
论文地址->Transformer官方论文地址
官方代码地址->暂时还没有找到有官方的Transformer用于时间序列预测的代码地址
个人修改地址-> Transformer模型下载地址CSDN免费
一、本文介绍
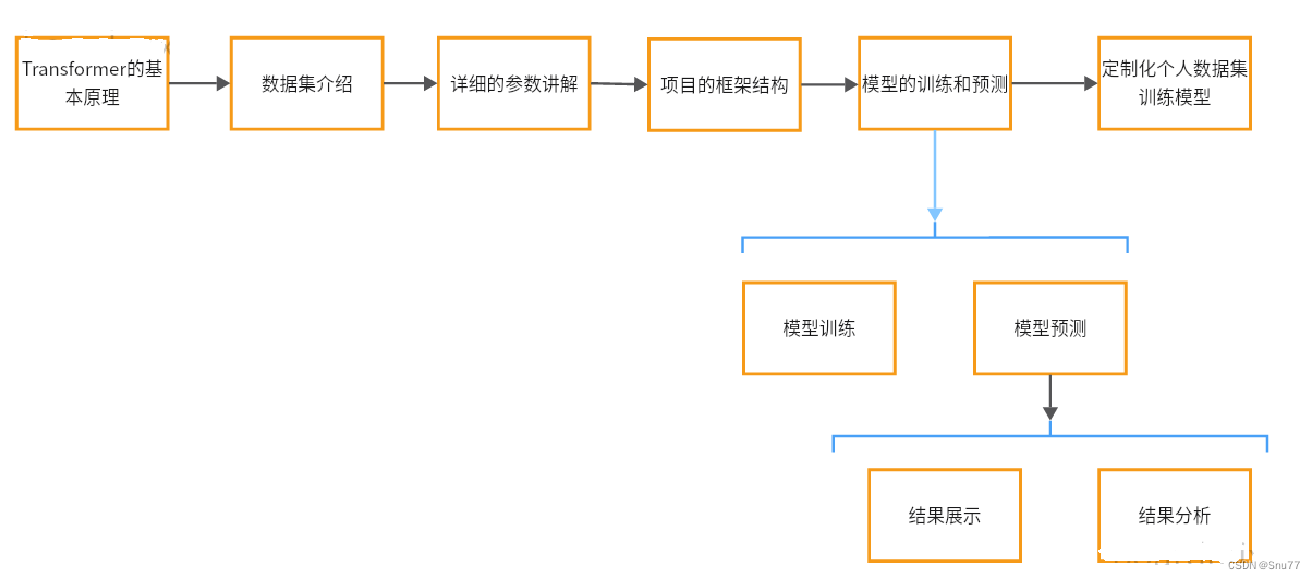
这篇文章给大家带来是Transformer在时间序列预测上的应用,这种模型最初是为了处理自然语言处理(NLP)任务而设计的,但由于其独特的架构和能力,它也被用于时间序列分析。Transformer应用于时间序列分析中的基本思想是:Transformer 在时间序列分析中的应用核心在于其自注意力机制,这使其能够有效捕捉时间序列数据中的长期依赖关系。通过并行处理能力和位置编码,Transformer 不仅提高了处理效率,而且确保了时间顺序的准确性。其灵活的模型结构允许调整以适应不同复杂度的数据,而编码器-解码器架构则特别适用于预测未来的时间点。本文的讲解内容包括:Transfomrer的基本原理、数据集介绍、模型的详细参数讲解、项目的构造、模型的训练和预测、如何用个人数据集进行训练,下面的为本文的讲解顺序图->
预测类型-> 单元预测、多元预测、长期预测、滚动预测、定制化数据集预测
二、Transformer的基本框架原理
Transformer的最开始提出是为了处理自然语言处理(NLP)任务而设计的,但由于其独特的架构和能力,所以被用于时间序列分析,但其实本身的Transformer作用于时间序列上的效果其实不是很好,它的应用主要是其变体类似于informer、FNet、MTS等模型效果比较好,在Transformer的基础上增添一些改进从而达到更高的效果,大家如果对其变体有兴趣可以看我的其它博客都有详细的实战讲解。
1.Transformer的基本原理
Transformer 在时间序列分析中的应用核心在于其自注意力机制,这使其能够有效捕捉时间序列数据中的长期依赖关系。通过并行处理能力和位置编码,Transformer 不仅提高了处理效率,而且确保了时间顺序的准确性。其灵活的模型结构允许调整以适应不同复杂度的数据,而编码器-解码器架构则特别适用于预测未来的时间点,以下是这一思想的几个关键方面->
捕捉时间依赖性:
时间序列数据的关键特征之一是其内在的时间依赖性。Transformer 通过自注意力机制能够捕捉这种依赖性,无论它们在序列中的距离有多远。并行处理序列数据:
与传统的循环神经网络(RNN)或长短时记忆网络(LSTM)不同,Transformer 可以并行处理序列数据,从而提高处理效率。位置编码:
由于 Transformer 缺乏处理序列顺序的内在机制,因此它引入位置编码来保持时间序列数据中的时间顺序信息。处理长期依赖关系:
在时间序列分析中,了解长期依赖关系很重要。Transformer 的自注意力机制能够处理长距离的依赖关系,这在传统方法中往往是个挑战。灵活的模型结构:
Transformer 模型可以根据需要调整其复杂性,例如通过增加层数或调整头的数量来处理不同规模和复杂度的时间序列数据。编码器-解码器架构:
一些 Transformer 变体采用编码器-解码器架构,这对于预测未来时间点的时间序列数据特别有效。
2.Transformer的基本结构
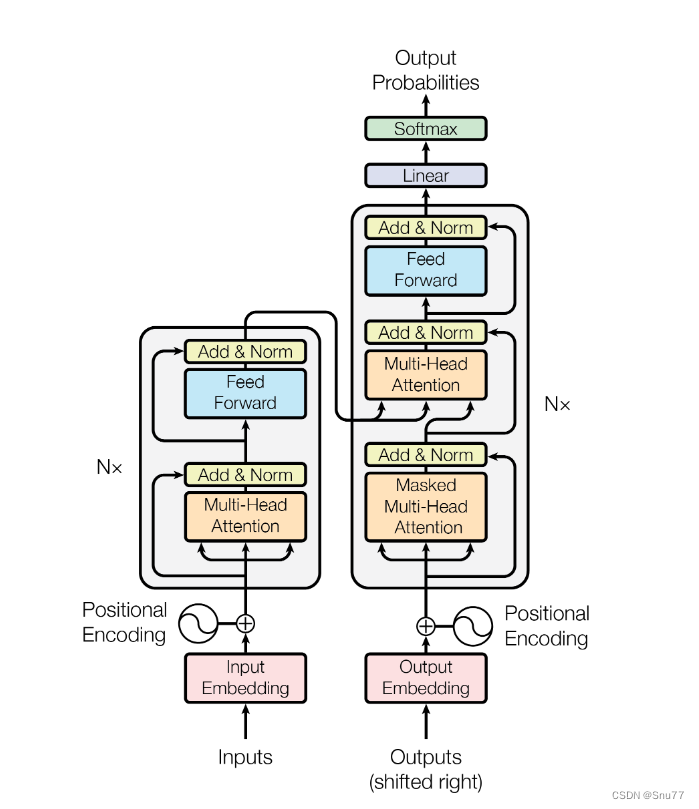
这个图片展示了一个标准的 Transformer 模型的架构,这个结构用于序列到序列的任务,如机器翻译。下面是各个部分的分析:
输入嵌入(Input Embedding):
- 输入序列的每个元素首先被转换成一个高维空间的嵌入向量。
位置编码(Positional Encoding):
- 由于 Transformer 没有递归结构来处理序列的顺序,位置编码向量被加到输入嵌入中以提供序列中每个元素的位置信息。
编码器(左侧):
- 编码器由 N个相同的层堆叠而成。
- 每层包含两个主要部分:多头注意力(Multi-Head Attention)和前馈(Feed Forward)网络。
- 每个部分后面都跟着一个加法 & 归一化(Add & Norm)步骤,这实际上是一个残差连接和层归一化。
多头注意力:
- 这个部分让模型同时关注输入序列的不同部分(称为“头”),每个头捕获序列中不同的信息。
前馈网络:
- 这是一个简单的全连接网络,对每个位置应用相同的操作,但是独立于其他位置。
解码器(右侧):
- 解码器也由 N个相同的层组成,每层有三个主要部分:遮蔽多头注意力(Masked Multi-Head Attention)、多头注意力和前馈网络。
- 遮蔽机制确保在预测一个序列的当前位置时,模型不会看到未来的位置。
