一个程序实现英语四六级高频单词的统计
写在前面
英语四六级考试快到了,相信很多同学只想背一些高频单词,如何知道哪些是高频单词呢,大多数同学都会在网上搜索一通,但自己也不确定搜到的就是高频单词,因此,我们编写一个程序让电脑帮我们统计高频单词,只要给出足够多的英语四六级文章,这样统计出的结果一定会很准确的
这个程序我是用C++编写的,如果你还不会C++也没关系,可以看看其中思路,那么让我们来看看具体实现过程吧
具体过程
- 创建一个单词类,用于存储某个单词及其出现的次数
- 把文档中的英语单词提取出来存储到一个字符串数组中
- 遍历该字符串数组,统计单词出现的次数,并把这个单词及其出现的次数存储到单词类的数组中,对这个数组按照次数降序排序
- 输出需要的高频单词及其个数
1.单词类的创建
class Word
{
public:
string m_word; //某个单词本身
int m_count; //这个单词出现的次数
Word(string word, int count = 0)//count默认值为0
{
m_word = word;
m_count = count;
}
};
2.提取文档中的单词
这里有两种方式:
- 其一是我们直接用键盘输入英语文档(当然基本是复制黏贴)
- 其二是访问文件中的英语文档,但你得提前建立好这个文件,并把要英语文档复制到这个文件中
1.键盘输入
void extractWord(vector<string> &vstr)
{
string str;
cout << "请输入需要统计高频词汇的英语文档,输入 # 结束: " << endl;
//遍历输入的字符,把完整单词存储到 vstr 中,过滤掉标点符号之类的,输入'#'结束循环
while (1)
{
char ch = cin.get();
//如果ch是字母或是 ' ,就把ch加的字符串str后面, ’是为应对类似此类情况:it's
if (ch >= 'A' && ch <= 'Z' || ch >= 'a' && ch <= 'z' || ch == '\'')//
{
if (ch >= 'A' && ch <= 'Z')//大写转小写,
ch += 32;
str += ch;
}//ch不是字母也不是'#'时,说明这个单词已经完整或者这是空串
else if (ch != '#')
{
if (!str.empty())
vstr.push_back(str);//把完整的单词添加到 vstr 尾部
str.clear(); //清空字符串
}//ch 是'#' 时退出循环
else break;
}
}
2.文件输入
void extractWord(vector<string> &vstr)
{
ifstream ifs;
//先手动创建一个txt文件保存英语文章,在你创建的那个路径下打开这个文件
ifs.open("D:\\文本文件\\English.txt", ios::in);
if (!ifs.is_open())
{
cout << "English.txt文件打开失败" << endl;
}
string str;
char ch;
while ((ch = ifs.get()) != EOF)//读取到文件尾结束循环
{
//如果ch是字母或是 ' ,就把ch加的字符串str后面, ’是为应对类似此类情况:it's
if (ch >= 'A' && ch <= 'Z' || ch >= 'a' && ch <= 'z' || ch == '\'')//
{
if (ch >= 'A' && ch <= 'Z')//大写转小写,
ch += 32;
str += ch;
}//ch不是字母也不是'#'时,说明这个单词已经完整或者这是空串
else if (ch != '#')
{
if (!str.empty())
vstr.push_back(str);//把完整的单词添加到 vstr 尾部
str.clear(); //清空字符串
}
else break;
}
ifs.close();
}
3.计算单词出现的次数
这里是这个程序的核心部分了。
虽然我们是要统计高频单词的,但有些例如:a、the、in、my等基础到不能再基础的单词,我们是不想统计的。
要解决这个问题,我们可以用一个文本文件先把这些不希望计入统计的单词记录下来,然后在程序运行时读取该文件,对文件中的单词特殊处理,达到让程序不进行统计的目的即可
1.把不计入统计的单词预先初始化
void notCaculate(vector<Word>& vWords)
{
ifstream ifs;
//先手动创建一个txt文件保存基础单词,在你创建的那个路径下打开这个文件
ifs.open("D:\\文本文件\\word.txt", ios::in);
if (!ifs.is_open())
{
cout << "文件打开失败!" << endl;
}
string str;
//读取文件中的单词(遇到空格读取下一个),把读取的单词存到Word类数组中
while (ifs >> str)
{
Word w(str);
vWords.push_back(w);
}
}
我在 word.txt 中加入的是以下内容,你可以自行添加更多的简单词汇
