点击蓝字
关注我们,让开发变得更有趣
作者 | 杨亦诚
排版 | 李擎

OpenVINO™..♩~ ♫. ♪..
LangChain简介
LangChain 是一个高层级的开源的框架,从字面意义理解,LangChain 可以被用来构建 “语言处理任务的链条”,它可以让AI开发人员把大型语言模型(LLM)的能力和外部数据结合起来,从而去完成一些更复杂的任务。简单来说,LangChain 可以让你的 LLM 在回答问题时参考自定义的知识库,实现更精确的答案输出。例如在以下这个Retrieval Augmented Generation (RAG)任务,LangChain 可以根据问题从已有的知识库中进行检索,并将原始的检索结果和问题一并包装为Prompt提示送入 LLM 中,以此获得更加贴近问题需求的答案。
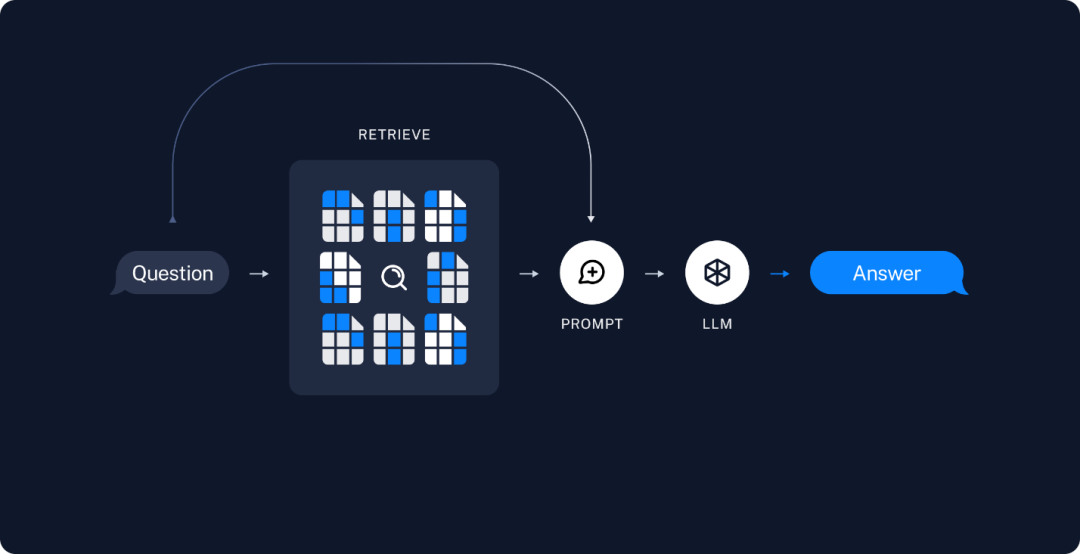
图:RAG任务示例
LangChain 的核心能力主要由以下几个模型所构成。
提示(prompts): 包括提示管理、提示优化和提示序列化。
大语言模型(LLM): 提供调用大预言模型生成文本的接口。
检索(Retrieval): 该模块用于构建自定义的知识仓库,从而基于LLM实现基于文档数据检测的文本生成任务(RAG),这也是LangChain最核心的能力之一。
代理(agents): LLM作为代理其他工具的代理,通过LLM来判断可以调用什么工具(tool)来解决用户提出的特殊需求。此处的工具需要被封装成API接口,供LangChain调用,比如一个返回文本长度的函数,就可以是一个工具。
记忆(memory): 记忆主要用来存储多轮对话中的历史数据,以便在后续的回答任务中可以对之前的交流记录进行参考。
基于以上这些模块,LangChain可以被应用于一些更复杂的任务中,例如:个人AI邮件助手,AI学习伙伴,AI数据分析,定制公司客服聊天机器人,社交媒体内容创作助手等,做为LangChain任务部署过程中的底座,LLM的推理任务势必是重点可以被优化的方向,那如何利用OpenVINO™来加速LangChain的中LLM任务呢,这里为大家整理了以下两个方法:
方法一:利用 Huggingface pipeline
调用 Optimum 后端
鉴于langchain.llm对象已经支持了huggingface_pipeline来直接调用huggingface上的LLM
(https://python.langchain.com/docs/integrations/llms/huggingface_pipelines),同时Huggingface的Optimum-intel组件可以将huggingface pipeline中的LLM推理任务通过OpenVINO™进行加速。因此我们的第一种方案就是利用Optimum-intel的pipeline来替换原本的Transformers pipeline,如下代码所示:
from langchain.llms import HuggingFacePipeline
from transformers import pipeline
- from transformers import AutoModelForCausalLM
+ from optimum.intel.openvino import OVModelForCausalLM
- model = AutoModelForCausalLM.from_pretrained(model_id)
+ ov_model = OVModelForCausalLM.from_pretrained(model_id)
pipe = pipeline("text-generation", model=ov_model, tokenizer=tokenizer, max_new_tokens=128, pad_token_id=tokenizer.eos_token_id)
hf = HuggingFacePipeline(pipeline=pipe)
llm_chain = LLMChain(prompt=prompt, llm= hf)
output = llm_chain.run(question)红色部分是标准 Transformers (第3、5行) 库在 huggingface_pipeline 中的调用方式,绿色部分为Optimum-intel (第4、6行)的调用方式,可以看到我们仅仅只需修改两行代码就可以把 LangChain 原生的 LLM 任务,通过 OpenVIN™ 进行加速,并且 Optimum-intel 提供的 API 也支持将 LLM 部署到不同的硬件平台,例如 Intel 的 CPU 及 GPU 系列产品。
方法二:构建新的 OpenVINO™ pipeline 类
