前言
看惯了SpringMVC,最近在闲来之余抽空了解了一下Spring早已发布并支持的一种新web框架-WebFlux。由于这玩意的使用需要具备的基础是Reactive programming 的理解、Reactor 的基础以及熟练的java8 lambda使用。但是并不影响笔者摸着石头过河……在此做个浅学笔记。
WebFlux 模块的名称是Spring-webflux,名称中的Flux 来源Reactor中的类Flux。Spring webflux 有一个全新的非堵塞的函数式 Reactive Web 框架,可以用来构建异步的、非堵塞的、事件驱动的服务,在伸缩性方面表现非常好。
为了方便了解WebFlux,先来对比看一下比较熟悉的Servlet模型:

可以看到Servlet由servlet container进行生命周期管理。container启动时构造servlet对象并调用servlet init()进行初始化;container关闭时调用servlet destory()销毁servlet;container运行时接受请求,并为每个请求分配一个线程(一般从线程池中获取空闲线程)然后调用service()。
弊端:servlet是一个简单的网络编程模型,当请求进入servlet container时,servlet container就会为其绑定一个线程,在并发不高的场景下这种模型是适用的,但是一旦并发上升,线程数量就会上涨,而线程资源代价是昂贵的(上线文切换,内存消耗大)严重影响请求的处理时间。在一些简单的业务场景下,不希望为每个request分配一个线程,只需要1个或几个线程就能应对极大并发的请求,这种业务场景下servlet模型没有优势。
Spring WebMVC是基于servlet之上的一个路由模型,即spring实现了处理所有request请求的一个servlet(DispatcherServlet),并由该servlet进行路由。所以spring webmvc无法摆脱servlet模型的弊端。
然而 Spring 借助 Reactive Programming 的势头,WebFlux 将 Servlet 容器从必须项变为可选项,并且默认采用 Netty Web Server 作为基础,从而组件地形成 Spring 全新技术体系,包括数据存储等技术栈。
Webflux模型
Webflux模式替换了旧的Servlet线程模型。用少量的线程处理request和response io操作,这些线程称为Loop线程,而业务交给响应式编程框架处理,响应式编程是非常灵活的,用户可以将业务中阻塞的操作提交到响应式框架的work线程中执行,而不阻塞的操作依然可以在Loop线程中进行处理,大大提高了Loop线程的利用率。官方结构图:

webflux官方架构图
在Java 8中添加lambda表达式也为Java中的函数API创造了机会。这对于允许异步逻辑的声明性组合的非阻塞应用程序和延续式API(CompletableFuture和ReactiveX推广了这一点)来说是一个好消息。在编程模型上,Java8中SpringWebFlux不仅支持命令式注解型编程,还提供了函数式编程。因此适当了解WebFlux的基础使用还是可以的。
Spring WebFlux介绍
Spring框架中包含的原始web框架Spring web MVC是专门为Servlet API和Servlet容器构建的。反应式堆栈web框架SpringWebFlux是在5.0版本后期添加的。它是完全无阻塞的,支持Reactive Streams背压,并在Netty、Undertow和Servlet容器等服务器上运行,填补了Spring在响应式编程中的空白。
这两个web框架都镜像了它们的源模块(spring-webmvc和spring-webflux)的名称,并在spring框架中并排共存。每个模块都是可选的。应用程序可以使用一个或另一个模块,在某些情况下,也可以同时使用这两个模块 — 例如具有反应式WebClient的Spring MVC控制器。更多详细资料可参考WebFlux文档

- SpringMVC方式实现同步阻塞的方式,基于SpringMVC+Servlet+Tomcat
- SpringWebFlux方式实现,异步非阻塞方式基于SpringWebFlux+Netty+Reactor
Reactive API
反应流在互操作性方面发挥着重要作用。它对库和基础设施组件很感兴趣,但作为应用程序API用处不大。应用程序需要一个更高级别、更丰富的功能API来组成异步逻辑 — 类似于Java 8 Stream API,但不仅仅用于集合。这就是反应库所扮演的角色。
Reactor是Spring WebFlux的首选反应库。它提供了Mono和Flux API类型,通过与ReactiveX操作符词汇表对齐的一组丰富的操作符来处理0..1(Mono)和0..N(Flux)的数据序列。反应器是一个反应流库,因此,其所有操作人员都支持无阻塞背压。Reactor非常关注服务器端Java。它是与Spring密切合作开发的。
WebFlux需要Reactor作为核心依赖项,但它可以通过reactive Streams与其他反应库进行互操作。一般来说,WebFlux API接受一个普通的Publisher作为输入,在内部将其调整为Reactor类型,使用它,并返回Flux或Mono作为输出。因此,您可以将任何Publisher作为输入传递,也可以对输出应用操作,但您需要调整输出以与另一个反应库一起使用。只要可行(例如,带注释的控制器),WebFlux就会透明地适应RxJava或其他反应库的使用。
支持的编程模型
spring-web模块包含作为spring-WebFlux基础的reactive基础,包括HTTP抽象、用于支持的服务器的reactive Streams适配器、编解码器,以及与Servlet API类似但具有非阻塞合约的核心WebHandler API。
在此基础上,SpringWebFlux提供了两种编程模型的选择:
- Annotated Controllers:与Spring MVC一致,并基于来自Spring web模块的相同注释。Spring MVC和WebFlux控制器都支持反应式(Reactor和RxJava)返回类型,因此,很难将它们区分开来。一个显著的区别是WebFlux还支持反应式@RequestBody参数。
- Annotated Controllers:基于Lambda的轻量级功能编程模型。您可以将其视为应用程序可以用来路由和处理请求的一个小型库或一组实用程序。与带注释的控制器的最大区别在于,应用程序负责从开始到结束的请求处理,而不是通过注释声明意图并被调用。
Spring MVC or WebFlux?
官方给出的一张图显示了两者之间的关系,它们有什么共同点,以及各自唯一支持什么,可供大家理解:
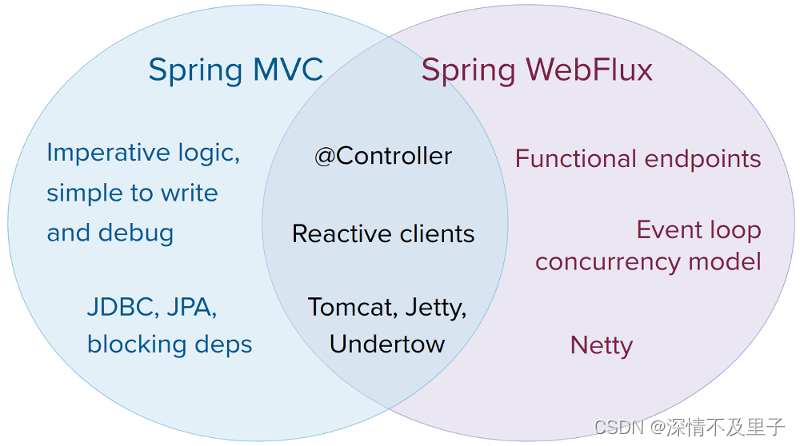
可以看到,这两个框架都可以用注解式编程模型,都可以运行在tomcat,jetty,undertow等servlet容器当中。但是SpringMVC采用命令式编程方式,分层设计思想,代码一句一句的执行,懂的都懂,这样更有利于理解与调试,而WebFlux则是基于异步响应式编程,对于习惯了MVC编程的小伙伴们来说可能会不习惯。对于这两种框架官方给出的建议是:
-
如果你有一个运行良好的SpringMVC应用程序,那么就没有必要进行更改。命令式编程是编写、理解和调试代码的最简单方法。你可以最大限度地选择库,因为从使用历史上看,大多数库都是阻塞的。
-
如果你已经在购买非阻塞web堆栈,那么Spring WebFlux提供了与该领域其他执行模型相同的执行模型优势,还提供了服务器选择(Netty、Tomcat、Jetty、Undertow和Servlet容器)、编程模型选择(annotated controllers and functional web endpoints)以及反应库选择(Reactor、RxJava或其他)。
-
如果你对用于Java 8 lambdas或Kotlin的轻量级、功能性web框架感兴趣,可以使用Spring WebFlux功能性web端点。对于要求不那么复杂的小型应用程序或微服务来说,这也是一个不错的选择,它们可以从更大的透明度和控制中受益。
-
在微服务架构中,你可以将应用程序与Spring MVC或Spring WebFlux控制器或Spring WebFlux功能端点混合使用。在两个框架中都支持相同的基于注释的编程模型,可以更容易地重用知识,同时为正确的工作选择正确的工具。事实上,两者的产生就是为了扩大了可用选项的范围,为了彼此的连续性和一致性,它们可以并排使用,双方的反馈对双方都有好处。
-
评估应用程序的一种简单方法是检查其依赖关系。如果你有阻塞持久性API(JPA、JDBC)或网络API可供使用,那么Spring MVC至少是通用体系结构的最佳选择。Reactor和RxJava在单独的线程上执行阻塞调用在技术上是可行的,但你将不会充分利用非阻塞的web堆栈。
-
如果你有一个可以调用远程服务的SpringMVC应用程序,可以考虑响应式WebClient。而且方法的返回值可以考虑使用Reactive Type类型的,当每个调用的延迟时间越长,或者调用之间的相互依赖程度越高,其好处就越明显。
-
如果你的团队打算使用非阻塞式web框架,WebFlux确实是一个可考虑的技术路线,而且它支持类似于SpringMvc的Annotation的方式实现编程模式,也可以在微服务架构中让WebMvc与WebFlux共用Controller,切换使用的成本相当小。
性能情况

参照官网翻译过来就是:反应式和非阻塞式通常不会使应用程序运行得更快。在某些情况下,它们可以(例如,如果使用WebClient并行运行远程调用)。总的来说,以非阻塞的方式做事需要更多的工作,这可能会略微增加所需的处理时间。
反应式和非阻塞的主要预期好处是能够使用少量、固定数量的线程和较少的内存进行扩展。这使得应用程序在负载下更具弹性,因为它们以更可预测的方式进行扩展。然而,为了观察这些好处,你需要有一些延迟(包括缓慢和不可预测的网络I/O的混合)。这就是reactive stack开始显示其优势的地方,并且差异可能是巨大的。
也就是说,相对Spring MVC而言,SpringWebFlux并不是让你的程序运行的更快,而是在有限的资源下提高系统的伸缩性和吞吐量,它更适合于IO 密集型的服务中,比如涉及磁盘IO或者网络IO的一些场景。
使用实践
项目准备
因为现在还没几个数据库系统实现了反应式数据访问的可用驱动,Spring Data Reactive 目前仅支持MongoDB、Redis 、Couchbase和 Cassandra,简单起见我们就用 MongoDB。
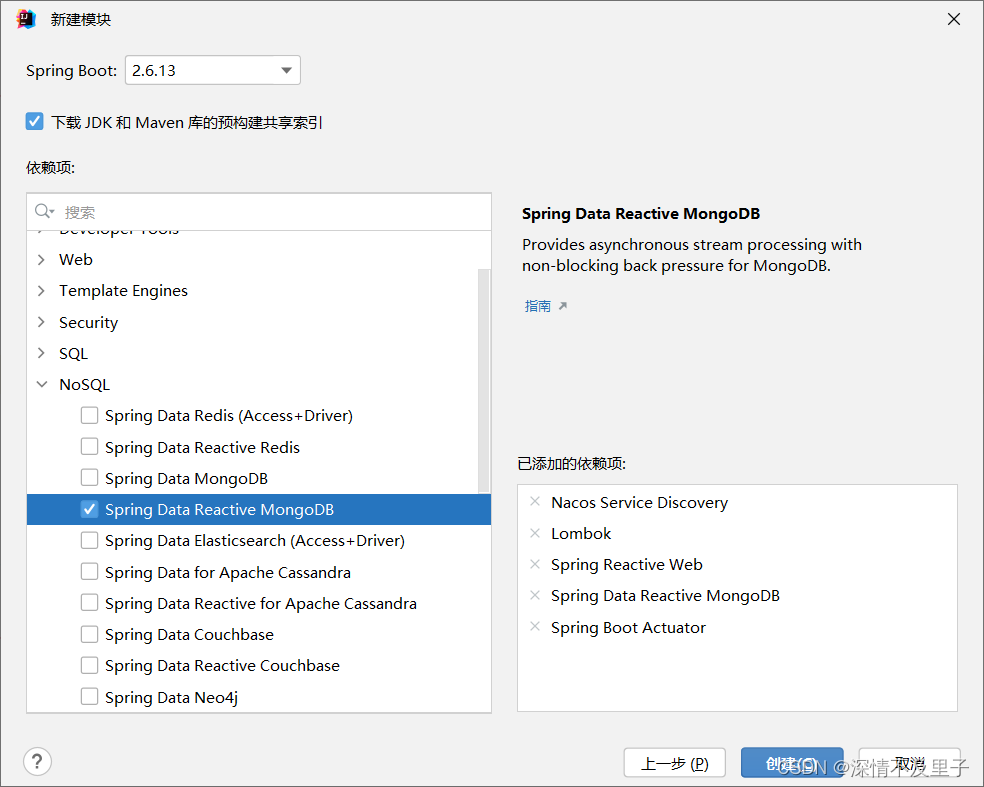
服务注册中心使用Nacos,除了这些依赖项以外还需要手动导入WebFlux的依赖。因此,项目整体依赖为:
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<artifactId>cloud-webflux-8025</artifactId>
<version>0.0.1-SNAPSHOT</version>
<name>cloud-webflux-8025</name>
<description>cloud-webflux-8025</description>
<parent>
<artifactId>SpringCloudAlibaba</artifactId>
<groupId>com.yy</groupId>
<version>1.0.1</version>
</parent>
<properties>
<java.version>1.8</java.version>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<project.reporting.outputEncoding>UTF-8</project.reporting.outputEncoding>
</properties>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-actuator</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-mongodb-reactive</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-webflux</artifactId>
</dependency>
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-nacos-discovery</artifactId>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<optional>true</optional>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
<dependency>
<groupId>io.projectreactor</groupId>
<artifactId>reactor-test</artifactId>
<scope>test</scope>
</dependency>
</dependencies>
</project>因为笔者使用的mongoDB数据库,因此这里准备好了一个mongo测试文档集合,并建立实体类。
package com.yy.entity;
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
import org.bson.types.ObjectId;
import org.springframework.data.annotation.Id;
import org.springframework.data.mongodb.core.mapping.Document;
/**
* @author young
* Date 2023/4/18 16:52
* Description: SpringCloudAlibaba
*/
@AllArgsConstructor
@Data
@NoArgsConstructor
@Document(collection = "stuMongoDB")
public class WebFluxEntity {
@Id
private Long id;
private String address;
private Integer age;
private String username;
}然后这里笔者不做太复杂的业务操作,为了方便直接用响应式ReactiveMongoRepository来扩展基础的mongoDB的简单增删改查操作。创建一个测试接口继承该接口,就像使用JPA一样,不同的是我们需要用响应式的repository。
package com.yy.repository;
import com.yy.entity.WebFluxEntity;
import org.springframework.data.mongodb.repository.ReactiveMongoRepository;
/**
* @author young
* Date 2023/4/18 16:55
* Description: SpringCloudAlibaba
*/
public interface TestDataRepository extends ReactiveMongoRepository<WebFluxEntity, Long> {
}接下来对照官网给的实践方式以注解和函数式两种不同编程实现方式来体验WebFlux的效果。
注解驱动实现
编写controller层,以注解的方式实现后端请求接口,熟悉的restful风格即可。
package com.yy.controller;
import com.yy.entity.WebFluxEntity;
import com.yy.repository.TestDataRepository;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.http.HttpStatus;
import org.springframework.http.ResponseEntity;
import org.springframework.web.bind.annotation.*;
import reactor.core.publisher.Flux;
import reactor.core.publisher.Mono;
/**
* @author young
* Date 2023/4/18 16:58
* Description: 基于注解实现
*/
@RestController
@RequestMapping("wf")
public class WebFluxTestController {
@Autowired
private TestDataRepository testDataRepository;
@GetMapping("all")
public Flux<WebFluxEntity> list() {
return testDataRepository.findAll();
}
@GetMapping("/get/{id}")
public Mono<ResponseEntity<WebFluxEntity>> get(@PathVariable Long id) {
return testDataRepository.findById(id)
.map(ResponseEntity::ok)
.defaultIfEmpty(ResponseEntity.notFound().build());
}
@PostMapping("/add")
public Mono<WebFluxEntity> create(@RequestBody WebFluxEntity webFluxEntity) {
return testDataRepository.save(webFluxEntity);
}
@PutMapping("/update/{id}")
public Mono<ResponseEntity<WebFluxEntity>> update(@PathVariable("id") Long id, @RequestBody WebFluxEntity webFluxEntity) {
return testDataRepository.findById(id).flatMap(
existing->{
existing.setUsername(webFluxEntity.getUsername());
existing.setAddress(webFluxEntity.getAddress());
existing.setAge(webFluxEntity.getAge());
return testDataRepository.save(existing);
}
).map(updateMsg->new ResponseEntity<>(updateMsg, HttpStatus.OK)).
