作者 | 智商掉了一地、ZenMoore
近年来,随着大模型的涌现,微调语言模型已经在各种下游任务上展现出了卓越的性能。然而,这些庞大模型的参数量常常达到数十亿甚至上百亿的级别,训练这样规模的模型需要消耗大量的内存,并且传统的反向传播方法在优化过程中表现缓慢。
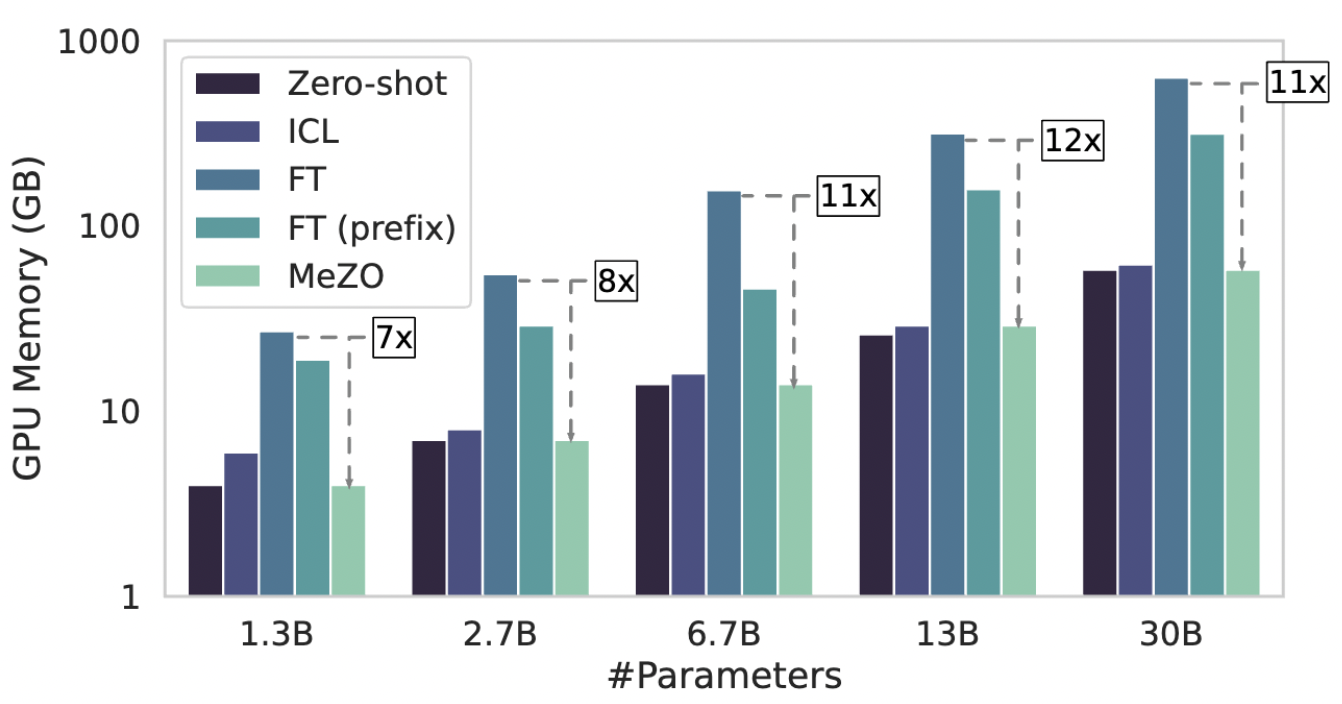
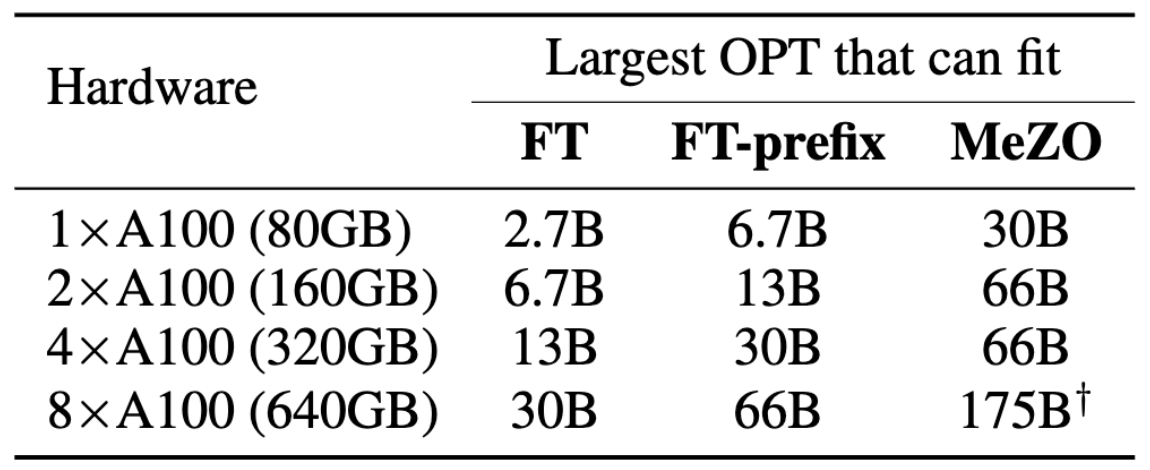
本文的作者们的提出了 MeZO 这种内存高效的零阶优化器。通过将经典的 ZO-SGD 方法改进为原地操作,该方法实现了与推理阶段相同的内存占用,使得微调语言模型变得更加高效。以单个 A100 80GB GPU 为例,使用 MeZO 可以训练具有 300 亿参数的模型,而传统的反向传播方法在相同的预算下只能训练 27 亿参数的大模型。
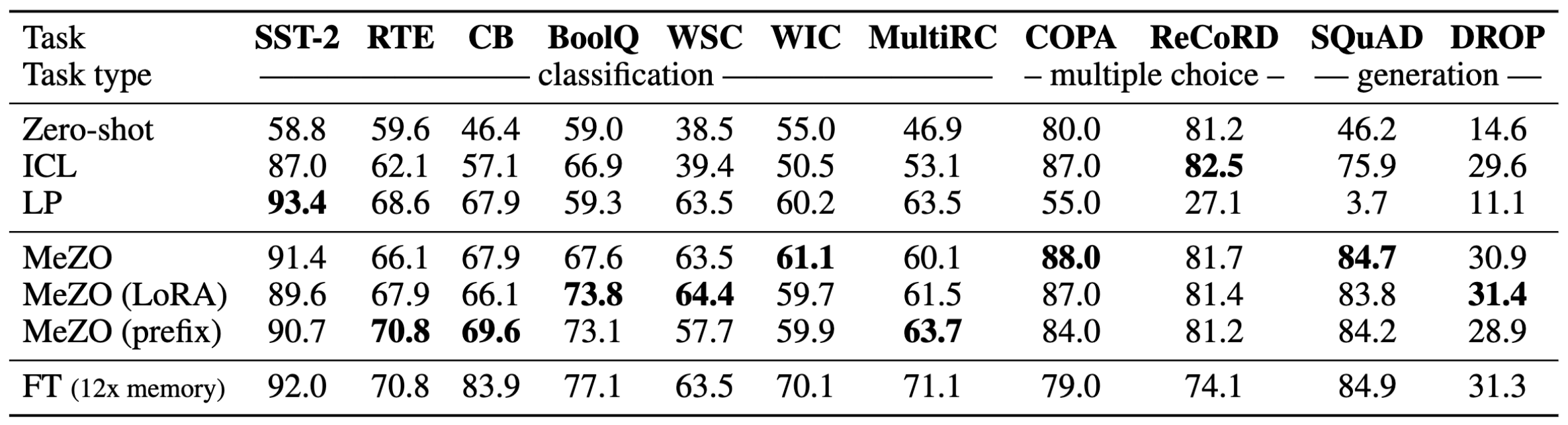
如图 1 所示,作者在 OPT-13B 模型上进行了实验,并对比了它们的结果。尽管仅使用了 1/12 的内存,MeZO 在 7 个任务中展现出优于 zero-shot 和 ICL 的结果。
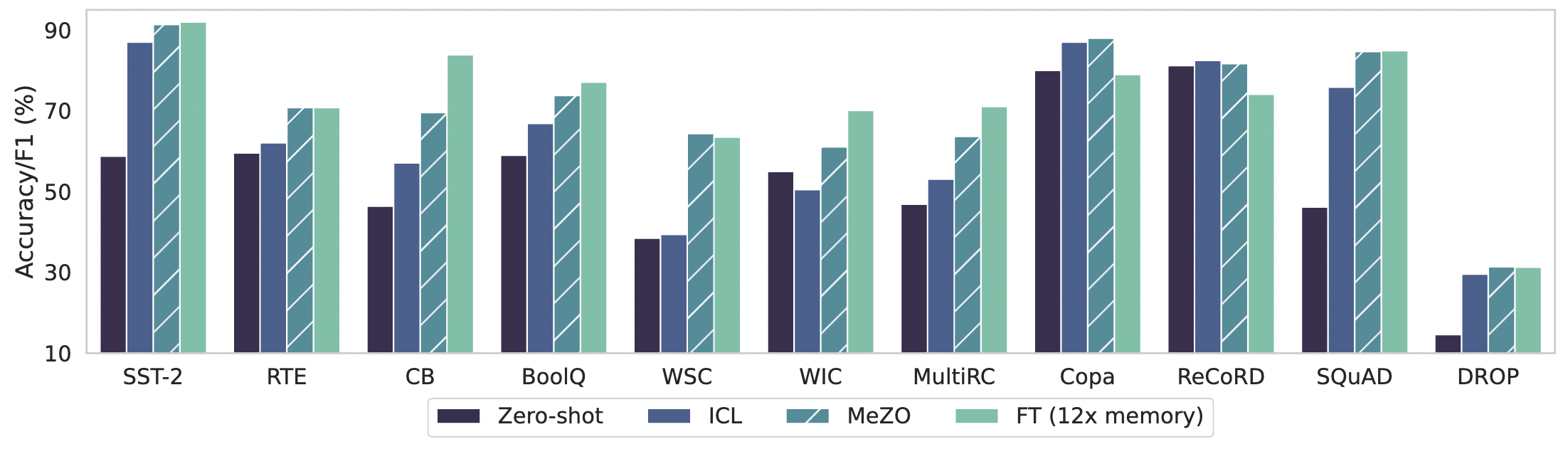
