激励层(Activating Layer)
神经元向后传递信息需要与阈值(Thresholding)做比较来激活神经元从而向后传递信息,在CNN卷积神经网络中,卷积后同样需要激活过程,把卷积层输出结果做非线性映射就是激励层的作用。
CNN采用非线性函数作为其激活函数(Activation Function)。
1、什么是激活函数呢?激活函数并不是去激活什么,而是指如何把“激活的神经元的特征”通过函数把特征保留并映射出来(保留特征,去除一些数据中的冗余),这是神经网络能解决非线性问题关键。激活函数最终决定了要发射给下一个神经元的内容。
2、为什么要用激活函数呢?激活函数的主要作用是提供网络的非线性建模能力。在卷积层中,主要采用了卷积的方式来处理,也就是对每个像素点赋予一个权值,这个操作显然就是线性的。但是对于我们的样本来说,不一定是线性可分的,为了解决这个问题,我们可以进行线性变化,或者引入非线性因素,解决线性模型所不能解决的问题。如果没有激活函数,那么该网络仅能够表达线性映射,此时即便有再多的隐藏层,其整个网络跟单层神经网络也是等价的。因此也可以认为,只有加入了激活函数之后,深度神经网络才具备了分层的非线性映射学习能力。
3、为什么激活函数要用非线性函数?假如网络中全部是线性部件,那么线性的组合仍然是线性的,与单独一个线性分类器无异。这样就做不到用非线性来逼近任意函数。使用非线性激活函数 ,以便使网络更加强大,增加它的能力,使它可以学习复杂的事物,复杂的表单数据,以及表示输入输出之间非线性的复杂的任意函数映射。使用非线性激活函数,能够从输入输出之间生成非线性映射。
神经网络激活函数
1、ReLU函数(The Rectified Linear Unit)
中文名称是线性整流函数,是非饱和激活函数,用于隐层神经元输出。
ReLU函数表达式:

ReLU图像:

使用ReLU函数能使计算变快,因为无论是函数还是其导数都不包含复杂的数学运算。然而,当输入为负值的时候,ReLU 的学习速度可能会变得很慢,甚至使神经元直接无效,因为此时输入小于零并且梯度为零,从而其权重无法得到更新,在剩下的训练过程中会一直保持静默。
ReLU优点:
相比于Sigmoid和Tanh两个函数,其线性、非饱和的形式在SGD中能够快速收敛。
ReLU解决了梯度消失的问题,至少x在正区间内,神经元不会饱和。
梯度求解公式简单,不会产生梯度消失和梯度爆炸。
ReLU缺点:
ReLU的输出不是“零为中心”(Notzero-centered output)。
Dead ReLU 问题(神经元坏死现象)。当输入为负时,ReLU 完全失效,但在正向传播过程中,这不是问题。有些区域很敏感,有些则不敏感。在反向传播过程中,如果输入负数,则梯度将完全为零,sigmoid 函数和 tanh 函数也具有相同的问题。
ReLU与Sigmoid区别
ReLU函数单侧可以起到抑制作用
ReLU具有相对更宽阔的兴奋边界
ReLU具有稀疏激活性
ReLU具有更快的收敛速度
2、Sigmoid函数
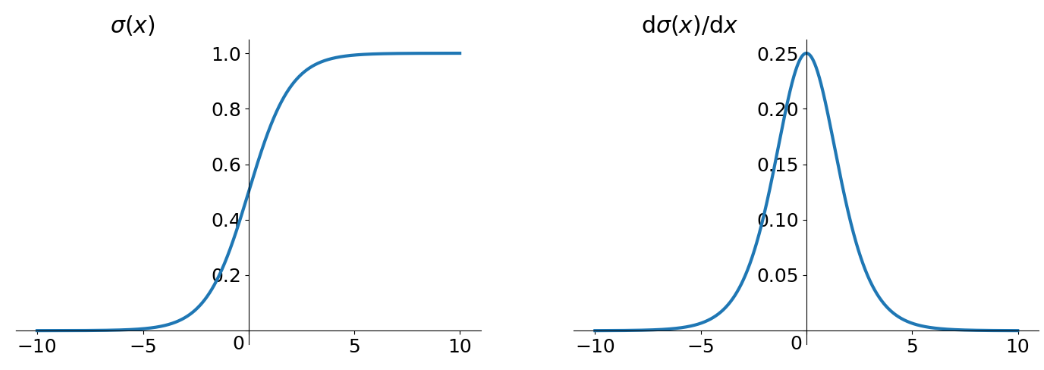
Sigmoid是饱和激活函数,是一种特殊的softmax函数,它能够把输入的连续实值变换为0和1之间的输出,如果是非常大的负数,那么输出就是0;如果是非常大的正数,输出就是1。当输入较大或较小时,输出几乎是平滑的并且梯度较小,这不利于权重更新。
Sigmoid函数表达式:

Sigmoid图像:
Sigmoid优点:
Sigmoid函数的输出在(0,1)之间,输出范围有限,优化稳定,可以用作输出层。
连续平滑函数,便于求导。
Sigmoid缺点:
最明显的就是饱和性,其两侧导数逐渐趋近于0,容易出现gradient vanishing(梯度消失)。
计算复杂度高,因为Sigmoid是指数形式。
函数输出不是zero-centered(以 0 为中心),这会降低权重更新的效率。
3、Softmax函数
Softmax 处理多分类问题,即只有一个正确答案,相当于是互斥输出。例如手写数字识别、鸢尾花分类。Softmax函数是二分类函数Sigmoid在多分类上的推广,目的是将多分类的结果以概率的形式展现出来。
Softmax函数表达式:

Softmax详细计算过程:

如上图所示,输入的数组为[3,1,-3],那么每项的计算过程为:
当输入为3时,计算公式为(e^3)/(e^3+e^1+e^-3)≈0.88
当输入为1时,计算公式为(e^1)/(e^3+e^1+e^-3)≈0.12
当输入为-3时,计算公式为(e^-3)/(e^3+e^1+e^-3)≈0
x=torch.Tensor([3.,1.,-3.])
softmax=torch.nn.Softmax(dim=0)
y=softmax(x)
print(y)tensor([0.8789, 0.1189, 0.0022])Softmax输出规则:
每一项的区间范围的(0,1)
所有项相加的和为1
Softmax缺点:
在零点不可微。
负输入的梯度为零,意味着对于该区域的激活,权重不会在反向传播期间更新,因此会产生永不激活的死亡神经元。
Softmax 函数的一种用途是在神经网络的末尾,它可以识别图像是猫还是狗。注意,图像必须是猫或狗,不能两者都是,因此这两个类是互斥的。如果我们在神经网络中添加一个Softmax 层,就可以将数字转换为概率分布。这意味着可以向用户显示输出,例如应用程序 95% 确定这是一只猫。
4、Tanh函数
中文名称双曲正切激活函数,是饱和激活函数,tanh 函数和 sigmoid 函数的曲线相对相似,但是比 sigmoid 函数更有优势。当输入较大或较小时,输出几乎是平滑的并且梯度较小,这不利于权重更新。
Tanh函数表达式:
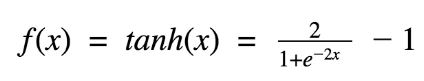
Tanh图像:

Tanh优点:
Tanh解决了Sigmoid的输出非“零为中心”的问题。
Tanh缺点:
有和Sigmoid一样过饱和的问题。
进行的是和Sigmoid一样的指数运算
Tanh与Sigmoid区别
tanh 的输出间隔为 1,并且整个函数以 0 为中心,比 sigmoid 函数更好。
在 tanh 图中,负输入将被强映射为负,而零输入被映射为接近零。
在一般的二元分类问题中,tanh 函数用于隐藏层, sigmoid 函数用于输出层,但并不是固定的,需要根据特定问题进行调整。
梯度消失和梯度爆炸
梯度消失、梯度爆炸其根本原因在于反向传播训练法则(BP算法):是指在使用梯度下降法对误差进行反向传播时,由于求偏导累乘而出现趋于0(梯度消失)或者趋于无穷大(梯度爆炸)的问题 。
Sigmoid函数最普遍发生的是梯度消失问题。
1、梯度消失和爆炸出现的原因:
经常因为网络层次过深。
以及激活函数选择不当,比如Sigmoid函数。
2、如何解决梯度消失和梯度爆炸:
梯度消失:用ReLU,maxout等替代sigmoid;权重初始化用高斯初始化。
梯度爆炸:更换参数初始化方法;使用Gradient Clipping(梯度裁剪),通过Gradient Clipping将梯度约束在一个范围内,就不会使得梯度过大。
饱和激活函数和非饱和激活函数
首先什么是饱和激活函数?
假设h(x)是一个激活函数。
1、当n趋近于正无穷,激活函数的导数趋近于0,我们称之为右饱和。

2、当n趋近于负无穷,激活函数的导数趋近于0,我们称之为左饱和。

当一个函数既满足右饱和又满足左饱和时,我们就称之为饱和,典型的函数有Sigmoid、Tanh函数。反之,不满足以上条件的函数称为非饱和,典型的有ReLU函数。
使用非饱和激活函数的优势:
非饱和激活函数能解决梯度消失问题。
能加快收敛速度。
总结
CNN卷积神经网络不建议使用Tanh,尤其是Sigmoid函数,如需使用可以在全连接层使用;除此之外,CNN应首先考虑ReLU激活函数,当效果不佳时,可考虑使用其他更为复杂的激活函数。
Sigmoid函数可以用来解决多标签问题,Softmax函数用来解决单标签问题:
1、若模型输出为非互斥类别,且可以同时选择多个类别,则采用Sigmoid函数计算原始输出值。
2、若模型输出为互斥类别,且只能选择一个类别,则采用Softmax函数计算原始输出值。
3、对于某个分类场景,当Softmax函数能用时,Sigmoid函数一定可以用。
如果使用ReLU,一定要小心设置学习率(learning rate),并且要注意不要让网络中出现很多死亡神经元。如果死亡神经元过多的问题不好解决,可以试试Leaky ReLU、PReLU、或者Maxout。
一般而言,不能把各种激活函数串起来在一个网络中使用。
题外话
ReLU是线性还是非线性函数?为什么还说它做激活函数比较好?
ReLU是非线性激活函数,为什么ReLU这种“看似线性”(分段线性)的激活函数所形成的网络,居然能够增加非线性的表达能力呢。
1、什么是线性的网络,如果把线性网络看成一个大的矩阵M。那么输入样本A和B,则会经过同样的线性变换MA,MB(这里A和B经历的线性变换矩阵M是一样的)。
2、的确对于单一的样本A,经过由relu激活函数所构成神经网络,其过程确实可以等价是经过了一个线性变换M1,但是对于样本B,在经过同样的网络时,由于每个神经元是否激活(0或者Wx+b)与样本A经过时情形不同了(不同样本),因此B所经历的线性变换M2并不等于M1。因此,relu构成的神经网络虽然对每个样本都是线性变换,但是不同样本之间经历的线性变换M并不一样,所以整个样本空间在经过relu构成的网络时其实是经历了非线性变换的。
3、另一种解释就是,不同样本的同一个feature,在通过ReLU构成的神经网络时,流经的路径不一样(ReLU激活值为0,则堵塞;激活值为本身,则通过),因此最终的输出空间其实是输入空间的非线性变换得来的。
4、更极端的,不管是Tanh还是Sigmoid,你都可以把它们近似看成是分段线性的函数(很多段),但依然能够有非线性表达能力;relu虽然只有两段,但同样也是非线性激活函数,道理与之是一样的。
5、ReLU的优势在于运算简单,网络学习速度快
reference: