继针对图像的分割一切之后,针对视频的继针对图像的分割一切之后,针对视频的Track-Anything(追踪一切)来了。
这是我关于分割一切的文章:
北方的郎:Meta Segment Anything 测试效果
Track-Anything其实是在Segment anything的基础上开发出来的,下面是它的论文,代码以及演示Demo:
论文:[2304.11968] Track Anything: Segment Anything Meets Videos (arxiv.org)
代码:https://github.com/gaomingqi/Track-Anything
演示:Track Anything - a Hugging Face Space by watchtowerss
1,论文摘要,技术介绍
论文《Track Anything: Segment Anything Meets Videos》提出了一种视频目标跟踪的新方法。其主要内容整理如下:

Track Anything Model (TAM):一个通用的视频目标跟踪框架,可以跟踪任意目标而不需要手工标注。它包含一下几个模块:Segment Anything Model (SAM),XMem,Interactive Video Object Segmentation,其作用分别如下:
Segment Anything 模型:最近,Meta AI研究提出了Segment Anything模型(SAM),得到了大量关注。作为图像分割的基础模型,SAM基于ViT模型,在大规模数据集SA-1B上训练。SAM在图像上展示了很强的分割能力,特别是在零样本分割任务上。但是,SAM仅在图像分割上显示出色的性能,而无法处理复杂的视频分割。
XMem:给定第一帧目标对象的Mask描述,XMem可以跟踪对象并在后续帧中生成相应的Mask。受Atkinson-Shiffrin记忆模型的启发,其目的是解决长视频中统一特征记忆存储的困难。XMem的缺点也很明显:1)作为半监督VOS模型,它需要精确的Mask进行初始化;2)对于长视频,XMem难以从跟踪或分割失效中恢复。在本文中,我们通过将SAM与交互式跟踪相结合来解决这两个难题。
Interactive Video Object Segmentation(交互式视频对象分割):交互式VOS以用户交互作为输入,例如涂鸦。然后,用户可以反复优化分割结果,直到他们对结果满意。交互式VOS因更容易提供涂鸦而不是指定每个像素的对象Mask而获得许多关注。但是,我们发现当前的交互式VOS方法需要多轮优化结果,这阻碍了它们在实际应用中的效率。
综上,Segment Anything模型可以高质量完成图像分割但未扩展到视频。XMem可以长期跟踪视频目标但需要准确的初始化Mask与难以恢复失效。交互式视频对象分割相对更易使用但需要多轮人工交互进行精细分割。将这三种方法相结合,利用SAM进行高质量视频分割,以XMem进行长期跟踪,并通过人工交互实现精细分割,从而解决视频目标分割与跟踪的难题。如下图所示:

整体效果很不错,如下图所示:

TAM可以很好地处理多目标分割、目标变形、Scale变化和摄像机运动,这表明它仅需要点击初始化和单轮推理就具有出色的跟踪和分割能力。


跟踪精度和速度也都很不错,如下图所示:

2,Demo试用
Demo网址:https://huggingface.co/spaces/watchtowerss/Track-Anything?duplicate=trueg
进入后看到的是一个Gradio开发的界面:

可以上传视频或者选择他们提供的Examples,我这里直接用的Examples里面的猫咪视频,选择猫咪后生成Mask

点击Tracing按钮开始追踪猫咪,效果如下:
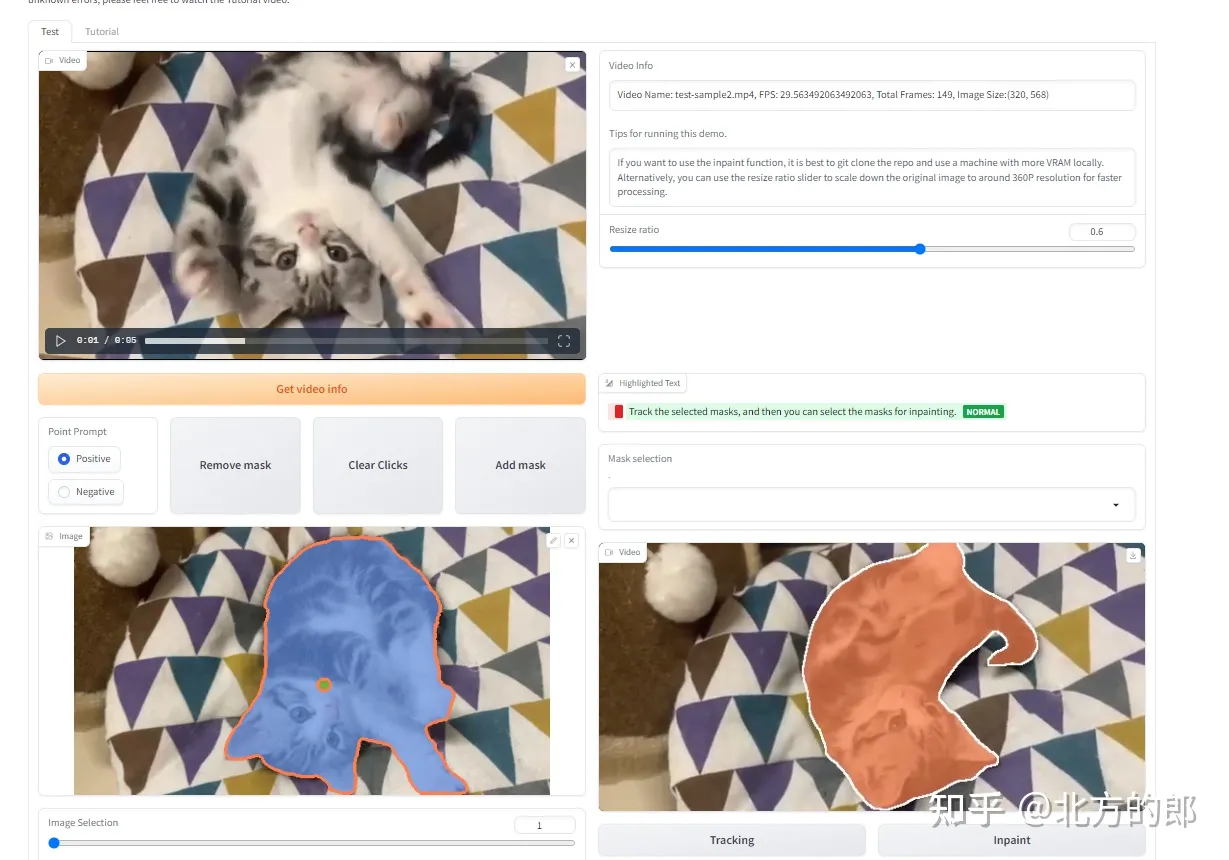
点击Inpaint可以去掉猫咪,效果如下:

整体感觉效果还是很不错的,大家有时间可以去实验一下。