a b c d e f g h i g k l m n o p q r s t u v w x y z
one two three four five six seven eight nine ten
an the am is are be and or can should would
it my me he she his him you your we us our they them their that this there
at on in before after by with in at on over from to up down as for of
too have has do did does more yes no not some any time

2.计算单词出现的频率
void caculateWordFrequency(vector<Word> &vWords,const vector<string> vstr)
{
notCaculate(vWords);//调用上面的函数
for (string str : vstr)//遍历所有单词求出现的次数
{
bool flag = false;//用于判断是否在vWords中找到相同的单词
//遍历vWords,把未出现在vWords中的单词添加进去,统计出现的单词数量
for (int i = 0; i < vWords.size(); ++i)
{
//如果找到相同单词,这个单词的数量加1
if (str == vWords[i].m_word)
{
flag = true;
//次数为0的是不计入统计的单词
if (vWords[i].m_count != 0)
vWords[i].m_count++;
break;
}
}
//如果没有找到,就把这个单词添加到vWords中
if (flag == false)
{
Word w(str, 1);
vWords.push_back(w);
}
}
}
4.排序并打印
- 利用sort()函数进行排序,但我们需要写一个排序规则的函数,规则是按照单词出现的次数降序排序,次数相同按照字符大小升序排序
- 排序过后,我们输出前num个高频单词,num由键盘输入
//排序规则函数
int compare(Word w1, Word w2)
{
if (w1.m_count == w2.m_count)
return w1.m_word < w2.m_word;
return w1.m_count > w2.m_count;
}
//先进行排序,再输出前num个高频单词
void printWord(vector<Word> vWords,int num)
{
sort(vWords.begin(), vWords.end(), compare);//调用STL算法排序函数
cout << "\t单词 \t\t| 出现次数 |" << endl;
cout << "-----------------------------------------" << endl;
for (int i = 0; i < vWords.size() && i < num; ++i)
{
if (vWords[i].m_count != 0)
{
//setw(w)控制后一个输出宽度为w个字符,右对齐
cout <<setw(15)<< vWords[i].m_word << "\t\t| "
<< "\t" << vWords[i].m_count << "\t|" << endl;
cout << "-----------------------------------------"<< endl;
}
}
}
源码汇总
- 删减了部分注释,提升观感。
- 英语文档的输入部分的代码,我是用的是第二种文件输入,想用键盘输入的同学,用上面键盘输入的代码替换掉文件输入的即可
#include<iostream>
#include<string> //使用string需要包含的头文件
#include<fstream> //文件操作需要包含的头文件
#include<vector> //使用vector容器需要包含的头文件
#include<algorithm>//使用sort()排序算法需要包含的头文件
#include<iomanip> //使用setw()输出格式对齐需要包含的头文件
using namespace std;
class Word
{
public:
string m_word;
int m_count;
Word(string word, int count = 0)//count默认为0
{
m_word = word;
m_count = count;
}
};
//文件输入英语文档(可以用键盘输入替换),提取其中的英语单词
void extractWord(vector<string> &vstr)
{
ifstream ifs;
//先手动创建一个txt文件保存英语文章,在你创建的那个路径下打开这个文件
ifs.open("D:\\文本文件\\English.txt", ios::in);
if (!ifs.is_open())
{
cout << "English.txt文件打开失败" << endl;
}
string str;
char ch;
