♥️作者:小刘在C站
♥️个人主页:小刘主页
♥️每天分享云计算网络运维课堂笔记,努力不一定有回报,但一定会有收获加油!一起努力,共赴美好人生!
♥️树高千尺,落叶归根人生不易,人间真情
前言
本次MySQL—索引章节比较多,分为多篇进行发布,本章继续,链接—上一章
目录
6 索引使用
6.1 验证索引效率

select * from tb_sku where id = 1\G;
可以看到即使有1000w的数据,根据id进行数据查询,性能依然很快,因为主键id是有索引的。 那么接下来,我们再来根据 sn 字段进行查询,执行如下SQL:
SELECT * FROM tb_sku WHERE sn = '100000003145001';
我们可以看到根据sn字段进行查询,查询返回了一条数据,结果耗时 20.78sec,就是因为sn没有索引,而造成查询效率很低。
那么我们可以针对于sn字段,建立一个索引,建立了索引之后,我们再次根据sn进行查询,再来看一下查询耗时情况。
创建索引:
create index idx_sku_sn on tb_sku(sn) ;
SELECT * FROM tb_sku WHERE sn = '100000003145001';
我们明显会看到,sn字段建立了索引之后,查询性能大大提升。建立索引前后,查询耗时都不是一个数量级的。
6.2 最左前缀法则

explain select * from tb_user where profession = '软件工程' and age = 31 and status
= '0';
explain select * from tb_user where profession = '软件工程' and age = 31;
explain select * from tb_user where profession = '软件工程';
explain select * from tb_user where age = 31 and status = '0'; 
explain select * from tb_user where status = '0';
explain select * from tb_user where profession = '软件工程' and status = '0';
6.3 范围查询
explain select * from tb_user where profession = '软件工程' and age > 30 and status
= '0';
explain select * from tb_user where profession = '软件工程' and age >= 30 and
status = '0';
6.4 索引失效情况
6.4.1 索引列运算

A. 当根据phone字段进行等值匹配查询时, 索引生效。
explain select * from tb_user where phone = '17799990015';
B. 当根据phone字段进行函数运算操作之后,索引失效。
explain select * from tb_user where substring(phone,10,2) = '15';
6.4.2 字符串不加引号
explain select * from tb_user where profession = '软件工程' and age = 31 and status
= '0';
explain select * from tb_user where profession = '软件工程' and age = 31 and status
= 0;
explain select * from tb_user where phone = '17799990015';
explain select * from tb_user where phone = 17799990015;
经过上面两组示例,我们会明显的发现,如果字符串不加单引号,对于查询结果,没什么影响,但是数据库存在隐式类型转换,索引将失效。 \
6.4.3 模糊查询
explain select * from tb_user where profession like '软件%';
explain select * from tb_user where profession like '%工程';
explain select * from tb_user where profession like '%工%';
6.4.4 or连接条件
explain select * from tb_user where id = 10 or age = 23;
explain select * from tb_user where phone = '17799990017' or age = 23;
由于age没有索引,所以即使id、phone有索引,索引也会失效。所以需要针对于age也要建立索引。
create index idx_user_age on tb_user(age); ![]()
建立了索引之后,我们再次执行上述的SQL语句,看看前后执行计划的变化。

最终,我们发现,当or连接的条件,左右两侧字段都有索引时,索引才会生效。
6.4.5 数据分布影响
select * from tb_user where phone >= '17799990005';
select * from tb_user where phone >= '17799990015';
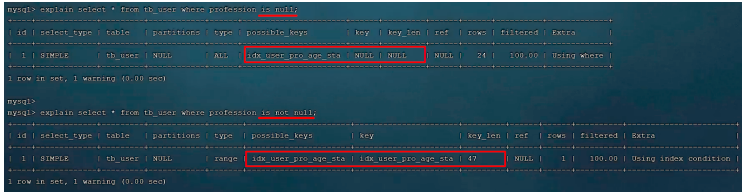
接下来,我们再来看看 is null 与 is not null 操作是否走索引。
explain select * from tb_user where profession is null;
explain select * from tb_user where profession is not null;
接下来,我们做一个操作将profession字段值全部更新为null。

♥️关注,就是我创作的动力
♥️点赞,就是对我最大的认可
♥️这里是小刘,励志用心做好每一篇文章,谢谢大家