关键词:AIGC,Artificial Intelligence Generated Content
【ChatGPT】人工智能生成内容的综合调查(AIGC):从 GAN 到 ChatGPT 的生成人工智能历史
A Comprehensive Survey of AI-Generated Content (AIGC):
A History of Generative AI from GAN to ChatGPT
【禅与计算机程序设计艺术:导读】2022年,可以说是生成式AI的元年。近日,俞士纶团队发表了一篇关于AIGC全面调查,介绍了从GAN到ChatGPT的发展史。
论文地址:
刚刚过去的2022年,无疑是生成式AI爆发的奇点。
自2021年起,生成式AI连续2年入选Gartner的「人工智能技术成熟度曲线」,被认为是未来重要的AI技术趋势。
近日,俞士纶团队发表了一篇关于AIGC全面调查,介绍了从GAN到ChatGPT的发展史。

本文节选了论文部分内容进行介绍。
奇点已来?
近年来,人工智能生成内容(AIGC,也称生成式AI)引发了计算机科学界以外的广泛关注。
整个社会开始对大型科技公司开发的各种内容生成的产品,如ChatGPT和DALL-E-2,产生了极大兴趣。
AIGC,是指使用生成式人工智能(GAI)技术生成内容,并可以在短时间内自动创建大量内容。
ChatGPT是OpenAI开发的一个用于构建会话的AI系统。该系统能够以一种有意义的方式有效地理解人类语言并作出回应。
此外,DALL-E-2也是OpenAI开发的另一种最先进的GAI模型,能够在几分钟内从文本描述中创建独特的高质量图像。
图1. AIGC 在图像生成中的示例
AIGC refers to content that is generated using advanced Generative AI (GAI) techniques, as opposed to being created by human authors, which can automate the creation of large amounts of content in a short amount of time. For example, ChatGPT is a language model developed by OpenAI for building conversational AI systems, which can efficiently understand and respond to human language inputs in a meaningful way. In addition, DALL-E-2 is another state-of-the-art GAI model also developed by OpenAI, which is capable of creating unique and high-quality