k-means聚类算法的原理
K-means是一种聚类算法,其原理是将数据集划分为k个簇,使得每个数据点都属于最近的簇,并且簇的中心是所有数据点的平均值。这个算法是基于迭代优化的,每个迭代步骤会更新簇的中心点,直到达到收敛条件。
下面是K-means聚类算法的基本原理:
初始化:首先,选择要将数据集分成k个簇,然后随机选择k个数据点作为初始簇中心。
分配:将每个数据点分配到距离其最近的簇中心,每个数据点只能属于一个簇。
更新:根据分配的数据点更新簇中心点,这是通过计算属于每个簇的数据点的平均值来实现的。
重复:重复步骤2和3,直到簇中心点不再发生变化,或者达到预定的迭代次数。
输出:得到k个簇和每个簇的中心点。
K-means聚类算法的优缺点:
优点:
K-means算法易于实现和理解,计算效率高,适用于大规模数据集。
适用于处理高维数据,效果较好。
缺点:
需要手动指定簇的个数k,且该值的选择会影响到最终聚类效果。
对于非凸的簇结构,K-means算法的表现不佳,容易陷入局部最优解。
初始的簇中心点的随机选择可能导致不同的聚类结果。
uci数据集网站上适合kmeans聚类算法分析的数据集
-
Iris数据集:这个数据集包含3个不同品种的鸢尾花的测量数据。每个样本有4个属性(花萼长度、花萼宽度、花瓣长度和花瓣宽度)。
-
Wine数据集:这个数据集包含三个不同来源的葡萄酒的测量数据。每个样本有13个属性,包括酸度、酒精含量等。
-
Seeds数据集:这个数据集包含三种小麦种子的测量数据。每个样本有7个属性,包括面积、周长等。
-
Wholesale customers数据集:这个数据集包含批发客户的购买数据。每个样本有8个属性,包括生鲜、牛奶、杂货等。
-
Abalone数据集:这个数据集包含贝类的测量数据。每个样本有8个属性,包括性别、直径、高度等。
-
Diabetes数据集:这个数据集包含糖尿病患者的测量数据。每个样本有8个属性,包括血糖、BMI等。
-
Heart Disease数据集:这个数据集包含心脏病患者的医学数据,每个样本有14个属性,包括年龄、性别、血压等。
-
Credit Card数据集:这个数据集包含信用卡客户的购买数据,每个样本有17个属性,包括客户年龄、性别、账单金额等。
-
Breast Cancer数据集:这个数据集包含乳腺癌患者的医学数据,每个样本有30个属性,包括肿块大小、形状、质地等。
-
Fashion-MNIST数据集:这个数据集包含10种不同类型的时尚服装图像数据,每个样本是一张28*28像素的灰度图像,共70000个样本。
以 Iris数据集这个简单的数据集为例做一个k-means聚类分析的完整代码
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
# 定义K-means算法函数
def kmeans(X, k, max_iter):
# 随机选择k个数据点作为聚类中心
centroids = X[np.random.choice(len(X), k, replace=False), :]
# 初始化簇类别
labels = np.zeros(len(X))
# 迭代K-means算法
for _ in range(max_iter):
# 计算每个样本到每个聚类中心的距离
distances = np.sqrt(((X - centroids[:, np.newaxis])**2).sum(axis=2))
# 更新样本所属的簇类别
new_labels = np.argmin(distances, axis=0)
# 判断簇类别是否改变
if (new_labels == labels).all():
break
else:
labels = new_labels
# 更新聚类中心
for i in range(k):
centroids[i] = X[labels == i].mean(axis=0)
return centroids, labels
# 读取数据集
iris = pd.read_csv('https://archive.ics.uci.edu/ml/machine-learning-databases/iris/iris.data', header=None)
# 设置数据集的列名
iris.columns = ['sepal_length', 'sepal_width', 'petal_length', 'petal_width', 'class']
# 获取特征数据
X = iris.iloc[:, :-1].values
# 设置K值和最大迭代次数
k = 3
max_iter = 100
# 调用K-means算法函数
centroids, labels = kmeans(X, k, max_iter)
# 绘制聚类结果
colors = ['r', 'g', 'b']
for i in range(len(X)):
plt.scatter(X[i][0], X[i][1], c=colors[labels[i]], s=50)
plt.scatter(kmeans.centroids[:, 0], kmeans.centroids[:, 1], c='k', marker='x', s=100)
plt.xlabel('Sepal length')
plt.ylabel('Sepal width')
plt.show()
代码2
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
# 读取数据集
iris = pd.read_csv('https://archive.ics.uci.edu/ml/machine-learning-databases/iris/iris.data', header=None)
# 设置数据集的列名
iris.columns = ['sepal_length', 'sepal_width', 'petal_length', 'petal_width', 'class']
# 获取特征数据
X = iris.iloc[:, :-1].values
# 定义K-means算法
class KMeans:
def __init__(self, n_clusters=3, max_iter=300):
self.k = n_clusters # 聚类数量
self.max_iter = max_iter # 最大迭代次数
def fit(self, X):
# 初始化聚类中心点
self.centroids = X[np.random.choice(X.shape[0], self.k, replace=False)]
# 迭代聚类直到收敛或达到最大迭代次数
for i in range(self.max_iter):
# 计算每个样本到聚类中心点的距离
distances = np.sqrt(((X - self.centroids[:, np.newaxis])**2).sum(axis=2))
# 分配样本到最近的聚类中心点
self.labels = np.argmin(distances, axis=0)
# 更新聚类中心点
for j in range(self.k):
self.centroids[j] = np.mean(X[self.labels == j], axis=0)
def predict(self, X):
# 预测新样本所属的聚类
distances = np.sqrt(((X - self.centroids[:, np.newaxis])**2).sum(axis=2))
return np.argmin(distances, axis=0)
# 初始化K-means聚类器
kmeans = KMeans(n_clusters=3)
# 训练模型
kmeans.fit(X)
# 预测类别
labels = kmeans.predict(X)
# 绘制聚类结果
colors = ['r', 'g', 'b']
for i in range(len(X)):
plt.scatter(X[i][0], X[i][1], c=colors[labels[i]], s=50)
plt.scatter(kmeans.centroids[:, 0], kmeans.centroids[:, 1], c='k', marker='x', s=100)
plt.xlabel('Sepal length')
plt.ylabel('Sepal width')
plt.show()
解释:
代码一的写法–函数
X = iris.iloc[:, :-1].values
这行代码将Iris数据集中除了最后一列的所有数据提取出来,也就是样本的特征值,赋值给变量X。其中,:,:-1的意思是取所有行(:),但是取列时只取到最后一列的前一列(:-1),即除了最后一列的所有列,也就是样本的特征值所在的列。values属性则将Dataframe转换成NumPy数组,这样便于后续的计算和处理。
- iloc是Pandas库中用于按照位置索引选取数据的方法。它的全称是“integer-location based indexing”,即整数位置定位索引。
- iloc方法可以接收两个参数,第一个参数表示所选取数据所在的行位置,第二个参数表示所选取数据所在的列位置。例如,iloc[0, 1]表示选取第0行第1列的数据。
- 在Iris数据集中,iloc[:, :-1]表示选取所有行(:)和除了最后一列以外的所有列(:-1),即选取所有样本的特征值所在的列。
# 随机选择k个数据点作为聚类中心
centroids = X[np.random.choice(len(X), k, replace=False), :]
这行代码是在KMeans类的fit方法中的第一步,它的作用是从数据集中随机选择k个样本作为初始聚类中心。具体解释如下:
- X:在KMeans聚类算法中,X是一个包含多个样本的数据集,每个样本由多个特征值组成,通常表示为一个二维数组。在Iris数据集的例子中,X是一个150x4的数组,其中每个样本有4个特征,即花萼长度、花萼宽度、花瓣长度和花瓣宽度。可以将X看作是一个由150个样本组成的样本集合,其中每个样本由4个特征值组成。
- X可以是dataframe类型
- 在Python的数据科学生态系统中,Pandas是一个非常流行的数据处理库,它提供了DataFrame对象,可以方便地处理和分析表格数据。DataFrame对象本质上是一个二维标签数组,可以包含多个数据类型。因此,如果你的数据集是以DataFrame对象的形式存在的,那么可以将其转换为NumPy数组并将其传递给KMeans算法。例如,在使用scikit-learn库中的KMeans算法时,可以使用DataFrame的values属性将其转换为NumPy数组,如下所示:
- iris_df是一个包含Iris数据集的Pandas DataFrame对象。iris_df.values[:, :-1]将DataFrame对象转换为NumPy数组,并且只保留所有行和除最后一列之外的所有列,即提取Iris数据集的所有特征值。最后,这些特征值被用作输入数据来构建和训练KMeans模型。
- X = iris_df.values[:, :-1]
iris_df是一个Pandas DataFrame对象,其中包含Iris数据集中所有的样本和它们的特征。values是一个属性,它返回一个NumPy数组,该数组包含DataFrame中存储的数据。因此,iris_df.values返回一个150x5的NumPy数组,其中包含150个样本和它们的4个特征值,以及一个包含每个样本所属类别的列。
为了将数据集的特征值提取出来,我们使用切片操作[:, :-1]。:表示选取所有的行,:-1表示选取除了最后一列之外的所有列。因此,iris_df.values[:, :-1]返回一个150x4的NumPy数组,其中包含Iris数据集中所有的样本和它们的4个特征值。这个NumPy数组被赋值给变量X,并将用于KMeans聚类算法的输入。 - 参数KMeans(n_clusters=3, random_state=0)
KMeans是scikit-learn库中实现的一种基于距离的聚类算法,用于将数据集分成k个簇。这里是对KMeans函数中的两个参数的解释:- n_clusters:指定聚类的个数,即将数据集划分为多少个簇。在这里,n_clusters=3表示我们希望将Iris数据集划分为3个簇。
- random_state:用于设置随机种子,以确保每次运行算法时得到的结果是一致的。如果不设置该参数,每次运行时将使用不同的随机种子,得到不同的结果。在这里,random_state=0表示我们使用随机种子0来初始化KMeans算法,以确保每次运行时得到相同的结果。
- X可以是dataframe类型
import pandas as pd
from sklearn.cluster import KMeans
# 读取数据集
iris_df = pd.read_csv('iris.csv')
# 提取特征值
X = iris_df.values[:, :-1]
# 构建KMeans模型
kmeans = KMeans(n_clusters=3, random_state=0)
# 训练模型
kmeans.fit(X)
-
np.random.choice(len(X), k, replace=False):np.random.choice()函数是NumPy提供的从给定的序列X中随机选择指定k数量的元素的函数,这里我们使用它从数据集X中随机选择k个样本的索引,这些索引会用来选择k个样本作为聚类中心。
-
np.random.choice()函数有三个参数,它们的含义如下:
-
第一个参数:表示从序列X中进行随机采样的样本总数。在这里,在这里,我们想要从X中随机选择k个数据点作为聚类中心,因此我们需要从X中选择样本作为聚类中心,而不是从某个特定的列或行中选择样本。X是一个NumPy数组,它的第一个维度包含了样本的数量,因此len(X)等于数据集中的样本总数,我们可以将其作为np.random.choice函数的第一个参数。
-
第二个参数:表示需要选择多少个元素。k是聚类的数量,需要根据问题的需要进行指定。在KMeans算法中,聚类数量是必选的一个参数,我们需要根据问题的具体情况来决定聚类的数量。通常我们可以通过试验不同的聚类数量,并评估每个聚类数量的聚类结果的质量,来选择最优的聚类数量。在本例中,我们将k设置为3,因为Iris数据集中有3个不同的品种。
-
第三个参数:表示是否可以重复选择。如果该参数为True,则可以多次选择同一个元素,否则只能选择一次。在这里,replace=False表示不可以重复选择,即每个选择的元素只能出现一次。这是因为在聚类中心的选择中,我们不希望选择重复的样本。
-
-
np.random.choice(len(X), k, replace=False) 返回的是一个长度为k的随机索引数组,其中每个索引值代表X中的一个样本。我们将这个随机索引数组作为X数组的第一个维度索引,从而获取到对应的k个样本的特征值。例如,如果np.random.choice(len(X), k, replace=False)返回了[0, 2, 4]这个数组,那么X[np.random.choice(len(X), k, replace=False), :]就会返回X数组中第0、2、4个样本的特征值。
也就是说:
在对数据进行聚类之前,我们需要先选择 k k k个初始的聚类中心,我们将这些初始的聚类中心存储在centroids数组中。其中,每个聚类中心是一个 n n n维向量, n n n是样本特征的数量。我们从样本中随机选择 k k k个样本,然后从它们的特征中提取出来,组成一个 k × n k \times n k×n的数组。具体地,我们可以先生成一个长度为len(X)的随机索引数组,其中每个索引值代表 X X X中的一个样本,然后从中随机选择 k k k个不重复的索引值,这样就得到了 k k k个随机选择的样本的索引数组。我们将这个随机索引数组作为X数组的第一个维度索引,使用:代表第二个维度索引(即所有的特征维度),从而获取到这 k k k个样本的特征值。最终得到的centroids数组就是这 k k k个样本的特征值组成的数组,它们被作为初始的聚类中心。
k行n列二维数组::
import numpy as np
# 随机选择k个数据点作为聚类中心
centroids = X[np.random.choice(len(X), k, replace=False), :]
代码2的写法–类
k行n列二维数组:写法2
self.centroids = X[np.random.choice(X.shape[0], self.k, replace=False)]
- len(X) 和 X.shape[0] 都是表示样本数量的,所以这里两者都可以使用。实际上,X.shape[0] 更常用,因为它适用于多维数组的情况。在实际使用中,两者没有本质的区别。
- self.centroids是KMeans类的一个属性,用于存储聚类中心点。在KMeans类的实例化过程中,我们并没有为其手动赋值,因此在fit方法中需要对其进行初始化。同时,我们需要在后续的迭代过程中不断更新聚类中心点,因此将其设为类的属性是比较方便的做法。
- 具体来说,代码中的np.random.choice(X.shape[0],self.k,replace=False)用于生成一个长度为k的随机整数数组,其中每个整数都是在0到X.shape[0]-1之间随机选择的,且不重复。这个随机整数数组用于从矩阵X中选择k个样本作为聚类中心点,即X[np.random.choice(X.shape[0],self.k,replace=False)]。这里使用了numpy的高级索引功能,可以根据指定的行索引从矩阵X中选取相应的行,从而得到k个聚类中心点。
欧式距离
欧式距离是一种常见的距离度量方法,用于计算两个向量之间的距离。它定义为两个向量之间的欧几里得距离,即两个向量对应元素差的平方和的平方根。
假设有两个向量 X = ( x 1 , x 2 , . . . , x n ) X = (x_1, x_2, ..., x_n) X=(x1,x2,...,xn) 和 Y = ( y 1 , y 2 , . . . , y n ) Y = (y_1, y_2, ..., y_n) Y=(y1,y2,...,yn),它们的欧式距离 d ( X , Y ) d(X, Y) d(X,Y) 可以表示为:
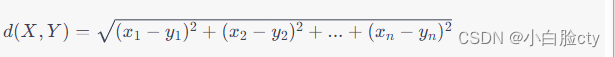
其中, n n n 表示向量的长度。在机器学习和数据挖掘中,欧式距离常被用于特征向量之间的相似性度量和聚类算法中。
矩阵减法–线代
矩阵的减法是指对应元素相减得到一个新的矩阵。若有两个矩阵 A A A 和 B B B,其中 A A A 的形状为 m × n m\times n m×n, B B B 的形状为 m × n m\times n m×n,则它们的差矩阵 C = A − B C=A-B C=A−B 的形状也为 m × n m\times n m×n。具体而言, C C C 中的每一个元素 c i , j c_{i,j} ci,j 都等于 A A A 和 B B B 中对应位置的元素相减所得,即:
 其中 a i , j a_{i,j} ai,j 和 b i , j b_{i,j} bi,j 分别表示 A A A 和 B B B 中第 i i i 行第 j j j 列的元素。
其中 a i , j a_{i,j} ai,j 和 b i , j b_{i,j} bi,j 分别表示 A A A 和 B B B 中第 i i i 行第 j j j 列的元素。
需要注意的是,矩阵减法要求两个矩阵的形状相同,否则无法进行减法运算。
-本例中, X X X 和 s e l f . c e n t r o i d s self.centroids self.centroids 分别是形状为 ( m , n ) (m, n) (m,n) 和 ( k , n ) (k, n) (k,n) 的矩阵,其中 m m m 是样本数, n n n 是特征数, k k k 是聚类中心数。为了进行矩阵减法,需要对其中一个矩阵增加一个新的维度,使其形状变为 ( k , 1 , n ) (k, 1, n) (k,1,n),然后将其与另一个矩阵 ( m , n ) (m, n) (m,n) 进行减法运算。在这里,我们使用了 NumPy 的广播规则,使得在减法运算中, ( k , 1 , n ) (k, 1, n) (k,1,n) 的矩阵会被广播为 ( k , m , n ) (k, m, n) (k,m,n),然后再对应相减,得到一个新的矩阵,其形状为 ( k , m , n ) (k, m, n) (k,m,n)。
这个过程可以用下面的公式表示:
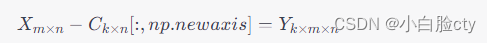
其中, X X X 是原始数据矩阵, C C C 是聚类中心矩阵, Y Y Y 是进行减法运算得到的新矩阵, [ : , n p . n e w a x i s ] [:, np.newaxis] [:,np.newaxis] 表示在矩阵 C C C 中增加一个新维度。
k-means算法中的矩阵减法
在K-Means算法中,每个样本点的特征向量就是由该样本在每个特征维度上的取值所组成的一维向量,假设有 n n n 个特征,则每个样本点的特征向量就是一个 n n n 维向量。
聚类中心的特征向量也是由聚类中心在每个特征维度上的取值所组成的一维向量,因为聚类中心是由一组样本点的特征向量均值计算得到的,所以聚类中心的特征向量也是一个 n n n 维向量。
举一个简单的例子说明一下
假设我们有3个样本点和2个聚类中心。每个样本点有2个特征,那么它们的特征向量就是2维的。每个聚类中心也有2个特征,因为我们的样本点有2个特征。
样本点的特征向量可以表示为 ( x 1 , x 2 ) (x_{1}, x_{2}) (x1,x2) 的形式,聚类中心的特征向量可以表示为 ( c 1 , c 2 ) (c_{1}, c_{2}) (c1,c2) 的形式。
假设我们的样本点和聚类中心的特征向量分别如下:
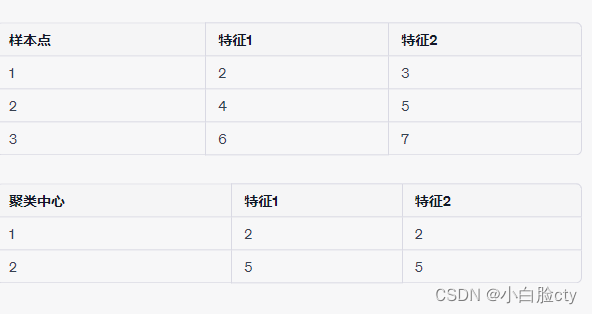 那么,我们可以将样本点的特征向量和聚类中心的特征向量分别放到一个矩阵中,形状为 ( 3 , 2 ) (3,2) (3,2) 和 ( 2 , 2 ) (2,2) (2,2),分别表示样本点和聚类中心的个数及其特征数量。然后,将样本点矩阵和聚类中心矩阵相减,得到一个新的矩阵,其形状为 ( 2 , 3 , 2 ) (2, 3, 2) (2,3,2),即聚类中心数、样本数、特征数。
那么,我们可以将样本点的特征向量和聚类中心的特征向量分别放到一个矩阵中,形状为 ( 3 , 2 ) (3,2) (3,2) 和 ( 2 , 2 ) (2,2) (2,2),分别表示样本点和聚类中心的个数及其特征数量。然后,将样本点矩阵和聚类中心矩阵相减,得到一个新的矩阵,其形状为 ( 2 , 3 , 2 ) (2, 3, 2) (2,3,2),即聚类中心数、样本数、特征数。
这个新的矩阵可以表示为:
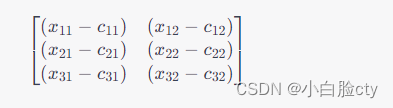
其中 ( x i 1 − c j 1 ) (x_{i1}-c_{j1}) (xi1−cj1) 表示第 i i i 个样本点的第一个特征减去第 j j j 个聚类中心的第一个特征, ( x i 2 − c j 2 ) (x_{i2}-c_{j2}) (xi2−cj2) 表示第 i i i 个样本点的第二个特征减去第 j j j 个聚类中心的第二个特征。
因此,在计算距离时,需要将每个样本点的 n n n 维特征向量与每个聚类中心的 n n n 维特征向量进行相减,得到一个新的 n n n 维向量,表示该样本点与该聚类中心在每个特征维度上的距离,最终将这些距离求平方、相加、开根号,即可得到该样本点到该聚类中心的距离。
本例代码实现
distances = np.sqrt(((X - self.centroids[:, np.newaxis])**2).sum(axis=2))
首先, X X X 和 s e l f . c e n t r o i d s self.centroids self.centroids 都是矩阵。假设 X X X 的形状为 ( m , n ) (m, n) (m,n),即有 m m m 个样本,每个样本有 n n n 个特征; s e l f . c e n t r o i d s self.centroids self.centroids 的形状为 ( k , n ) (k, n) (k,n),即有 k k k 个聚类中心,每个聚类中心也有 n n n 个特征。为了计算每个样本到聚类中心的距离,我们需要进行矩阵减法,即对 X X X 和 s e l f . c e n t r o i d s self.centroids self.centroids 中的每个元素对应相减,得到一个新的矩阵,其形状为 ( k , m , n ) (k, m, n) (k,m,n)。
[:, np.newaxis]的解释
在 numpy 中,如果我们想要改变数组的维度或者增加一个新的维度,可以使用 np.newaxis。它的作用是在数组的维度中增加一个新的轴。
在这个代码中,我们使用了 self.centroids[:, np.newaxis],这表示在 self.centroids 矩阵的第二个维度上增加了一个新的轴,使得其变成了一个形状为 (k, 1, n) 的三维数组。这样做的目的是为了能够与 X 矩阵 (m, n) 进行相减操作,以计算每个样本点与聚类中心的距离。
为什么形状为 (k, 1, n) 的三维数组可以和X 矩阵 (m, n) 进行相减操作?
-
在 Numpy 中,如果两个数组的形状不完全相同,它们可能会进行广播 (broadcasting) 操作。广播操作是指将较小的数组沿着缺失的维度进行复制,使得它们形状相同,然后进行相应的计算。在本例中,形状为 (k, 1, n) 的三维数组被复制成形状为 (k, m, n) 的数组,然后才能与形状为 (m, n) 的 X 矩阵进行相减操作。这个过程就是广播操作。
-
numpy 广播的规则是,两个数组的形状在每个维度上要么相同,要么其中一个为1,才能进行广播。在对形状为 (k, n) 的数组进行广播时,只能在最后一个维度上进行广播,而不能在第二个维度上进行广播,因为第二个维度的大小是 m,不是 1。因此需要添加一个新维度才能进行正确的广播。
-
具体来说,当进行两个数组相减时,Numpy 会从最后一个维度开始比较它们的形状,如果相同或其中一个为1,则认为是可以广播的。如果两个数组的形状不同,并且它们在某些维度上不兼容,则会在这些维度上进行复制,直到形状匹配为止。因此,形状为 (k, 1, n) 的三维数组被复制成形状为 (k, m, n) 的数组,这样就能与形状为 (m, n) 的 X 矩阵进行相减操作了。
X - self.centroids[:, np.newaxis]:
对样本点和聚类中心点进行广播计算,每个样本点都与所有聚类中心进行了减法操作。
(X - self.centroids[:, np.newaxis])**2
计算每个样本点与每个聚类中心之间的差的平方,并将结果保存在一个形状为 (k, m, n) 的三维数组中,其中第一个维度表示聚类中心,第二个维度表示样本点,第三个维度表示特征值。
.sum(axis=2)
对第三个维度上的特征值进行求和,得到一个形状为 (k, m) 的二维数组,其中每个元素表示一个样本点与一个聚类中心之间的差的平方的和。
np.sqrt()
对所有元素取平方根,得到一个形状为 (k, m) 的距离矩阵,其中每个元素表示一个样本点与一个聚类中心之间的欧式距离。
广播规则
举个例子来讲解。
假设有一个矩阵 X,其形状为 (3, 2),也就是有 3 个样本点,每个样本点有 2 个特征,如下所示:
X = [[1, 2],
[3, 4],
[5, 6]]
现在我们有一个聚类中心数组,其形状为 (2,),也就是有 2 个特征值,如下所示:
centroids = [0, 1]
如果我们想将 centroids 广播到 X 上进行矩阵减法,那么需要将其形状扩展成和 X 相同的形状。由于 X 的形状为 (3, 2),因此需要将 centroids 扩展成形状为 (1, 2) 或者 (2, 1) 或者 (1, 1, 2) 或者 (1, 2, 1) 或者 (2, 1, 1) 或者 (2, 1, 2) 或者 (1, 2, 2) 等等,只要在第二个维度上有一个 2 就可以。这里我们选择形状为 (1, 2) 的数组。
那么扩展后的 centroids 数组为:
centroids_new = [[0, 1]]
减法的结果为:
result = [[ 1, 1],
[ 3, 3],
[ 5, 5]]
可以看到,这里得到的 result 和我们之前的例子中得到的 (2, 2) 矩阵相同。这是因为对于矩阵减法来说,广播的形状只需要在对应的维度上相同即可,其余维度的长度可以自动扩展或者缩减。
为什么可以将 centroids 扩展成形状为 (1, 2) 或者 (2, 1) 或者 (1, 1, 2) 或者 (1, 2, 1) 或者 (2, 1, 1) 或者 (2, 1, 2) 或者 (1, 2, 2) 等等这么多种形状?
在 Numpy 中,可以在任何一个维度上扩展数组的形状,只要符合广播规则即可。在这里,我们需要将形状为 (2,) 的数组扩展为和 X 相同的形状,因此需要在某些维度上进行扩展,以满足广播规则。
具体而言,我们需要将形状为 (2,) 的数组扩展成形状为 (m, 2) 或者 (1, 2) 或者 (k, 2) 或者 (1, k, 2) 或者 (m, k, 2) 等等,只要这些形状满足以下条件:
扩展后的形状中,所有维度的大小都必须相等或者其中一个维度的大小为 1。
对于所有维度大小大于 1 的数组,它们的大小必须相等。
例如,(m, 2) 表示扩展成形状为 (m, 2) 的数组,其中第一个维度的大小与 X 相同,第二个维度的大小为 2。这个形状满足广播规则,因为第一个维度的大小相同,第二个维度的大小为 2,可以匹配 X 的第二个维度的大小为 2。
同样地,(1, 2) 表示扩展成形状为 (1, 2) 的数组,其中第一个维度的大小为 1,第二个维度的大小为 2。这个形状也满足广播规则,因为第一个维度的大小为 1,可以匹配 X 的任意维度的大小为 1 或者 X 的第一个维度的大小为 m。
其他形状也是类似的,只要符合广播规则,就可以扩展为相应的形状。
对于一个形状为 (k, n) 的数组,在进行广播操作时,可以在任何维度上进行广播,只要在其他维度上的大小能够匹配。因此,可以将这个数组扩展成任何一个形状为 (a, b, c, …, k, …, z) 的数组,只要在维度 k 上进行广播即可。
具体来说,以 (k, n) 扩展成形状为 (1, 2) 的数组为例,可以在第二个维度上进行广播,也就是扩展成 (k, 1, n) 的形状,然后再在第二个维度上进行广播,得到形状为 (1, 2) 的数组。同理,也可以在其他维度上进行广播,得到其他形状的数组。
综上所述,扩展数组的形状并不唯一,只要在需要广播的维度上进行扩展即可。
分配样本到最近的聚类中心点
self.mins = np.argmin(distances, axis=0)
- np.argmin 函数返回数组中最小值的索引值,axis=0 表示按列方向进行比较。
- distances 是一个形状为 (k, m)的二维数组,其中 k 表示聚类中心的数量,m 表示样本的数量。distances 中每一列表示一个样本到所有聚类中心的距离。我们需要将每个样本分配到距离它最近的聚类中心。
- 对于每个样本,我们可以通过在 distances 的每一列中找到最小值来找到它距离最近的聚类中心。np.argmin 函数返回最小值的索引值,即对应的聚类中心的索引。
- 因此,self.mins 中的每个值表示对应样本所属的聚类中心的索引。最终得到的 self.mins是一个长度为 m 的一维数组,其中每个值表示对应样本所属的聚类中心的索引。
更新聚类中心点
for j in range(self.k):
self.centroids[j] = np.mean(X[self.mins== j], axis=0)
在KMeans算法中,每个聚类中心点的位置由其所关联的所有样本的平均值来确定。因此,对于每个聚类中心点,我们需要找到其关联的所有样本,并计算这些样本的平均值。具体地,对于第 j j j 个聚类中心点,我们可以使用以下代码来计算其关联的所有样本的平均值:
X[self.mins == j] # 选出所有属于第 j 个聚类的样本
np.mean(X[self.mins == j], axis=0) # 计算这些样本的平均值
- np.mean(X[self.mins== j], axis=0) 返回的是所有属于第 j 个聚类的样本在各个特征维度上的平均值,即一个长度为 n 的一维数组,其中 n 为特征维度的数量。这个一维数组可以作为第 j 个聚类的新中心点。
- self.centroids[j] 是表示第 j 个聚类的聚类中心点,它是一个 n n n 维的向量,其中 n n n 表示特征的数量。在 K-Means 算法的迭代过程中,self.centroids[j] 会被不断更新为该聚类所有样本的平均值。
X[self.mins== j] 表示选出所有属于第 j j j 个聚类的样本,这里使用了布尔索引,self.labels == j 会返回一个布尔数组,其中第 i i i 个元素表示样本 i i i 是否属于第 j j j 个聚类。然后,使用 np.mean 函数对这些样本沿第0个轴(即对样本数量进行平均)计算平均值,即可得到第 j j j 个聚类中心点的新位置。
因此 ,在循环中,对于每个聚类中心点,我们都可以使用上述代码来计算其新位置,并将其更新到 self.centroids[j] 中。
为什么对样本数量进行平均可以得到该聚类所有样本的平均值,作为该聚类的新中心点。?
聚类算法的目标是将相似的样本分配到同一聚类中,并使聚类内的样本尽可能接近聚类中心点。因此,在更新聚类中心点时,我们可以计算该聚类中所有样本的平均值作为新的聚类中心点,因为该平均值可以代表聚类中所有样本的特征。当我们将新的聚类中心点用于下一轮迭代时,它将更好地代表该聚类中的所有样本,从而更好地将相似的样本分配到同一聚类中,进一步优化聚类效果。
对样本数量进行平均的结果是该聚类所有样本在每个特征上的平均值,这个平均值作为该聚类的新中心点。
例如,假设有一个二维空间中的聚类,其中包含了三个样本点 (1, 2),(3, 4) 和 (5, 6)。那么这三个样本在第一个特征上的平均值为 (1+3+5)/3 = 3,在第二个特征上的平均值为 (2+4+6)/3 = 4。因此,该聚类的新中心点为 (3, 4)。
predict函数
def predict(self, X):
# 预测新样本所属的聚类
distances = np.sqrt(((X - self.centroids[:, np.newaxis])**2).sum(axis=2))
return np.argmin(distances, axis=0)
-
predict() 函数用于对新的未标记数据进行分类,即将其分配给最近的聚类中心。在聚类算法中,fit()
函数是用来拟合模型的,即通过训练数据学习聚类中心并对数据进行聚类。而 predict()
函数则用于对新数据进行预测。在预测时,使用已经训练好的聚类中心对新数据进行分类。因此,当我们有新的未知数据需要分类时,就可以使用
predict() 函数对其进行分类。 -
predict 函数是用来对新的样本进行聚类预测的。它接受一个新的样本数据集
X,并返回一个数组,其中包含每个新样本所属的聚类标签。实现过程与 fit
函数中计算样本到聚类中心点距离的方式相同,只不过这里不需要更新聚类中心点,而是根据距离找到最近的聚类中心点并返回其对应的聚类标签。具体来说,代码中distances 变量计算了新样本 X 到聚类中心点的距离,然后 np.argmin(distances, axis=0)找到每个新样本距离哪个聚类中心点最近,从而得到每个新样本所属的聚类标签。 -
在使用 predict 方法时,不需要再次更新聚类中心点,因为聚类中心点已经在 fit 方法中被计算出来并且保存在 self.centroids 中了。在预测新的样本所属的聚类时,只需要计算新样本与已有聚类中心点之间的距离,并返回距离最近的聚类的标签即可。因此,在 predict 方法中不需要进行聚类中心点的更新。
绘制聚类效果
# 绘制聚类结果
"定义了一个包含三种颜色的列表,用于后续的绘图。"
colors = ['r', 'g', 'b']
"""
循环遍历所有样本,对每个样本绘制一个散点图,其中x轴为样本的第一个特征值,y轴为样本的第二个特征值,点的颜色由该样本所属的聚类决定,s参数控制散点的大小。
"""
for i in range(len(X)):
plt.scatter(X[i][0], X[i][1], c=colors[labels[i]], s=50)
"绘制聚类中心点的散点图,用黑色叉号标记,s参数控制叉号的大小。"
plt.scatter(kmeans.centroids[:, 0], kmeans.centroids[:, 1], c='k', marker='x', s=100)
plt.xlabel('Sepal length')
plt.ylabel('Sepal width')
plt.show()
使用 plt.scatter 函数在当前的绘图中画出了聚类中心点
- kmeans.centroids[:, 0] 表示取聚类中心点在所有样本的第一维的坐标,即横坐标。
- kmeans.centroids[:,1] 表示取聚类中心点在所有样本的第二维的坐标,即纵坐标。
- c=‘k’ 表示使用黑色作为聚类中心点的颜色。
- marker='x’表示使用"x"作为聚类中心点的标记。
- s=100 表示聚类中心点的大小为100。
- 数据有n(n>=2)个特征,那么就需要在绘制散点图时选择2个特征来表示每个样本点的位置。在KMeans聚类中,我们通常是将数据降维至2维或者3维,以便于可视化观察聚类效果。在这种情况下,您可以选择两个最具代表性的特征,或者使用一些特征选择算法来挑选最具区分性的特征进行可视化。
- c=colors[labels[i]-1]:
如果标签只有1,2,3,而 i=0,1,2,3,4,5,6,7,8,9…,那么当 i=0 时,用的是第一个标签值,即0,当 i=1 时,用的是第二个标签值,即1,以此类推。当 i=3 时,用的是第四个标签值,由于标签只有0,1,2,所以用的又是标签0。当 i=4 时,又回到了第一个标签值,即1,以此循环。因此,对于任意一个样本的标签值,都可以通过 i%3 来得到。
而colors的[0,1,2]对应颜色[‘r’, ‘g’, ‘b’]