defaultIfEmpty(new ResponseEntity<>(HttpStatus.NOT_FOUND));
}
@DeleteMapping("/delete/{id}")
public Mono<ResponseEntity<Void>> delete(@PathVariable Long id) {
return testDataRepository.findById(id)
.flatMap(existing->testDataRepository.delete(existing))
.then(Mono.just(new ResponseEntity<Void>(HttpStatus.OK)))
.defaultIfEmpty(new ResponseEntity<>(HttpStatus.NOT_FOUND));
}
}它的返回值基本用Mono或Flux表示,在这块Mono是一种响应式类型,代表0或1个值。适用于处理要么成功获取结果,要么没有值可供使用的情况。而Flux与Mono相似,只不过它代表0到N个值。它适用于处理类似于查询数据集的情况。
用ApiPost简单测试一下接口,基本符合预期效果:
函数式端点实现
在WebFlux.fn中,HTTP请求由HandlerFunction处理:该函数接受ServerRequest并返回延迟的ServerResponse(即Mono<ServerResponse>)。请求和响应对象都有不可变的协议,这些协议为JDK8提供了对HTTP请求和响应。HandlerFunction相当于基于注释的编程模型中@RequestMapping方法的主体。
传入请求被路由到具有RouterFunction的处理程序函数:该函数接受ServerRequest并返回延迟的HandlerFunction(即Mono<HandlerFunction>)。当路由器函数匹配时,将返回一个处理程序函数;否则为空Mono。RouterFunction相当于@RequestMapping注释,但主要区别在于路由器函数不仅提供数据,还提供行为。
RouterFunctions.route()提供了一个路由器生成器,它有助于创建路由器,也就是说它是通过路由来实现接口跳转到业务实现的过程。因此,在这需要一个Handler类处理请求响应逻辑:
package com.yy.controller;
import com.yy.entity.WebFluxEntity;
import com.yy.repository.TestDataRepository;
import lombok.extern.slf4j.Slf4j;
import org.bson.types.ObjectId;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.http.HttpStatus;
import org.springframework.http.MediaType;
import org.springframework.http.ResponseEntity;
import org.springframework.stereotype.Component;
import org.springframework.web.reactive.function.server.ServerRequest;
import org.springframework.web.reactive.function.server.ServerResponse;
import reactor.core.publisher.Flux;
import reactor.core.publisher.Mono;
/**
* @author young
* Date 2023/4/18 17:24
* Description: 函数式编程
*/
@Component
@Slf4j
public class WebFluxHandler {
@Autowired
private TestDataRepository testDataRepository;
/**
* 函数式统一格式 ,查询所有数据
* @param serverRequest 不管是否使用都加上,否则route报错
* @return
*/
public Mono<ServerResponse> findAll(ServerRequest serverRequest){
Flux<WebFluxEntity> all = testDataRepository.findAll();
log.info("获取所有数据信息---");
//第一种响应写法
return ServerResponse.ok().contentType(MediaType.APPLICATION_JSON).body(all,WebFluxEntity.class);
}
/**
* 根据id获取单个信息
* @param serverRequest
* @return
*/
public Mono<ServerResponse> findById(ServerRequest serverRequest){
//根据uri中的拼接的id数值获取具体值
String id = serverRequest.pathVariable("id");
//转换为mongoDB主键id
long l = Long.parseLong(id);
Mono<WebFluxEntity> obj = testDataRepository.findById(l);
return ServerResponse.status(HttpStatus.OK).contentType(MediaType.APPLICATION_JSON).body(obj,WebFluxEntity.class);
}
/**
* 添加/更新一个的对象
* @param serverRequest
* @return
*/
public Mono<ServerResponse> addOne(ServerRequest serverRequest){
Mono<WebFluxEntity> webFluxEntityMono = serverRequest.bodyToMono(WebFluxEntity.class);
return webFluxEntityMono.flatMap(s->{
Mono<WebFluxEntity> mono = testDataRepository.save(s);
return ServerResponse.ok().contentType(MediaType.APPLICATION_JSON).body(mono,WebFluxEntity.class);
});}
}配置路由函数route,实现请求映射:
package com.yy.configuration;
import com.yy.controller.WebFluxHandler;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.http.MediaType;
import org.springframework.web.reactive.function.server.RequestPredicates;
import org.springframework.web.reactive.function.server.RouterFunction;
import org.springframework.web.reactive.function.server.RouterFunctions;
import org.springframework.web.reactive.function.server.ServerResponse;
/**
* @author young
* Date 2023/4/18 17:27
* Description: 函数式编程方式处理请求
*/
@Configuration
public class RouteConfig {
@Bean
public RouterFunction<ServerResponse> routeCity(WebFluxHandler webFluxHandler) {
return RouterFunctions.route(RequestPredicates.GET("/func/list").and(RequestPredicates.accept(MediaType.APPLICATION_JSON)), webFluxHandler::findAll)
.andRoute(RequestPredicates.GET("/func/getOne/{id}").and(RequestPredicates.accept(MediaType.APPLICATION_JSON)),webFluxHandler::findById)
.andRoute(RequestPredicates.POST("/func/updateOrAdd").and(RequestPredicates.accept(MediaType.APPLICATION_JSON)), webFluxHandler::addOne);
}
}WebFlux使用配置函数路由的方式来实现请求映射,而在处理接口(WebFluxHandler) 中的方法返回全都是Mono<ServerResponse>类型的,这个就跟函数式接口@FunctionInterface有关,有兴趣的小伙伴可以仔细了解一下。这里就作简单的解释。最后测试一下: 
但是这样测试结果其实是有不足的,因为最终返回的都是一个封装好的对象,如果查不到数据怎么办呢,服务器没有出错,但是测试返回是没有数据的,并不方便我们查看实际响应结果。
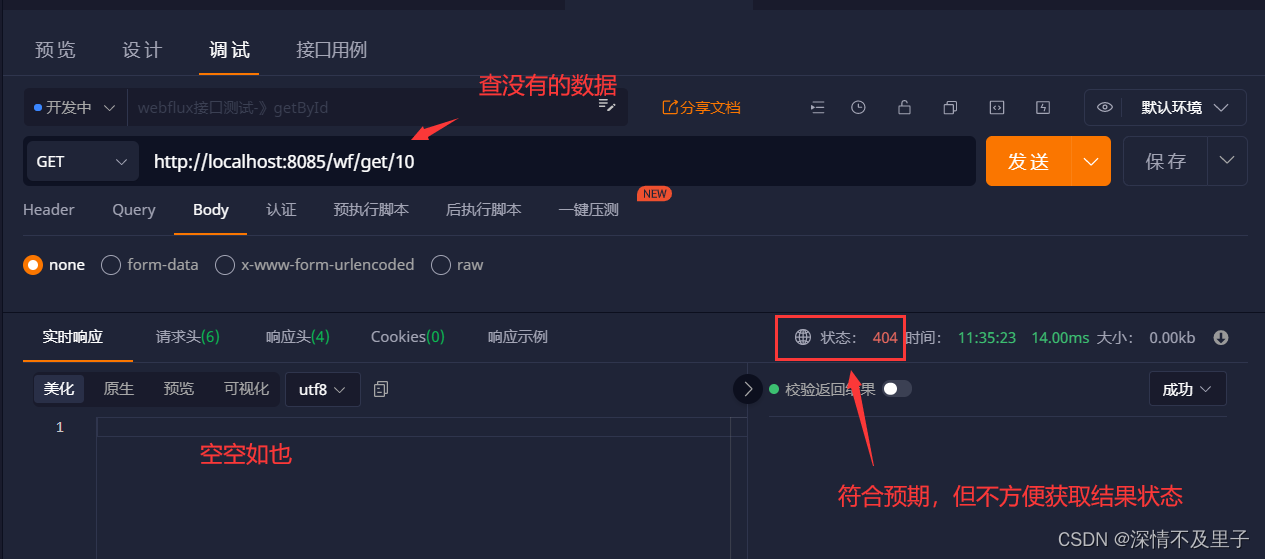
因此需要做个简单封装来展示接口返回结果,做统一返回处理。
返回值处理
统一返回值处理在常用开发中非常常见了,不同于之前需要定义返回码,返回消息和数据三个数据,在WebFlux中可以在Mono或者Flux中的通过ResponseEntity来定义返回码与其对应的结果,在web框架中集成了一个HttpStatus枚举类来使用。
public enum HttpStatus {
CONTINUE(100, HttpStatus.Series.INFORMATIONAL, "Continue"),
SWITCHING_PROTOCOLS(101, HttpStatus.Series.INFORMATIONAL, "Switching Protocols"),
PROCESSING(102, HttpStatus.Series.INFORMATIONAL, "Processing"),
CHECKPOINT(103, HttpStatus.Series.INFORMATIONAL, "Checkpoint"),
OK(200, HttpStatus.Series.SUCCESSFUL, "OK"),
CREATED(201, HttpStatus.Series.SUCCESSFUL, "Created"),
ACCEPTED(202, HttpStatus.Series.SUCCESSFUL, "Accepted"),
NON_AUTHORITATIVE_INFORMATION(203, HttpStatus.Series.SUCCESSFUL, "Non-Authoritative Information"),
NO_CONTENT(204, HttpStatus.Series.SUCCESSFUL, "No Content"),
RESET_CONTENT(205, HttpStatus.Series.SUCCESSFUL, "Reset Content"),
PARTIAL_CONTENT(206, HttpStatus.Series.SUCCESSFUL, "Partial Content"),
MULTI_STATUS(207, HttpStatus.Series.SUCCESSFUL, "Multi-Status"),
ALREADY_REPORTED(208, HttpStatus.Series.SUCCESSFUL, "Already Reported"),
IM_USED(226, HttpStatus.Series.SUCCESSFUL, "IM Used"),
MULTIPLE_CHOICES(300, HttpStatus.Series.REDIRECTION, "Multiple Choices"),
MOVED_PERMANENTLY(301, HttpStatus.Series.REDIRECTION, "Moved Permanently"),
FOUND(302, HttpStatus.Series.REDIRECTION, "Found"),
……
}因此这里只对数据进行封装即可。编写数据统一处理封装类:
package com.yy.utils;
import com.yy.enums.ResultEnum;
import lombok.Data;
import lombok.NonNull;
import reactor.core.publisher.Flux;
import reactor.core.publisher.Mono;
import java.io.Serializable;
/**
* @author young
* Date 2023/4/20 11:44
* Description: webflux的统一返回格式
*/
@Data
public class FluxResult<T> implements Serializable {
private static final long serialVersionUID = 289927880636348482L;
/**
* 返回数据
*/
private T data;
/**
* 对Mono数据封装
* @param monoData
* @param <T>
* @return
*/
public static <T> Mono<FluxResult<T>> build(Mono<T> monoData) {
return monoData.map(data -> {
final FluxResult<T> result = new FluxResult<>();
result.setData(data);
return result;
});
}
}重新修改一下controller中的返回值,这里只改两个仅供测试:
@GetMapping("/result/get/{id}")
public Mono<FluxResult<ResponseEntity<WebFluxEntity>>> getResult(@PathVariable Long id) {
return FluxResult.build(testDataRepository.findById(id)
.map(ResponseEntity::ok)
.defaultIfEmpty(ResponseEntity.notFound().build()));
}
测试统一处理后的请求响应效果:
能够获取对应数据时: 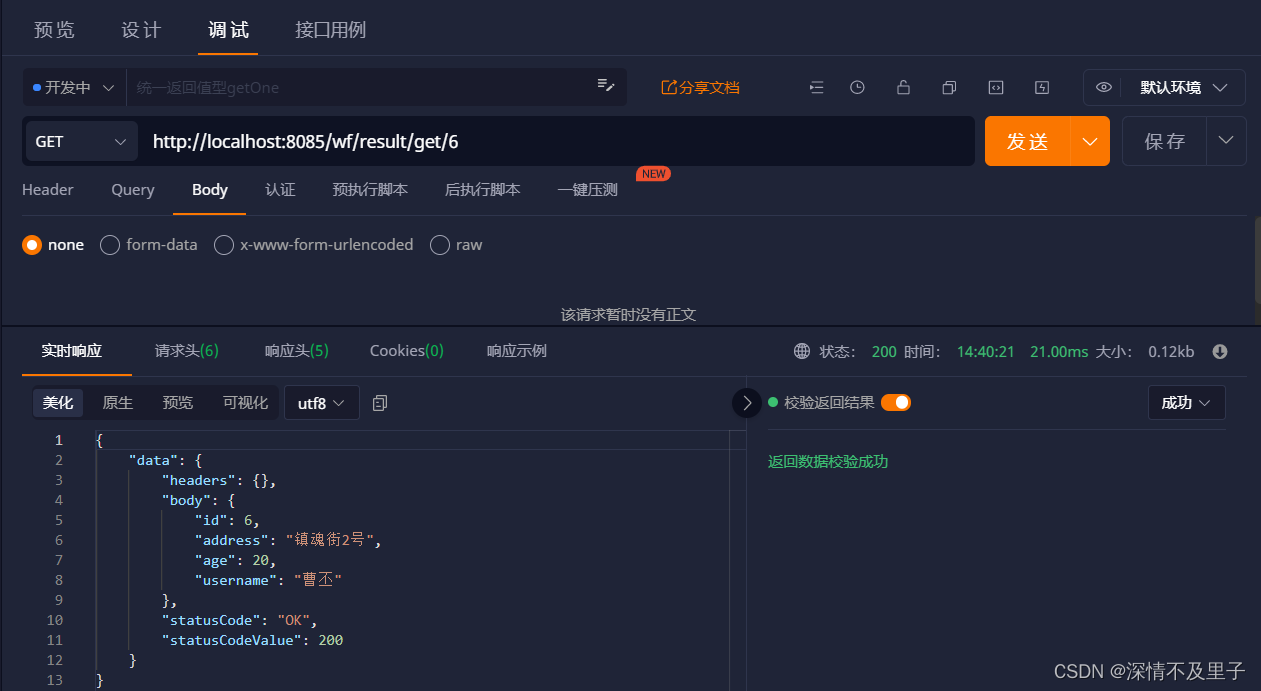
没有获取数据时:
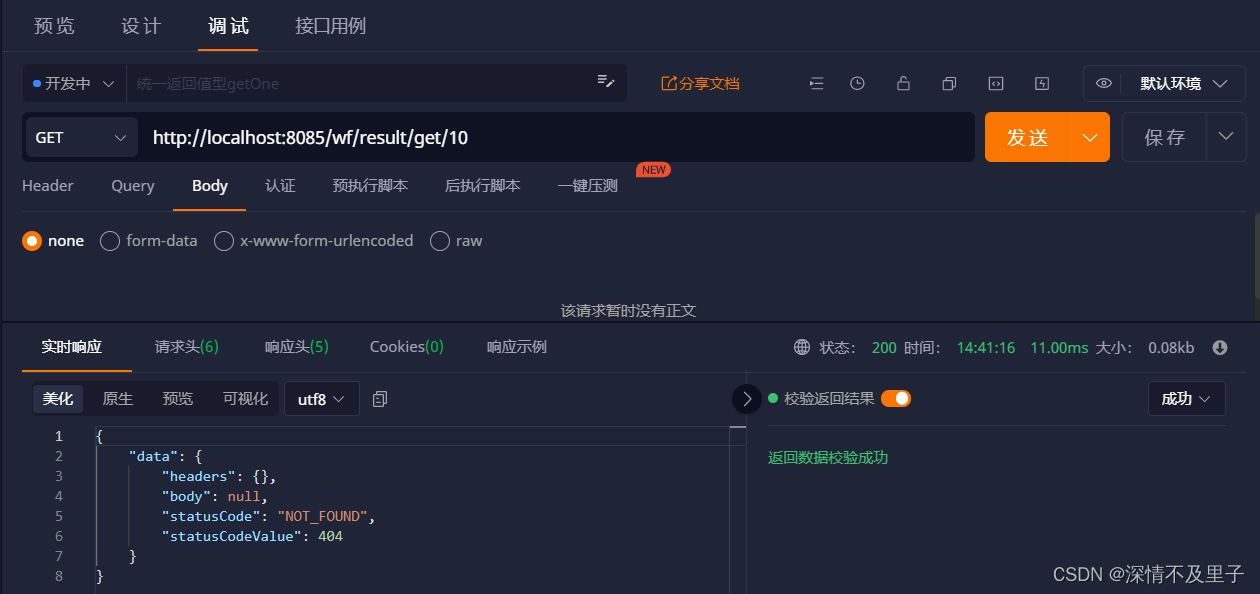
但这种方式封装统一返回值并不太适合返回Flux数据集,不多说,有兴趣的小伙伴可以去试一下。
小总结
其实这种函数式写法并不是在WebFlux才出现的,在官网中,SpringMVC其实也支持这两种方式,只不过在日常的学习中,因为函数式编程对初学者并不友好,它的学习曲线相对命令式编程语言还是比较高的,习惯于面向对象编程思维的开发者不容易适应这种函数式编程风格和以数据流驱动的思维模式。这给聚焦业务功能的开发者带来了较高的技术门槛。另外,函数式编程中常用的操作符,也比较难掌握,需要花费额外的工夫和精力才能完全掌握它的具体用法。 
但是在JDK8中引入的Lambda 表达式和Stream API函数式编程风格的引入,也慢慢开始让很多大佬开始使用起来。而对于自身的技术选型来看,WebFlux似乎更适用于高负载、高并发、大数据量场景,适用于在异步边界作为非阻塞模块交互的技术解决方案。如果你的应用对消息的实时性、高负载、用户量等方面没有太大的诉求,那么使用Spring MVC这样传统的编程框架就足够。所以,在进行技术选型或者编程模型选择时,首先要从业务的性质、用户规模和实际使用场景出发,还要考虑团队技术人员的学习能力和知识储备。选择Spring WebFlux作为Web服务器框架还需要从上述技术、业务、人员等因素来权衡利弊。笔者这里写的也仅仅是WebFlux的冰山一角,对于函数式,流式编程一脸懵逼。有兴趣的小伙伴可以自行参照官网学习了解哈。