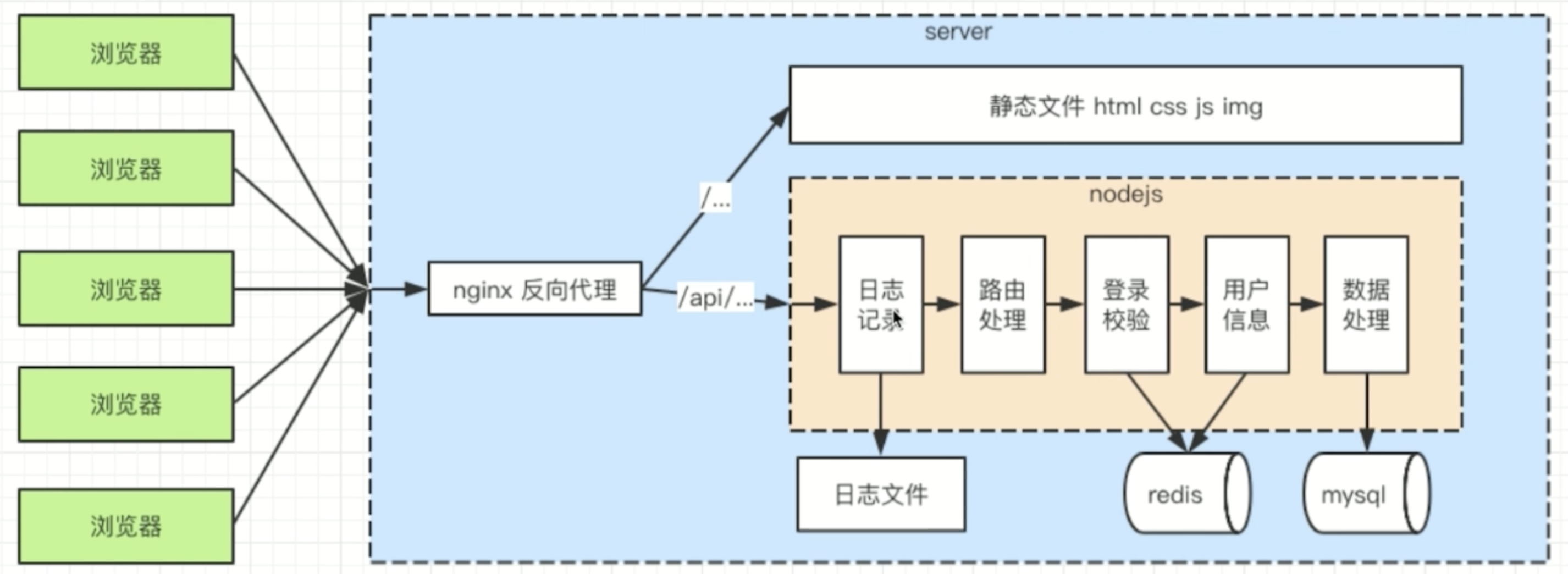
博客项目介绍
1. 目标
- 开发一个博客系统,具备博客基本功能
- 只开发
server端,不关心前端
2. 需求
- 首页、作者页、博客详情页
- 登陆页
- 管理中心、新建页、编辑页
3. 技术方案
数据如何存储
- 博客
| id | title | content | createtime | author |
|---|---|---|---|---|
| 1 | 标题 1 | 内容 1 | 1111112 | zhangsan |
| 2 | 标题 2 | 内容 2 | 1111111 | lisi |
- 用户
| id | username | password | realname |
|---|---|---|---|
| 1 | zhangsan | 123 | 张三 |
| 2 | lisi. | 123 | 李四 |
如何与前端对接接口,即接口设计
| 描述 | 接口 | 方法 | url参数 | 备注 |
|---|---|---|---|---|
| 获取博客列表 | /api/blog/list | get | author 作者,keyword搜索关键字 | 参数为空,则不进行查询过滤 |
| 获取一篇博客的详情 | /api/blog/detail | get | id | 无 |
| 新增一篇博客 | /api/blog/new | post | 无 | post中有新增的信息 |
| 更新一遍博客 | /api/blog/update | post | id | postData中包含更新内容 |
| 删除一篇博客 | /api/blog/del | post | id | 无 |
| 登陆 | /api/user/login | post | 无 | postData包含用户名和密码 |
4. 开发接口(原生node,不使用框架)
4.1 http请求过程
- DNS解析,建立TCP连接(三握四挥),发起请求;
- serve 端接收请求处理数据,响应返回数据;
- 客户端接收到数据,渲染页面,执行脚本。
4.2 搭建开发环境
- 使用
nodemon检测文件变化,自动重启node项目; - 使用
cross-env设置环境变量。
4.3 路由和数据
- 初始化路由:根据之前的技术方案的设计,做出路由;
- 返回假数据:将路由和数据分离,符和设计原则。
4.4 项目结构
根目录下
bin/www.js处理端口和 有关 http 服务的相关事宜app.js处理基本逻辑(导入路由函数,传递req,res参数),和 404 页面router文件夹,完成路由规则(分为blog.js、 user.js),只处理路由,不关心数据的处理controller/blog.js文件, 连接数据库,处理数据,在router/blog.js中使用,类似工具model/resModel文件, 完成响应数据模块resModel,封装成功和失败类,在router/blog.js的某个路径成功获取数据后就使用成功类响应数据和消息提示。
4.5 处理 post
使用 promise 优化 post 请求的数据,放入 req.body 里。对于请求方法不正确或者请求头不匹配直接 resolve 一个空对象,并不需要当作一个错误。应为读取 data 的过程是异步的,所以需要将原来的命中路由的逻辑放在promise中,在 app.js 中实现。
部分代码如下:
/**
* 处理 post data
*/
const getPostData = (req) => {
const promise = new Promise((resolve, reject) => {
// 方法不是 post
...
