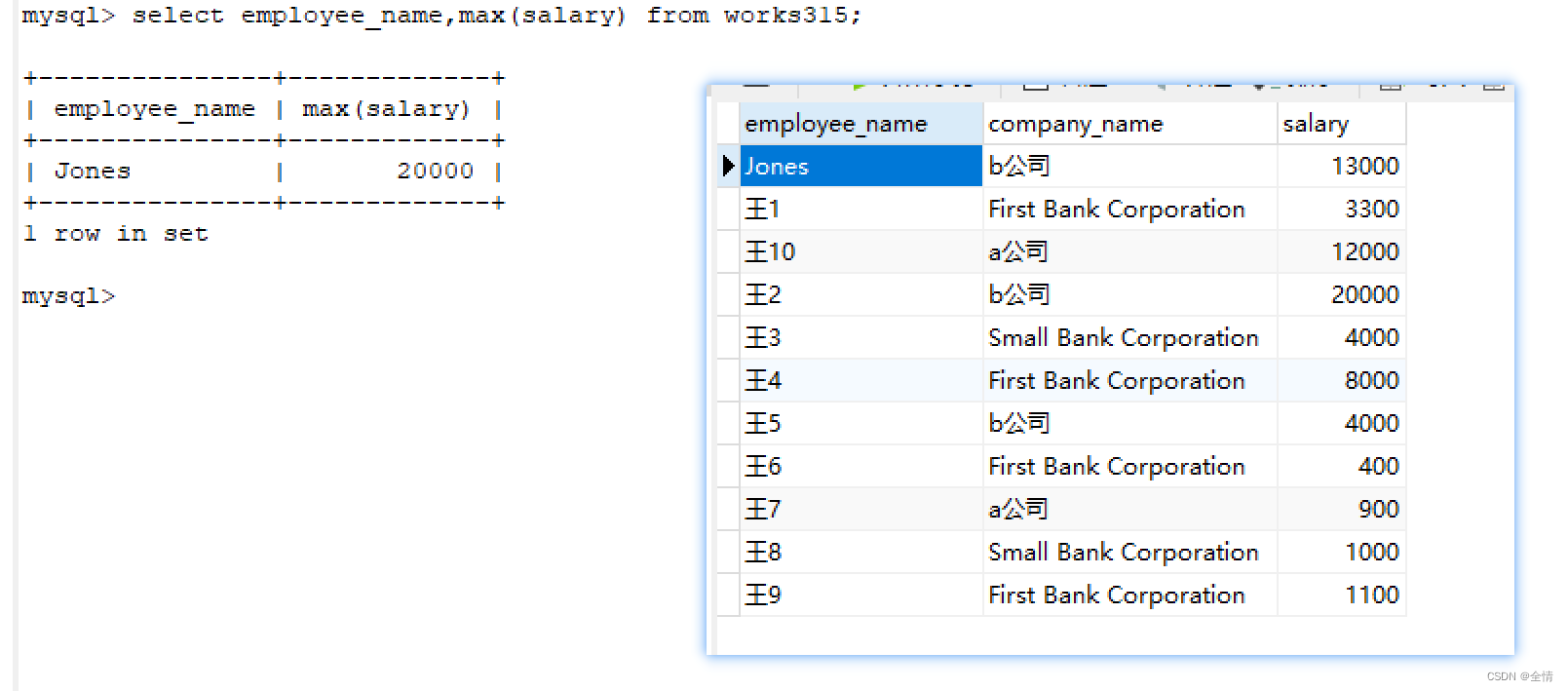
显然,jones和 max 工资没有任何关系,我们只是强行把它输出出来了
由于max(salary)只有一条数据,所以name也就只输出了所有name里的第一条数据咯。
select对应代数运算中的投影操作,投影操作是有去重能力的
不过select并没有去重能力,去重需要借助下面两个
2.distinct去重
3.group by去重
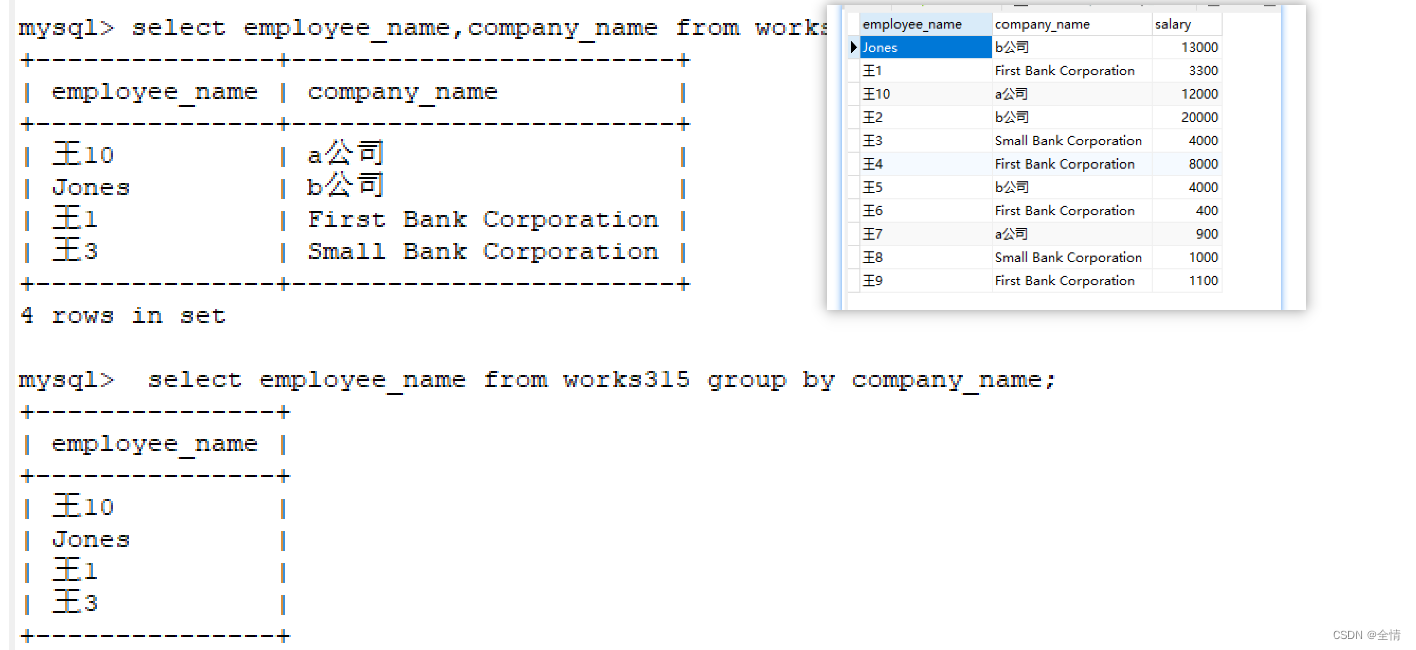
可以看到,group by 列
输出的都是每个公司在表中第一次出现的人名。

主要是SQL的书写顺序和执行顺序
执行顺序
(8) SELECT (9)DISTINCT<Select_list>
(1) FROM <left_table> (3) <join_type>JOIN<right_table>
(2) ON<join_condition>
(4) WHERE<where_condition>
(5) GROUP BY<group_by_list>
(6) WITH {CUBE|ROLLUP}
(7) HAVING<having_condtion>
(10) ORDER BY<order_by_list>
(11) LIMIT<limit_number>
我们可以看出,SELECT子句是必选的,其它子句如WHERE子句、GROUP BY子句等是可选的。
