目录
4. operator new & operator delete
5. malloc/free和new/delete的区别总结
6. 定位new表达式(placement-new) (了解)
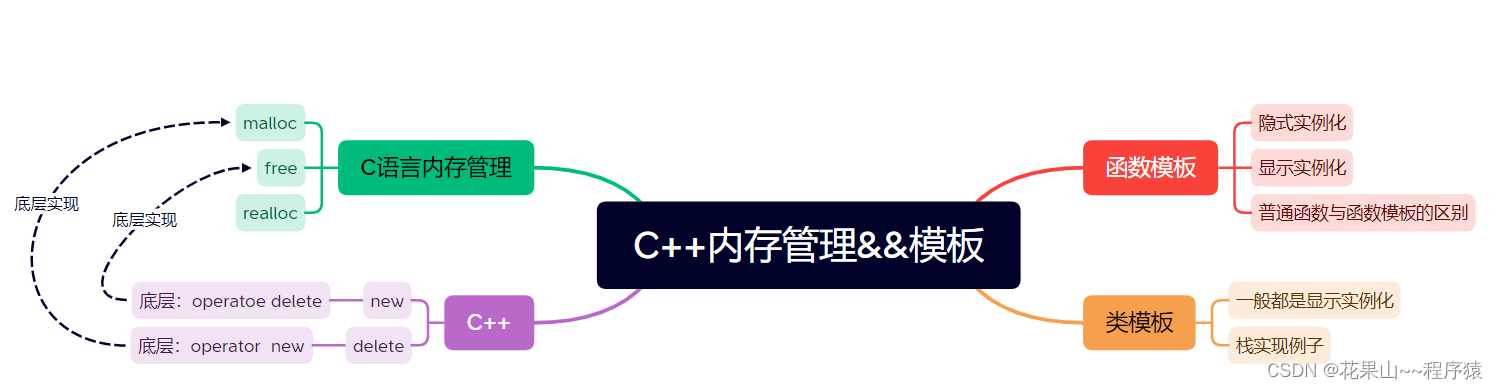
一,回望C语言内存
尝试给出下面答案:

结果:

解析:
二, C++ 内存管理方式
1. 内置类型
对于内置类型 new / delete 与 malloc & free 没有本质的区别
void Test()
{ // 申请一个int空间
int* z1 = new int;
// 申请5个int的数组
int* z2 = new int[5];
// 申请一个int空间,初始化为5
int* z3 = new int(5);
// 销毁
delete z1;
delete[] z2; // 销毁类型要匹配
delete z3;
// 对于内置类型 new / delete 与 malloc & free 没有本质的区别
// 仅仅new只是用法上简化了
}注意: C++里面没有支持 C语言 realloc 的创新,C++接口不支持扩容。
2. 自定义类型
struct B
{
public:
B(int b)
{
k = b;
cout << "B" << endl;
}
~B()
{
cout << "~B" << endl;
}
private:
int k;
};
struct A
{
public:
A(int sum, int b)
: _sum(sum)
, _b(b)
{
cout << "A" << endl;
}
~A()
{
cout << "~A" << endl;
}
private:
int _sum;
B _b;
};
int func()
{
A* p1 = new A(10, 20); // 1.内置类型初始化 2. 自定义类型调用其构造函数
A* p2 = new A[10];
A* p3 = new A[10]{1, 2, 3, 4, 5, 6, 7, 8, 9, 10}; // 多实例,并且初始化
delete p1; // 1. 销毁内置类型 2. 调用析构函数
delete[] p2; // 销毁类型一定要匹配使用, 否则可能出现报错
delete[] p3;
return 0; // 返回码
}3. new & malloc 返回内容区别
(1) malloc 失败 返回 null 指针
(2) new 失败 会返回异常 (异常后面再着重开始讲)
void test()
{
try // 其中如果new失败会进入异常,也就是catch
{
// 当内存申请超过一定限度,会申请失败
// malloc 失败会返回null
char* p1 = (char*)malloc(sizeof(char) * 1024u * 1024u * 1024u * 1024u * 1024 * 1024);
printf("%p\n", p1);
// new 失败会抛异常
char* p2 = new char[1024 * 1024 * 1024 * 1024 * 1024 * 1024];
printf("%p\n", p2);
free(p1);
delete[] p2;
}
catch (const std::exception& e) // 打印最近的异常信息
{
cout << e.what() << endl;
}
}注意: 面对new 失败返回异常 会用一个try 来包含 需要new 的代码。
4. operator new & operator delete