输出嵌入(Output Embedding)和位置编码:
- 解码器的输出嵌入和位置编码与编码器端类似,位置编码提供了输出序列中元素的位置信息。
线性层和 Softmax:
- 解码器的最顶层输出通过一个线性层,然后是一个 Softmax 层,它预测下一个序列元素的概率分布,并且根据Sofrtmax进行输出最大值(需要注意的是我们在时间序列中将softmax替换为Linear线性层处理)。
总结:整个模型通过训练来同时优化所有这些部分,学习将输入序列转换为输出序列,从而具有预测的功能。
下面是定义的Transformer的网络结构代码(如果想研究可以配合网络结构图看看是有差别的)->
class Model(nn.Module):
"""
Vanilla Transformer with O(L^2) complexity
"""
def __init__(self, configs):
super(Model, self).__init__()
self.label_len = configs.label_len
self.pred_len = configs.pred_len
self.output_attention = configs.output_attention
# Embedding
if configs.embed_type == 0:
self.enc_embedding = DataEmbedding(configs.enc_in, configs.d_model, configs.embed, configs.freq, configs.dropout)
self.dec_embedding = DataEmbedding(configs.dec_in, configs.d_model, configs.embed, configs.freq, configs.dropout)
elif configs.embed_type == 1:
self.enc_embedding = DataEmbedding_wo_temp(configs.enc_in, configs.d_model, configs.dropout)
self.dec_embedding = DataEmbedding_wo_temp(configs.dec_in, configs.d_model, configs.dropout)
# Encoder
self.encoder = Encoder(
configs.e_layers, configs.n_heads, configs.d_model, configs.d_ff,
configs.dropout, configs.activation, configs.output_attention,
norm_layer=torch.nn.LayerNorm(configs.d_model)
)
# Decoder
self.decoder = Decoder(
configs.d_layers, configs.n_heads, configs.d_model, configs.d_ff,
configs.dropout, configs.activation, configs.output_attention,
norm_layer=torch.nn.LayerNorm(configs.d_model),
)
self.projection = nn.Linear(configs.d_model, configs.c_out)
self.rev = RevIN(configs.c_out) if configs.rev else None
def forward(self, x_enc, x_mark_enc, x_dec, x_mark_dec, enc_self_mask=None, dec_self_mask=None, dec_enc_mask=None):
x_enc = self.rev(x_enc, 'norm') if self.rev else x_enc
enc_out = self.enc_embedding(x_enc, x_mark_enc)
enc_out, attns = self.encoder(enc_out, attn_mask=enc_self_mask)
dec_out = self.dec_embedding(x_dec, x_mark_dec)
dec_out = self.decoder(dec_out, enc_out, x_mask=dec_self_mask, cross_mask=dec_enc_mask)