那这也就意味着,研究人员和开发者们使用 MeZO 这种内存高效的零阶优化器,也许能克服传统方法中遇到的内存限制和计算瓶颈。可以实现更自由地探索、训练和优化具有巨大参数规模的语言模型,为自然语言处理领域带来更加精确和高效的解决方案~

论文题目:
Fine-Tuning Language Models with Just Forward Passes
论文链接:
https://arxiv.org/abs/2305.17333
代码地址:
https://github.com/princeton-nlp/MeZO
大模型研究测试传送门
GPT-4能力研究传送门(遇浏览器警告点高级/继续访问即可):
https://gpt4test.com
论文速览
背景设置:考虑一个标记数据集 D \mathcal{D} D 和一个 mini-batch B \mathcal{B} B,用 L ( θ ; B ) L(\theta;\mathcal{B}) L(θ;B) 表示 mini-batch 上的损失。在这个设置下,引入经典的零阶(ZO)梯度估计。
内存高效的 ZO-SGD(MeZO)
由于经典的 ZO-SGD 算法需要存储分布 z ∈ R d \mathcal{z} ∈ \mathbb{R}^d z∈Rd,因此其内存开销是推理的两倍。内存高效的 ZO-SGD(MeZO)的提出是为解决这个问题,如算法 1 所示。

在每个步骤中,首先随机选择一个种子 s,对于算法 1 中 z 的四种用法中的每一种,通过 s 重新设置随机数生成器,并重新采样 z 的相关条目。通过这种原地实现,MeZO 的内存占用与推理阶段的内存成本相当。
需要注意的是,算法 1 描述了对每个参数进行分别扰动的操作,对于大型模型来说,这可能会耗费大量时间。在实践中,可以通过同时扰动整个权重矩阵而不是独立扰动每个标量来节省时间。这会带来额外的内存开销,开销的大小与最大的权重矩阵相当;通常情况下,最大的权重矩阵是词嵌入矩阵。
MeZO 扩展
MeZO 可以与其他基于梯度的优化器结合使用,例如带动量的随机梯度下降(SGD)或 Adam 优化器。
尽管原始的实现方式需要额外的内存来存储梯度动量的估计值,但 MeZO-momentum 和 MeZO-Adam 通过使用保存的前向传播损失和 z 来重新计算梯度的移动平均值,从而减少了这种内存开销。
此外,SPSA 梯度估计中的所有坐标具有相同的尺度,但深层 Transformer 的不同层可能具有不同尺度的梯度。因此,作者借鉴了分层自适应优化器的思想,设计了几种 MeZO 的变体。