images from textual descriptions in a few minutes, such as "an astronaut riding a horse ina photorealistic style" as shown in Figure 1. As the remarkable achievements in AIGC, many people believe it will be the new era of AI and make significant impacts on the whole world.
AIGC是指使用高级生成人工智能(GAI)技术生成的内容,如而不是由人类作者创建,后者可以自动创建大量在短时间内完成大量内容。例如,ChatGPT是由用于构建对话式人工智能系统的OpenAI,可以有效地理解和响应人类语言以有意义的方式输入。此外,DALL-E-2是另一种最先进的GAI 该模型也是由OpenAI开发的,能够创建独特且高质量的图像几分钟后的文字描述,例如“一名宇航员骑马,照片逼真样式”,如图1所示。作为AIGC取得的显著成就,许多人相信它会成为人工智能的新时代,并对整个世界产生重大影响。
从技术上讲,AIGC是指给定指令,可以引导模型完成任务,利用GAI生成满足指令的内容。这个生成过程通常包括两个步骤:从指令中提取意图信息,并根据提取的意图生成内容。
然而,正如以前的研究所证明的那样,包含上述两个步骤的GAI模型的范式并非是完全新颖的。
与此前工作相比,最近AIGC进步的核心点是在更大的数据集上训练更复杂的生成模型,使用更大的基础模型框架,并且可以访问广泛的计算资源。
比如,GPT-3和GPT-2的主框架一样,但是预训练数据大小从 WebText (38GB) 增加到 CommonCrawl (过滤后为570GB) ,基础模型大小从1.5B 增加到 175B。
因此,GPT-3在各种任务上比GPT-2有更好的泛化能力。
除了数据量和计算能力增加所带来的好处之外,研究人员还在探索将新技术与GAI算法结合起来的方法。
比如,ChatGPT利用人类反馈的强化学习 (RLHF) 来确定给定指令的最适当响应,从而随着时间的推移提高模型的可靠性和准确性。这种方法使ChatGPT能够更好地理解长时间对话中的人类偏好。
同时,在CV中,Stability AI在2022年提出的Stable Diffusion在图像生成方面也取得了巨大的成功。
与以往的方法不同,生成扩散模型可以通过控制探索和开发之间的平衡来帮助生成高分辨率图像,从而在生成的图像中实现多样性,与训练数据相似性的和谐组合。
通过将这些进步结合起来,模型在AIGC的任务中取得了重大进展,并已被艺术、广告和教育等各行各业采用。
在不久的将来,AIGC将继续成为机器学习研究的重要领域。
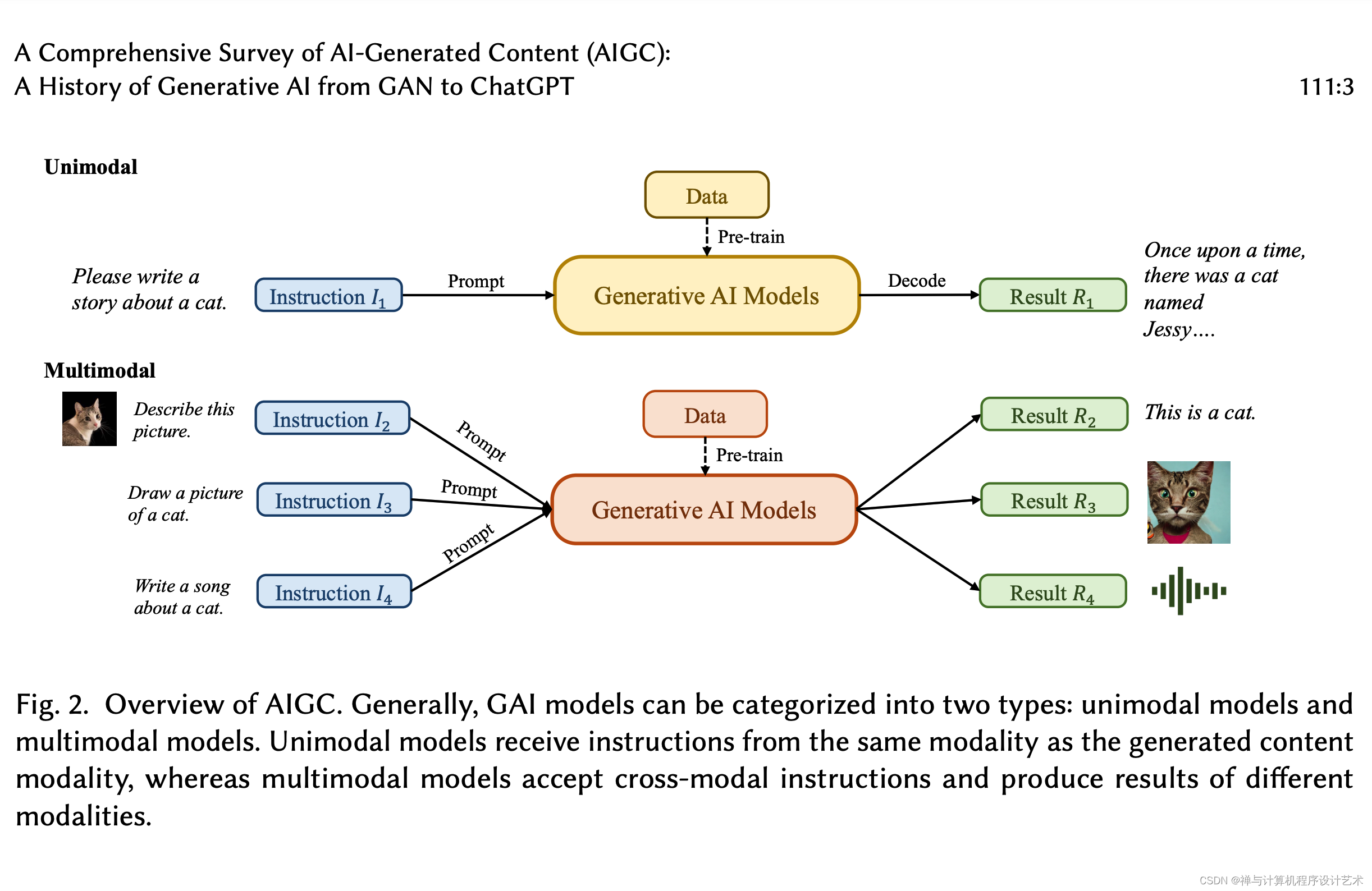
一般来说,GAI模型可以分为两种类型: 单模态模型和多模态模型.
因此,对过去的研究进行一次全面的回顾,并找出这个领域存在的问题是至关重要的。这是首份关注AIGC领域的核心技术和应用的调查。
这是AIGC第一次在技术和应用方面总结GAI的全面调查。
以前的调查主要从GAI不同角度介绍,包括自然语言生成 ,图像生成,多模态机器学习生成。然而,这些先前的工作只关注AIGC的特定部分。
在这次调查中,最先回顾了AIGC常用的基础技术。然后,进一步提供了先进GAI算法的全面总结,包括单峰生成和多峰生成。此外,论文还研究了 AIGC 的应用和潜在挑战。
最后强调了这个领域未来方向。总之,本文的主要贡献如下:
-据我们所知,我们是第一个为AIGC和AI增强的生成过程提供正式定义和全面调查。
-我们回顾了AIGC的历史、基础技术,并从单峰生成和多峰生成的角度对GAI任务和模型的最新进展进行了综合分析。
-本文讨论了AIGC面临的主要挑战和未来的研究趋势。
生成式AI历史
生成模型在人工智能中有着悠久的历史,最早可以追溯到20世纪50年代隐马尔可夫模型 (HMMs) 和高斯混合模型(GMMs)的发展。
这些模型生成了连续的数据,如语音和时间序列。然而,直到深度学习的出现,生成模型的性能才有了显著的提高。
在早期的深度生成模型中,不同的领域通常没有太多的重叠。
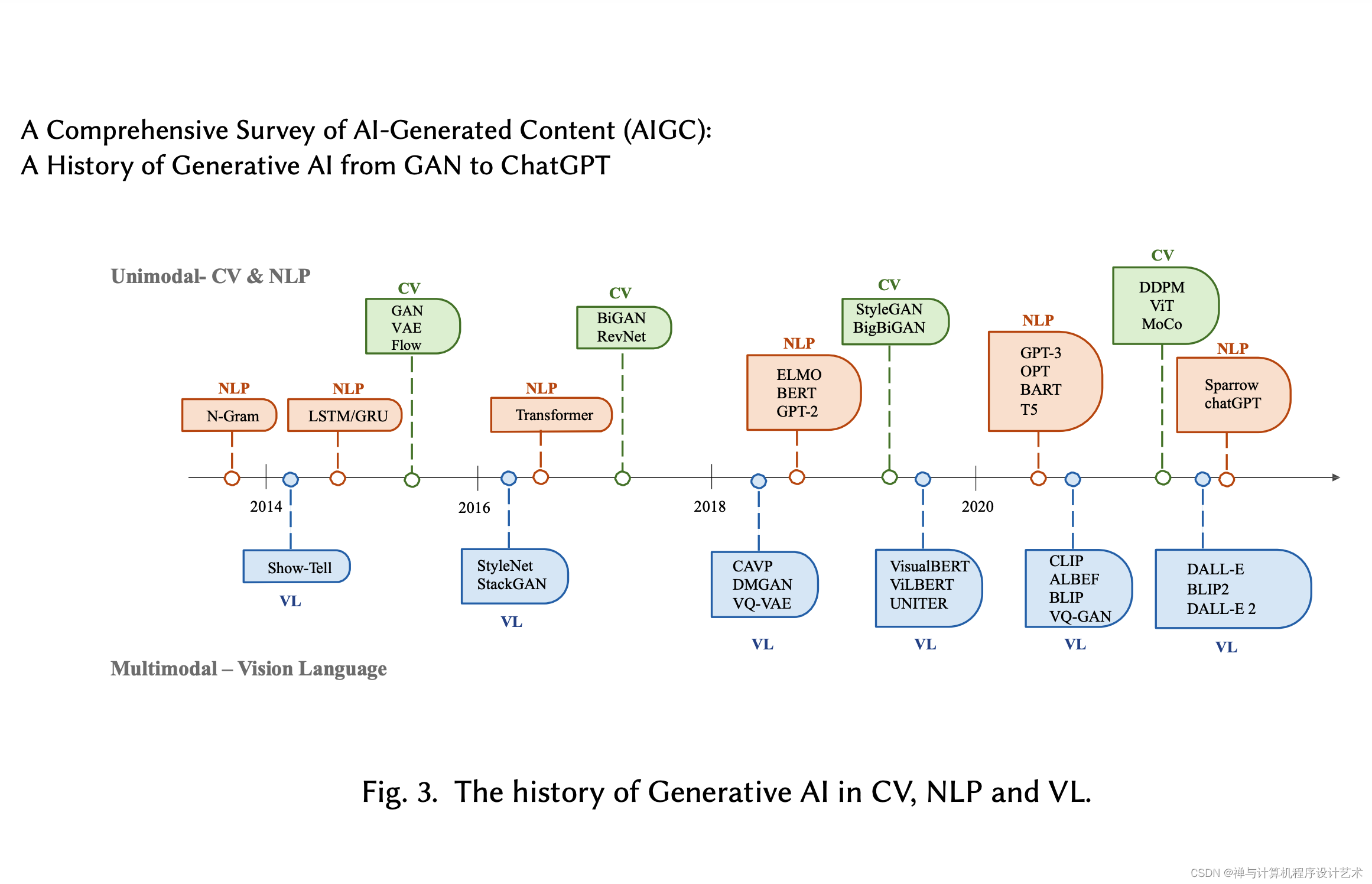
生成AI在 CV、NLP和VL中的发展史
在NLP中,生成句子的传统方法是使用N-gram语言模型学习词的分布,然后搜索最佳序列。然而,这种方法不能有效适应长句子。
为了解决这个问题,递归神经网络(RNNs)后来被引入到语言建模任务中,允许相对较长的依赖关系进行建模。
