广播变量理解图
广播变量(broadcast variables):
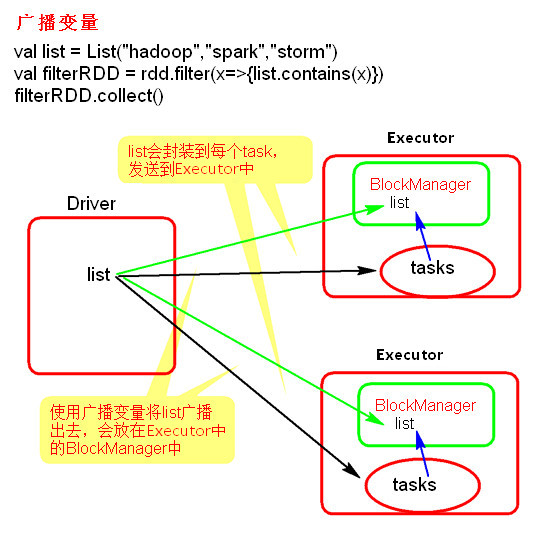
允许程序开发人员在每个机器上缓存一个只读的变量,而不是为机器上的每个任务都生成一个副本。通过这种方式,就可以非常高效地给每个节点(机器)提供一个大的输入数据集的副本。Spark的“动作”操作会跨越多个阶段(stage),对于每个阶段内的所有任务所需要的公共数据,Spark都会自动进行广播。通过广播方式进行传播的变量,会经过序列化,然后在被任务使用时再进行反序列化。这就意味着,显式地创建广播变量只有在下面的情形中是有用的:当跨越多个阶段的那些任务需要相同的数据,或者当以反序列化方式对数据进行缓存是非常重要的。
val conf =new SparkConf()
conf.setMaster("local").setAppName("brocast")
val sc =new SparkContext(conf)
val list =List("hello xasxt")
val broadCast = sc.broadcast(list)
val lineRDD =sc.textFile("./words.txt")
lineRDD.filter {x =>broadCast.value.contains(x) }.foreach {println}
sc.stop()
可以通过调用SparkContext.broadcast(v)来从一个普通变量v中创建一个广播变量。这个广播变量就是对普通变量v的一个包装器,通过调用value方法就可以获得这个广播变量的值,
这个广播变量被创建以后,那么在集群中的任何函数中,都应该使用广播变量broadcastVar的值,而不是使用v的值,这样就不会把v重复分发到这些节点上。此外,一旦广播变量创建后,普通变量v的值就不能再发生修改,从而确保所有节点都获得这个广播变量的相同的值。
注意事项
能不能将一个RDD使用广播变量广播出去?
不能,因为RDD是不存储数据的。可以将RDD的结果广播出去。
广播变量只能在Driver端定义,不能在Executor端定义。
在Driver端可以修改广播变量的值,在Executor端无法修改广播变量的值。
累加器

累加器是仅仅被相关操作累加的变量,通常可以被用来实现计数器(counter)和求和(sum)。Spark原生地支持数值型(numeric)的累加器,程序开发人员可以编写对新类型的支持。如果创建累加器时指定了名字,则可以在Spark UI界面看到,这有利于理解每个执行阶段的进程。
一个数值型的累加器,可以通过调用SparkContext.longAccumulator()或者SparkContext.doubleAccumulator()来创建。运行在集群中的任务,就可以使用add方法来把数值累加到累加器上,但是,这些任务只能做累加操作,不能读取累加器的值,只有任务控制节点(Driver Program)可以使用value方法来读取累加器的值。
val conf =new SparkConf()
conf.setMaster("local").setAppName("accumulator")
val sc =new SparkContext(conf)
val accumulator =sc.accumulator(0)
sc.textFile("./words.txt").foreach {x =>{accumulator.add(1)}}
println(accumulator.value)
sc.stop()
注意事项
累加器在Driver端定义赋初始值,累加器只能在Driver端读取,在Excutor端更新。