随着模型的复杂度增加,过拟合是怎么导致的?如何解决?
具体原因:
对于多项式曲线的拟合问题,我们定义模型如下所示(蓝色圆圈表示离散的样本点,绿色曲线为拟合样本点的多项式曲线)。
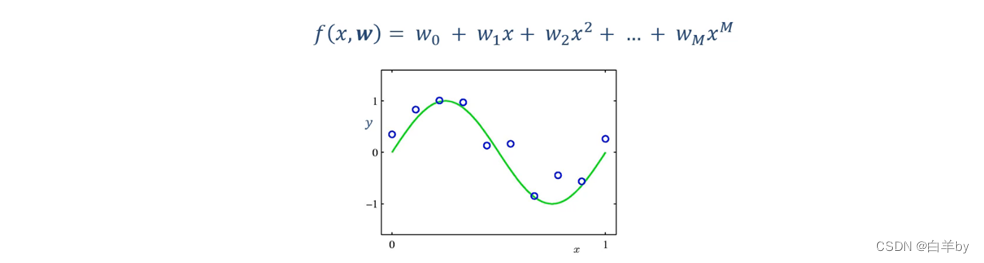
模型的定义十分重要,他会影响最后的拟合效果,其中M为超参数,M很小时,模型比较简单容易出现欠拟合的问题,而如果M很大又容易产生过拟合的问题。
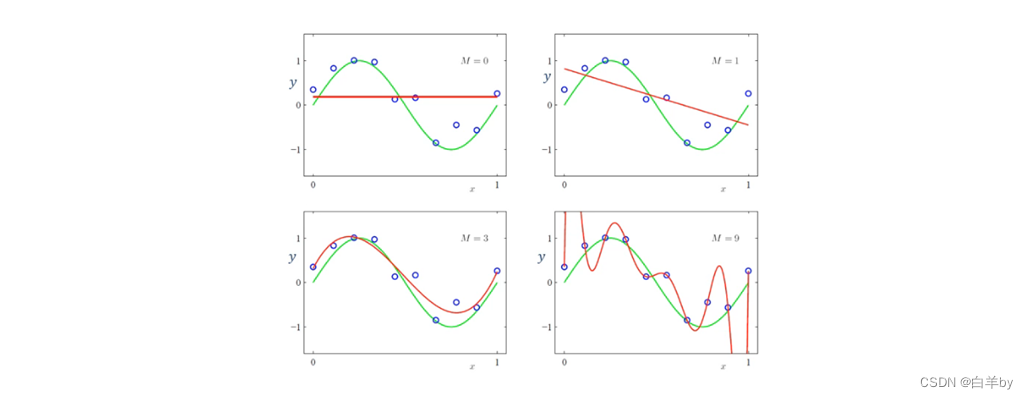
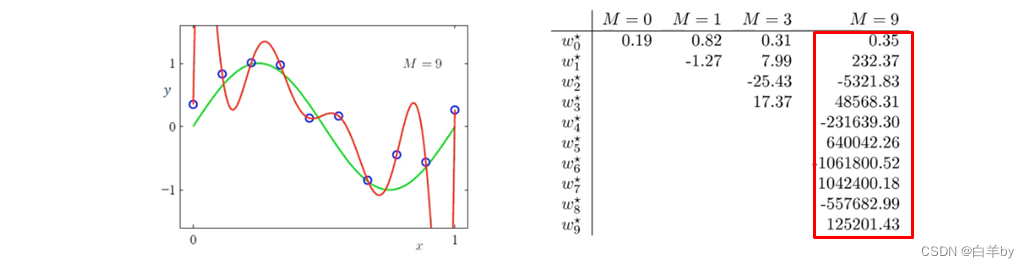
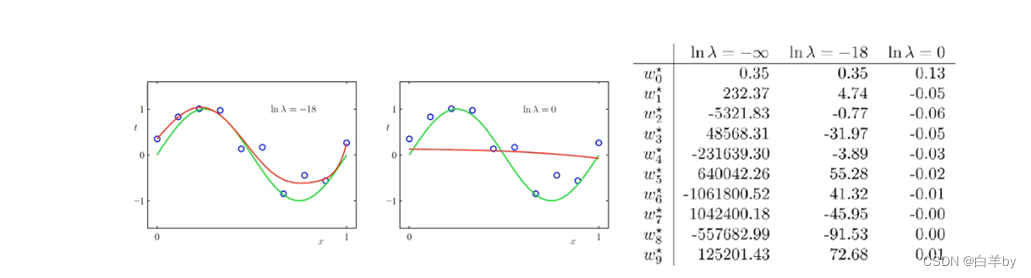
当模型的超参数M选为9时(即多项式次数为9),则模型发生了过拟合,M取不同值时,求解得到经验风险最小化的结果如表所示,由表可以看出,随着M的增大W值疯狂增大,这是因为x取值在(0,1)之间,随着x的次数增大,只有x的系数过大才能对最终结果有一定的影响,例如当x=0.1,则x的9次方只有0.00000000001,所以x的系数为十亿时结果才为1.