while ((ch = ifs.get()) != EOF)//读取到文件尾结束循环
{
//如果ch是字母或是 ' ,就把ch加的字符串str后面, ’是为应对类似此类情况:it's
if (ch >= 'A' && ch <= 'Z' || ch >= 'a' && ch <= 'z' || ch == '\'')//
{
if (ch >= 'A' && ch <= 'Z')//大写转小写,
ch += 32;
str += ch;
}//ch不是字母也不是'#'时,说明这个单词已经完整或者这是空串
else if (ch != '#')
{
if (!str.empty())
vstr.push_back(str);//把完整的单词添加到 vstr 尾部
str.clear(); //清空字符串
}
else break;
}
ifs.close();
}
//把不计入统计的单词预先初始化
void notCaculate(vector<Word>& vWords)
{
ifstream ifs;
//先手动创建一个txt文件保存基础单词,在你创建的那个路径下打开这个文件
ifs.open("D:\\文本文件\\word.txt", ios::in);
if (!ifs.is_open())
{
cout << "\word.txt文件打开失败!" << endl;
}
string str;
//读取文件中的单词(遇到空格读取下一个),把读取的单词存到Word类数组中
while (ifs >> str)
{
Word w(str);
vWords.push_back(w);
}
ifs.close();
}
//计算单词出现的频率
void caculateWordFrequency(vector<Word> &vWords,const vector<string> vstr)
{
notCaculate(vWords);//把不计入统计的单词预先初始化
for (string str : vstr)//遍历所有单词求出现的频率
{
bool flag = false;//用于判断是否在vWords中找到相同的单词
for (int i = 0; i < vWords.size(); ++i)
{
if (str == vWords[i].m_word)//如果找到,这个单词的数量加1
{
flag = true;
if (vWords[i].m_count != 0)
vWords[i].m_count++;
break;
}
}
if (flag == false)
{
Word w(str, 1);
vWords.push_back(w);
}
}
}
//排序规则函数
int compare(Word w1, Word w2)
{
if (w1.m_count == w2.m_count)
return w1.m_word < w2.m_word;
return w1.m_count > w2.m_count;
}
//先进行排序,再输出前num个高频单词
void printWord(vector<Word> vWords,int num)
{
sort(vWords.begin(), vWords.end(), compare);
cout << "\t单词 \t\t| 出现次数 |" << endl;
cout << "-----------------------------------------" << endl;
for (int i = 0; i < vWords.size() && i < num; ++i)
{
if (vWords[i].m_count != 0)
{
//setw(w)控制后一个输出宽度为w个字符,右对齐
cout <<setw(15)<< vWords[i].m_word << "\t\t| "
<< "\t" << vWords[i].m_count << "\t|" << endl;
cout << "-----------------------------------------"<< endl;
}
}
}
int main()
{
vector<string> vstr;
extractWord(vstr);
vector<Word> vWords;
caculateWordFrequency(vWords, vstr);
int num;
cout << "输入需要打印的高频单词的数量:";
cin >> num;
cout << "高频单词及其出现的次数如下:" << endl;
printWord(vWords, num);
}
测试及结果
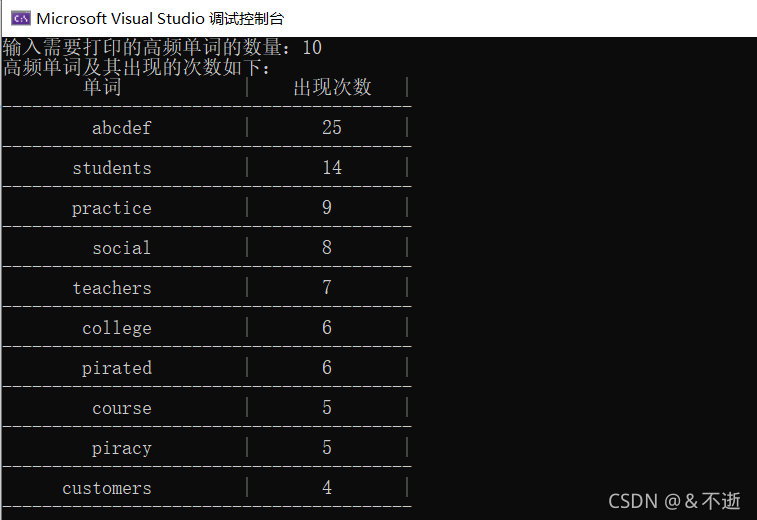
随便找了几篇英语作文复制到 English.txt 文件中,为了测试统计的单词出现的次数对不对,我在文件中加了25个 abcdef
结果如下
如何优化
英语中一个单词有多种形式,如:
- 动词的原型、三单、过去分词、现在分词等
- 名词的形容词、副词形式等
本质上这些不同的形式的单词都属于同一个单词,因此可以优化计数规则,把一个单词的不同形式计算在一起。具体如何实现这个规则,感兴趣的同学可以自己尝试。
至于为什么我不去实现一下呢,我绝对不会说我自己也没想好,哈哈哈