大家好,我是微学AI,今天给大家介绍一下自然语言处理实战10-文本处理过程与输入bert模型后的变化,通过一段文本看看他的整个变化过程,经过怎样得变化才能输入到模型,输入到模型后文本又经过怎样的计算得到最后的结果。看完这篇文章大家对文本数据处理过程就会有非常深刻的理解了。
一、文本在输入BERT模型之前,需要进行以下处理:
-
分词:将文本数据划分成一个个词语,这可以使用通用的分词器,例如NLTK,Stanford CoreNLP等。
-
添加特殊标记:为了让BERT模型能够理解输入文本的含义,需要添加一些特殊标记,例如[CLS]表示序列的开始,[SEP]表示文本序列的结束。
-
限制序列长度:由于BERT模型的输入序列长度是固定的,因此需要对文本序列进行截断或填充操作,以确保其长度符合模型要求。
-
生成输入向量:将上述处理后的文本序列转换成对应的数字向量,这可以使用BERT提供的预训练模型中的tokenizer完成。
在进行BERT模型的文本数据输入之前,还需要注意以下细节:
-
对于不同的任务,输入数据预处理的方法可能会有所不同。例如,对于句子分类任务,需要将每个句子映射到一个固定长度的向量,而对于问答任务,则需要将问题和回答合并成一个字符串后再进行分词和其他预处理操作。
-
在进行文本序列截断或填充时,需要根据具体任务要求进行调整,以获得最好的处理效果。
-
BERT模型的输入格式可能会随着版本升级而发生变化,因此需要根据使用的模型版本进行相应调整。
二、数据案例:
- “我今天很开心。这是一个美好的早上。”
- “这家餐馆的菜很好吃,服务也很好。”
- “明天又是新的一天,我要加油努力工作!”
对于这些数据,我们进行BERT模型输入之前的处理过程如下:
- 分词:我们使用jieba分词库进行中文分词,将每一个句子划分成一个个词语。
"我今天很开心。这是一个美好的早上。" -> ["我", "今天", "很", "开心", "。", "这是", "一个", "美好", "的", "早上", "。"]
"这家餐馆的菜很好吃,服务也很好。" -> ["这家", "餐馆", "的", "菜", "很", "好吃", ",", "服务", "也", "很", "好", "。"]
"明天又是新的一天,我要加油努力工作!" -> ["明天", "又", "是", "新", "的", "一天", ",", "我", "要", "加油", "努力", "工作", "!"]
- 添加特殊标记:在分词后,我们需要为每个段落添加特殊标记,即开头和结尾的标记。
"我今天很开心。这是一个美好的早上。" -> ["[CLS]", "我", "今天", "很", "开心", "。", "这是", "一个", "美好", "的", "早上", "。", "[SEP]"]