operator new: 该函数实际通过malloc来申请空间,当malloc申请空间成功时直接返回;申请空间失败,尝试执行空间不足应对措施,如果改应对措施用户设置了,则继续申请,否则抛异常。( new -> operator new -> malloc -> 指针 或 异常 )
operator delete: 该函数最终是通过free来释放空间的。
5. malloc/free和new/delete的区别总结
- 1. malloc和free是函数,new和delete是操作符
- 2. malloc申请的空间不会初始化,new可以初始化
- 3. malloc申请空间时,需要手动计算空间大小并传递,new只需在其后跟上空间的类型即可,如果是多个对象,[]中指定对象个数即可
- 4. malloc的返回值为void*, 在使用时必须强转,new不需要,因为new后跟的是空间的类型
- 5. malloc申请空间失败时,返回的是NULL,因此使用时必须判空,new不需要,但是new需要捕获异常
- 6. 申请自定义类型对象时,malloc/free只会开辟空间,不会调用构造函数与析构函数,而new在申请空间后会调用构造函数完成对象的初始化,delete在释放空间前会调用析构函数完成空间中资源的清理。
6. 定位new表达式(placement-new) (了解)
定位new表达式是在已分配的原始内存空间中调用构造函数初始化一个对象
如: new (p1) A (10) // 其中 p1 通过malloc已开辟空间但未初始化,A是类型 , 10是调用自定义构造函数初始化的值。
struct B
{
public:
B(int b)
{
k = b;
cout << "B" << endl;
}
~B()
{
cout << "~B" << endl;
}
private:
int k;
};
void test1()
{
B* p3 = (B*)malloc(sizeof(B));
// malloc 的空间并未初始化
new (p3) B(100); // 给构造函数参数 100
p3->~B();
delete p3;
}
三,模板初阶
1. 泛型编程——概念
我们肯定写过这样的编程
void Swap(int& z1, int& z2)
{
int tmp = z2;
z2 = z1;
z1 = tmp;
}交换函数,一般只能处理一种数据; 而一个程序需要交换多种类型数据,这样我们需要创建多种类型交换函数,这个过程是重复,低效的。
泛型编程:编写与类型无关的通用代码,是代码复用的一种手段。模板是泛型编程的基础。

2. 函数模板
编译器使用模板步骤:
1. 推演 类型
2. 模板实例化

下面简单展示一下:
template <class T> // 或者 <template T> T只是取名字
void Swap(T& z1, T& z2)
{
T tmp = z2;
z2 = z1;
z1 = tmp;
}
int main()
{
int i = 1, b = 2;
Swap(i, b);
return 0;
}在编译器编译阶段,对于模板函数的使用,编译器需要根据传入的实参类型来推演生成对应类型的函数以供调用。比如:当用double类型使用函数模板时,编译器通过对实参类型的推演,将T确定为double类型,然后产生一份专门处理double类型的代码,同理这就是我们交换函数的模板, 中间编译器会进行推导类型,编译更复杂,时间会稍久一些。
注意:交换用的是同一套模板,但调用的函数并不是同一个函数。(编译器自动帮我们创建不同类型的交换函数)