实验
- ICL:在上下文学习中使用
- LP:线性探测
- FT:使用 Adam 进行完全微调
内存使用情况
MeZO 在许多任务上的表现与 FT 相当,优于等价内存方法,同时大大降低了内存成本。图 2 和图 3 中比较了 ICL、FT、LP 和 MeZO 的内存消耗。
中等规模的掩码语言模型
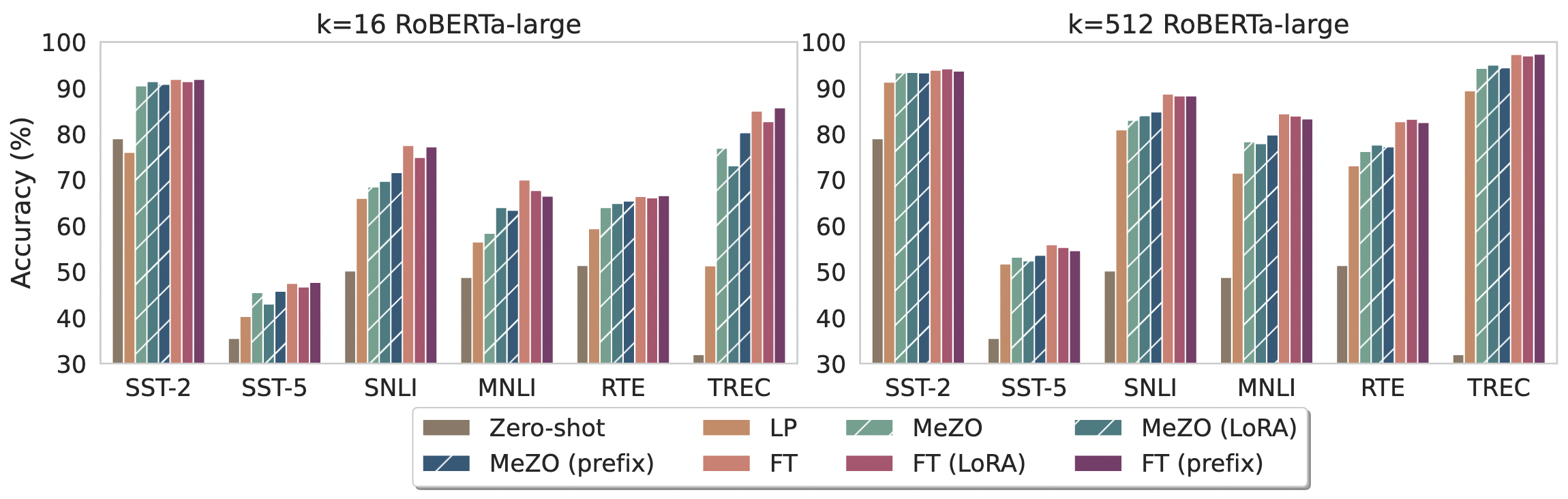
实验结果显示:
- MeZO 在与 zero-shot、LP 和其他等价内存方法相比表现明显更好。
- 在有足够数据的情况下,MeZO 实现了与 FT 相当的性能(最多相差5%)。
- MeZO 在全参数调优和 PEFT 方面都表现良好。
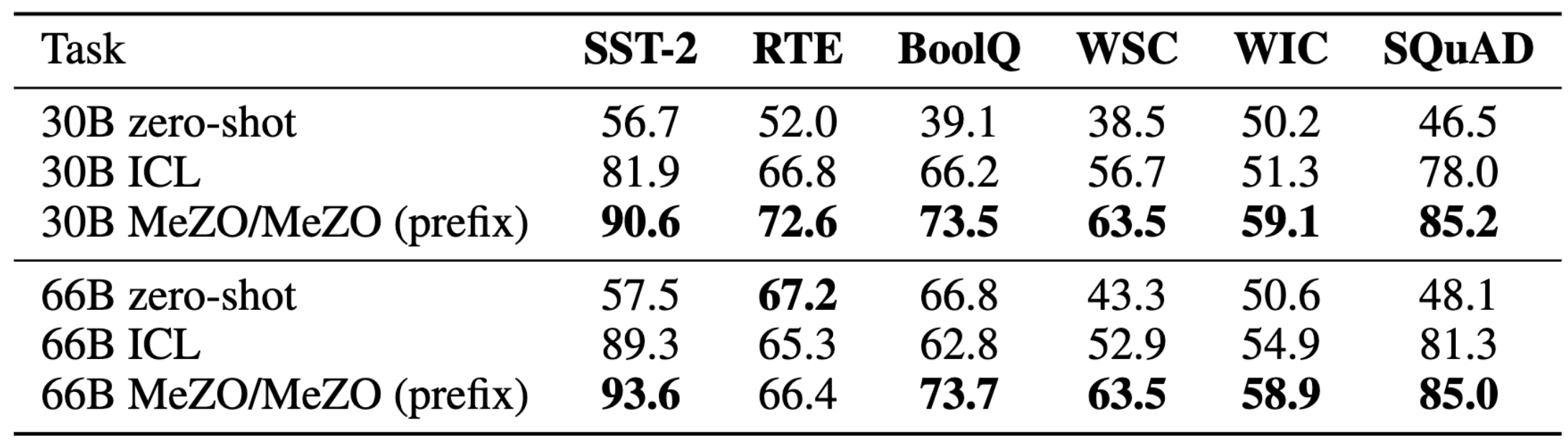
大型自回归语言模型
MeZO 在分类、多项选择和生成任务中展现出强大的性能。
MeZO 可扩展至拥有 660 亿参数的模型。
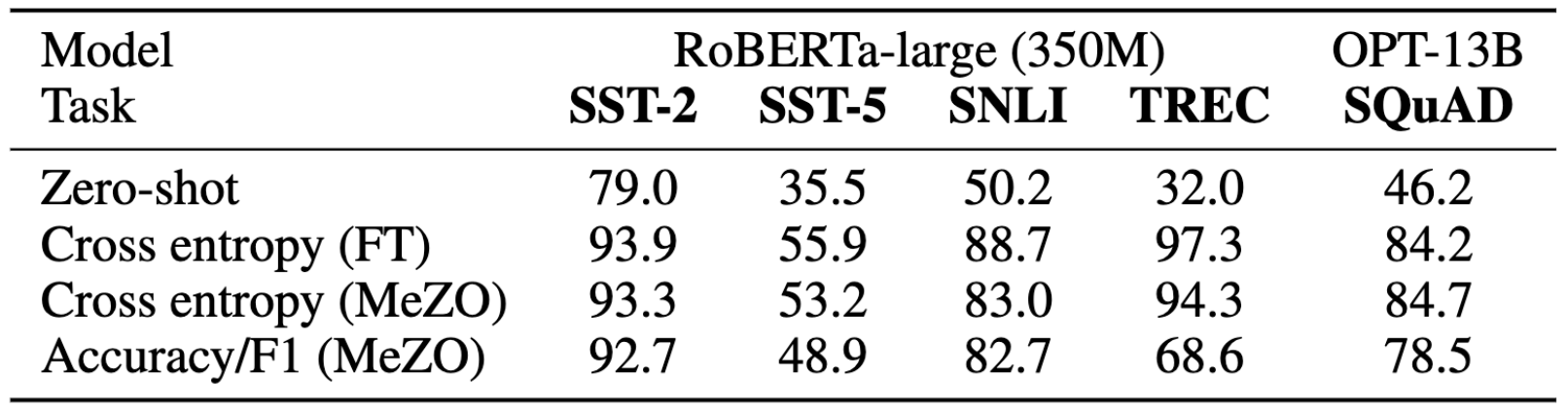
使用非可微目标进行训练
MeZO 可以优化准确率和 F1 分数等不可微目标。
小结