一个SELECT语句中,子句的顺序是固定的。必须严格按照上述的顺序书写。
所有的查询语句都是从FROM开始执行的,在执行过程中,每个步骤都会为下一个步骤生成一个虚拟表,这个虚拟表将作为下一个执行步骤的输入。
1.先对FROM子句中的两个表执行一个笛卡尔乘,此时生成虚拟表 virtual table (选择相对小的表做基础表)
2.然后是应用ON条件筛选器,将ON中的逻辑表达式将应用到 virtual table 1中的各个行,筛选出满足ON中的逻辑表达式的行,生成虚拟表 virtual table 2
3.根据连接方式进行进一步的操作。如果是OUTER JOIN,那么这一步就将添加外部行
LEFT OUTER JOIN就把左表在第二步中筛选掉的行添加进来
RIGHT OUTER JOIN就将右表在第二步中筛选掉的行添加进来 这样生成虚拟表 virtual table 3
如果 FROM子句中的表数目大于2,那么就将virtual table 3和第三个表连接从而计算笛卡尔积,生成虚拟表,该过程就是一个重复1-3的步骤,最终得到一个新的虚拟表virtual table 3
1.应用WHERE筛选器,对上一步生产的virtual table 3用WHERE筛选器筛选,生成虚拟表virtual table 4
在这有个比较重要的细节需要提一下,如果我们有一个condition需要去筛选,应该在在ON条件筛选器还是用WHERE筛选器指定condition逻辑表达式呢?