dec_out = self.projection(dec_out)
dec_out = self.rev(dec_out, 'denorm') if self.rev else dec_out
if self.output_attention:
return dec_out[:, -self.pred_len:, :], attns
else:
return dec_out[:, -self.pred_len:, :] # [B, L, D]三、数据集介绍
所用到的数据集为某公司的业务水平评估和其它参数具体的内容我就介绍了估计大家都是想用自己的数据进行训练模型,这里展示部分图片给大家提供参考->
四、参数讲解
下面是模型声明的所有参数->
parser.add_argument('--train', type=bool, default=True, help='Whether to conduct training')
parser.add_argument('--rollingforecast', type=bool, default=True, help='rolling forecast True or False')
parser.add_argument('--rolling_data_path', type=str, default='ETTh1-Test.csv', help='rolling data file')
parser.add_argument('--show_results', type=bool, default=True, help='Whether show forecast and real results graph')
parser.add_argument('--model', type=str, default='FNet',help='Model name')
# data loader
parser.add_argument('--root_path', type=str, default='./data/', help='root path of the data file')
parser.add_argument('--data_path', type=str, default='ETTh1.csv', help='data file')
parser.add_argument('--features', type=str, default='MS',
help='forecasting task, options:[M, S, MS]; M:multivariate predict multivariate, S:univariate predict univariate, MS:multivariate predict univariate')
parser.add_argument('--target', type=str, default='OT', help='target feature in S or MS task')
parser.add_argument('--freq', type=str, default='h',
help='freq for time features encoding, options:[s:secondly, t:minutely, h:hourly, d:daily, b:business days, w:weekly, m:monthly], you can also use more detailed freq like 15min or 3h')
parser.add_argument('--checkpoints', type=str, default='./models/', help='location of model models')
# forecasting task
parser.add_argument('--seq_len', type=int, default=126, help='input sequence length')
parser.add_argument('--label_len', type=int, default=64, help='start token length')
parser.add_argument('--pred_len', type=int, default=4, help='prediction sequence length')
# model
parser.add_argument('--norm', action='store_false', default=True, help='whether to apply LayerNorm')