其次是长期短期记忆(LSTM)和门控递归单元(GRU)的发展,它们利用门控机制来在训练中控制记忆。这些方法能够在一个样本中处理大约200个标记(token),这与N-gram语言模型相比标志着显著的改善。
同时,在CV中,在基于深度学习方法出现之前,传统的图像生成算法使用了纹理合成(PTS)和纹理映射等技术。
这些算法基于手工设计的特征,并且在生成复杂多样图像的方面能力有限。
2014年,生成对抗网络(GANs)首次被提出,因其在各种应用中取得了令人印象深刻的结果,成为人工智能领域的里程碑。
变异自动编码器(VAEs)和其他方法,如生成扩散模型,也被开发出来,以便对图像生成过程进行更细粒度的控制,并能够生成高质量的图像。
生成模型在不同领域的发展遵循着不同的路径,但最终出现了交集: Transformer架构。
2017年,由 Vaswani 等人在NLP任务中引入Transformer,后来应用于CV,然后成为各领域中许多生成模型的主导架构。
在NLP领域,许多著名的大型语言模型,如BERT和GPT,都采用Transformer架构作为其主要构建模块。与之前的构建模块,即LSTM和GRU相比,具有优势。
在CV中,Vision Transformer (ViT) 和 Swin Transformer后来进一步发展了这一概念,将Transformer体系结构与视觉组件相结合,使其能够应用于基于图像的下行系统。
除了Transformer给单个模态带来的改进外,这种交叉也使来自不同领域的模型能够融合在一起,执行多模态任务。
多模态模型的一个例子是CLIP。CLIP是一个联合的视觉语言模型。它将Transformer架构与视觉组件相结合,允许在大量文本和图像数据上进行训练。
由于在预训练中结合了视觉和语言知识,CLIP也可以在多模态提示生成中作为图像编码器使用。总之,基于Transformer模型的出现彻底改变了人工智能的生成,并导致了大规模训练的可能性。