// 请求头格式不是 json
...
let postData = "";
req.on("data", (chunk) => {
// 将json格式的参数转为字符串保存
postData += chunk.toString();
});
req.on("end", () => {
// null
if (!postData) {
resolve({
});
return;
}
// success
resolve(JSON.parse(postData));
});
});
return promise;
};
// 处理 post data
getPostData(req).then((postData) => {
// 将数据放入body
req.body = postData;
/**
* blog 路由
*/
const blogData = handleBlogRouter(req, res);
// 命中 blog 路由
...
/**
* user 路由
*/
const userData = handleUserRouter(req, res);
// 命中 user 路由
...
// 处理 404
...
});
5.数据存储
5.1.实现思路
- 建立数据库myblog,建立博客表、和用户表
conf/db.js下封装数据库工具,处理开发和生产环境下的数据库连接配置db/mysql.js使用promise获取数据库的数据,resolve给getList工具,在getList中只需处理sql语句,然后在app.js中使用.then,发送res.end给客户端
6.登陆功能
核心:登陆鉴权和信息存储
-
cookie和session
-
session 写入 redis
-
开发登陆功能-和前端联调 Nginx 反向代理
session/cookie
前端保存 cookie 携带 userId,后端通过是否有 userId 进行一系列操作,当登陆成功但是没有 session 时需要设置 session
目前有关session的问题
- session 是直接储存 js 变量,放在 node.js 进程内存中;
- 第一,进程内存有限,访问量过大时内存爆增,可能导致服务崩溃;
- 第二,正式线上运行时多进程,进程之间无法共享内存。
解决:使用 redis
为什么:

- session 访问非常频繁,不能使用 mysql,对性能要求高。
- 并且 session 可以丢失,无须内存永久保存。
- session数据量不大,没必要使用 mysql
要使用 Redis,在 Node.js 中存储会话(session),你需要执行以下步骤:
1. 下载和安装 Redis:
官方网站(https://redis.io/download)
启动服务:执行 redis-server,建立连接和操作:执行:redis-cli
基本使用语法:
- 添加:set [key] [value]
- 获取:get [key]
- 删除:del [key]
- 获取所有key: keys *
2. 配置 Redis:
安装完成后,你需要配置 Redis 服务器。打开 Redis 配置文件(redis.conf)并进行必要的更改。确保 bind 配置项设置为允许远程连接(如果需要从 Node.js 应用程序访问 Redis)。
3. 在 Node.js 中安装 Redis 客户端:
npm install redis
这将安装 Redis 客户端库,使你能够在 Node.js 应用程序中与 Redis 进行交互。
4. 在 Node.js 应用程序中存储会话:
首先,你需要在 Node.js 应用程序中创建与 Redis 的连接。使用 Redis 客户端库提供的方法进行连接。
const redis = require('redis');
const client = redis.createClient(); // 创建与 Redis 的连接
client.on('error', (err) => {
console.error('Redis连接错误:', err);
});
// 储存会话示例
app.post('/login', (req, res) => {
// 处理用户登录逻辑
// ...