parser.add_argument('--rev', action='store_true', default=True, help='whether to apply RevIN')
parser.add_argument('--d_model', type=int, default=512, help='dimension of model')
parser.add_argument('--n_heads', type=int, default=1, help='num of heads')
parser.add_argument('--e_layers', type=int, default=2, help='num of encoder layers')
parser.add_argument('--d_layers', type=int, default=1, help='num of decoder layers')
parser.add_argument('--d_ff', type=int, default=2048, help='dimension of fcn')
parser.add_argument('--enc_in', type=int, default=7, help='encoder input size')
parser.add_argument('--dec_in', type=int, default=7, help='decoder input size')
parser.add_argument('--c_out', type=int, default=7, help='output size')
parser.add_argument('--dropout', type=float, default=0.05, help='dropout')
parser.add_argument('--embed', type=str, default='timeF',
help='time features encoding, options:[timeF, fixed, learned]')
parser.add_argument('--output_attention', action='store_true', help='whether to output attention in ecoder')
parser.add_argument('--activation', type=str, default='gelu', help='activation')
parser.add_argument('--embed_type', type=int, default=1,
help='0: default 1: value embedding + temporal embedding + positional embedding 2: value embedding + positional embedding')
# optimization
parser.add_argument('--num_workers', type=int, default=0, help='data loader num workers')
parser.add_argument('--train_epochs', type=int, default=10, help='train epochs')
parser.add_argument('--batch_size', type=int, default=16, help='batch size of train input data')
parser.add_argument('--learning_rate', type=float, default=0.001, help='optimizer learning rate')
parser.add_argument('--loss', type=str, default='mse', help='loss function')
parser.add_argument('--lradj', type=str, default='type1', help='adjust learning rate')
# GPU
parser.add_argument('--use_gpu', type=bool, default=True, help='use gpu')
parser.add_argument('--device', type=int, default=0, help='gpu')1.详细的参数讲解