近年来,研究人员也开始引入基于这些模型的新技术。
例如,在NLP中,为了帮助模型更好地理解任务需求,人们有时更倾向于少样本(few-shot)提示。它指的是在提示中包含从数据集中选择的一些示例。
在视觉语言中,研究人员将特定模式的模型与自监督对比学习目标的模式相结合,以提供更强大的表示。
未来,随着AIGC变得愈发重要,越来越多的技术将被引入,将赋予这一领域极大的生命力。
AIGC基础
本节中,介绍了AIGC常用的基础模型。
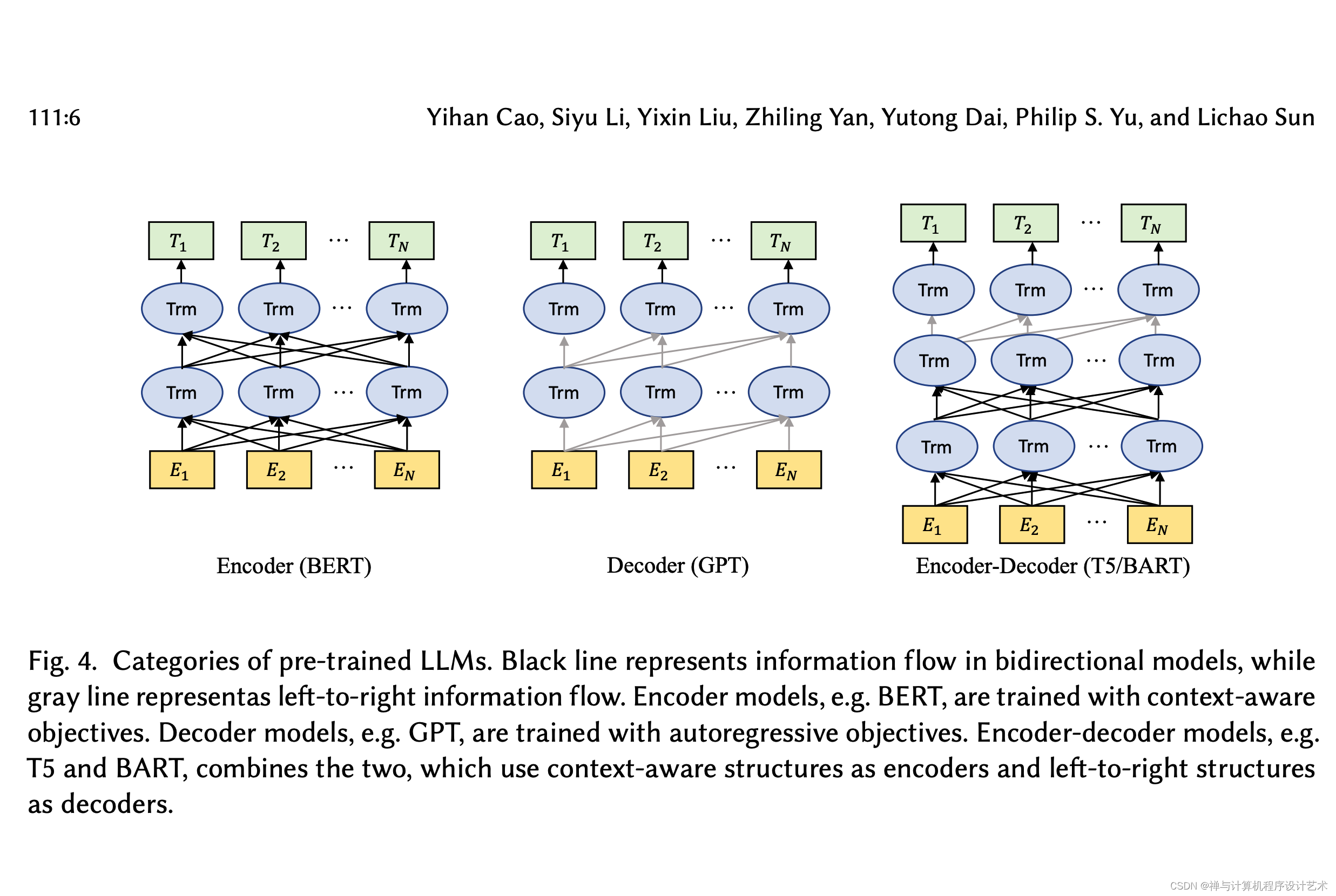
基础模型:Transformer
Transformer是许多最先进模型的骨干架构,如GPT-3、DALL-E-2、Codex和Gopher。
它最早是为了解决传统模型,如RNNs,在处理变长序列和上下文感知方面的局限性而提出的。
Transformer的架构主要是基于一种自注意力机制,使模型能够注意到输入序列中的不同部分。
Transformer由一个编码器和一个解码器组成。编码器接收输入序列并生成隐藏表示,而解码器接收隐藏表示并生成输出序列。
编码器和解码器的每一层都由一个多头注意力和一个前馈神经网络组成。多头注意力是Transformer的核心组件,学习根据标记的相关性分配不同的权重。
这种信息路由方法使该模型能够更好地处理长期的依赖关系,因此,在广泛的NLP任务中提高了性能。
Transformer的另一个优点是它的架构使其具有高度并行性,并允许数据战胜归纳偏置。这一特性使得Transformer非常适合大规模的预训练,使基于Transformer的模型能够适应不同的下游任务。
预训练语言模型
自从引入Transformer架构以来,由于其并行性和学习能力,让其成为自然语言处理的主流选择。