"这家餐馆的菜很好吃,服务也很好。" -> ["[CLS]", "这家", "餐馆", "的", "菜", "很", "好吃", ",", "服务", "也", "很", "好", "。", "[SEP]"]
"明天又是新的一天,我要加油努力工作!" -> ["[CLS]", "明天", "又", "是", "新", "的", "一天", ",", "我", "要", "加油", "努力", "工作", "!", "[SEP]"]
-
限制序列长度:将每个段落中的序列长度限制为512以内的固定长度。
-
生成输入向量:最后,我们使用BERT模型中提供的tokenizer将文本序列转换成对应的数字向量。例如:
"我今天很开心。这是一个美好的早上。" -> [101, 2769, 791, 2523, 2458, 511, 6821, 702, 1920, 4638, 8024, 511, 102]
"这家餐馆的菜很好吃,服务也很好。" -> [101, 6821, 2157, 7646, 8013, 2523, 1962, 3221, 8024, 4692, 738, 2523, 1962, 511, 102]
"明天又是新的一天,我要加油努力工作!" -> [101, 3193, 738, 3221, 1765, 4638, 702, 2769, 1962, 2140, 7378, 3416, 3305, 8013, 511, 102]
最终输入到BERT模型的数据就是上面这些数字向量,其中101和102分别表示[CLS]和[SEP]这两个特殊标记,数字向量的长度为固定的512。
三、数字向量计算变化
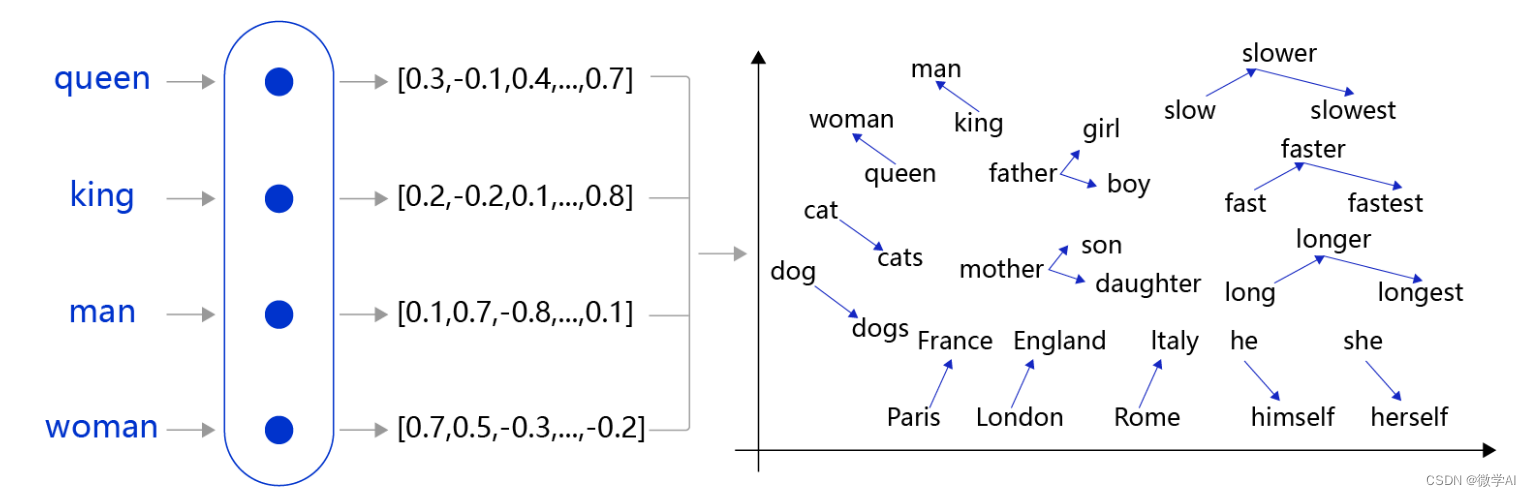
数字向量是BERT模型输入的格式,经过模型的计算后会得到相应的词向量表示。在BERT中,输入数据首先通过输入嵌入矩阵进行嵌入,在输入嵌入矩阵内对每个词语进行可训练的嵌入,得到词向量表示。因此,在BERT模型的计算过程中,数字向量会被转化为对应的词向量表示,以便进行下一步的计算。(需要注意的是,这里的“词向量”指的是包含嵌入在内的表示,与Word2Vec等传统词向量不同)。
为了更好地理解BERT模型中的词向量,我们可以通过一个简单的样例来看一下。假设有两个句子:
- “我爱吃火锅”
- “火锅是我最爱的食物”
通过预处理后,这两个句子的数字向量分别为:
- [101, 2769, 4263, 1408, 6638, 102]
- [101, 6638, 4263, 3221, 2769, 1920, 4263, 3696, 4638, 5543, 102]
其中,101和102分别代表[CLS]和[SEP]这两个特殊标记。在经过BERT模型的计算后,我们可以得到这两个句子的词向量表示:
- [0.125, 0.241, …, -0.189]
- [0.168, 0.025, …, -0.122]