关键的来了: 以后不需要自己创建交换函数,C++库中有一套交换函数,在std 命名空间里面。
操作如下:
#include <iostream>
using namespace std;
int main()
{
int i = 1, b = 2;
double z = 1.1, k = 2.2;
swap(i, b); // 小写就行
swap(z, k); // 模板推导,需要类型相同,否则报推导类型不确定
return 0;
}(1. 模板实例化
概念
(2. 显式实例化
在函数名后的<>中 指定模板参数 的实际类型
template <class T> // 或者 <template T>
T* func1(int n)
{
T* k1 = new T(n);
}
int main(void)
{
int a = 10;
double b = 20.0;
// 显式实例化
Add<int>(a, b); 1. 普通
func1<A>(10); 2. 特殊,必须要显式否则怎么推演?计算机:二进制给你,你来推演!
return 0;
}(3. 隐式实例化
让编译器根据实参 推演模板 参数的实际类型
#include <iostream>
using namespace std;
int ADD(size_t & z1, size_t & z2) // size_t是标准C库中定义的,它是一个基本的与机器相关的无符号整数的C/C + +类型
// 就简单理解为 unsiged int 主要防止 负数
{
return z1 + z2;
}
template <class T> // 或者 <template T>
T ADD(const T& z1, const T& z2)
{
return z1 + z2;
}
template <class B1, class B2> // 可以提供多个模板
B1 ADD(B1& b1, B2& b2)
{
return b1;
}
int main()
{
// 隐式实例 ——通过编译器自动推导, 不人为干预。
int i = 1, b = 2;
double z = 1.1, k = 2.2;
cout << ADD(i, (int)z) << endl; // 模板 不支持1.1 -> 1 隐式转化,但可以提前,进入的是
cout << ADD(1.2, (double)1) << endl;
// 思考;调用哪一个函数
cout << ADD(i, b) << endl; // 计算机会调用现成的函数,
// 调用 int ADD(int& z1, int& z2) ; 模板实例化需要通过编译器,所以优先级比较低。
cout << ADD(z, i) << endl; // 两种类型,则会选择多类型模型 B1 ADD(B1& b1, B2& b2)
return 0;
}3. 类模板——【练习】实现栈的Push
#include <iostream>
using namespace std;
#include <assert.h>
template <class T>
class stack
{
public:
stack(int capacity = 4)
: _size(0)
, _capacity(capacity)
, plist(nullptr)
{
plist = new T[_capacity];
}
void Push(T x)
{
assert(plist);
if (_size == _capacity)
{
// 1. 开空间
// 2. 拷贝旧数据
T* tmp = new T[_capacity * 2];
if (plist) // plist 首先是空指针,如果是是第一次不需要拷贝旧数据
{
memcpy(tmp, plist, sizeof(T) * _capacity);
// 如果申请成功
_capacity *= 2;
delete[] plist;
plist = tmp;
}
}
plist[_size++] = x;
cout << plist[_size - 1] << endl;
}
void Pop()
{
assert(_size > 0)
_size--;
}
const T& TopStack() // 返回栈顶元素,用的是引用,可以修改 私密成员,所以需要const修饰
{
assert(_size > 0); // 防止栈为空
return plist[_size - 1];
}
~stack()
{
delete[] plist;
_size = _capacity = 0;
}
private:
T* plist;
int _size;
int _capacity;
};
void func()
{
try
{
stack<int> p1; // 其中如果new失败会进入异常,也就是catch
stack<char> p2;
p1.Push(1);
p1.Push(2);
p1.Push(3);
p1.Push(4);
p1.Push(5);
cout << p1.TopStack() << endl;
}
catch (const std::exception& e)
{
cout << e.what() << endl; // 打印最近的异常信息
}
}总结:
- 类模板定义与声明不能分离(同文件允许分离),否则会报错。
- 一般类实例化时,不带类类型,所以一般类模板都要使用显示实例化。
- 在C++中,类模板在头文件中定义,因此可以写成“ .hpp”的头文件,意思是不仅有声明而且还有实现,一般是类模板实现。
结语
本小节就到这里了,感谢小伙伴的浏览,如果有什么建议,欢迎在评论区评论;如果给小伙伴带来一些收获请留下你的小赞,你的点赞和关注将会成为博主创作的动力。