点击下方卡片,关注“CVer”公众号
AI/CV重磅干货,第一时间送达
引用表达分割(Referring Expression Segmentation,简称引用分割或RES)是一个基础的视觉语言多模态任务。给定一张图像和一个描述该图像中某个对象的自然语言表达式,RES旨在找到该目标对象并将其分割。现有的引用分割数据集和方法通常仅支持单目标表达式,即一个表达式指代一个目标对象。而对于多目标和无目标表达式的情况,则没有考虑在内。严重限制了引用分割的实际应用。
基于这个问题,来自新加坡南洋理工大学的研究者们定义了一个名为广义引用分割(Generalized Referring Expression Segmentation,GRES)的新任务,将经典的引用分割扩展到允许表达式指代任意数量的目标对象。同时,文章还构建了第一个大规模的GRES数据集gRefCOCO,其同时包含多目标、无目标和单目标表达式。

论文地址:https://arxiv.org/abs/2306.00968
项目主页:https://henghuiding.github.io/GRES/
欢迎加入CVer计算机视觉知识星球!每天更新最新最前沿的AI论文、项目,扫描下方二维码,即可加入学习!

RES在图形编辑、视频制作、人机交互和机器人等众多应用领域具有巨大潜力。目前,大多数现有方法都遵循在知名数据集ReferIt和RefCOCO中定义的RES规则,并在近年来取得了巨大进展。然而,大多数经典的引用分割方法对任务有预定义的强约束:
1.传统的RES不考虑无目标表达式,即在图像中没有匹配对象的自然表达语句。这意味着如果语句描述的目标在输入图像中不存在,现有的RES方法的行为是未定义的。在这种假设下,输入表达式必须与图像中的某个对象匹配,否则会不可避免地出现错误。
2.大多数现有数据集,例如最流行的RefCOCO,几乎不包含多目标表达式,即在一句话中同时指向多个目标物体的表达式。这意味着如果需要同时查找多个目标,用户需要分多次键入查询指令且每次只能指向一个目标物体。

图1:引用分割的实例,使用“The kid in red”来指示并分割图片中的红衣服小男孩
新任务:广义引用表达式分割
在文章中,为了解决传统RES存在的问题,研究者们提出了一个名为广义引用表达分割(Generalized Referring Expression Segmentation,简称GRES或广义引用分割)的新任务,允许表达式指向任意数量的目标对象。与经典的RES类似,GRES接受一张图像和一句自然语言表达式作为输入。但与传统RES不同,GRES进一步支持了多目标表达式,即在单个表达式中指定多个目标对象,例如图2中的“Everyone except the kid in white”,以及无目标表达式,即表达式没有指向图像中的任何对象,例如图2中的“the kid in blue”。GRES为输入表达式提供了更大的灵活性,可以更好地支撑引用分割的实际应用。

图2:多目标表达式和无目标表达式示例
新数据集:gRefCOCO
然而,现有的几个引用表达数据集,如RefCOCO系列,几乎不包含多目标表达式或无目标表达式样本,只有单目标表达式样本,如表1所示。
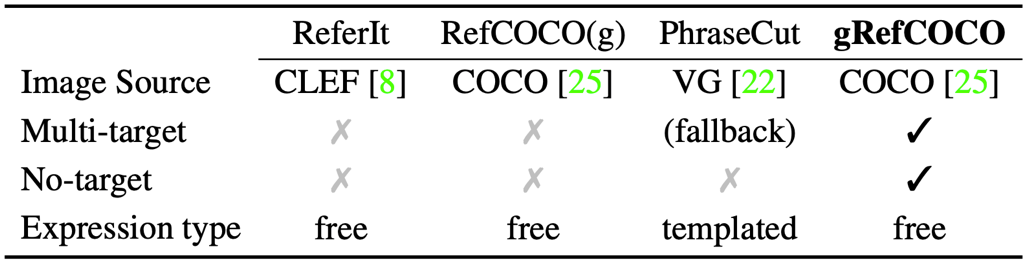
表1:gRefCOCO与其他引用表达式数据集的比较
为了促进对GRES的研究工作,本文构建了新的大规模引用分割数据集gRefCOCO。它进一步包含多目标表达式和无目标表达式。该数据集共有278,232个表达式,其中包括80,022个多目标表达式和32,202个无目标表达式,涉及19,994张图像中的60,287个不同物体。
gRefCOCO数据集的多目标表达式主要有以下难点:
1.计数表达式:处理包含计数的表达式,需要区分基数词和序数词,如“two”和“second”,并具备对象计数能力。
2.复合句结构:理解复合句结构中的多个元素之间的关系,包括“A and B”、“A except B”和“A with B or C”。如图3中的第一个表达式。
3.属性的范围:要处理多目标表达式中的不同目标之间的属性共享或差异,需深入理解各个属性以及它们与相应对象之间的关系。
4.复杂关系:多目标表达式中的关系描述更复杂,需要理解并推断目标之间的关系,例如通过关键词“and”来指示目标数量。模型需对图像和表达式中的所有实例及其相互作用有深入理解。如图3中的第二个表达式,使用了复杂的句子来表达目标与非目标之间的关系。