一般来说,这些基于Transformer的预训练语言模型可以根据其训练任务通常分为两类: 自回归语言模型,以及掩码语言模型。
给定一个由多个标记组成的句子,掩蔽语言建模的目标,例如BERT和RoBERTa,即预测给定上下文信息的掩蔽标记的概率。
掩码语言模型最显著的例子是BERT,它包括掩蔽语言建模和下句预测任务。RoBERTa使用与BERT相同的架构,通过增加预训练数据量,以及纳入更具挑战性的预训练目标来提高其性能。
XL-Net也是基于BERT的,它结合了排列操作来改变每次训练迭代的预测顺序,使模型能够学习更多跨标记的信息。
而自回归语言模型,如GPT-3和OPT,是对给定前一个标记的概率进行建模,因此是从左到右的语言模型。与掩码语言模型不同,自回归语言模型更适合生成式任务。
从人类反馈中强化学习
尽管经过大规模数据的训练,AIGC可能并不总是输出与用户意图一致的内容。
为了使 AIGC 输出更好地符合人类的偏好,从人类反馈中强化学习(RLHF)已应用于各种应用中的模型微调,如Sparrow、InstructGPT和ChatGPT。
通常情况下,RLHF的整个流程包括以下三个步骤: 预训练、奖励学习和强化学习的微调。
计算
硬件
近年来,硬件技术有了显著的进步,促进了大模型的训练。
在过去,使用 CPU训练一个大型神经网络可能需要几天甚至几周的时间。然而,随着算力的增强,这一过程已经被加速了几个数量级。
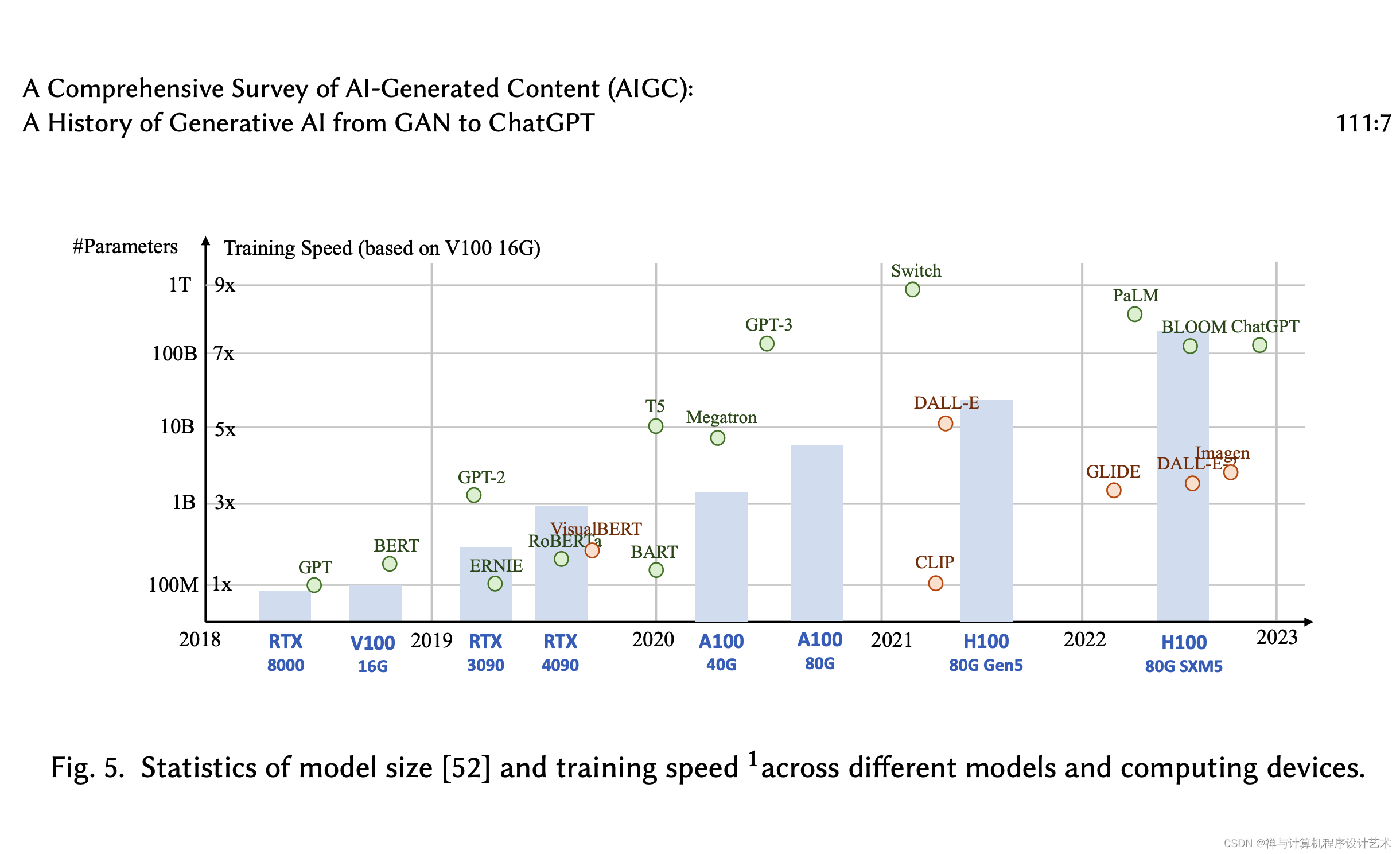
例如,英伟达的NVIDIA A100 GPU在BERT大型推理过程中比V100快7倍,比T4快11倍。
此外,谷歌的张量处理单元(TPU)专为深度学习设计的,与A100 GPU相比,提供了更高的计算性能。
计算能力的加速进步显著提高了人工智能模型训练的效率,为开发大型复杂模型提供了新的可能性。
分布式训练
另一个重大的改进是分布式训练。
在传统机器学习中,训练通常是在一台机器上使用单个处理器进行的。这种方法可以很好地应用于小型数据集和模型,但是在处理大数据集和复杂模型时就变得不切实际。
在分布式训练中,训练的任务被分散到多个处理器或机器上,使模型的训练速度大大提升。
一些公司也发布了框架,简化了深度学习堆栈的分布式训练过程。这些框架提供了工具和API,使开发者能够轻松地将训练任务分布在多个处理器或机器上,而不必管理底层基础设施。
云端运算
云计算在训练大模型方面也发挥了至关重要的作用。以前,模型经常在本地进行训练。现在,随着AWS和Azure等云计算服务提供了对强大计算资源的访问,深度学习研究人员和从业人员可以根据需要创建大模型训练所需的大型GPU或TPU集群。
总的来说,这些进步使得开发更复杂、更精确的模型成为可能,在人工智能研究和应用的各个领域开启了新的可能性。
作者介绍
俞士纶(Philip S. Yu)是计算机领域学者,是ACM/IEEE Fellow,在伊利诺大学芝加哥分校(UIC)计算机科学系任特聘教授。
他在大数据挖掘与管理的理论、技术方面取得了举世瞩目的成就。他针对大数据在规模、速度和多样性上的挑战,在数据挖掘、管理的方法和技术上提出了有效的前沿的解决方案,尤其在融合多样化数据、挖掘数据流、频繁模式、子空间和图方面做出了突破性的贡献。

他还在并行和分布式数据库处理技术领域做出了开创性贡献,并应用于IBM S/390 Parallel Sysplex系统,成功将传统IBM大型机转型为并行微处理器架构。
参考资料
https://arxiv.org/pdf/2303.04226.pdf