目录:
爬虫之国内音乐爬取
一、设计思路
二、使用资源
三、具体代码编写
四、优化空间
五、应用
一、设计思路
1、选取目标音乐平台
2、获取目标的关键信息,如音乐接口信息、音乐名称和大小
3、分析接口属性,对这些信息做提取,获取到有用信息,存放在字典或者列表里
4、对数据进行处理和操作,如访问下载、保存命名
5、回顾整个编写过程,优化结构,整理归类。

二、使用资源
1、requests库、urllib库、lxml库,bs4库,tqdm进度条神器及其它自带库
2、Python3+Windows执行环境
3、网抑云云平台、其它平台音乐集地址
三、具体代码编写

选择平台
网易云反爬做的较好,去其它小站快捷获取。
发现了以前的通用接口几乎不可用,新接口变化挺大。
拿到网易接口的时候是挺高兴的,但是Post要提交的表单信息不知道每首歌是不是一样的,
在我总是去找ID的时候,看到表单几乎不敢相信,这个是啥
。。。上图。。。
于是,我想到了是否每首歌的前面那一大串是否是一样的。。。
还是先拿到ID再说吧,

看到通过requests访问到的ID内容是隐藏的,
=====!
网抑云让人忧郁。。。(虽然可以通过selenium以用户方式在已解码的网页上访问拿到ID)
但是还是顺其自然,去其它平台搞一搞。
果然,其它专业做音乐的,简单易懂,还没有防备之心!
对搜索结果页处理:
对歌曲详情页处理,获得下载链接:

所有方法归位后最终验证:
过程中遇到的部分问题:连接超时,是格式问题还是访问超时的时长设置 过短?让我们来看看!

最终fixed了上诉gif图的问题,并下载成功:

然后,封装到方法里,对代码进行格式化,并重命名方法和临时变量:
第一个方法:[url_music_name]
def url_music_name(name_put):
urlReady = "https://www.gequbao.com/s/" + name_put # 拉取音乐页面,获取音乐标签里的关键信息
site = requests.get(urlReady)
# bs方法获取标签内容
bs = BeautifulSoup(site.text, "lxml") # hml.parser解析不能对复杂内容处理,这里使用lxml
bs_tag = bs.select(".text-primary.font-weight-bold") # 通过class属性定位到标签
url_name_list = []
for url_and_name in bs_tag: # 测试限制了数据,记得改过来[:20]
url_name_list.append(str(url_and_name)[48:].strip(
r"\n </a>")) #
# 有换行,对其进行处理,处理后再来个循环进行链接与歌曲名的分割
out_array = []
for m in url_name_list:
url_str = m.split("\">")[0] # 很好,数据越来越短,离想提取的数据越来越近。这里利用切片和数组索引那到了第一个值
music_name_str = name_put + '_' + m.split("\">")[1][:-1]
out_array.append([url_str, music_name_str])
return out_array # 搜索歌手的结果列表,取到链接与歌曲名的数组第二个方法:[second_url_name]通过搜索具体歌名或者歌名+歌手的方式获取歌曲详情页的链接,然后可以从单个歌曲详情里提取单个歌曲的下载链接。
所以说还得是用requests,用selenium+webdriver那不得累死。。。
def second_url_name(name):
urlReady = "https://www.gequbao.com/s/" + name
site = requests.get(urlReady)
# bs方法获取标签内容
bs = BeautifulSoup(site.text, "lxml") # html.parser解析不能对复杂内容处理,这里使用lxml
bst_tag = bs.find_all('tr') # 通过tr标签匹配
print("\n【注意】:当搜索的是歌曲名时,为节省资源,\n 将仅下载搜索结果的前五首歌曲! ")
CertainContent = []
for urlMusicName in bst_tag[1:6]:
noReady = str(urlMusicName)[57:-56].split("\n")
# print(noReady)
CertainContent.append([noReady[0], noReady[-1]])
print("----------------")
second_array = []
for m, n in CertainContent:
urlStr = m.split("\">")[0] # 很好,数据越来越短,离想提取的数据越来越近。这里利用切片和数组索引那到了第一个值
MusicName = m.split("\">")[1]
singer = n.strip('<td class="text-success">')
MusicNameStr = MusicName + "_" + singer
# print(f"MusicName's Content is |{MusicNameStr}|")
second_array.append([urlStr, MusicNameStr]) # 添加到列表后,我们看看是不是真的提取到了这两个值
return second_array第三个方法:[getDownUrl]
header = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 Chrome/103.0.0.0 ' #
'Safari/537.36',
'accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,'
'application/signed-exchange;v=b3;q=0.9',
'accept-encoding': 'gzip, deflate, br'
}
# 想办法由列表数据,生成一个只含下载链接的数组
def getDownUrl(input_list=None):
if input_list is None:
input_list = [['music/81215', '笨小孩 (Live)'], ['music/37479', '忘情水(Live)']]
s = requests.session()
# 设置连接活跃状态为False
s.keep_alive = False
checklist = []
for xi, yi in input_list:
final_url = "https://www.gequbao.com/" + xi
response = requests.get(final_url, headers=header, timeout=100) # 超时
response.close()
down_url = re.findall(r'url = (.+)\.', response.text)[0].strip('\'').strip('\'').replace(r'amp;',
'') # 合理提取MP3链接
yi = yi.replace('...', '')
checklist.append([down_url, yi])
return checklist
# 中间用正则提取到了下载链接,即down_url以及未启用的selenium下载方式,因为其中多组按键操作里的ctrl+s操作时灵时不灵,有专业搞按键的童鞋可以帮忙看看:
# def SeleniumDown(list_for=None):
# from pykeyboard import PyKeyboard
# from pymouse import PyMouse
# k = PyKeyboard()
# mouse = PyMouse()
# xm, ym = mouse.screen_size() # 获取屏幕尺寸
# # print(xm,ym)
# # 继续通过访问页面,再获取页面下的链接来
# wd = webdriver.Chrome()
# action = ActionChains(wd)
#
# # 先打开一个基本页面
# urlencoded = "https://www.gequbao.com/s/%E5%88%98%E5%BE%B7%E5%8D%8E"
# wd.get(urlencoded) # 是否调用浏览器
# wd.maximize_window()
#
# # 拿到下载页的button
# downBtn = "//*[@id='btn-download-mp3']"
# if list_for is None:
# list_for = []
#
# # 循环调用下载详情页地址
# for content in list_for:
# detailUrl = "https://www.gequbao.com/" + content[0]
# after_string = str(random.randint(10, 20))
# print(content[1])
# detailMusicName = content[1] + after_string
#
# wd.get(detailUrl)
# handles = wd.window_handles
# wd.switch_to.window(handles[-1])
# wd.implicitly_wait(1.5)
# # 使用webdriver调用button点击下载
# wd.find_element(By.XPATH, downBtn).click() # 注释掉
# handles = wd.window_handles
# wd.switch_to.window(handles[-1])
# wd.implicitly_wait(2)
#
# # 随机定位浏览器播放页的元素
# # ele = "//body/video/source[@type='audio/mpeg']" # 选取任意元素
# # inputElement = wd.find_element(By.XPATH,ele) # 找不到元素
# # time.sleep(1)
# # playEle = wd.find_element(By.CSS_SELECTOR,css_selector)
# # playEle = wd.find_element(By.TAG_NAME,tag_name)
#
# # ctrl+s 保存当前文件。重复保存一次,并给予弹窗足够保留时间
# action.reset_actions()
# action.move_by_offset(xm / 2, ym / 2).click(None).perform() # 点击空白处
# # action.key_down(Keys.CONTROL).send_keys('s').key_up(Keys.CONTROL).perform()
# # print("------[1]------")
# # playEle.send_keys(Keys.CONTROL,'s')
# # print("------[2]------")
# k.press_key(k.control_key)
# k.tap_key("S", n=2, interval=1)
# k.release_key(k.control_key)
# time.sleep(3)
#
# # 输入歌名
# k.type_string(detailMusicName)
# # print("输入音乐保存名了。。。")
#
# # 联合点击Alt+s 快速定位到保存按钮: 替代回车键
# # inputElement.send_keys(Keys.ENTER)
# k.press_key(k.alt_key) # 按住alt键
# k.tap_key("S") # 单骑s键
# k.release_key(k.alt_key) # 释放alt键
#
# # 给两秒的下载时间
# time.sleep(2)
# # 慎用close操作
# # wd.close()
# print(f"执行了第{list_for.index(content) + 1}次")
# wd.quit()def displayProgress(module, totalsize, which):
"""
Dynamic display of progress
:param module:已经下载的数据块
:param totalsize:数据块的大小
:param which:远程文件的大小
:return:不用return,直接打印
"""
progressDown = module * totalsize * 100.0 / which
if progressDown > 100:
progressDown = 100
print("\r downloading: %.1f%%" % progressDown, end="")
def downloadMp3(uurl, singer_music):
if '.' in uurl[-6:]:
postfix = uurl.split(".")[-1]
else:
postfix = uurl.split("=")[-1]
MusicName = singer_music + "." + postfix
print(f'MusicName = {MusicName}')
downloadPath = "./" + input_name
try:
os.makedirs(input_name, exist_ok=True)
print("目录已创建!")
finally:
pass
downloadDir = downloadPath + "/" + MusicName
urlretrieve(uurl, downloadDir, displayProgress) # api接口的可以直接下,部分接口暂无法正常下载
print(" 下载完成!")上诉是通过urllib.request方法下载的。
接下来是正文,requests下载:
def fileDownloadUsingRequests(file_url, music_name):
"""It will download file specified by url using requests module"""
global r
# 处理文件后缀名
if file_url.count("=") >= 2:
file_suf = '.' + file_url.split('=')[-1]
else:
file_suf = '.' + file_url.split('.')[-1]
# 处理文件命名异常,非法命名无法保存到windows磁盘里
if "<" in music_name:
music_name = music_name.split("<")[0] # .replace("<",""),多了个斜杠
if "|" in music_name or "/" in music_name:
music_name = music_name.replace("/", "")
music_name = music_name.replace("|", "")
if True:
music_name = music_name.replace(r"amp;", "")
music_name = music_name.replace(r":", "")
file_name = music_name.replace(",", "") + file_suf
print(f"已获取歌名:{file_name}!")
pwd = os.path.join(os.getcwd(), input_name, file_name)
fileDir = os.path.join(os.getcwd(), input_name)
# print(pwd)
if not os.path.exists(fileDir):
os.mkdir(input_name)
print(f"目录'{input_name}'已创建!")
if os.path.exists(pwd):
print('File already exists')
return
try:
r = requests.get(file_url, stream=True, timeout=200)
except requests.exceptions.SSLError:
try:
response = requests.get(file_url, stream=True, verify=False, timeout=200)
print(f'连接状态:{response.status_code}')
except requests.exceptions.RequestException as e:
print(e)
quit()
except requests.exceptions.RequestException as e:
print(e)
quit()
chunk_size = 1024
total_size = int(r.headers['Content-Length'])
total_chunks = total_size / chunk_size
print('歌曲包totalsize:%.2fKB' % total_chunks)
file_iterable = r.iter_content(chunk_size=chunk_size)
# 用tqdm进度提示信息,包括执行进度、处理速度等信息,且可在一定程度上进行定制。
tqdm_iter = tqdm(iterable=file_iterable, total=total_chunks, unit='KB',
leave=False, colour='MAGENTA'
)
with open(pwd, 'wb') as f: # file_name
for data in tqdm_iter:
f.write(data) # 字节写入
# total_size=float(r.headers['Content-Length'])/(1024*1024)
'''
print 'Total size of file to be downloaded %.2f MB '%total_size
'''
f.close()
print('Downloaded file %s' % file_name)
print(print("------------------------------------\n")) # 因为是循环写入,加上换行,便于查看fileDownloadUsingRequests里面的内容分这几个部分,
1)从歌曲的播放地址里获得歌曲的格式,也就是后缀
2)处理文件命名异常,非法命名无法保存到windows磁盘里
3)预建立歌曲的下载地址和下载目录,下载地址通常是os.cwd()当前目录+歌曲名,为了方便管理,我们还把搜索关键字当作目录,所以小伙伴一定要正确去搜索歌曲哦~
4)异常处理
5)拿到响应头,将请求的迭代字节对象放入可迭代插件tqdm里
6)等待数歌,哦不,听歌即可。

来查看调用main的过程:
if __name__ == "__main__":
global input_name
# 搜歌手 和 搜歌名的方式结合后,去下载
print('\n小Tips:输入2后,按歌名+歌手名搜索。如搜索:"Mojito 周杰伦"')
while 1:
down_type = input("请输入搜索方式-- 1:歌手;2:歌名!:")
down_type = down_type.strip()
if down_type in ('1', '2'):
break
else:
print('请输入 1 或者 2 ')
while 1:
try:
input_name = input("请输入要搜索的内容:")
if input_name:
print('歌曲下载源的解析速率取决于源服务器效率,下载时长取决于歌曲大小,请耐心等待!')
break
finally:
pass
if down_type == "1":
get_now = getDownUrl(url_music_name(input_name))
if len(get_now) < 1:
print('暂未搜索到歌曲资源,请等待作者更新歌源!')
print('5秒钟后将会关闭下载通道~~~')
for i in range(5)[::-1]:
print(f'还剩 {i + 1} 秒!')
time.sleep(1)
else:
for du, dn in get_now:
fileDownloadUsingRequests(du, dn)
elif down_type == "2":
letGo = getDownUrl(second_url_name(input_name))
print(letGo)
if len(letGo) < 1:
print('暂未搜索到歌曲资源,请等待作者更新歌源!')
print('5秒钟后将会关闭下载通道~~~')
for i in range(5)[::-1]:
print(f'还剩 {i + 1} 秒!')
time.sleep(1)
else:
for mm, nn in letGo:
fileDownloadUsingRequests(mm, nn)
else:
print("Unknown error.Check ur code again pls.")
print("\n全部下载:已完成!<-- Author:HuZK --> 将在8秒后自动关闭窗口!")
for i in range(8)[::-1]:
print(f'还剩 {i + 1} 秒!')
time.sleep(1)
# time.sleep(8) # 打包成EXE文件必备停顿>>>下载完成,请在EXE所在目录(如果用的是工具)查看歌曲。
最精华的部分讲完,我们谈谈其它的。
请求五要素。

了解接口特点,对接口进行访问处理。
请求content-type的四种格式
text/xml -- 它是一种使用 HTTP 作为传输协议,XML 作为编码方式的远程调用规范。
它的使用也很广泛,如 WordPress 的 XML-RPC Api,搜索引擎的 ping 服务等等。JavaScript 中,也有现成的库支持以这种方式进行数据交互,能很好的支持已有的 XML-RPC 服务
application/json
用来告诉服务端消息主体是序列化后的 JSON 字符串。由于 JSON 规范的流行,除了低版本 IE 之外的各大浏览器都原生支持 JSON.stringify,服务端语言也都有处理 JSON 的函数,使用 JSON 不会遇上什么麻烦。
multipart/form-data
post数据的提交方式。如果传输的是文件,还要包含文件名和文件类型信息。消息主体最后以 –boundary– 标示结束
application/x-www-form-urlencoded
这应该是最常见的 POST 提交数据的方式了。浏览器的原生 form 表单,如果不设置 enctype 属性,那么最终就会以 application/x-www-form-urlencoded 方式提交数据。如果是get,必要时需要填入params,如果访问方式是post,必要时需要填入data内容。
传入的数据信息随响应格式的要求,需要进行格式化。
四、优化空间
1、多类别搜索下载:不光通过歌手搜索,通过歌曲搜索实现下载(歌曲的搜索下载又有不同)。
2、歌曲重复:下载的100首歌曲里,除了校验本地文件重复外,有些重复的歌曲,其实名字不尽相同,可以写个算法排除。
3、并行下载:歌曲的下载任务都是单程,并没有冲突,考虑实现并行下载。
5、内存优化:逻辑简化,也就是内存优化。
6、通用适配:如果在方法里内嵌多层校验,直到找到想要的下载地址为止,那就可以不局限于一个音乐平台了,可以是任意平台,只要能输入该音乐平台的地址,就能给用户自主选择去哪儿下载的空间。
目前优化项暂时做了第一条。
五、应用
比较selenium与requests在爬虫上的各个方向的优劣.
【比较接口测试与爬虫的区别】

·接口获取:
这个很好理解,接口测试的获取是现成的。而爬虫需要自己找接口,没有接口时,需要绕开接口,使用其它技术手段实现,如页面获取、点击操作、图片识别等方式。
·接口对接:
接口对接,参照接口文档,用什么方式或信息建立有效连接,有的需要认证,按照标准提供认证信息即可。
而爬虫一般需要伪装user-agent,并需要知道接口对接的方式,需要哪些关键信息。有时候为了应对服务器封杀,还要变换IP,并控制访问频率。
·接口数据格式化处理:
有序格式,按序列提取关键参数。
无需格式,需要做校验与判断,并分层提取关键参数。
·接口信息的应用:
普通接口主要用于前后端数据交互,或者对外开放API,适配多终端实时获取数据。
爬虫的应用:比较有业务价值,主要用于获取目标信息,并能提供海量数据互相比较,如果能分门别类,就是搜索引擎的雏形;如果能做数据仓库和开发,就是大数据的开端;如果能不停歇批量地访问可配置接口,就是压力攻击。综上所述,用的好的时候,可以说是大数据及数字化的前一步。
·对企业产生的价值:
接口对企业价值:使用户可以在多终端访问并使用公司提供的服务,且能存储重要信息。连接客户,连接企业,连接数据。
爬虫对企业:帮助寻找目标商品或者酒店最优惠的价格。根据点击量和有效阅读数,生成热搜或者其它排行榜。
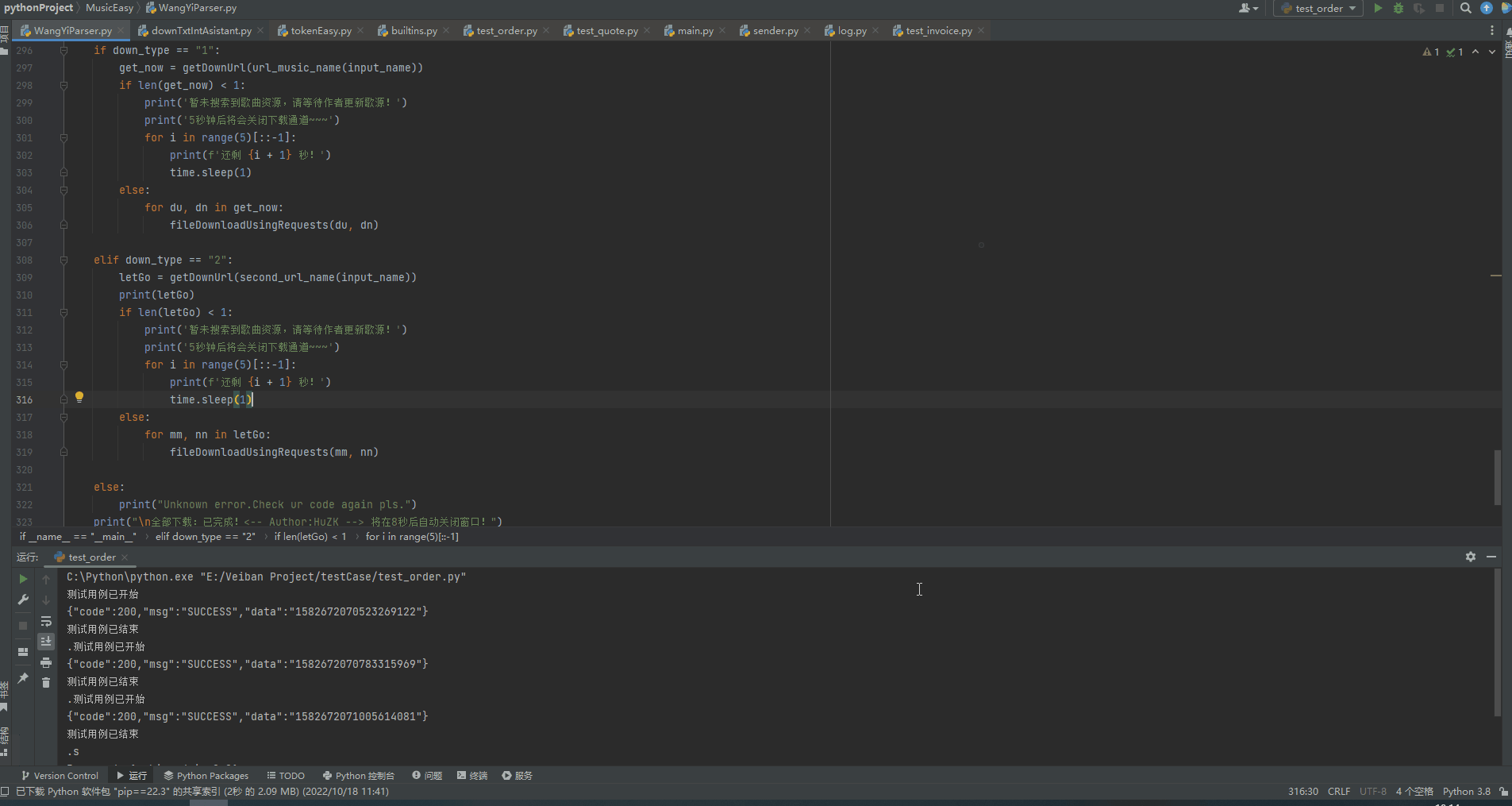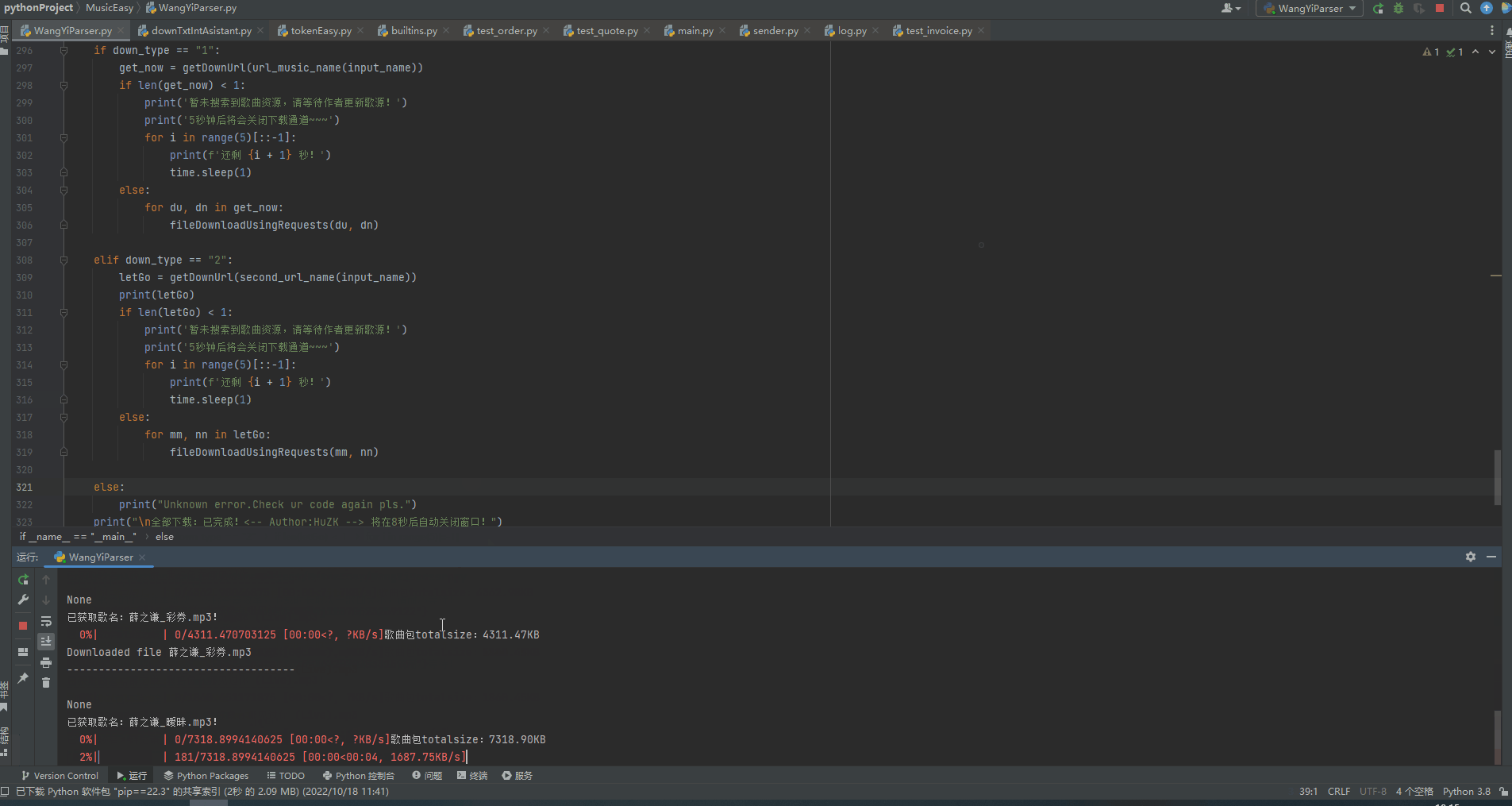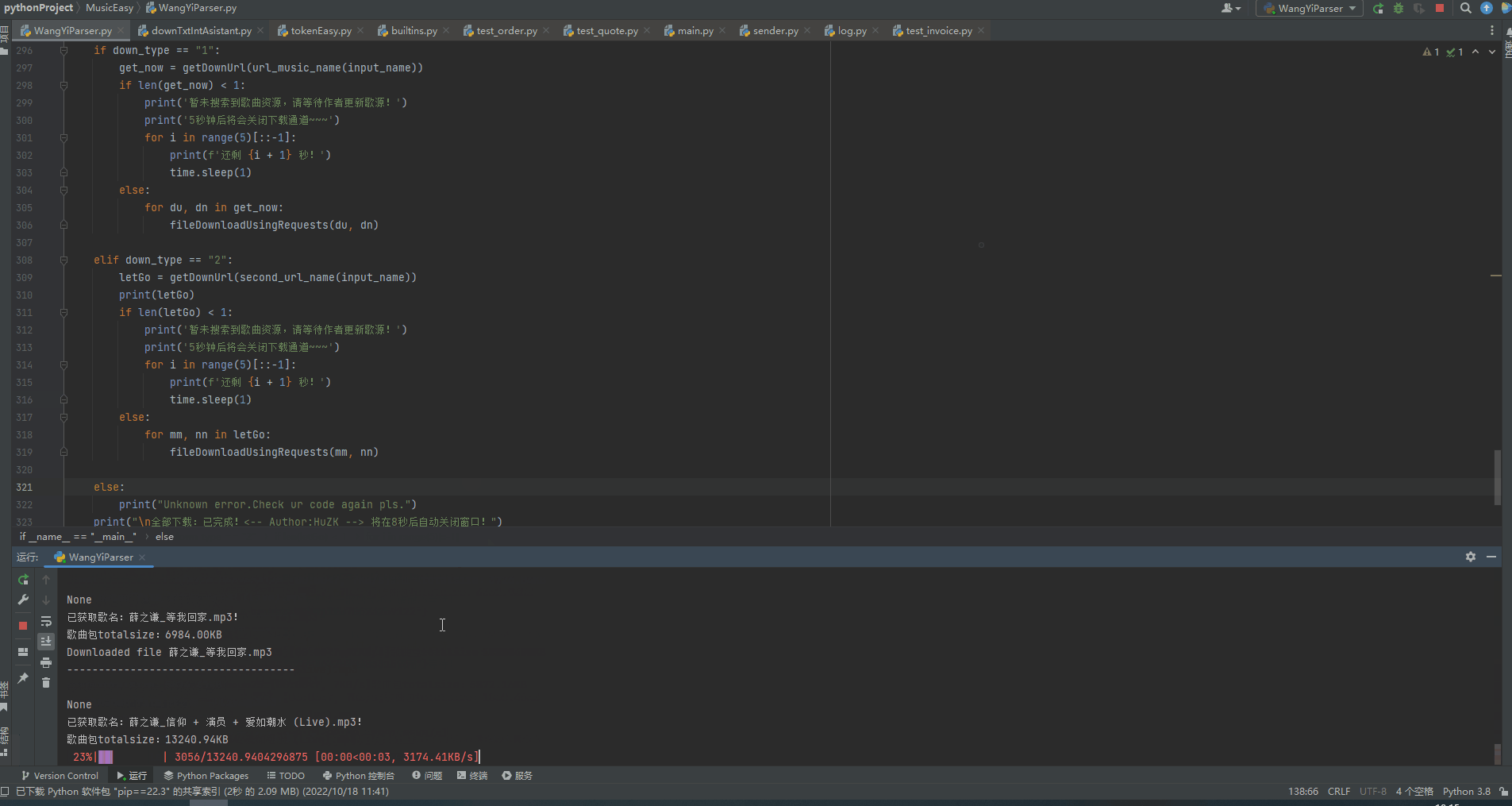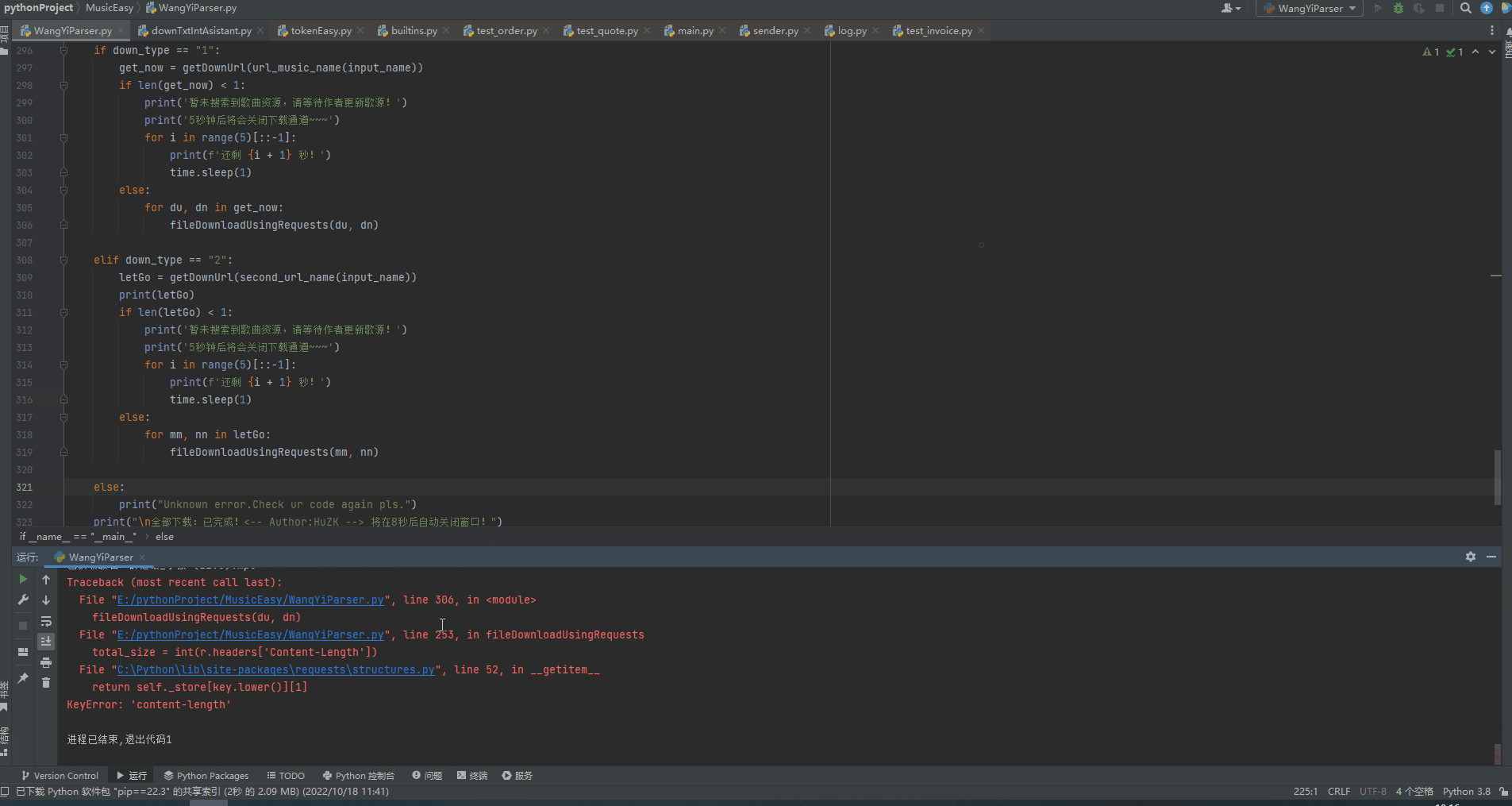
【留下的漏洞】:有的小破站,对音乐格式处理比较随便,我们获取不到
headers['Content-Length']
也就没法完美展示tqdm进度条了,大伙拿到源码后,可以注释掉这个,然后把tqdm()里的total去掉就行
打包成.EXE工具后,分享给大家:
百度网盘 请输入提取码 码:wynb
项目地址:GitHub - HardyHu/MusicEasy: 用来从名为收费、实则垄断的听歌生态里爬取喜欢的音乐。妈妈再也不用担心我买了网易会员下不了周杰伦的歌了!