。
前言
现在和班上同学组了一个小组跟老师进行一个项目–人工智能案例教学。老师给我们四个案例—手写识别,猫狗大战,车牌识别,典型植物识别。,在学习的过程中把学习过程记录下来,写成教程。
而这篇博客则就是用来记录学习过程。那现在就开始吧
什么是神经网络
正所谓工欲善其事,必先利其器。想要学习神经网络,就要在电脑上配置好合适的环境。
准备工作
所需下载的东西都可在资料包中下载。提取码:tqvy
- python安装
在python下载地址根据自己电脑的环境,来下载合适的版本。我根据老师给的资料包安装的python3.7.1版本。下载好安装包之后,就可以安装了。
step1

step2
默认全选,直接点击next,就可以了

step3
这个路径就是安装路径也是python的运行路径。我一般都会把这类编译语言统一放在非系统盘里的一个文件夹里,命名为Environment。这样便于集中管理。

等待安装完成。
step4
安装完成之后,可以命令提示符来查看是否安装成功。同时按住win+R,在运行里面输入cmd,按回车执行。

进入界面之后,输入python,按下回车。出现“Python 版本号”则安装成功。
- 安装jupyter
1、首先介绍一下什么是jupyter。
Jupyter Notebook是一个开源的Web应用程序,允许用户创建和共享包含代码、方程式、可视化和文本的文档。它的用途包括:数据清理和转换、数值模拟、统计建模、数据可视化、机器学习等等。它具有以下优势:
- 可选择语言:支持超过40种编程语言,包括Python、R、Julia、Scala等。
- 分享笔记本:可以使用电子邮件、Dropbox、GitHub和Jupyter Notebook * * Viewer与他人共享。
- 交互式输出:代码可以生成丰富的交互式输出,包括HTML、图像、视频、LaTeX等等。
- 大数据整合:通过Python、R、Scala编程语言使用Apache Spark等大数据框架工具。支持使用pandas、scikit-learn、ggplot2、TensorFlow来探索同一份数据。
说简单一点就是一款编译器,可以在上面写python代码。
2、安装
我个人建议使用pip安装,方面快捷一点。那pip有是什么东西呢?pip 是 Python 中的标准库管理器。它允许你安装和管理不属于 Python标准库的其它软件包。我个人理解为pip等同于linux中的yum和note.js中的npm,都是用来下载东西的。
因为在安装python的时候,同时也安装了pip。但是那个版本太低了,下载包时可能会出现一些问题,所以我们要升级一下。
打开命令提示符,进入到python的安装文件夹下的Scripts文件夹中,你在这个文件夹中就可以看到pip.exe。点击窗口栏中的地址栏,输入cmd,进入当前路径的命令提示符。

执行如下命令
pip install --upgrade pip

出现这个,pip更新安装成功。
现在安装Jupyter Notebooks
还是在Scripts文件夹路径的命令提示符下,输入如下指令
pip install jupyter
安装完成后,在Scripts文件夹下,会出现jutpter有关的文件,表示安装成功

现在进入命令提示符,输入如下指令
jupyter notebook

这时会自动跳转到浏览器。
进入到浏览器后,会显示当前电脑用户下的所有文件,不太方便。这时我们可以更改启动路径。进入到电脑当前用户下的文件夹。


在记事本中按住Ctrl+F进行查找,查找内容为:#c.NotebookApp.notebook_dir =


修改完之后,保存。重新在命令提示符里输入jupyter notebook。进入浏览器后,会发现在自己想要的路径之中。
到了这里,jupyter就安装完成了。
- 安装其他的库
首先要安装whl。whl是python中特有的安装包。进入Scripts路径的命令提示符中输入pip install wheel。出现Successfully installed这表明安装成功。
1、numpy
这个拓展包就十分强大了,在后面学习中,会频繁调用其中的库函数。
首先下载numpy.whl文件放入Scripts文件夹中。然后,进入Scripts路径的命令提示符中输入pip install 下载的文件名.whl,就可以安装了。成功之后也会出现Successfully installed。
2、matplotlib
matplotlib是Python编程语言及其数值数学扩展包 NumPy的可视化操作界面,可以把数据可视化出来。方法同上。
3、pickle
直接在Scripts路径的命令提示符中输入pip install pickle。
4、直接在Scripts路径的命令提示符中输入pip install tqdm - 将MNIST文件放入Scripts中
MNIST(Modified National Institute of Standards and Technology)是一个数据集。包含手写数字的扫描和相关标签(描述每个图像是0-9中的哪个数字)。具体介绍进Yann LeCun教授的个人主页。可在资料包中下载。
到了这里所有的准备工作已经完成了,可以正式开始学习了。
知识补充
根据老师给的资料,我是通过B站UP大野喵渣的视频进行学习。是他的专栏视频—从零开始神经网络系列。传送门
虽然,在一个视频中,up主已经用绘图生动形象地对神经网络进行了讲解。但还是有点抽象。接下来,我将进行一些补充。
首先,我们要知道什么的神经网络。在机器学习和认知科学领域,是一种模仿生物神经网络(动物的中枢神经系统,特别是大脑)的结构和功能的数学模型或计算模型,用于对函数进行估计或近似。我的理解是,通过设立一个模型,让计算机像动物的神经网络网络一样处理数据。如果你有一点生物知识的话,应该知道在我们人的大脑里面,有着一个一个的神经元,也叫做神经细胞。而神经元能感知环境的变化,再将信息传递给其他的神经元,并指令集体做出反应。那么在计算机中,我构建一个模型,我对这个模型进行一个数据的输入,经过这个模型的转换,把结果给输出。在计算机中设立许多这样的模型,再让他们作为彼此的输入和输出,即相互联级。就像神经网络一样,形成一个网络。这样就可以对数据进行复杂的处理。基本结构如下所示:

这里分成了三个部分:
- input layer(输入层):数据的输入
- hidden layer(隐藏层):对数据进行处理,可以有多层
- output layer(输出层):数据的输出
其实这个的数学模型就是复合函数—f(g(x)),进行不断的复合。在复合函数中
除了要有输入数据x和输出数据f(x),那还要有参数,例如f(x)=ax+b。这样就可以表示一个平面上的所有直线。
在神经网络中,也是如此。如图所示:

- a1~an为输入向量的各个分量
- w1~wn为神经元各个突触的权值(weight)
- b为偏置
- f为传递函数,通常为非线性函数。
- t为神经元输出
由于输入可以输入多个不同变量,参数也可以是多个不同的参数,那就可以用向量来表示。这就涉及到一点线性代数方面的知识。强烈建议上B站看一下这个系列的视频,让你在线性代数上有一个几何层次的了解。传送门
那数学表示就可以是这个:

这就是单个神经元的数学模型。那神经网络就是对神经元的复合。
而现在所学习的手写识别案例中,输入是2828个数据。这个是怎么来的呢?众所周知,图片是由一个一个像素点组成的。比如我们常说的1080P就是表示1920(长)1080(宽)的垂直像素分布,也就是大概是200万个像素点。而在MNIST中的数据集中的图片,所采用的是2828的像素分布。而在计算机中,像素可以用二进制数表示,也就是一个一个的数据。输出是10,就是0~9十个数字。
在第一个视频中,就只要两层,一个输入层和一个输出层,中间没有隐藏层。视频中,把输入的数据定义为data。那输入层的数学模型就是L0=A(data+b0)。这里的A,就是指函数。在神经网络中,这个函数也叫做激活函数(Activation)。输出层的数学模型就是L1=A’(L0·w1+b1)。在视频中,已经给出激活函数A=tanh(x),A‘=softmax(x)。
tanh(x)是双曲正切函数。可以在numpy中直接调用。具体内容可参考这个传送门
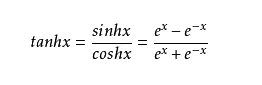
softmax(x)是归一化指数函数。具体内容可参考这个传送门
激活函数有了,接下来就是确定参数。因为data有2828=784个,所以b0有784个,L0也要有1784个。输出L1是10个,L0内积权值w1,w1是78410。L0·w1=[1784]·[78410]=[10],b0也是10。到了这里基本知识点已经补充完了。
代码解释
对代码实现不懂的可以参考下面代码:
#导入程序库
import numpy as np #将numpy导入进来,这个库是用来计算维度数组与矩阵运算
import math #基本的函数运算
#激活函数 也就是下面的activation 对输入进来的值进行非线性函数变换,
def tanh(x): #numpy中自带,直接调用即可
return np.tanh(x)
def softmax(x): #归一化函数,就是求某个数出现的概率
exp=np.exp(x-x.max()) #避免出现指数爆炸,指数部分减去一个最大值
return exp/exp.sum()
dimensions=[28*28,10]#维数,在本例中就两个,一个输入和一个输出。输入是28*28的像素数据,输出是0-9的10个数
activation=[tanh,softmax]#激活函数,因为有两个维度,所以要有两个激活函数对输入数据进行非线性变换
#激活函数的参数,例如激活函数f(x),这只是一个基本函数,如同y=x,只能表示一条单一过原点的直线。而现在有两个参数w和b,作用在f(x)的x上,f(wx+b),如同
# y=ax+b,则可任意一条直线。根据本例,b0,b1都是0,w1如代码所示。
distribution=[ #用{}圈起来的是字典,形如key:value,在这里的值是列表。也就是说b是一个列表,第一个值是0,第二个值也是0.后面的w同理。总体的看,这
#两个维度的参数是放在列表里面,不同维度的参数用字典来表示,参数的值则是在字典中嵌套列表表示
{
'b':[0,0]},
{
'b':[0,0],'w':[-math.sqrt(6/(dimensions[0]+dimensions[1])),+math.sqrt(6/(dimensions[0]+dimensions[1]))]},
]
#对 b和w初始化
def init_parameters_b(layer):
dist=distribution[layer]['b']#第一个[]是表示distribution第一个元素,元素是字典,用第二个[]取出key的值
#np.random.rand(x),生成x个(0,1]的随机数,假如值是[a,b],那就要用(b-a)*(0,1}+a,这样范围才会在a,b之间
return np.random.rand(dimensions[layer])*(dist[1]-dist[0])+dist[0]
def init_parameters_w(layer):
dist=distribution[layer]['w']
#因为有两个参数b1和w1,所以参数是layer-1和layer
return np.random.rand(dimensions[layer-1],dimensions[layer])*(dist[1]-dist[0])+dist[0]
def init_parameters():
parameter=[]
for i in range(len(distribution)):
layer_parameter={
}
for j in distribution[i].keys():
if j=='b':
layer_parameter['b']=init_parameters_b(i)
continue
if j=='w':
layer_parameter['w']=init_parameters_w(i)
continue
parameter.append(layer_parameter)
return parameter
parameters=init_parameters()
#预测,生成的随机数中,那个数字出现概率最大
def predict(img,parameters):
l0_in=img+parameters[0]['b']
l0_out=activation[0](l0_in)
l1_in=np.dot(l0_out,parameters[1]['w'])+parameters[1]['b']
l1_out=activation[1](l1_in)
return l1_out
predict(np.random.rand(784), parameters).argmax
我对代码进行了注释,进行了跟进一步的解释和说明。这样方便大家进来理解,在看视频时不至于一脸懵逼。