Local Intensity Order Transformation
Artical DOI: 10.1109/TIP.2022.3155954
Artical Code: github
1 Main Contribution
- In this paper, we aim to improve the generalizability by introducing a novel local intensity order transformation (LIOT).
- faces some particular challenges [7]: 1) thin, long, and tortuosity shapes; 2) inadequate contrast between curvilinear structures and the surrounding background; 3) uneven background illumination; 4) various image appearances.That is the paper gogal
2 Datasets
Cross-datasets includes DRIVE, STARE, CHASEDB1 and CrackTree:
DRIVE: 40 565584 color retinal images,which split into 20 traing images and 20 test test images
STARE: consists of 20 700605 color retina images divided into 10 training and 10 test images
CHASEDB1: contains 28 999960 color retinal images, which are split into 20 training images and 8 test images
CrackTree: contains 206 800600 pavement images with different kinds of cracks having curvilinear structuree,which ard split into 160 training and 46 test images.
3 Data Augment
- transforms.RandomRotation(180)
- transforms.RandomHorizontalFlip()
- transforms.RandomVerticalFlip()
- shear from -0.1 to 0.1
- randomly shifted from -0.1 to 0.1
- randomly zoomed from 0.8 to 1.2
- transforms.RandomCrop(128)
4 Initialization
Loss: Cross-entropy and topological loss(Topo)
Evaluation protocol: TPs,TNs,FPs,FNs are used for F1 score; Acc、Se(sensitivity)、Sp(specificity) and area under the receiver operating characteristics curve (AUC).
Batch_size: 32
Epoch: 1000
Optimizer: Adam abd lr is 0.001
5 Comparison Range
5.1 Apply the model trained on the CrackTree dataset to segment retinal blood vessels:
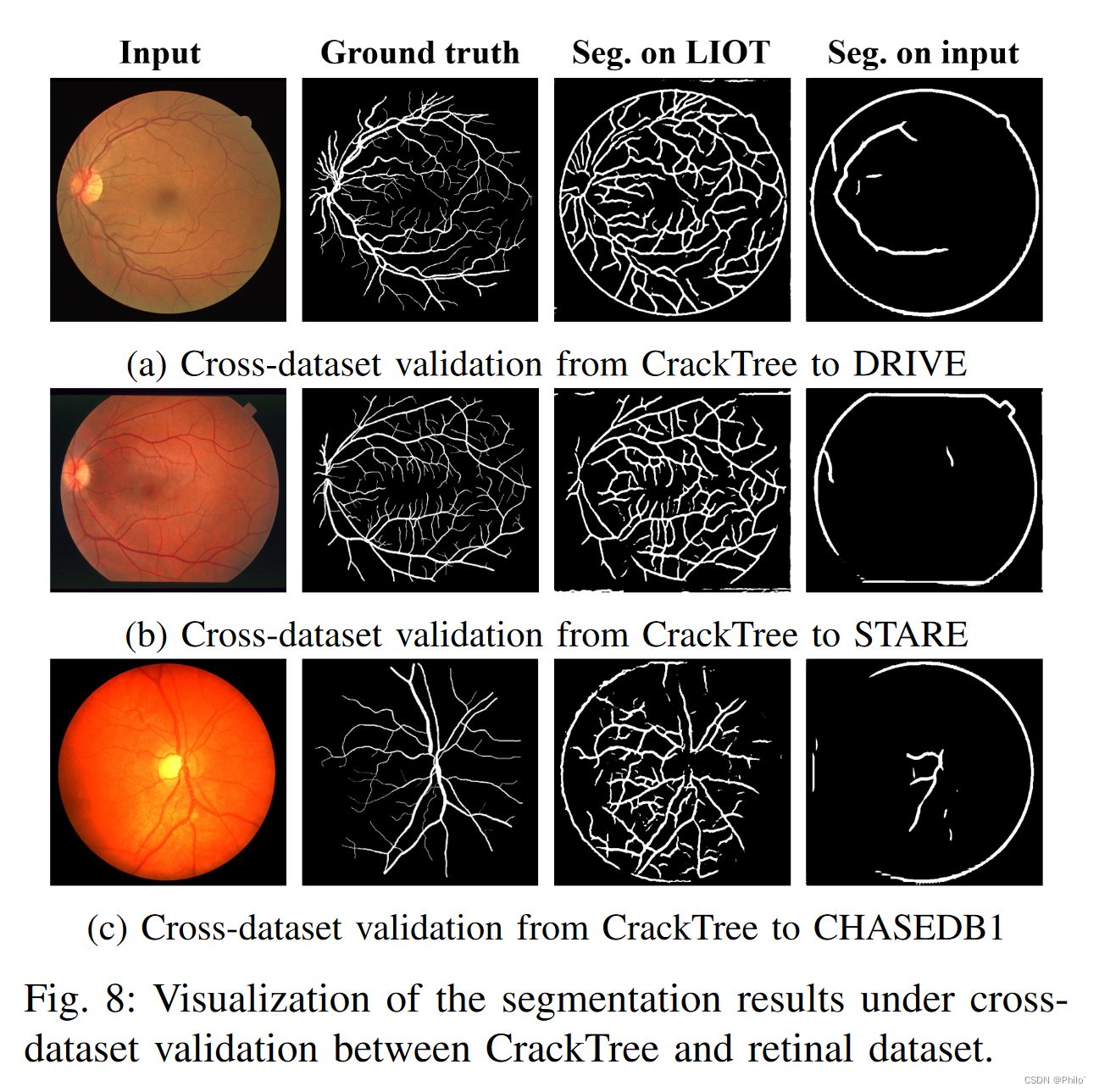
and the precies results:

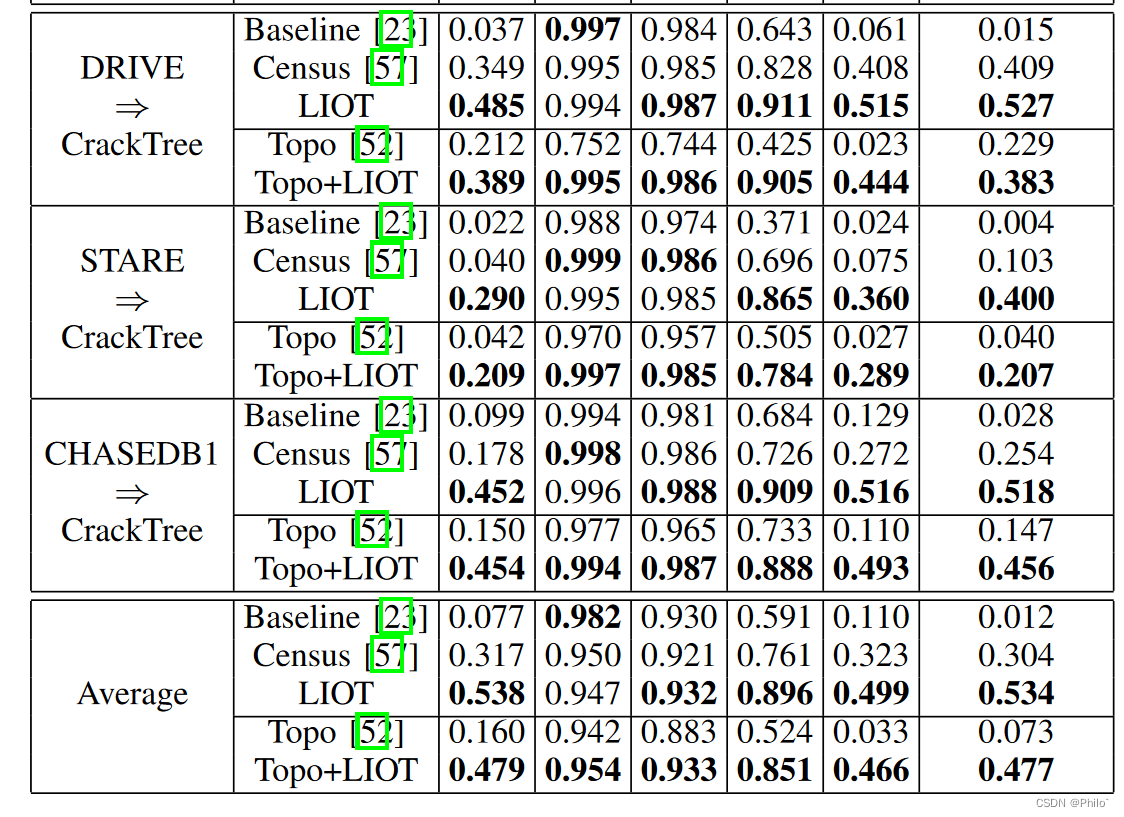
5.2 Apple the model trained on the retinal dataset to evaluate the CrackTree:

and the pricies results:
Generalization to images with different curvilinear objects: appley the model trained on the DRIVE dataset to images with different types of curvilinear structures:

6 Conclusion
- we propose the LIOT that converts a grayscale image to a novel representation that is invariant to increasing contrast changes.
- extensive crossdataset experiments on three widely adopted retinal blood vessel segmentation datasets and CrackTree dataset demonstrate that LIOT can improve the classical segmentation pipeline that directly operates on the original image
LIOT forms a simple yet effective way to improve the generalization performance of different models.
7 Core Ways
Core Methode:

They convert the given image into a gray-scale one. Secondly, they rely on the local intensity oredr to computer four directional binary codes, forming a 4-channel image that captures the curvilinear structure charcteristic.Last, They feed this contrast invariant 4-channel image into a segmentation network.
The Fig.4 show the creationof 4-channels images, for each pixel, Among the 8 pixels in the four directions, the pixel greater than or equal to the center point is set as 0, and the pixel less than the center point is set as 1. Then, the image of the four channels 0-255 is obtained by converting binary to decimal.