今天要写一个下拉框的使用想采用SQL的distinct方法去过滤重复的数据,查询两列数据的时候,发现当一列数据重复,另一列数据不重复时,并不会舍弃,于是采用group by的方式。
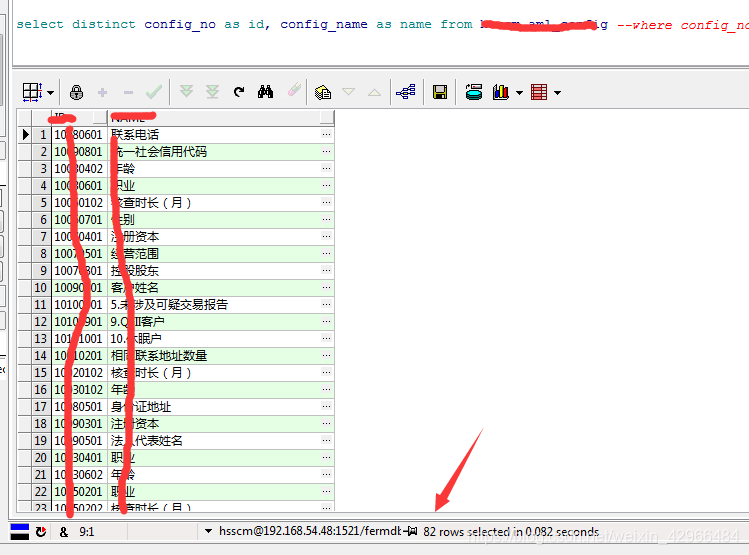
1,起初数据量为82条
2.当单独使用distinct之后,其实数据只有73条,那就是name列有不重复的数据,但是id是一样的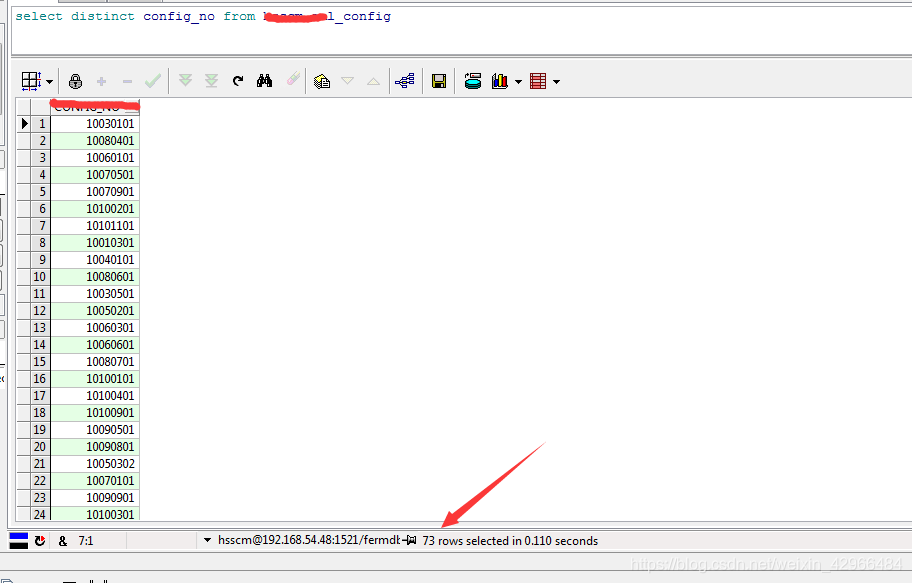
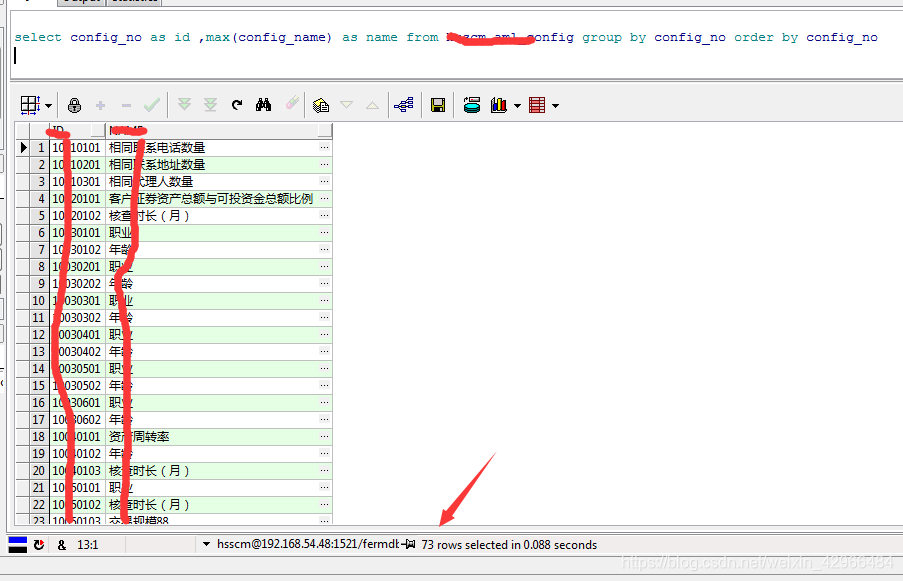
3.所以采用group by的方式:利用id分组,然后取name的最大值,去除重复数据就可以啦
今天要写一个下拉框的使用想采用SQL的distinct方法去过滤重复的数据,查询两列数据的时候,发现当一列数据重复,另一列数据不重复时,并不会舍弃,于是采用group by的方式。
1,起初数据量为82条
2.当单独使用distinct之后,其实数据只有73条,那就是name列有不重复的数据,但是id是一样的
3.所以采用group by的方式:利用id分组,然后取name的最大值,去除重复数据就可以啦
