大数据:共享变量
2022找工作是学历、能力和运气的超强结合体,遇到寒冬,大厂不招人,可能很多算法学生都得去找开发,测开
测开的话,你就得学数据库,sql,oracle,尤其sql要学,当然,像很多金融企业、安全机构啥的,他们必须要用oracle数据库
这oracle比sql安全,强大多了,所以你需要学习,最重要的,你要是考网络警察公务员,这玩意你不会就别去报名了,耽误时间!
与此同时,既然要考网警之数据分析应用岗,那必然要考数据挖掘基础知识,今天开始咱们就对数据挖掘方面的东西好生讲讲 最最最重要的就是大数据,什么行测和面试都是小问题,最难最最重要的就是大数据技术相关的知识笔试
文章目录
文章目录
大数据:广播变量

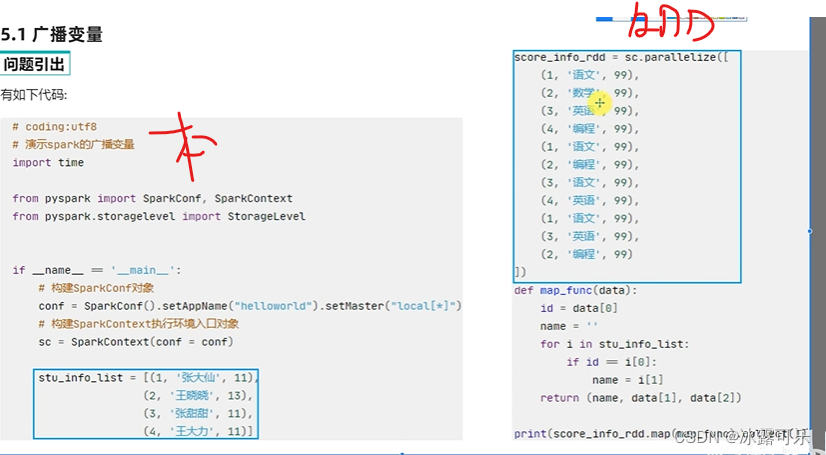
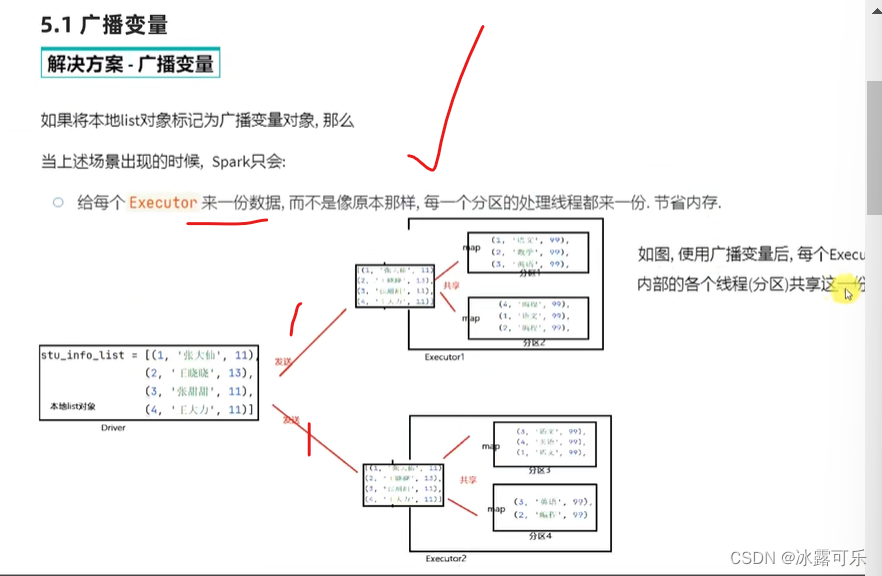
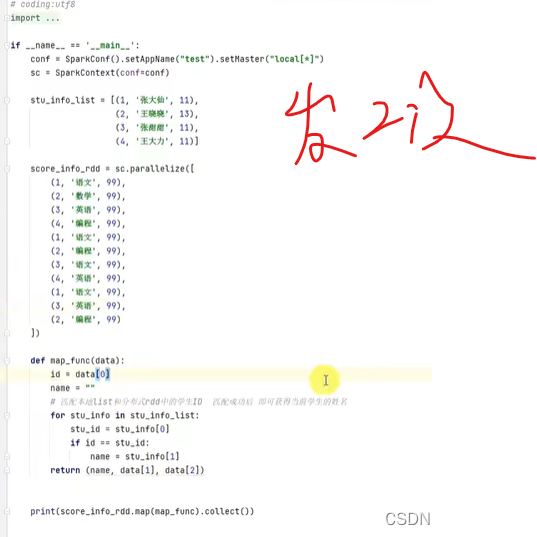
把RDD中的id替换为左边的姓名