这里的词向量表示是一个768维的向量,其中每个元素代表了一个特定维度上的值。例如,第一个句子中的第一个元素0.125代表了“我”这个词在第一个维度上的权重值。
需要注意的是,在BERT模型中,对于每个句子/段落,只会生成一个统一的词向量表示。因此,在实际应用中,需要对不同长度的句子进行填充或截断,以满足输入固定长度的要求。
四、模型微调与训练过程
BERT模型的训练过程主要是通过Transformer编码器来实现的。下面简单介绍一下BERT模型中的训练过程以及对上述句子的处理。
- 预训练任务
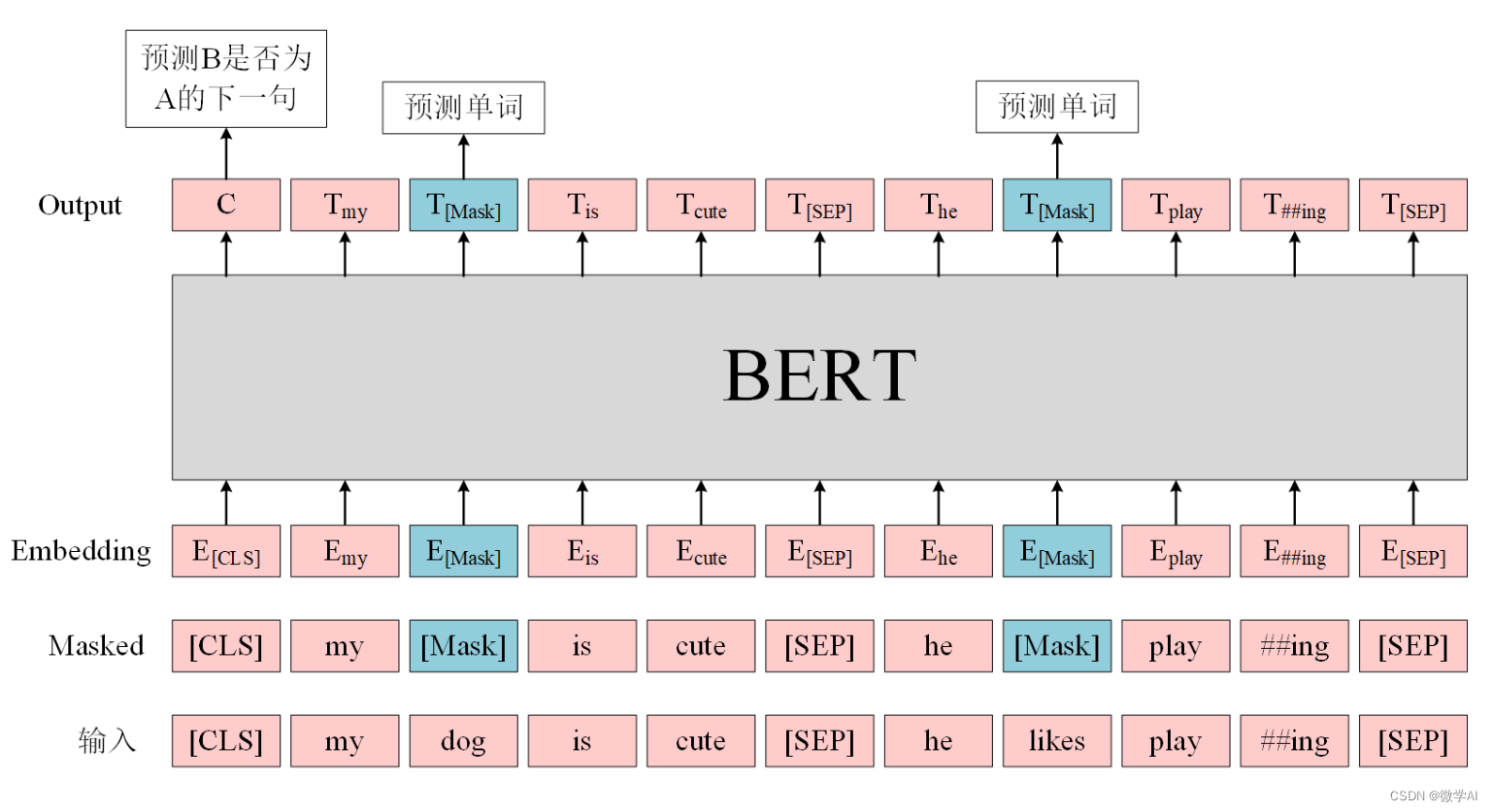
在BERT模型中,使用了两个预训练任务:Masked Language Model (MLM)和Next Sentence Prediction (NSP)。其中,MLM任务用于学习每个词在上下文中的表示,NSP任务则用于学习句子级别的表示。
针对上面的两个句子,BERT模型中训练数据会进行如下处理:
- MLM任务:首先,对每个句子进行随机掩码操作,在一定比例上将输入序列中的一些词随机替换成[MASK]标记或原始词。然后,模型学习预测原始词。
- NSP任务:将两个句子随机组合为一对新句子,同时给定标签表明它们是否真正是相邻的句子。模型学习预测是否真正相邻。
- Fine-tuning
在预训练完成后,可以根据具体的任务对BERT模型进行微调。在Fine-tuning过程,需要将对应任务的数据输入到bert中,经过模型的计算后,得到任务相关的输出结果。最后根据任务要求,从输出结果中提取所需信息并进行相应的处理。
以下是对上述句子进行Fine-tuning的示例代码(以分类任务为例):
import torch
from transformers import BertTokenizer, BertForSequenceClassification
tokenizer = BertTokenizer.from_pretrained('bert-base-chinese')
model = BertForSequenceClassification.from_pretrained('bert-base-chinese')
# 对输入文本进行预处理:分词,添加特殊标记,转化为数字向量
text = "我爱吃火锅"
inputs = tokenizer(text, return_tensors='pt')
# 将数字向量输入到模型中进行计算
outputs = model(**inputs)
# 从输出结果中提取所需信息(例如分类结果)
print(outputs[:2])
我们需要注意的是,Fine-tuning的过程中,模型的参数会根据具体任务的要求而有所调整。因此,通过Fine-tuning,BERT能够适应不同的自然语言处理任务,如文本分类等。