这种方法的重要性不言而喻,它为研究人员和开发者们提供了一种有效路径,使得他们能够在有限的资源下训练更大规模的语言模型。
- 首先,MeZO 的内存效率使得在训练阶段可以使用与推理阶段相似的硬件配置,这对于实际应用和部署非常重要。传统的反向传播方法需要更多的内存和计算资源,限制了大规模模型的使用范围。而使用 MeZO,研究人员和开发者们可以在相对较低的成本下进行训练,同时获得更高的模型容量和表达能力。
- 其次,MeZO 的原地操作特性避免了不必要的内存开销和数据传输,进一步提升了训练效率。传统的反向传播方法需要存储和传输大量的中间计算结果,而 MeZO 则在不增加额外内存开销的情况下进行模型参数的更新,减少了内存占用和数据传输的需求。这对于训练大规模语言模型而言尤为重要,使得训练过程更快速和高效。
- 因此,MeZO 的提出对于推动大规模语言模型的发展具有重要意义。它为研究人员和开发者们提供了一种创新的优化方法,使得他们能够更加灵活地设计和训练具有庞大参数量的模型。通过提高训练效率和降低资源成本,MeZO 为语言模型的进一步研究和应用打开了新的可能性,有望在自然语言处理领域带来更大的突破和创新。此外,这种内存高效的优化器还有助于降低训练大规模模型的门槛,使更多的人能够参与到语言模型的研究和应用中,从而促进创新和技术的普及。