spark右边是RDD,分布式的
左边是本地python的list
左边是driver在负责,右边是executor在执行
通过函数处理
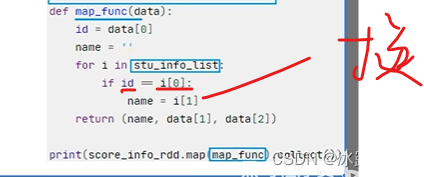
返回姓名和数据
map算子来自RDD
分布式运行在executor
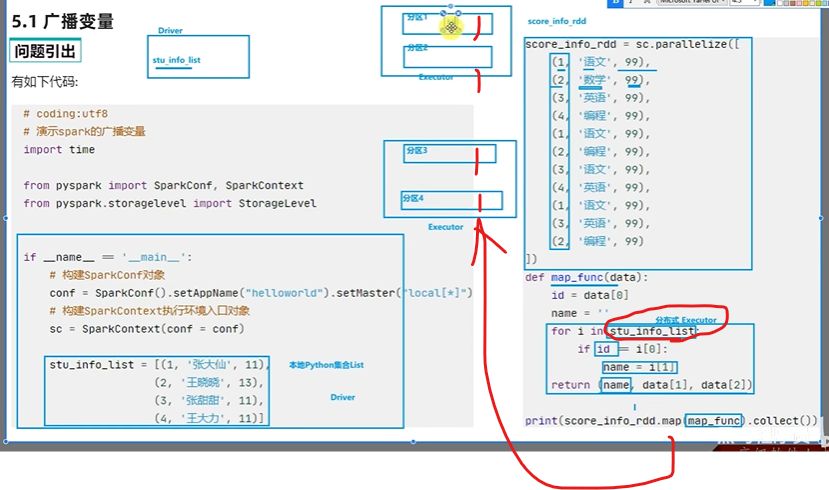
分区执行map,需要网络传输本地的stu_info_list
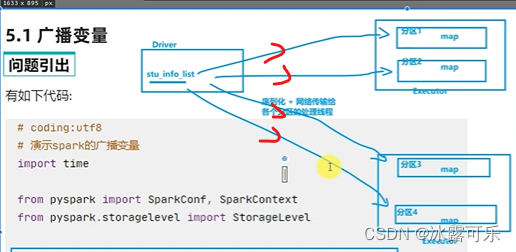
executor是进程
进程之内内存空间是各个线程共享的
所以executor你有必要发2份吗?
不
只需要发一份即可
解决这个问题,需要广播变量技术

如果给你spark标记哦一下,stu这个信息是广播变量
如果分区1发了,OK
你分区2再要,不给了,让你去分区1要去,去共享,懂吗?
我不发了!!
如果分区3发了,OK
你分区4再要,不给了,让你去分区3要去,去共享,懂吗?
我不发了!!