ON和WHERE的最大区别在于,如果在ON应用逻辑表达式那么在第三步OUTER JOIN中还可以把移除的行再次添加回来,而WHERE的移除的不可挽回的
2.GROUP BY子句将具有相同属性的row组合成为一组,得到虚拟表virtual table 5
如果应用了GROUP BY,那么后面的所有步骤都只能得到的virtual table 5的列或者是聚合函数,并且分组的时候是将列中唯一的值分成一组,同时只为每一组返回一行记录,这一点请牢记。
3.应用CUBE或者ROLLUP选项,为virtual table 5生成超组,生成virtual table 6. 这个暂时还没了解,先放到这里吧。
4.应用HAVING筛选器,生成virtual table 7
HAVING筛选器是唯一一个用来筛选组的筛选器
5.处理SELECT子句。将virtual table 7中的并且在Select_list中的列筛选出来,生成virtual table 8
6.应用DISTINCT子句,virtual table 8中移除相同的行,生成virtual table 9
事实上如果应用了GROUP BY子句,那么DISTINCT是多余的,原因同样在于,分组的时候是将列中唯一的值分成一组,同时只为每一组返回一行记录,那么所以的记录都将是不相同的。
7.应用ORDER BY子句。按照order_by_condition排序virtual table 10,此时返回的一个游标,而不是虚拟表。SQL是基于集合的,集合不会预先对行进行排序,它只是成员的逻辑集合,成员的顺序是无关紧要的。对表进行排序的查询可以返回一个对象,这个对象包含特定的物理顺序的逻辑组织。这个对象就叫游标。正因为返回值是游标,那么使用ORDER BY子句查询不能应用于表达式。
总之粗略理解呢
如果有聚合函数,那么就是先分组不去重,等聚合函数计算完后
再说,同理having后面有聚合函数也一样
(having作用,对分组进行过滤,不满足条件的分组直接全组丢弃。having里也可以使用聚合函数)

