来自:量子位
进NLP群—>加入NLP交流群
单台机器,就能微调全参数羊驼大模型!
这一令开源党狂喜的最新成果,来自复旦邱锡鹏团队。

具体而言,研究人员提出了名为LOMO(低内存优化)的新优化器,并在配备8卡RTX 3090(24GB内存)的单台服务器上,成功微调65B LLaMA。
论文一经发布,就引发了不少讨论——
在GPT-4掀起狂潮之后,人们在惊叹于大语言模型能力的同时,正在越来越多地思考模型控制权的问题。
有业内人士对此感到十分兴奋:
对于大模型普及来说,单机微调LLaMA 65B具有非常重要的意义!
我曾梦想每个人都至少可以微调Chinchilla(700亿参数,DeepMind出品)这种规模和质量的模型,现在复旦做到了这一点。
单机微调650亿参数大模型
论文的主要贡献LOMO(Low-Memory Optimization)优化器,想要解决的是有限资源条件下,大模型全参数微调的难题。
研究人员指出,在训练大语言模型的过程中,优化器状态占用了大部分内存。比如Adam,就会把中间状态存储下来,而这些状态的大小能达到参数大小的2倍。
因此,复旦团队的优化思路是这样的:
第一步,从算法角度重新思考优化器的功能。 由于SGD(随机梯度下降)不存储任何中间状态,因此这是一个很好的替代方案。问题在于,SGD中梯度计算和参数更新是分开执行的,仍可能会导致梯度张量过大,内存使用率高。
于是,研究人员提出了LOMO,将梯度计算和参数更新合二为一,避免存储任何梯度张量,以减少内存占用量。
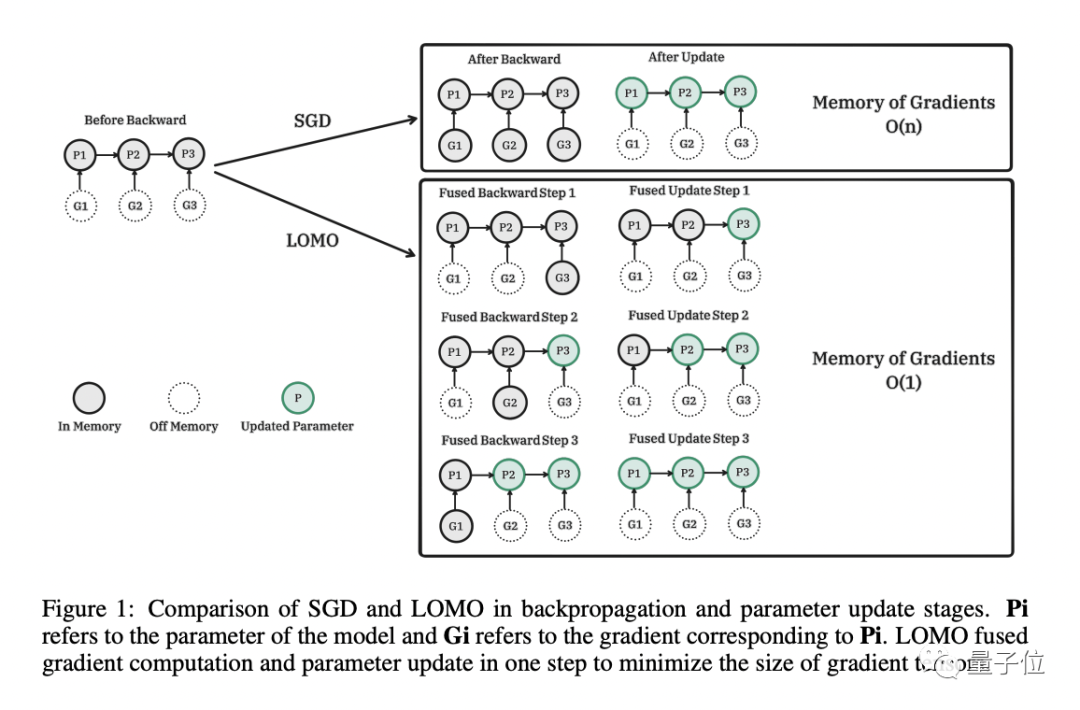
为了稳定LOMO的混合精度训练,研究人员还采取了以下步骤。
梯度归一化:将梯度应用于模型参数之前,对梯度进行归一化。
损失缩放:在计算梯度之前,用损失函数乘以缩放系数。
在训练期间将某些计算转换为全精度
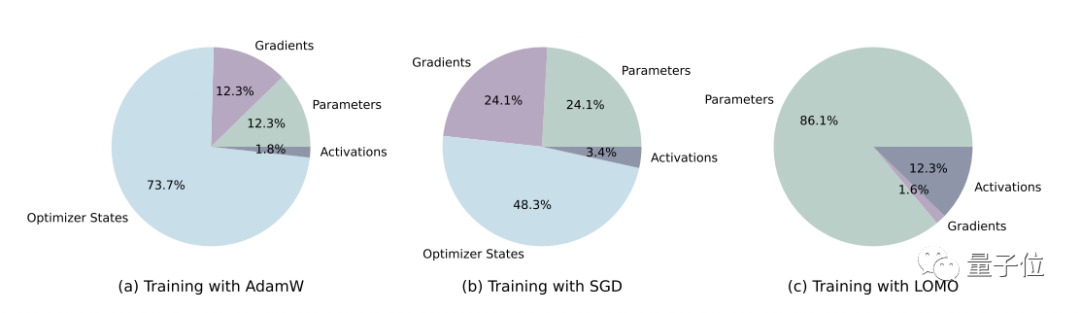
研究人员分析了使用不同优化器的训练过程中,模型状态和激活的内存使用情况。
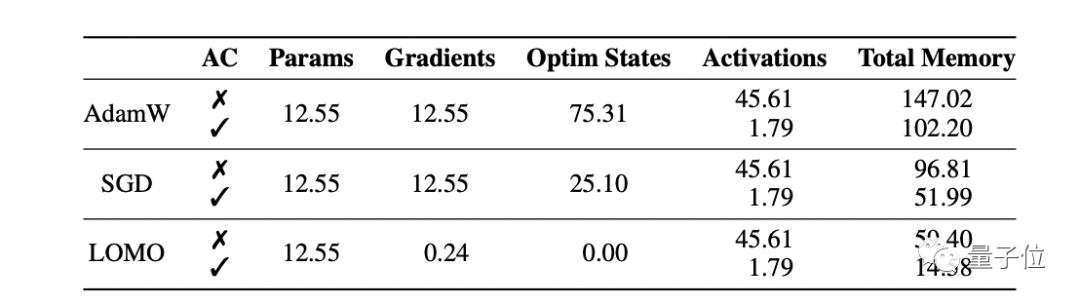
可以看到,与AdamW相比,LOMO的内存占用从102.20GB降低到了14.58GB。
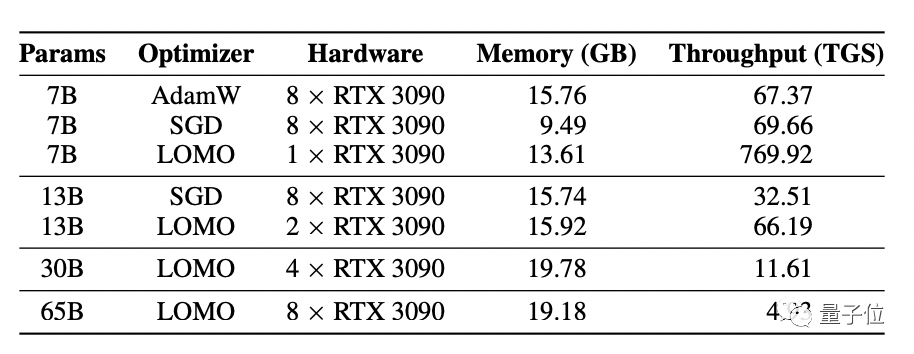
吞吐量测试的结果则显示,在配备8块RTX 3090显卡的服务器上,LOMO可以hold得住LLaMA 65B的训练。
研究人员提到,使用这样的服务器配置和LOMO,在1000个样本上进行训练,每个样本包含512个token,训练时间大约为3.6小时。
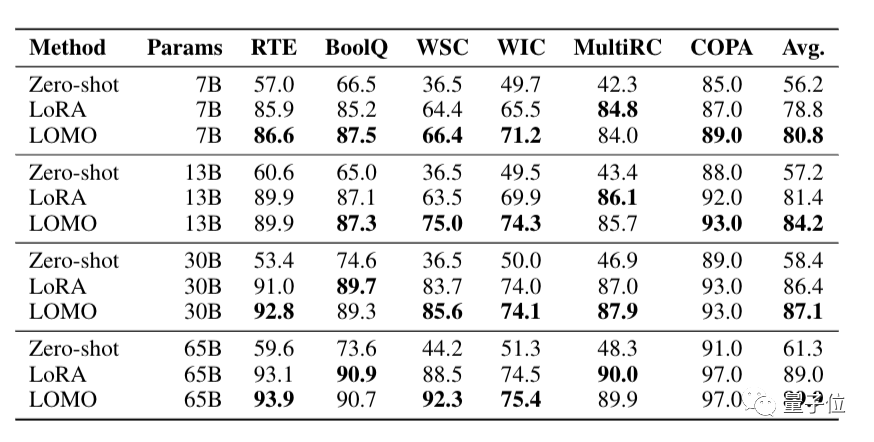
研究人员还在SuperGLUE基准测试上,比较了LOMO与Zero-shot、LoRA的下游任务性能。
结果显示,在6个数据集和不同大小模型中,LOMO的表现均好于Zero-shot。在大部分实验中,LOMO的表现优于LoRA。
当然啦,尽管在大模型训练中,8块3090并不是高配,但对于普通人来说,还是有点不亲民。
有不少网友就吐槽说:8块3090还能叫资源有限吗?
不过,也有人认为,这仍然是个好消息。
虽然不太可能拥有这样的服务器配置,但租这个配置的机器也不算贵。

另一边,研究人员也坦承了论文的局限性,并表示将进一步降低训练大语言模型的资源门槛。
目前,使用LOMO训练时,大部分内存被参数占用。因此,一个有前景的方向是探索参数量化技术,这可能会大大减少内存使用。
LOMO一作吕凯,是论文通讯作者、复旦大学计算机科学技术学院邱锡鹏教授门下的硕士生。本科同样毕业于复旦大学。
此前,复旦开源的MOSS大模型,正是来自邱锡鹏团队。
论文地址:
https://arxiv.org/abs/2306.09782
项目地址:
https://github.com/OpenLMLab/LOMO
进NLP群—>加入NLP交流群