这就是少发送,你们一个整体,我只法一次,你们共享即可
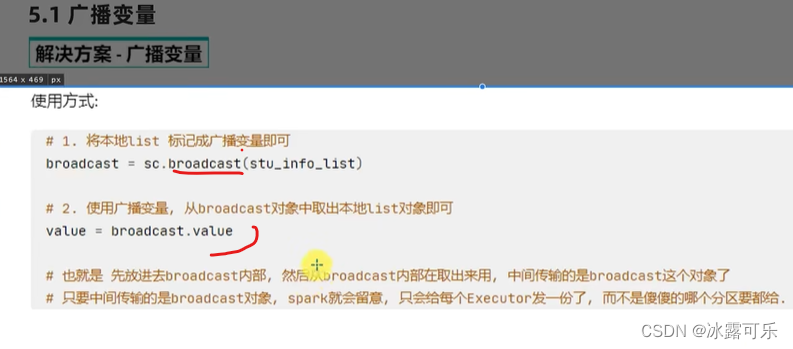
类型就是广播变量
标记广播变量
然后value使用即可
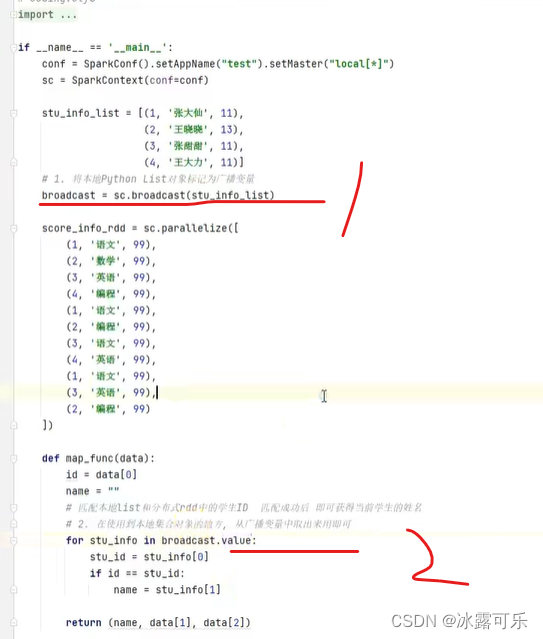
这样的话,内存不会浪费哦
妹子最
适用对象:
本地集合对象和RDD对象关联的时候,就可以将本地集合对象封装为广播变量,这样RDD使用分布式传输就能节约内存空间
那为啥不把本地集合变RDD?
不,我们避免shuffle耗费太多性能
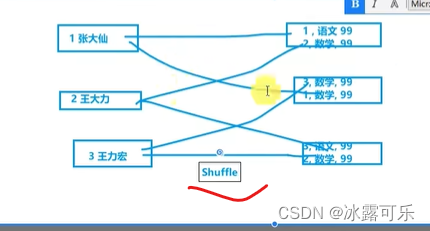 shuffle是最耗费性能的
shuffle是最耗费性能的
本地集合如果转RDD, 那就要费劲到处传输
但是如果封装为广播变量,就只需要交互一次
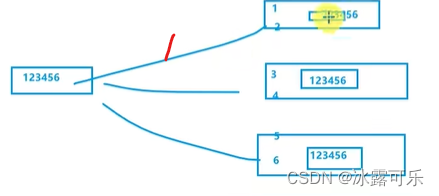


各自处理5个
最终的累加咋是0?
非RDD代码,都是driver执行的
RDD是executor执行的
需要用的时候,发送count
你打印最后的count是内存指针那原来driver的值
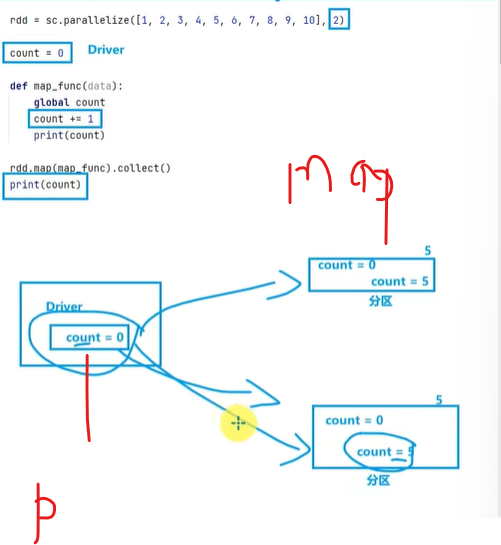
普通的写法,再分布式计算过程中,难搞
那我们设定全局累加器变量
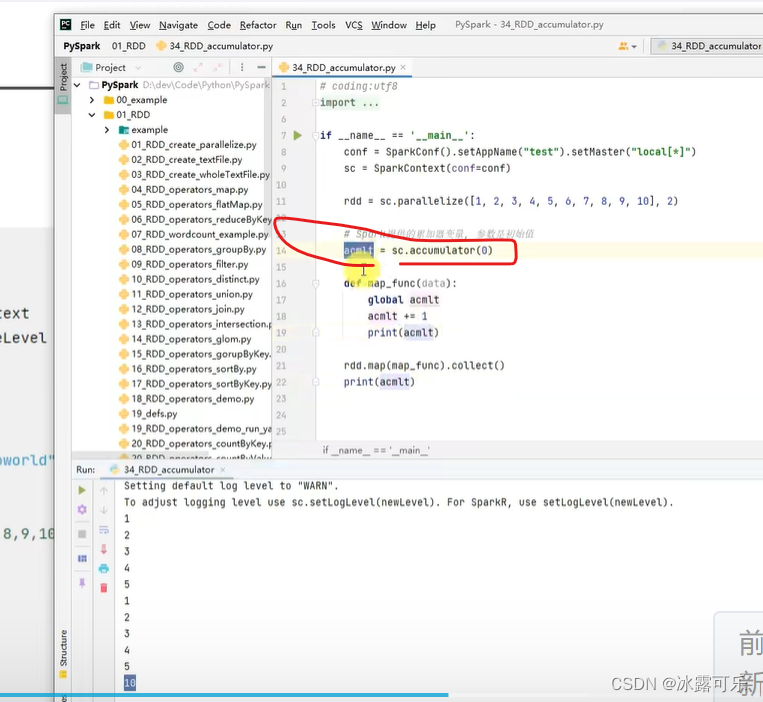
累加器定义类型,封装一下,它就会双边叠加
美滋滋
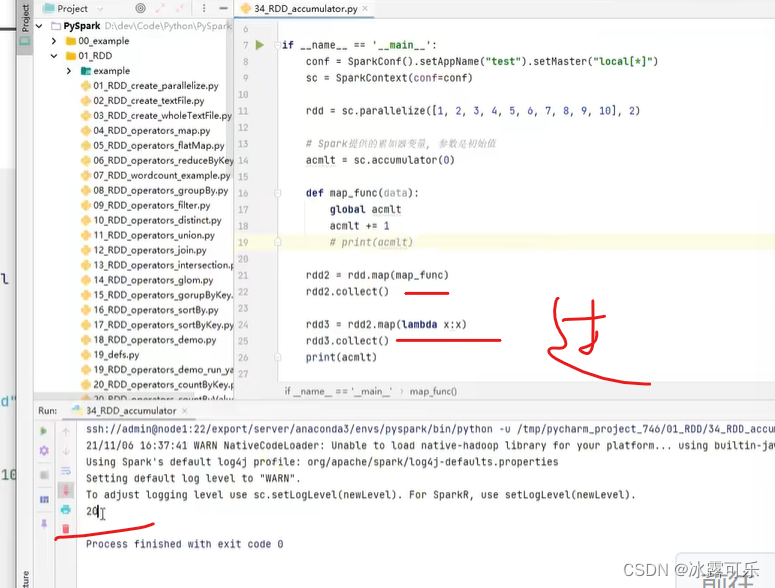
我们说过,rdd是一个过程数据
后面再次调用rdd2时,还需要再去执行一次,重新构建
这就是rdd过程数据的本质引发的
懂了吗
20次
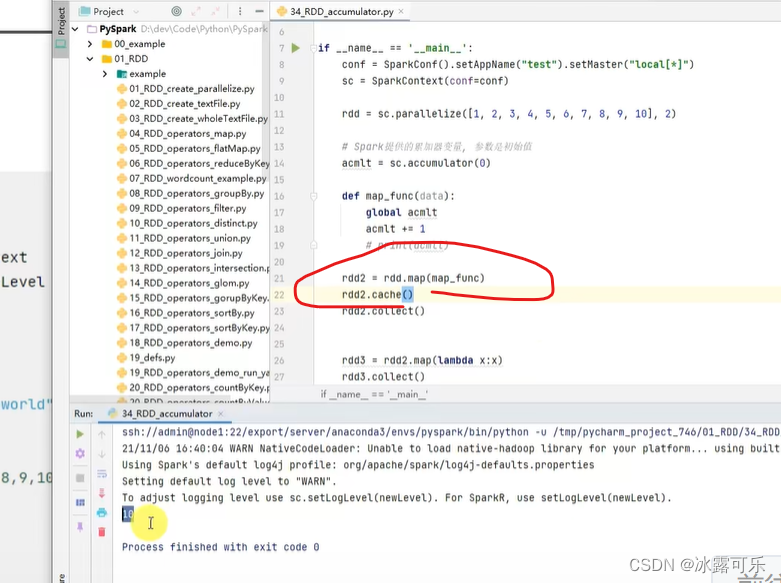
用累加器要小心
要缓存,才不会累加异常哦

总结
提示:重要经验:
1)
2)学好oracle,即使经济寒冬,整个测开offer绝对不是问题!同时也是你考公网络警察的必经之路。
3)笔试求AC,可以不考虑空间复杂度,但是面试既要考虑时间复杂度最优,也要考虑空间复杂度最优。