解决方法:
随着M的增大,其多项式系数也变大,可以对大的多项式系数惩罚!
引入正则化项
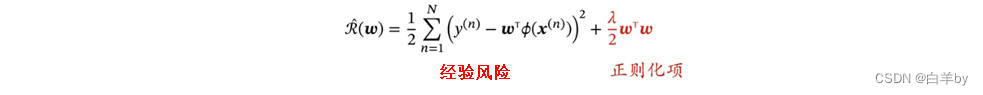
在原有的经验风险的基础上引入正则化项,其中为正则化系数。
用来控制对w惩罚的强弱,当等于
时,对W惩罚较大,W值变小只有72,并且曲线拟合较好。
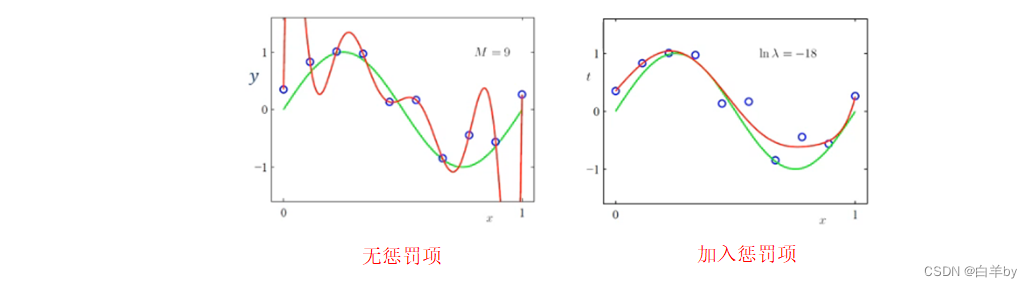
当等于
时几乎起不到惩罚作用,当
等于1时拟合曲线几乎为水平线,惩罚作用很大。
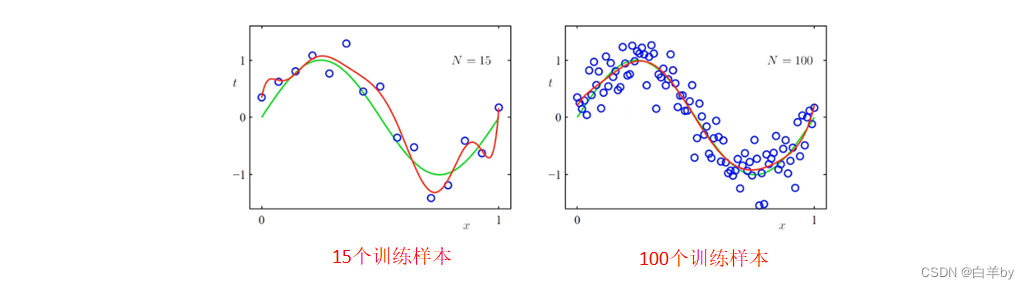
增加训练样本的数量
随着训练样本数量的增加,及时M为9模型较复杂,但是曲线拟合效果越来越好