图3:gRefCOCO样本示例
无目标表达式的构建主要遵循两个原则:
1.表达式不能与图像完全无关。例如,给定图1中的图像,“the kid in blue”是可以接受的,因为图像中确实存在“kid”和“blue”,但没有一个“kind in blue”。但是像"狗"、"汽车"、"河流"等与该图像中的任何内容都完全无关的表达式是不可接受的。
2.如果规则1中所要求的表达式很难想出,标注员可以选择从RefCOCO同一split中的其他图像中选取具有迷惑性的表达式。
新模型:ReLA
GRES中多目标表达式中的关系和属性描述更加复杂。与经典的引用分割(RES)相比,对于广义引用表达分割(GRES)来说,更具挑战性的是对图像中区域之间的复杂交互关系进行建模,并捕捉所有对象的细粒度属性。本文提出了一个新的基准模型ReLA,明确地对图像的不同部分和表达式中的不同单词进行信息交换和相互作用,以分析它们之间的依赖关系。通过这种方式,我们能够更好地理解图像和表达式之间的复杂交互。
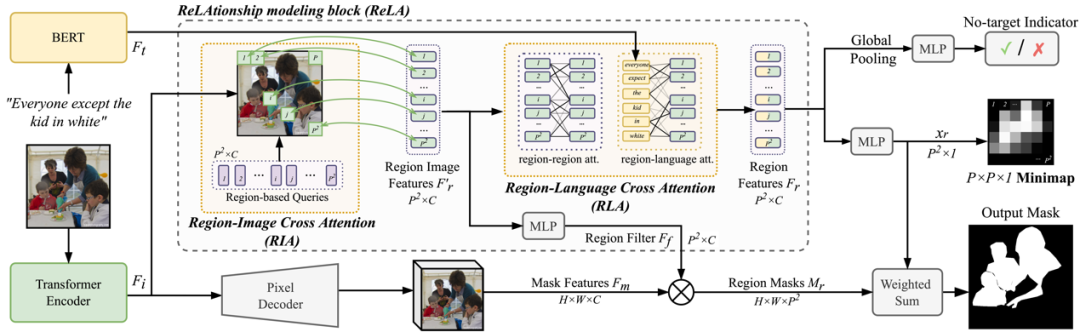
所提出的关系(ReLAtionship)建模方法具有两个主要模块,即区域-图像交叉注意力(Region-Image Cross Attention,RIA)和区域-语言交叉注意力(Region-Language Cross Attention,RLA)。RIA模块灵活地收集区域图像特征,而RLA模块则捕捉区域之间的关系以及区域与语言之间的依赖关系。通过这两个模块,我们能够更好地建模图像和表达式之间的复杂交互,并提高引用表达分割的性能。
实验
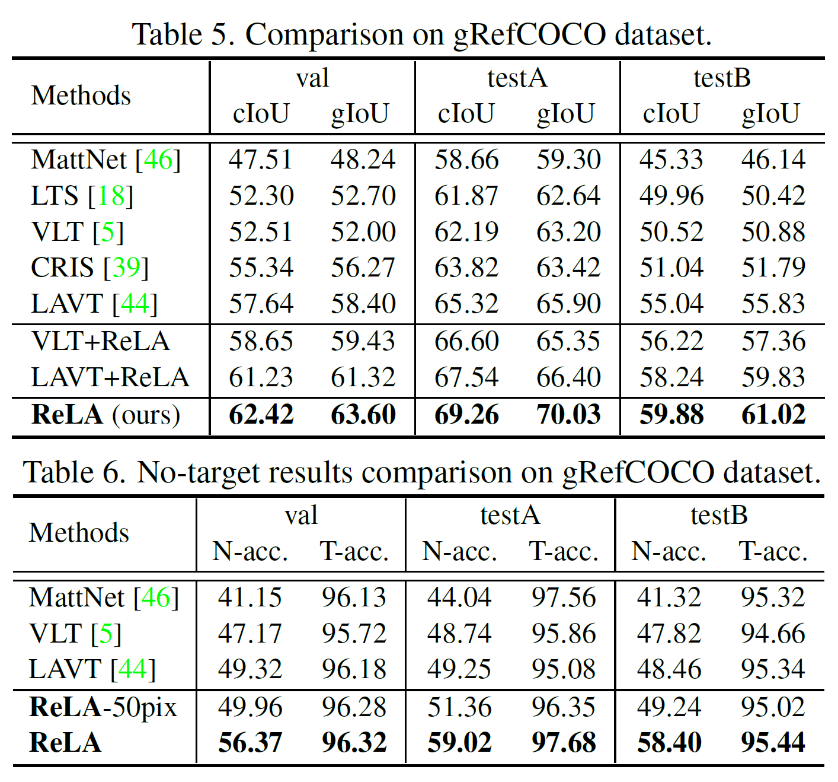
根据GRES任务的特性,文章提出了新的测评指标:gIoU、N-acc、T-acc,分别用来衡量整体分割性能、正确识别无目标表达式的性能、和无目标表达式对引用分割的影响。
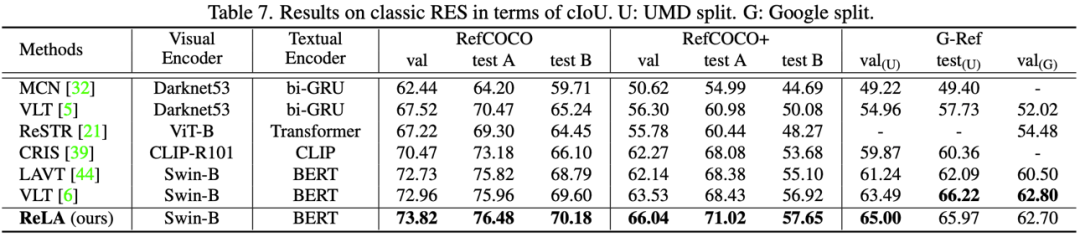
提出的基准方法ReLA在GRES和传统单目标RES上均取得了最佳性能。这证明了显式建模不同图像区域和词语之间的关系对引用分割的有效性。
对多目标表达式的分割结果可视化如下:


对无目标表达式的分割结果可视化如下:


总结
本文分析并解决了经典引用分割(RES)任务的局限性,即无法处理多目标和无目标表达式。基于此,本文定义了一个名为广义引用表达分割(GRES)的新任务,允许表达式中包含任意数量的目标。为支持GRES的研究,本文构建了一个大规模的数据集gRefCOCO、提出了基准方法ReLA,用于显式建模不同图像区域和词语之间的关系。该方法在经典的RES任务和新提出的GRES任务上取得了最佳结果。GRES降低了对自然语言输入的限制,扩大了引用分割的应用范围,如多实例和无正确对象的情况,期待GRES能够打开了新的应用领域。
更多细节,敬请参考论文原文。
最新CVPR 2023论文和代码下载
后台回复:CVPR2023,即可下载CVPR 2023论文和代码开源的论文合集
后台回复:Transformer综述,即可下载最新的3篇Transformer综述PDF
目标检测和Transformer交流群成立
扫描下方二维码,或者添加微信:CVer333,即可添加CVer小助手微信,便可申请加入CVer-目标检测或者Transformer 微信交流群。另外其他垂直方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch、TensorFlow和Transformer等。
一定要备注:研究方向+地点+学校/公司+昵称(如目标检测或者ransformer+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群
▲扫码或加微信号: CVer333,进交流群
CVer计算机视觉(知识星球)来了!想要了解最新最快最好的CV/DL/AI论文速递、优质实战项目、AI行业前沿、从入门到精通学习教程等资料,欢迎扫描下方二维码,加入CVer计算机视觉,已汇集数千人!
▲扫码进星球
▲点击上方卡片,关注CVer公众号整理不易,请点赞和在看![]()