五、项目结构
项目的目录结构如下图->
六、模型的训练和预测
6.1训练模型
配置好我们的所有参数之后,我们可以运行main.py文件之后就可以开始训练, 可以看到控制台开始输出训练批次和损失->

当我们训练完成之后,训练好的模型会保存到该目录下->

6.2滚动长期预测
当我们保存之后可以开启滚动预测了,预测是每次预测未来四个点的数据(这个是根据你自己设定的就是参数中的pred_len)控制台输出如下->

6.2.1滚动长期预测结果展示
我将你目标列其你的OT列进行了保存为csv的格式文件方便大家进行二次修改或者分析,结果保存在如下的文件中。
然后可视化结果保存在下图的results.png中,
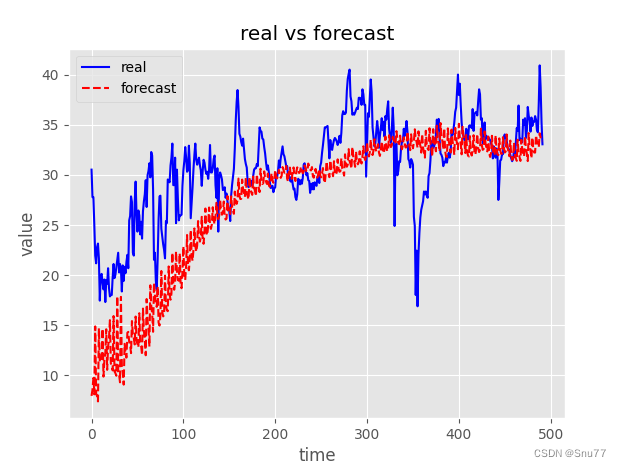
我们的预测结果图片如下->
6.2.2结果分析
可以看到结果是十分的一般,我甚至怀疑Transformer模型是对于预测是否是真的有效,最近的DLinear提出了一个十分简单的模型就是为了推翻Transformer模型的预测是否有效,参数量比Transformer少了上百倍但是结果却比Transformer好的很多很多,所以我也对Transformer模型表示怀疑,当然Transformer的变体还是有预测效果的类似于informer毕竟是当年的bestpaper ,但是我试验过很多模型我觉得Transformer的模型整体效果预测都一般(以上仅代表我个人观点)
七、定制化训练个人数据集
这个模型我在写的过程中为了节省大家训练自己数据集,我基本上把大部分的参数都写好了,需要大家注意的就是如果要进行滚动预测下面的参数要设置为True。
parser.add_argument('--rollingforecast', type=bool, default=True, help='rolling forecast True or False')如果上面的参数设置为True那么下面就要提供一个进行滚动预测的数据集,该数据集的格式要和你训练模型的数据集格式完全一致(重要!!!),如果没有可以考虑在自己数据的尾部剪切一部分,不要粘贴否则数据模型已经训练过了的话预测就没有效果了。
parser.add_argument('--rolling_data_path', type=str, default='ETTh1-Test.csv', help='rolling data file')其它的没什么可以讲的了大部分的修改操作在参数讲解的部分我都详细讲过了,这里的滚动预测可能是大家想看的所以摘出来详细讲讲。
全文总结
到此本文已经全部讲解完成了,希望能够帮助到大家,在这里也给大家推荐一些我其它的博客的时间序列实战案例讲解,其中有数据分析的讲解就是我前面提到的如何设置参数的分析博客,最后希望大家订阅我的专栏,本专栏均分文章均分98,并且免费阅读。
概念理解
数据分析
时间序列预测中的数据分析->周期性、相关性、滞后性、趋势性、离群值等特性的分析方法
机器学习——难度等级(⭐⭐)
时间序列预测实战(四)(Xgboost)(Python)(机器学习)图解机制原理实现时间序列预测和分类(附一键运行代码资源下载和代码讲解)
深度学习——难度等级(⭐⭐⭐⭐)
时间序列预测实战(五)基于Bi-LSTM横向搭配LSTM进行回归问题解决
时间序列预测实战(七)(TPA-LSTM)结合TPA注意力机制的LSTM实现多元预测
时间序列预测实战(三)(LSTM)(Python)(深度学习)时间序列预测(包括运行代码以及代码讲解)
时间序列预测实战(十一)用SCINet实现滚动预测功能(附代码+数据集+原理介绍)
时间序列预测实战(十二)DLinear模型实现滚动长期预测并可视化预测结果
Transformer——难度等级(⭐⭐⭐⭐)
时间序列预测模型实战案例(八)(Informer)个人数据集、详细参数、代码实战讲解
时间序列预测模型实战案例(一)深度学习华为MTS-Mixers模型
时间序列预测实战(十三)定制化数据集FNet模型实现滚动长期预测并可视化结果
个人创新模型——难度等级(⭐⭐⭐⭐⭐)
时间序列预测实战(十)(CNN-GRU-LSTM)通过堆叠CNN、GRU、LSTM实现多元预测和单元预测
传统的时间序列预测模型(⭐⭐)
时间序列预测实战(二)(Holt-Winter)(Python)结合K-折交叉验证进行时间序列预测实现企业级预测精度(包括运行代码以及代码讲解)
时间序列预测实战(六)深入理解ARIMA包括差分和相关性分析
融合模型——难度等级(⭐⭐⭐)
时间序列预测实战(九)PyTorch实现融合移动平均和LSTM-ARIMA进行长期预测