第一种方法固然简单,但如果遇到 Optimum-intel 中还未适配的 LLM,那依然无法奏效,因此这里的第二种办法就是参考 HuggingFacePipeline 这个类对象(https://github.com/langchain-ai/langchain/blob/master/libs/langchain/langchain/llms/huggingface_pipeline.py),重新构建一个基于 OpenVINO™ 的类对象,以此来支持自定义的模型类别。
详细实现可以参考这个仓库:https://github.com/OpenVINO-dev-contest/langchain.openvino
仓库中的ov_pipeline.py就是用来构建 OpenVINO™ pipeline 的代码,为了方便演示,示例中底层还是调取 Optimum-intel 进行推理,但不同与第一种方式,这里我们可以选择脱离 Optimum-intel 的束缚,自行定义pipeline中的关键方法。这里有两个关键方法:
1. from_model_id函数用于读取本地或者远端的LLM以及其对应的Tokenizer,并利用OpenVINO™ runtime 对其进行编译以及初始化。这里的函数名仅供参考,大家可以根据自己的习惯自行修改,此外在这个函数中,我们还可以对模型的配置进行调整,比如指定不同的硬件平台进行部署,修改硬件端性能配置,例如供推理任务线程数(tread),并行任务数(stream)等,该函数预期返回一个可以直接运行的模型对象。
from_model_id(
cls,
model_id: str,
model_kwargs: Optional[dict] = None,
**kwargs: Any,
) -> LLM2. _call函数继承自父类 LLM,用于根据提升生成本文,根据父类中的定义,他的输入为 prompt文本,输出同样也是一个文本,因此在这个函数中就要求我们实现三个功能,Tokenizer 分词编码->LLM推理->tokenizer 解码,其实这也是LLM 问答任务中必须经历的三个步骤,所以这里的实现方式大家可以根据自己LLM模型对于输入输出的要求自行定义。
def _call(
self,
prompt: str,
stop: Optional[List[str]] = None,
**kwargs: Any,
) -> str:3. 这个仓库中提供了一个简单的 LangChain 示例sample.py,用于展示自定义 OpenVINO™ pipeline 在 LangChain 中的调用方式,核心部分可以参考以下代码片段。
llm = OpenVINO_Pipeline.from_model_id(
model_id=model_path,
model_kwargs={"device":device, "temperature": 0, "trust_remote_code": True},
max_new_tokens=64
)
llm_chain = LLMChain(prompt=prompt, llm=llm)总结
LangChain 做为当前最受欢迎的自然语言系统框架之一,可以帮助开发者快速构建起基于LLM的上层应用方案。而 OpenVINO™ 2023.2 新版本的发布又进一步提升了LLM的性能表现,同时降低了部署门槛,两者的结合可以帮助开发者更便捷地在英特尔平台上部署基于大语言模型的服务系统,丰富本地化 AI PC 应用场景的落地。
参考项目地址:
https://github.com/OpenVINO-dev-contest/langchain.openvino
https://github.com/langchain-ai/langchain
https://github.com/huggingface/optimum-intel
OpenVINO™
--END--
你也许想了解(点击蓝字查看)⬇️➡️ OpenVINO™ 2023.2 发布:让生成式 AI 在实际场景中更易用➡️ 开发者实战 | 介绍OpenVINO™ 2023.1:在边缘端赋能生成式AI➡️ 基于 ChatGLM2 和 OpenVINO™ 打造中文聊天助手➡️ 基于 Llama2 和 OpenVINO™ 打造聊天机器人➡️ OpenVINO™ DevCon 2023重磅回归!英特尔以创新产品激发开发者无限潜能➡️ 5周年更新 | OpenVINO™ 2023.0,让AI部署和加速更容易➡️ OpenVINO™5周年重头戏!2023.0版本持续升级AI部署和加速性能➡️ OpenVINO™2023.0实战 | 在 LabVIEW 中部署 YOLOv8 目标检测模型➡️ 开发者实战系列资源包来啦!➡️ 以AI作画,祝她节日快乐;简单三步,OpenVINO™ 助你轻松体验AIGC
➡️ 还不知道如何用OpenVINO™作画?点击了解教程。扫描下方二维码立即体验
OpenVINO™ 工具套件 2023.2点击 阅读原文 立即体验OpenVINO 2023.2
文章这么精彩,你有没有“在看”?