这块儿理解的不好,以后有机会看个什么书慢慢补吧
战佬也讲的不够细,时间不够
补充,理解group by
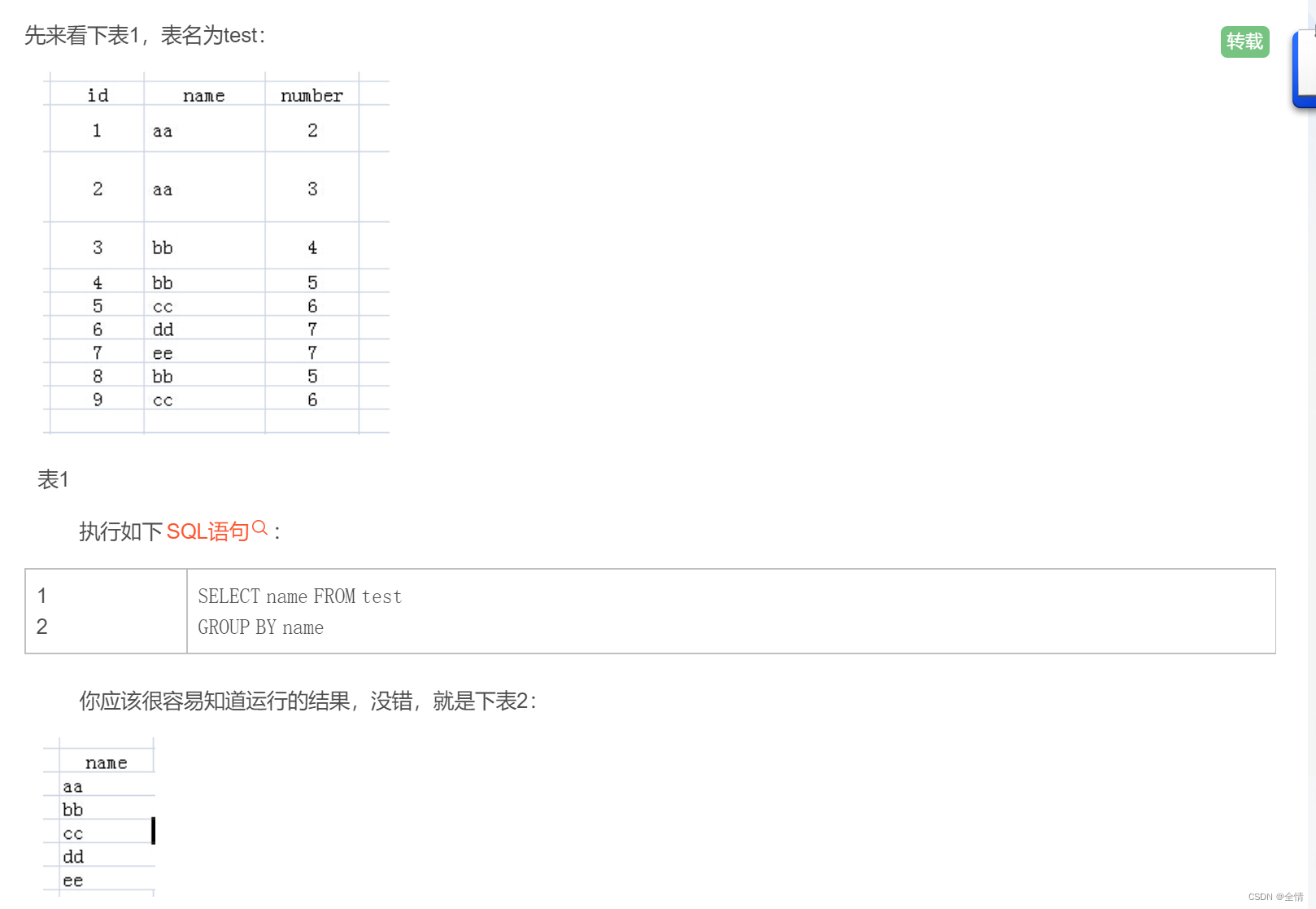
表2
可是为了能够更好的理解“group by”多个列“和”聚合函数“的应用,我建议在思考的过程中,由表1到表2的过程中,增加一个虚构的中间表:虚拟表3。下面说说如何来思考上面SQL语句执行情况:
1.FROM test:该句执行后,应该结果和表1一样,就是原来的表。
2.FROM test Group BY name:该句执行后,我们想象生成了虚拟表3,如下所图所示,生成过程是这样的:group by name,那么找name那一列,具有相同name值的行,合并成一行,如对于name值为aa的,那么<1 aa 2>与<2 aa 3>两行合并成1行,所有的id值和number值写到一个单元格里面。

3.接下来就要针对虚拟表3执行Select语句了:
(1)如果执行select *的话,那么返回的结果应该是虚拟表3,可是id和number中有的单元格里面的内容是多个值的,而关系数据库就是基于关系的,单元格中是不允许有多个值的,所以输出的时候会输出多值格子中的第一个值,比如id的1 number的2。
(2)我们再看name列,每个单元格只有一个数据,所以我们select name的话,就没有问题了。为什么name列每个单元格只有一个值呢,因为我们就是用name列来group by的。
(3)那么对于id和number里面的单元格有多个数据的情况有什么用呢?答案就是用聚合函数,聚合函数就用来输入多个数据,输出一个数据的。如cout(id),sum(number),而每个聚合函数的输入就是每一个多数据的单元格。
(4)例如我们执行select name,sum(number) from test group by name,那么sum就对虚拟表3的number列的每个单元格进行sum操作,例如对name为aa的那一行的number列执行sum操作,即2+3,返回5,最后执行结果如下: