文章目录
Q: 作者您好,感谢您的分享! Then the learning target for σ(pss) is 1 if it
corresponds to the positive sample of an instance; otherwise negative
labels. 我对于pss head不太理解,想请教您下
关于论文中的这句话,指的是对于一个instance只有一个pixel表示的最优正样本会被置 为1,还是和原始fcos一样,所有的正样本的pixel都被置为1?A: 最优正样本的target是1,set loss还是用focal loss。
Q: 作者我还想请教下, 是不是在计算match cost的时候,
得分值Q_ij中的classification的pss还是所有的正样本(如果是FCOS ,根 据的是center
sampling中的所有pixels)? 而在计算loss的时候,是已经通过二分图匹配算法得到了最优的正样本,因此Total Loss中的PSS
Loss只算N个instances和N个 最优正样本的focal loss?A: 是的
Q: 感谢您的回复,作者我对于Rank Loss还是有点疑惑,还想问下您,请问rankloss中的“positive and
negative anchors”,指的是不是挑选最优正样本后作为postive,其余的原先的“正样本”作为了negative? 不然感觉 P ^ i − ( c i − ) \hat P_{i-}(c_{i-}) P^i−(ci−)表示负样本 i − i_- i−属于类别 C i − C_{i-} Ci−的分类得分。这个没有意义?
A: 是PSS过滤后的。
1. Motivation
-
在原有detectors的基础上,去除NMS,实现端到端的网络。
-
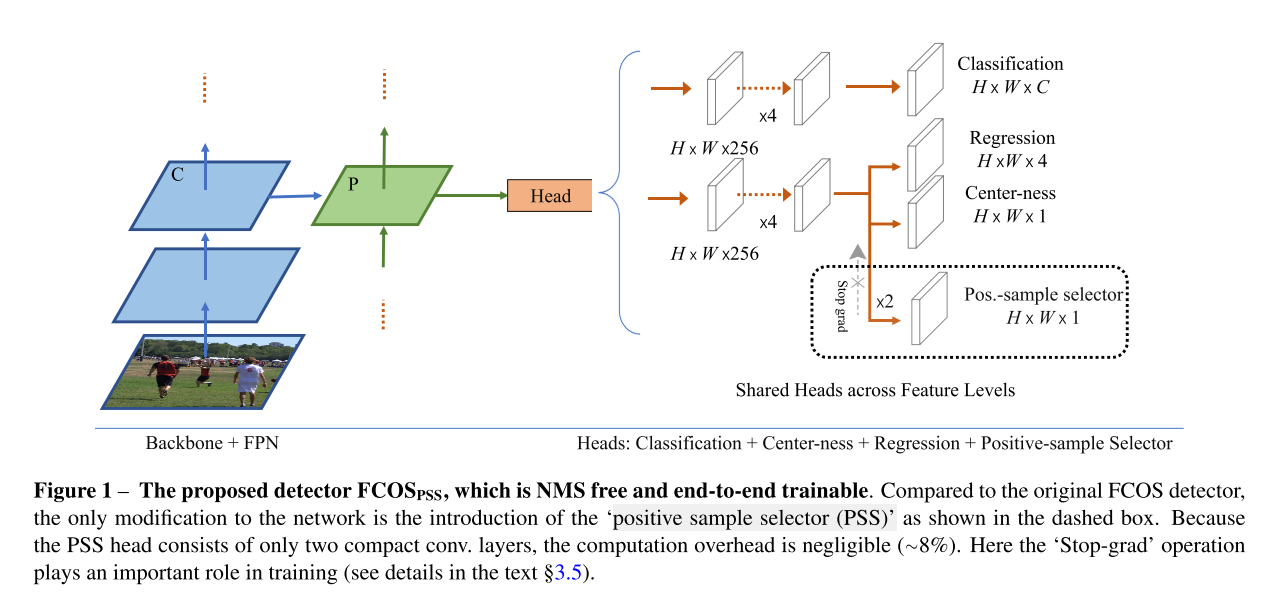
作者在原有FCOS网络结构的基础上,加入了一个positve sample selector(PSS)分支,用于对每一个object instance挑选一个正样本。
-
由于one-to-one和one-to-many的label assignment之间存在矛盾,作者提出了一个stop-grad方法,来阻止PSS head的反传到原始FCOS网络参数的梯度。
Concretely, in this work wewant to design a simple high-performance fully convolutional network for object detection, which is NMS free and fully end-to-end trainable.
2. Contribution
作者所提出的detector,命名为 F C O S P S S FCOS_{PSS} FCOSPSS,不依靠attention以及3D max filtering,具有以下优点:
- F C O S P S S FCOS_{PSS} FCOSPSS在FCOS的基础之上进行改进,更simpler地去除了NMS,比较和其他的FCN-solvable任务兼容。
- 引入了一个PSS head去除NMS,并且相对于vanilla FCOS, F C O S P S S FCOS_{PSS} FCOSPSS的计算开支是negligible的。
- 实质上,PSS head可作为可学习的NMS。通过设计,使香草FCOS探头和原始检测器保持正常工作,所以FCOS PSS在使用NMS方面具有灵活性。
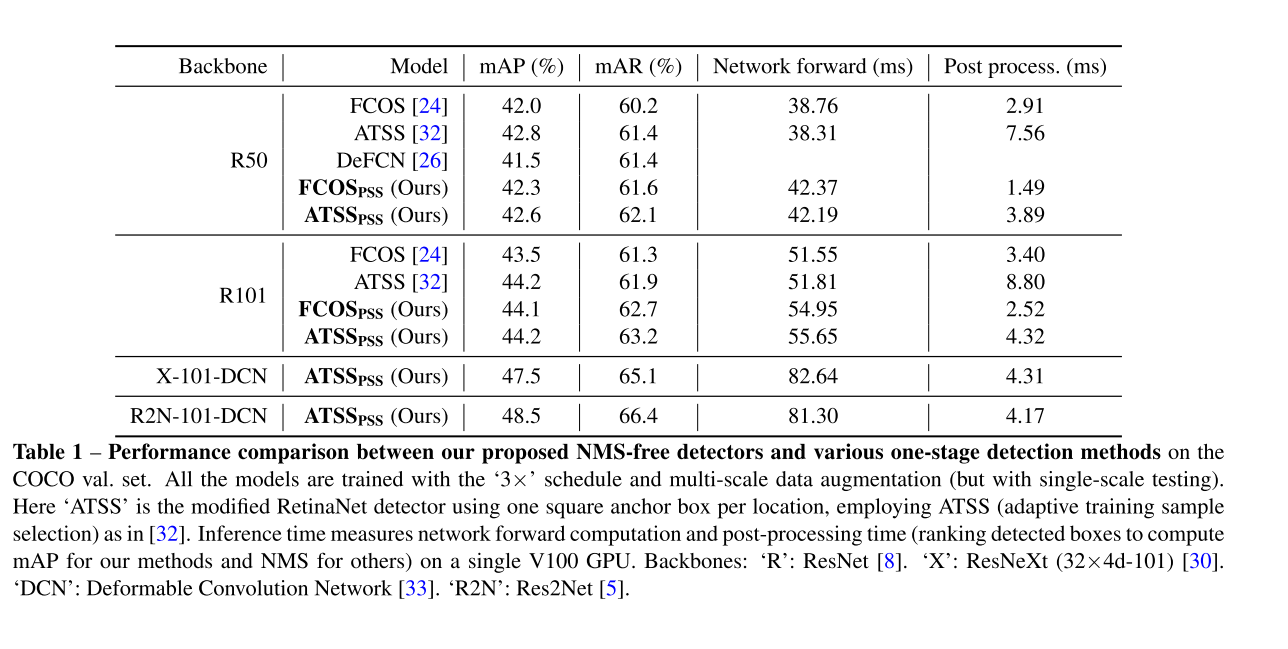
- 在COCO数据集上,与FCOS以及ATSS相比,精度都有改善。
- PSS head同样适用于其他anchor-box detectors,例如RetinaNet。
- 这个idea可以应用于实例分割领域中。
3. Our Method
3.1 Overall Training Objective
总体的损失函数制定为:
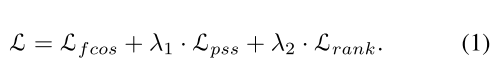
3.1.1 PSS LOSS
L p s s L_{pss} Lpss是整个网络的核心所在,将分类损失和正样本选择联系在了一起。PSS head就是用来实现对于每一个实例,挑选一个并且只挑选一个正样本。如图1所示,PSS head输出的特征图为 R H × W × 1 R^{H \times W \times 1} RH×W×1,定义 σ ( p s s ) \sigma(pss) σ(pss)为特征图上的一个pixel的值,那么当pixel是一个实例的最优正样本, σ ( p s s ) \sigma(pss) σ(pss)的target的值为1(target也就是gt先验的含义),否则就为负样本,负样本的target值为0。
最后 σ ( p s s ) 、 \sigma(pss)、 σ(pss)、 σ ( s ) \sigma(s) σ(s)以及 σ ( c t r ) \sigma(ctr) σ(ctr)会和gt计算一下focal loss。
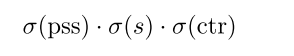
3.1.2 Ranking Loss
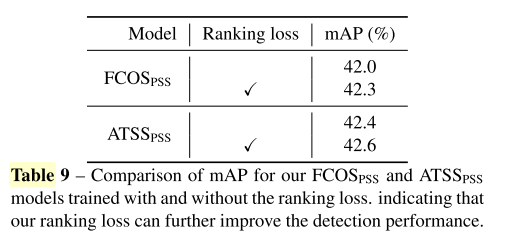
通过实验,作者发现加入了ranking loss可以提高精度。Ranking Loss的公式如2所示:
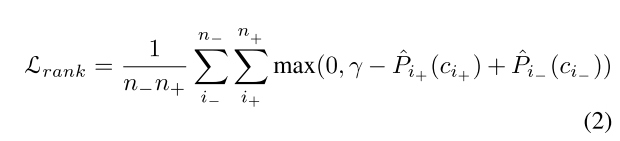
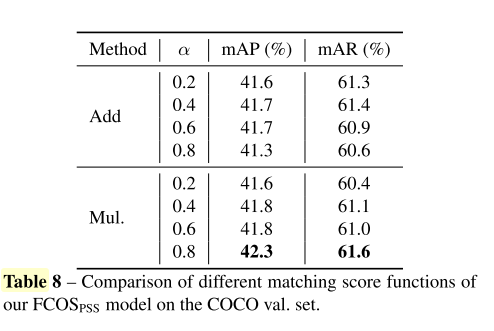
其中 γ \gamma γ表示正anchors与负anchors之间的margin。在实验中,默认使用0.5. n − n- n−和 n + n+ n+表示正样本和负样本的个数。实验中,作者选取了 n − = 100 n- = 100 n−=100。 P ^ i + ( c i + ) \hat P_{i+}(c_{i+}) P^i+(ci+)表示正样本 i + i_+ i+属于类别 C i + C_{i+} Ci+的分类得分值。 P ^ i − ( c i − ) \hat P_{i-}(c_{i-}) P^i−(ci−)表示负样本 i − i_- i−属于类别 C i − C_{i-} Ci−的分类得分值。
3.2 One-to-many Label Assignment
作者认为这种对于一个one-to-many的优点在于,这种丰富的表示形式可以改善对特定的比例,translation等不变性进行编码的强分类器的学习。
The advantage of having multiple boxes for one instance is that such a rich representation improves learning of a strong classifier that encodes invariances of aspect ratios, translations, etc.
作者认为NMS就变得非常有indispensable。虽然是记法式的NMS后处理方法,但是作者认为这种one-to-many的label assignment有它自己的重要性。其一在于丰富的训练数据可以帮助学习一些证明是有效的不变性;其二,这也与几乎所有深度学习技术中当前数据扩增的实际做法一致。
①richer training data help learning of some helpful invariances that are proven beneficial.
②it is also consistent with the de facto practice of current data aug- mentation in almost all deep learning techniques.
因此,作者认为保持FCOS 训练的one-to-many的label assignment方法作为新得检测器的一个重要成分是很重要的。
3.3 One-to-one Label Assignment
与DeFCN类似,作者制定的matching score Q如公式3所示,由positiveness prior,classification,localization3个部分组成。其中,有2点不同。首先,对于分类match来说,加入了pss分支,由公式4所示。公式4中的 p s s i pss_i pssi就是PSS分支输出的binary mask预测的scores。 σ ( . ) ∈ [ 0 , 1 ] \sigma(.) \in [0,1] σ(.)∈[0,1]是sigmoid函数。用于将scores归一化为概率值P。其次,是将DeFCN中的center sampling中心采样改成了
原始FCOS/ATSS的positiveness prior。

最后,每一个gt instance j使用匈牙利算法进行二分图匹配来制定一个label,最大化Q的得分,从而为每一个instance j找到最优的anchor的索引i。
We have observed similar performance if using the simple top-one selection to replace the Hungarian matching.
3.4 Conflict in the Tow Classification Loss Terms
在FCOSpss中,vanilla FCOS的分类loss是one-to-many的,而 L p s s L_{pss} Lpss 是只选择了一个正样本。因此对于为了训练PSS 分支,vanilla FCOS中的K-1个正样本会在PSS分支中被置为负样本。通过我们的PSS head仅选出了一个最优的正样本,也就是需要把其余K-1个样本置为负样本,one-to-many的分类loss和one-to-one的分类loss是存在优化矛盾的,多个样本可能同时被当作正样本和负样本,这使得模型难以训练,产生优化冲突。
In other words, a few samples are assigned as positive samples and negative samples at the same time when train- ing the model.
这个为了解决这个问题,作者引入 stop-grad,新的PSS head对于原始的FCOS检测分支产生较小的影响(但不是not zero impact)。
原因是因为FCOS的分类分类和 L p s s L_{pss} Lpss关联。
But not zero impact because Lpss is coupled with the FCOS classi- fier in Lfcos.
3.5 Stop Gradient
在实验中,当SGD更新了vanilla FCOS权重参数的时候,PSS head被置为常数,因此来自PSS的0梯度被回传会剩余的网络中。
将 θ = { θ f c o s , θ p s s } \theta = \{\theta_{fcos}, \theta_{pss} \} θ={ θfcos,θpss}作为整个网络需要优化的参数,可以分为2个部分,stop gradient与对2部分的权重参数alternating optimization很相似,网络需要解决:
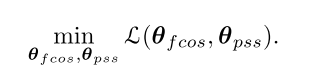
因此作者将stop gradient近似认为是将权重参数 θ = { θ f c o s , θ p s s } \theta = \{\theta_{fcos}, \theta_{pss} \} θ={ θfcos,θpss}交替优化,而不需要解决2个优化的子问题。如公式5和6所示:

交替优化和只训练原始FCOS分支直到收敛,然后冻结FCOS,接着在训练PSS head直到收敛。但作者在实验中发现这个方法会导致检测性能变差,并且训练的计算时间更长。
4. Experiments
4.1 Albation Experiments
4.1 Effect of Stop Gradient
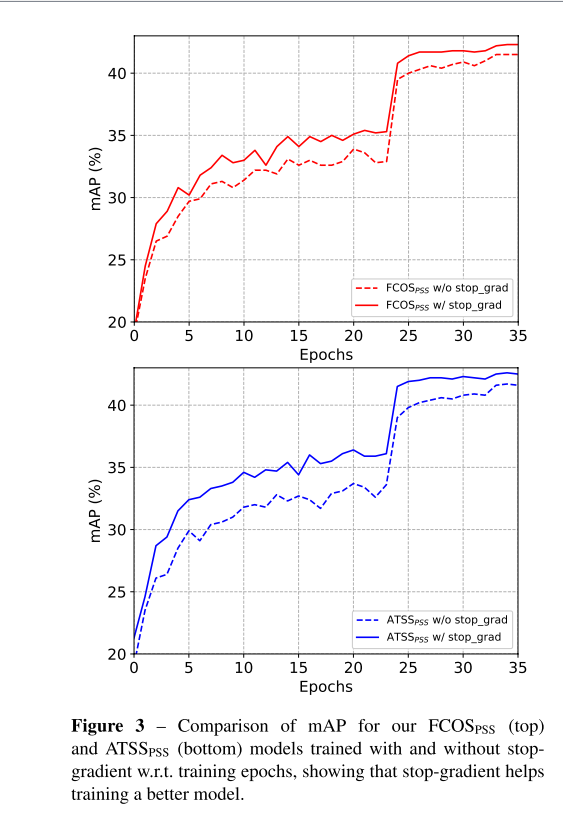
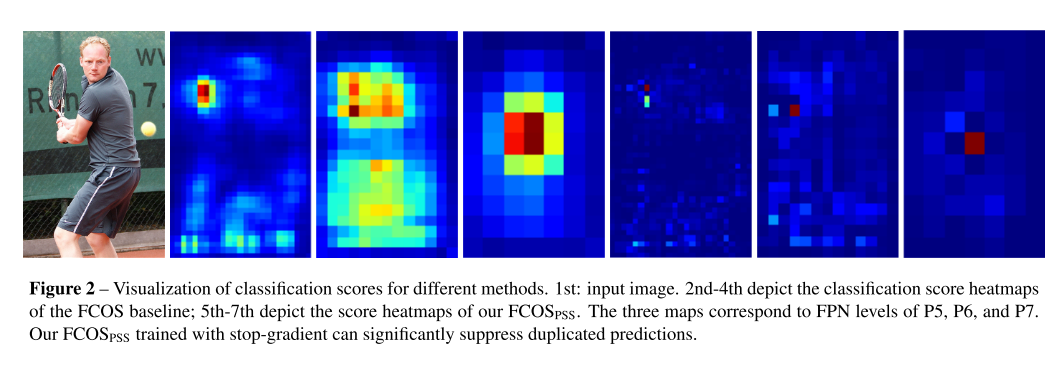
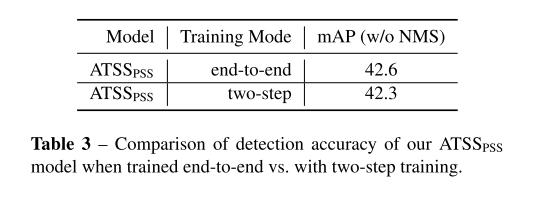
4.1.1 Stop Gradient vs.Two-step Training
这一部分探究将分开训练2个分支还是直接使用stop-gradient进行端到端的训练。
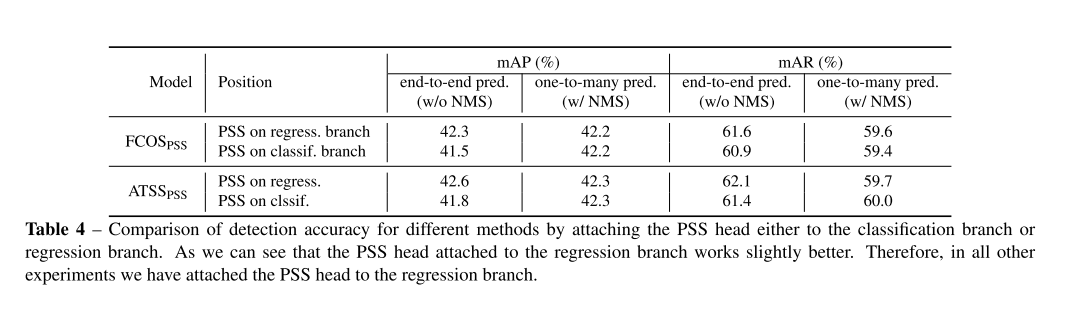
4.1.2 Attaching PSS to Regression vs. Classification Branch
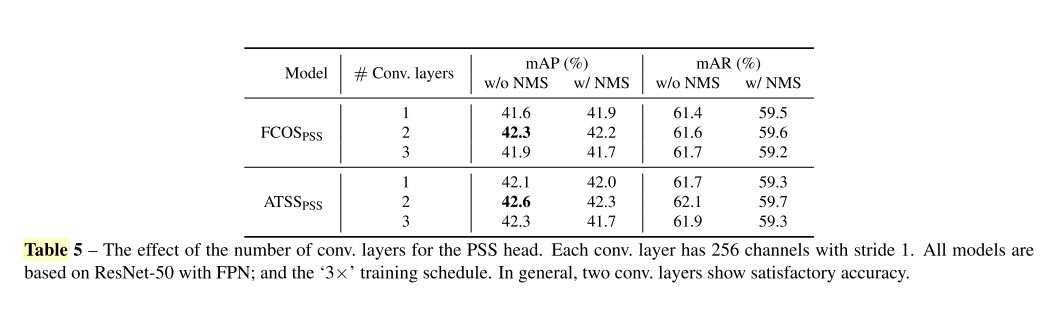
4.1.3 How Many Conv. Layers for the PSS Head Since
4.1.4 Effect of the Center-ness Branch

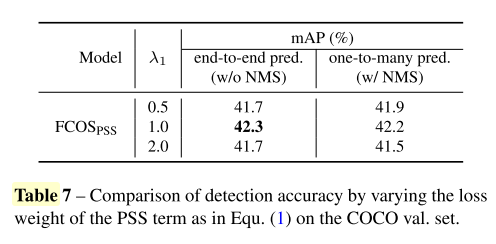
4.1.5 Loss Weight of PSS Loss Lpss
4.1.6 Matching Score Function
4.1.7 Effect of the Ranking Loss
4.2 Comparsion with State-of-the-art