项目介绍
使用Scrapy进行数据爬取,MySQL存储数据,Django写后端服务,PyEcharts制作可视化图表,效果如下。
项目下载地址:Scrapy爬取数据,并使用Django框架+PyEcharts实现可视化大屏
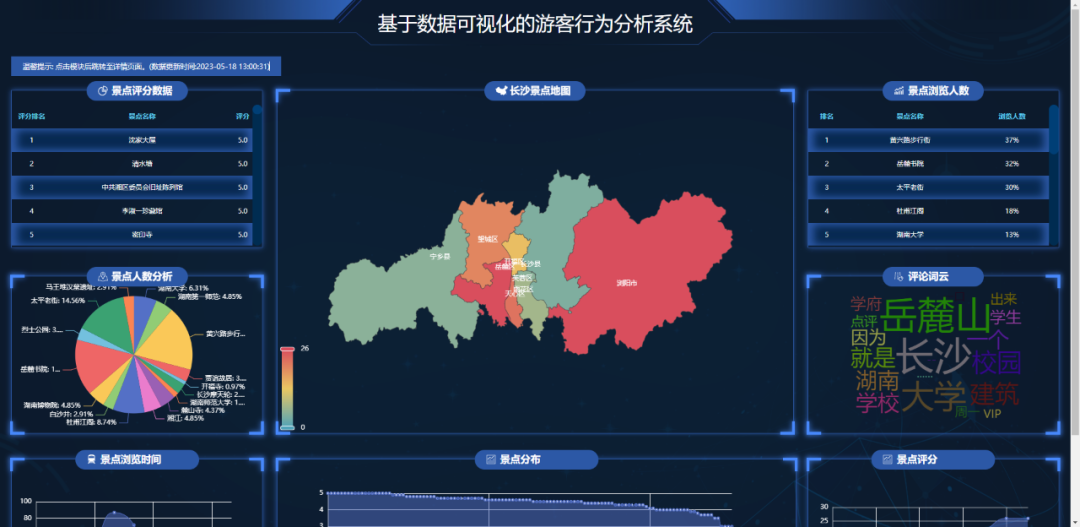
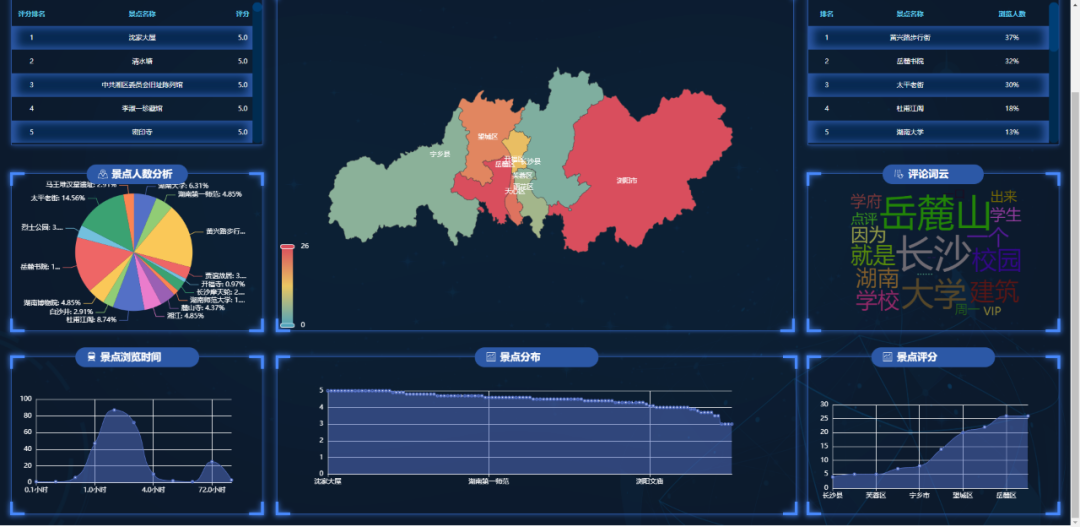
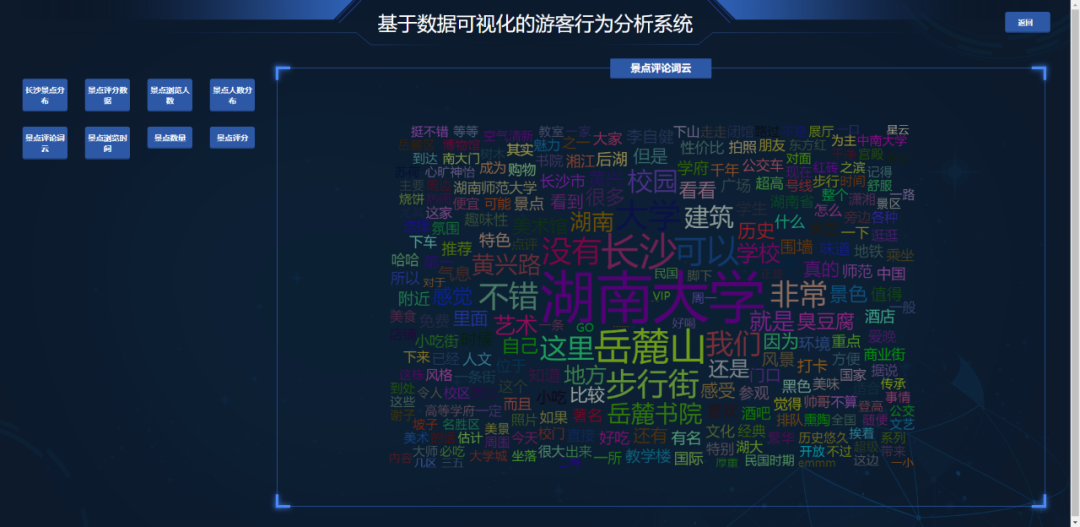
发现每个模块都有详情页,可以通过点击首页各个模块的标签,进行访问。
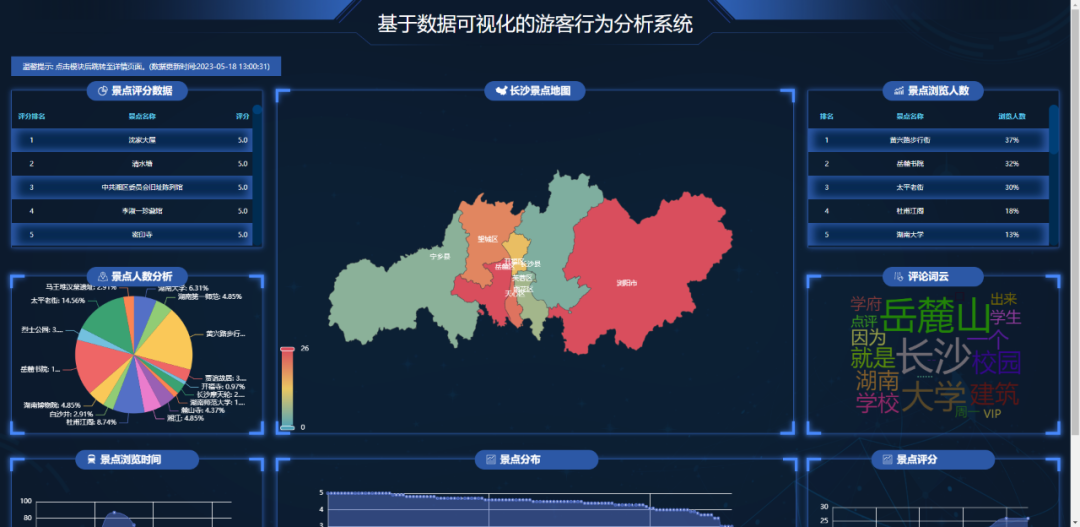
基于数据可视化的游客行为分析系统,包含以下几类图表。
- 景点数量各区县分布地图
- 景点数量各区县分布图
- 景点评分分布图
- 景点浏览时间分布图
- 景点评论词云图
- 景点浏览人数占比分析
- 景点人数占比分析
- 景点评分数据排名
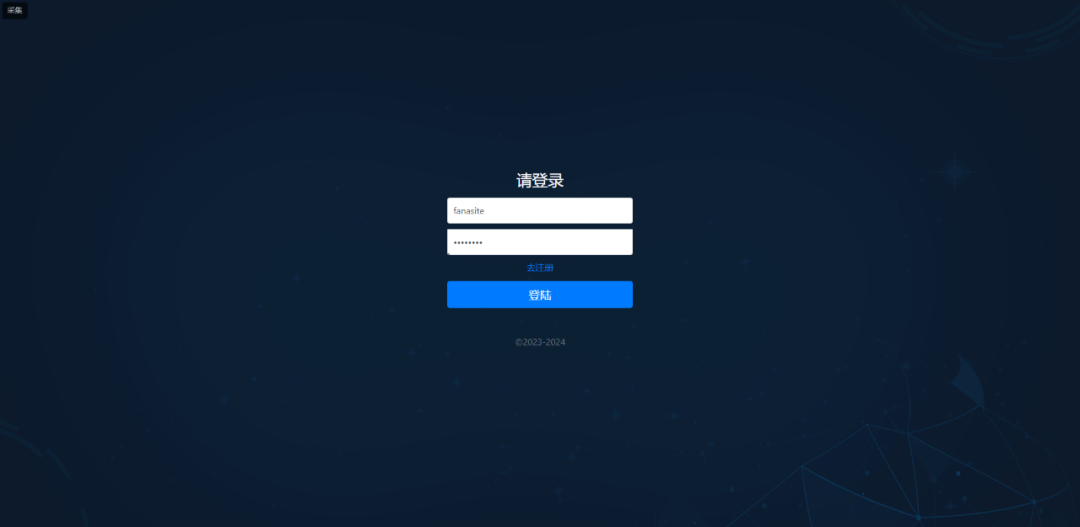
还有登录界面,可以自己注册账号,说明包含用户管理。
接下来教大家如何去部署,以win10为例。

1、项目部署-Python
首先需要安装Anaconda(版本4.11.0),方便创建Python环境。
Anaconda的安装方法,大家可以自行百度,还是比较容易的。
安装好以后,创建虚拟环境,根据项目提供的【requirements.txt】文件,安装所需的依赖。
# 创建虚拟环境
conda create --name test python=3.8.13
# 激活环境
conda activate test
# 安装依赖
pip install -r requirements.txt2、项目部署-MySQL
然后是安装MySQL数据库(版本8.0.33),推荐使用msi文件进行安装,不容易出错。
一定要记住root账户的密码,后续会用到。
安装好以后,创建数据库,使用数据库。
# 创建数据库
create database hunan_web;
# 使用数据库
use hunan_web;接下来创建数据表,并且插入数据。
具体可以看项目中【new_hunan_web.sql】这个文件。
原始数据。
也就意味着,你无需运行爬虫代码,便有数据,能立马将项目运行起来。
最后在程序里面设置下数据库的密码。
在hunan_web文件夹中setting.py文件里去设置。

设置好以后,运行服务的时候,就可以连接到数据库了。
3、项目部署-运行访问
当Python和数据库环境都搭建好时,运行【manage.py】文件
# 运行项目
python manage.py runserver结果如下。

使用谷歌浏览器访问网页地址:http://127.0.0.1:8000/
是一个登录页,点击去注册。

输入账号密码,即可注册成功,然后去登录。
登录成功,即可看到到分析页面。
4、项目部署-数据更新
如果你想更新数据库,可以运行爬虫代码。
# 更新数据
scrapy crawl qunaer运行的时候可能会出问题,可以通过下面两种方法解决。
# ImportError: cannot import name 'SSLv3_METHOD' from 'OpenSSL.SSL'
pip3 install pyopenssl==22.0.0
# AttributeError: module 'lib' has no attribute 'OpenSSL_add_all_algorithms'
pip3 install cryptography==38.0.4如果上面的方法也不能解决,就把scrapy库升级到最新版本。
# 升级
pip install --upgrade scrapy总结
以上操作,就能实现可视化大屏项目的部署。
当然我们还可以写不同省份的游客行为分析系统,或者切换其它的数据来源。
又或者是使用pyecharts其它类型的图表,这个大家都可以自行去学习。