自己的项目中有部分不校准,于是特意写几个例子进行阐述:
第一性原则: 非手动malloc或者calloc系列申请的空间(非堆内存),都会随着{}大括号结束而生命周期消亡;而手动申请的部分必须由自己手动释放;(私以为)手动申请的堆内存没有生命周期的概念,只有栈内存才有生命周期;
vector中的清理内存方法:
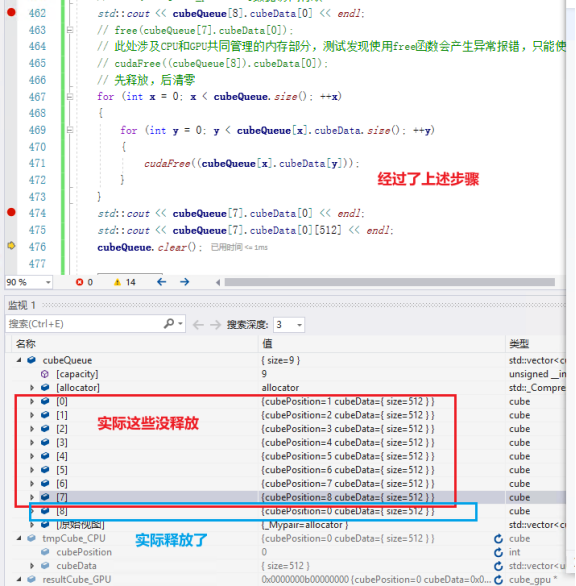
“vector.clear()”本身的函数并不会释放已申请的内存,只是把容器尺寸信息清零(类似浅拷贝),故导致类似内存泄露的问题出现,需要手动编写内存释放代码,在队列更改部分补充修正;(尝试过其他方式,实际效果并无,可能是版本的问题。https://blog.csdn.net/zhizhengguan/article/details/107781428)
vector中指针和数据值的测试
(根本可以参看STL中vector的实现细节以及内存分布,写多了就写不完了,所以这里抛砖引玉)
struct cube
{
int cubePosition = 0; // 未被赋值的都为0
vector<uint16_t*> cubeData; // n*512*512
};
#define cube_queue vector<cube>
cube_queue cubeQueue;
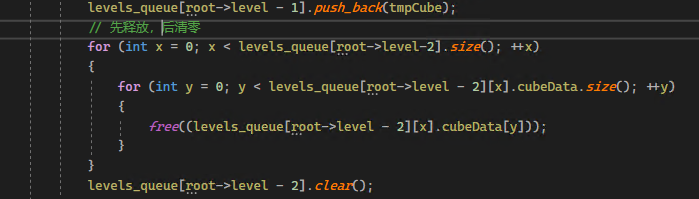
std::cout << cubeQueue[7].cubeData[0] << endl; //这是一个地址
std::cout << cubeQueue[7].cubeData[0][512] << endl; //这是一个数据值动态容器中的内存申请图
3.手动申请的堆内存没有生命周期的概念,只有栈内存才有生命周期;
uint16_t* bufferSlice = (uint16_t*)calloc((size_t)dstWight * (size_t)dstHeight, sizeof(uint16_t));
uint16_t* otherPtr = bufferSlice;
Free(bufferSlice);执行到此处后面,otherPtr则访问的是一段非法内存,可以访问,但访问的是一段错误值;
4.生命周期之外无法通过变量名访问数据,即使数据未被释放;
//加入变量的生命周期理解
for (uint16_t i = 0; i < dstFrame; ++i) {
uint16_t* bufferSlice = (uint16_t*)calloc((size_t)dstWight * (size_t)dstHeight, sizeof(uint16_t));
tmpCube.cubeData.push_back(bufferSlice);
// free(bufferSlice);
}
cout << tmpCube.cubeData[0][2] + 1 << endl;此时,生命周期过程结束(根据{}的括号边界判别),执行到了外部,在内部的bufferSlice直接被系统释放,bufferSlice不复存在,也无法通过bufferSlice访问任何信息;
但新接手指针的主人(tmpCube.cubeData),它由于是在外部定义的一个变量,它还存在(它的值未被释放),且通过calloc申请的堆内存并未手动释放(该块数据内存也未被释放,且仍然有效,前提是有指向这块堆内存的有效指针),
5.随着指针的复制和传值,只要不手动free,就不会影响到实际malloc申请到的堆内存;
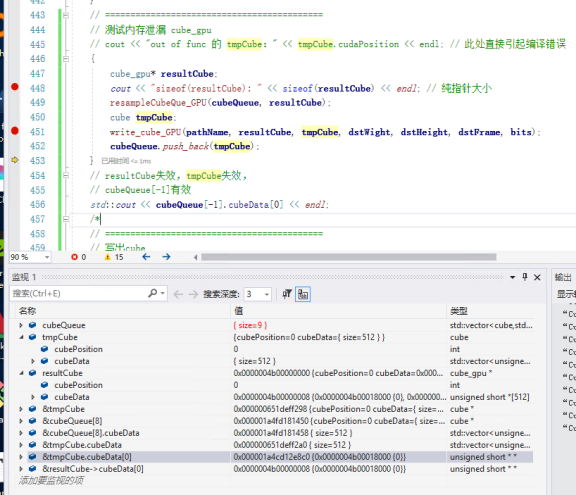

resultCube(根源)和tmpCube(地址复制)和cubeQueue[last_position](再嵌套一个结构体),它们实际的数据内容地址是否相同?
答:生命周期内数据地址相同,最终都是指向相同的某一处,同理于浅拷贝;
6.异构程序中,根据内存地址需要使用对应的free或者cudaFree才能真正释放;
异构程序内存释放(我前面使用的cuda的统一内存管理)
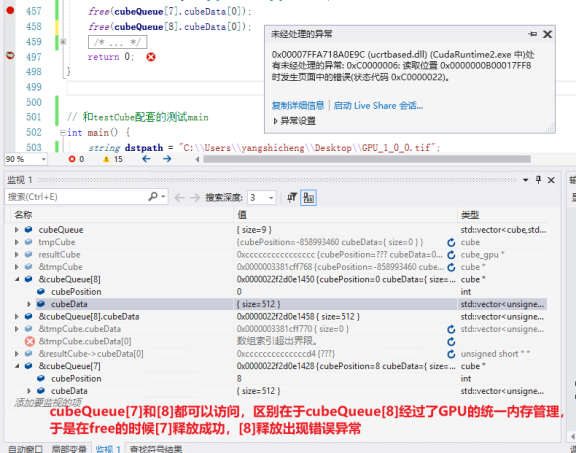
批量释放内存时出错,在进行内存释放时需注意内存地址;如果在GPU上,则需要使用cudaFree,如果在CPU上,则需要使用free。(经测试实证)
此处涉及CPU和GPU共同管理的内存部分,测试发现使用free函数会产生异常报错,只能使用cudaFree来进行内存销毁;
但是cudaFree释放CPU上的内存,不会报错,但没有效果,不会释放实际空间;free释放GPU上的内存会报错,直接程序中断异常;

7.cudaFree释放CPU上的内存,不会报错,但没有效果,不会释放实际空间;
判断cudaFree/free函数能否递归释放结构体中的数据——不能
struct cube_gpu
{
int cubePosition; // 未被赋值的都为0
// uint16_t *cubeData[512][512*512]; //直接申请过大的空间会出错
uint16_t* cubeData[512]; // 512*512
};
cube_gpu* u_tmpSourceCube = new cube_gpu;
HANDLE_ERROR(cudaMallocManaged((cube_gpu**)&u_tmpSourceCube, sizeof(cube_gpu)));
cudaDeviceSynchronize();
for (int umem_id = 0; umem_id < 512; umem_id++)
{
HANDLE_ERROR(cudaMallocManaged((uint16_t**)&u_tmpSourceCube->cubeData[umem_id], (size_t)512 * 512 * sizeof(uint16_t)));
cudaDeviceSynchronize();
}
std::cout << "make u_tmpSourceCube over!" << endl;
// 对结构体赋值完成,
// 测试下面方法,cudaFree能否连结构体里申请的堆内存一起释放,测试能否递归释放?
uint16_t* tmpPtr = u_tmpSourceCube->cubeData[0];
cudaFree(u_tmpSourceCube);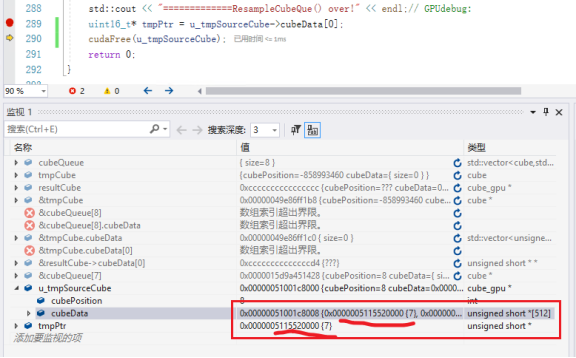
执行到这里发现tmpPtr的指向仍有值,且可以访问,证明没有递归释放。只是结构体中指针被释放了。

可见malloc申请的内存数据并未被释放,只是结构体u_tmpSourceCube自己含有的一个int和512个uint16*的指针被释放了。
真正的释放:
// 递归彻底释放GPU使用空间
// 释放内层
for (int x = 0; x < 512; ++x) {
cudaFree(u_tmpSourceCube->cubeData[x]);
}
// 释放表层
cudaFree(u_tmpSourceCube);