// 在 Redis 中存储会话
client.set(req.sessionID, JSON.stringify(req.user), (err, reply) => {
if (err) {
console.error('存储会话错误:', err);
return res.status(500).send('存储会话失败');
}
console.log('会话已存储:', reply);
res.send('登录成功');
});
});
在上面的示例中,我们使用 Redis 客户端的 set 方法将会话数据以 JSON 字符串的形式存储在 Redis 中。req.sessionID 是会话的唯一标识符,通常存储在用户的浏览器 cookie 中。req.user 是用户对象,我们将其转换为 JSON 字符串后存储在 Redis 中。
和前端联调
- 登陆依赖 cookie 必须使用 浏览器联调
- cookie 跨域不共享,前端和 server 端必须同域
- 需要使用 nginx 代理,使前后端同域
登陆总结:
Cookie和Session都是用于跟踪用户状态的技术。它们之间有一些区别:
-
Cookie:Cookie是一种存储在客户端的小型文本文件,用于保存用户的一些信息。当用户访问一个网站时,服务器会将Cookie发送到用户的浏
-
用户在登录页面输入用户名和密码。
-
客户端将用户名和密码发送到服务器。
-
服务器验证用户名和密码。如果验证成功,服务器会创建一个Session,并将Session ID发送给客户端(通常通过Cookie)。
-
客户端保存Session ID,并在后续请求中将其发送回服务器。
-
服务器根据Session ID识别用户,并获取其会话信息。
在使用Redis存储Session信息时,可以将Session ID作为键,将用户会话信息作为值。这样,当服务器需要获取用户会话信息时,可以直接从Redis中查询,而不需要访问数据库,从而提高性能。同时,由于Redis支持分布式存储,可以方便地扩展Session存储容量。
7.日志
- 访问日志
access log(最重要); - 自定义日志,包括自定义事件、错误记录。
大致思路:
- 封装 utils log.js 工具
- 使用 writerStream 分别实现 access 访问日志,和错误、事件日志
- 分别导出使用
/**
* 写日志的一小步操作
* @param {Function} writeStream
* @param {string} log
*/
const writeLog = function (writeStream, log) {
writeStream.write(log + "\n");
};
/**
* 写入流函数
* @param {string} fileName -logs 文件夹下的文件名,你将要写入的文件
* @return writeStream
*/
const createWriteStream = function (fileName) {
const fullFilePath = path.join(__dirname, "../", "../", "logs", fileName);
const writeStream = fs.createWriteStream(fullFilePath, {
flags: "a" });
return writeStream;
};
// 1. 写入访问日志
// 利用 createWriteStream 函数创建 access 写入流
const accessWriteStream = createWriteStream("access.log");
const access = function (log) {
writeLog(accessWriteStream, log);
};
// 2. 写入错误日志
...
// 3. 写入事件日志
...
module.exports = {
...
};
日志拆分
使用 linux 的 crontab 命令,即定时任务。
使用 crontab -e 写入在什么时候执行什么文件
* 0 * * * sh /Users/jiangchuanyou/Desktop/项目/node博客项目/src/utils/copy.sh
以上就是在每天凌晨0点执行以下脚本
#!/bin/sh
cd /Users/jiangchuanyou/Desktop/项目/node博客项目/logs
cp access.log $(date +%Y-%m-%d).access.log
echo '' > access.log
8. 安全
- sql 注入:窃取数据库内容;
解决方案:mysql 自带 escape 函数
- xss 攻击:窃取前端 cookie 内容;
解决方案:转换特殊字符,使用 xss 函数,下载 npm 包 xss -s,直接使用 xss 函数包裹变量,以免生成危险的 js 代码
前端预防 xss 攻击
-
输入验证和过滤:对于用户输入的数据,进行输入验证和过滤,确保只接受预期的数据类型和格式。可以使用正则表达式、白名单过滤或使用专门的输入验证库来检查和清理用户输入。
-
HTML转义:将用户输入的数据进行适当的 HTML 转义,确保任何特殊字符都被转义为它们的等效实体表示形式。这样可以防止恶意脚本在页面中执行。可以使用专门的转义函数或库,如
htmlspecialchars等。 -
跨站点脚本保护:禁止内联 JavaScript 代码、限制只接受特定的 HTML 标签和属性。使用安全的 HTML 渲染库或模板引擎,这些库会自动转义用户输入。
-
HTTP-only Cookie:将敏感信息存储在 HTTP-only Cookie 中,确保 JavaScript 无法访问该信息。这样可以减少 XSS 攻击者窃取会话信息的可能性。
-
内容安全策略(Content Security Policy,CSP):使用 CSP 可以限制页面中可以执行的脚本和资源。通过配置 CSP,可以指定允许的域、资源类型和加载方式,以减少 XSS 攻击的风险。
-
防止拼接 HTML 字符串:避免直接拼接用户输入的数据来构建 HTML 字符串。而是使用 DOM 操作或模板引擎来动态生成 HTML,确保数据被正确地转义和处理。
-
安全编码实践:遵循安全的编码实践,避免在代码中出现漏洞,如不信任的数据源、不安全的 eval() 使用、动态执行用户输入的代码等。
- 密码加密:保障用户信息安全
9. 总结