
前几篇博客分别对配置文件、注册器进行了介绍,完成了模型、数据集、训练策略的流程,但这个流程目前为止还只是静态的,如果要动态地运行这个流程,将模型训练起来,需要用到Runner和Hook。本篇博客将从源码角度对MMCV中的Runner和Hook进行介绍。本文主要是对下面内容的总结和梳理。
1. Runner和Hook概述
Runner又称执行器,负责模型训练过程的调度,主要目的是让用户使用更少的代码以及灵活可配置的方式开启训练。换句话说,MMCV将整个训练过程封装起来了,并使用Runner进行管理和配置。高度封装虽然减少了代码量,但如何对内部流程进行自定义的修改(比如动态调整学习率等)?这时就需要用到Hook机制。
Hook是能够改变程序执行流程的一种技术统称。通俗的说,Hook可以理解为一种触发器,在程序预定义的位置执行预定义的函数。MMCV已经在几个常用的位置预留了接口函数(称为回调函数),如下图所示。MMCV已经实现了一些常用的Hook函数,同时用户也可以增加自己的Hook函数,非常方便。当程序执行到指定位置时,就会进入到回调函数中,执行相应的功能,执行结束后再接着执行主流程。

上图对应到具体的代码:
# 开始运行时调用
before_run()
while self.epoch < self._max_epochs:
# 开始 epoch 迭代前调用
before_train_epoch()
for i, data_batch in enumerate(self.data_loader):
# 开始 iter 迭代前调用
before_train_iter()
self.model.train_step()
# 经过一次迭代后调用
after_train_iter()
# 经过一个 epoch 迭代后调用
after_train_epoch()
# 运行完成前调用
after_run()
总的来说,Runner封装了OpenMMLab体系下各个框架的训练和验证流程,负责管理训练/验证过程的整个生命周期;通过预定义的回调函数,用户可以插入定制化Hook,实现各种各样定制化的需求。
2. Runner类
Runner分为EpochBasedRunner和IterBasedRunner,顾名思义,前者以epoch的方式管理流程,后者以iter的方式管理流程,它们都是BaseRunner的子类。BaseRunner的任何子类都需要实现run()、train()、val()和save_checkpoint()四个方法,这也是Runner的核心方法。这里以EpochBasedRunner为例对上述四个函数进行分析,为了使代码结构看起来更清晰,删去了和核心功能无关的代码。
2.1 构造函数
EpochBasedRunner和IterBasedRunner都是BaseRunner的子类,继承了BaseRunner的构造函数。runner默认调用model类中的train_step()和val_step()进行训练和验证,如果指定了batch_processor,则会调用batch_processor对data_loader中的数据进行处理。
class BaseRunner(metaclass=ABCMeta):
def __init__(self,
model, # [torch.nn.Module] 要运行的模型
batch_processor=None, # 过时用法, 通过实现模型中的train_step()和val_step()方法替代
optimizer=None, # [torch.optim.Optimizer] 优化器, 可以是一个也可以是一组通过dict配置的优化器
work_dir=None, # [str] 保存检查点和Log的目录
logger=None, # [logging.Logger] 训练中使用的日志记录器
meta=None, # [dict] 一些信息, 这些信息会在logger hook中记录
max_iters=None, # [int] 训练epoch数
max_epochs=None): # [int] 训练迭代次数
2.2 run()函数
run()是runner类的主调函数,会根据workflow指定的工作流,对data_loaders中的数据进行处理。目前MMCV支持训练和验证两种工作流,对于EpochBasedRunner而言,workflow配置为[('train', 2),('val', 1)]表示先训练2个epoch,然后验证一个epoch;[('train', 1)]表示只进行训练,不进行验证。如果是IterBasedRunner,[('train', 2),('val', 1)]则表示先训练2个iter,然后验证一个iter。
def run(self, data_loaders, workflow, max_epochs=None, **kwargs):
while self.epoch < self._max_epochs:
for i, flow in enumerate(workflow):
mode, epochs = flow
# 根据工作流确定当前是运行train()还是val(), getattr返回对应的函数句柄
epoch_runner = getattr(self, mode)
for _ in range(epochs):
if mode == 'train' and self.epoch >= self._max_epochs:
break
# 运行train()或val()
epoch_runner(data_loaders[i], **kwargs)
2.3 train()和val()函数
train()和val()函数循环调用run_iter()完成一个epoch流程。函数开头的self.model.train()和self.model.eval()实际上调用的是torch.nn.module.Module的成员函数,将当前模块设置为训练模式或验证模式,两种不同模式下batchnorm、dropout等层的操作会有区别。然后由于测试过程不需要梯度回传,所以val函数加了一个装饰器@torch.no_grad()。
def train(self, data_loader, **kwargs):
# 将模块设置为训练模式
self.model.train()
self.mode = 'train'
self.data_loader = data_loader
self._max_iters = self._max_epochs * len(self.data_loader)
for i, data_batch in enumerate(self.data_loader):
self.run_iter(data_batch, train_mode=True, **kwargs)
self._iter += 1
self._epoch += 1
@torch.no_grad()
def val(self, data_loader, **kwargs):
# 将模块设置为验证模式
self.model.eval()
self.mode = 'val'
self.data_loader = data_loader
for i, data_batch in enumerate(self.data_loader):
self.run_iter(data_batch, train_mode=False)
train()和val()的核心函数是run_iter(),根据train_mode参数调用model.train_step()或model.val_step(),这两个函数最终会执行我们自己模型的forward()函数,返回loss值。
def run_iter(self, data_batch, train_mode, **kwargs):
if self.batch_processor is not None:
outputs = self.batch_processor(self.model, data_batch, train_mode=train_mode, **kwargs)
elif train_mode:
outputs = self.model.train_step(data_batch, self.optimizer, **kwargs)
else:
outputs = self.model.val_step(data_batch, self.optimizer, **kwargs)
self.outputs = outputs
2.4 save_checkpoint()函数
save_checkpoint()函数调用torch.save将检查点以下列格式保存。

checkpoint = {
'meta': dict(), # 环境信息(比如epoch_num, iter_num)
'state_dict': dict(), # 模型的state_dict()
'optimizer': dict()) # 优化器的state_dict()
}
3. Hook类
MMCV在./mmcv/runner/hooks/hook.py中定义了Hook的基类以及Hook的注册器HOOKS。作为基类,Hook本身没有实现具体的函数,只是提供了before_run、after_run等6个接口函数,其他所有的Hooks都通过继承Hook类并重写相应的函数完整指定功能。
from mmcv.utils import Registry
HOOKS = Registry('hook')
class Hook:
def before_run(self, runner):
pass
def after_run(self, runner):
pass
def before_epoch(self, runner):
pass
def after_epoch(self, runner):
pass
def before_iter(self, runner):
pass
def after_iter(self, runner):
pass
MMCV已经实现了部分常用的Hooks,如下图所示。默认Hook不需要用户自行注册,通过配置文件配置对应的参数即可;定制Hook则需要用户手动注册进去。
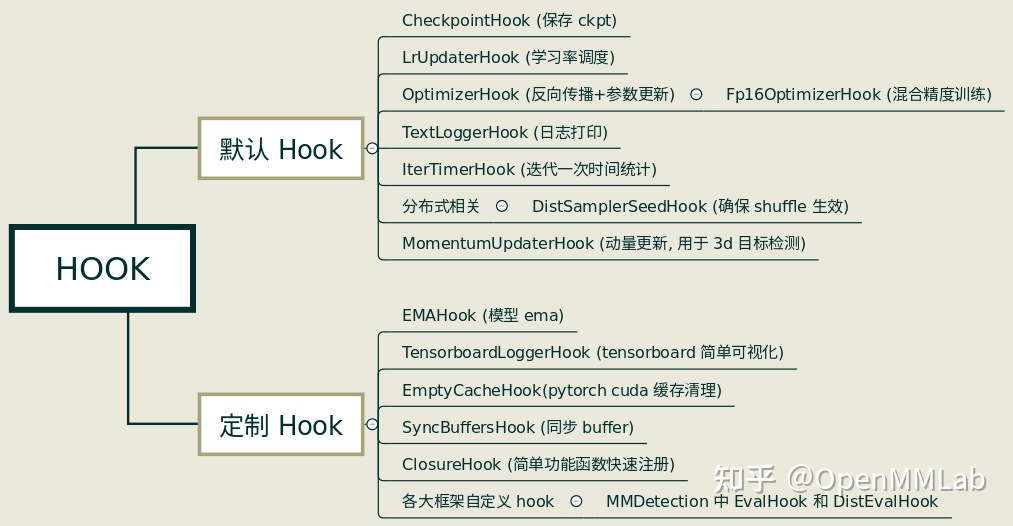
Hook也是一个模块,使用时需要定义、注册、调用3个步骤。
3.1 定义
MMCV实现的Hook都在./mmcv/runner/hooks目录下,这里以CheckpointHook为例介绍一下怎么新建一个Hook。
首先从hook.py中导入注册器HOOKS以及基类Hook。然后新建一个名为CheckpointHook类继承Hook基类,由于Hook基类没有定义构造函数,这里首先必须自己定义__init__函数,然后根据Hook需要实现的功能,重写Hook基类中的一种或几种方法。比如MMCV会在每次训练开始前打印checkpoint的保存路径,会在每次循环结束后或每个epoch执行完成后保存checkpoint,因此CheckpointHook类重写了before_run、after_train_iter和after_train_epoch这3个方法。
from .hook import HOOKS, Hook
@HOOKS.register_module()
class CheckpointHook(Hook):
def __init__(self,
interval=-1,
by_epoch=True,
save_optimizer=True,
out_dir=None,
max_keep_ckpts=-1,
save_last=True,
sync_buffer=False,
file_client_args=None,
**kwargs):
...
def before_run(self, runner):
...
def after_train_iter(self, runner):
...
def after_train_epoch(self, runner):
...
3.2 注册
对于MMCV的默认Hook,在执行runner.run()前会调用BaseRunner类中的register_training_hooks方法进行注册:
def register_training_hooks(self,
lr_config,
optimizer_config=None,
checkpoint_config=None,
log_config=None,
momentum_config=None,
timer_config=dict(type='IterTimerHook'),
custom_hooks_config=None):
"""Register default and custom hooks for training.
Default and custom hooks include:
+----------------------+-------------------------+
| Hooks | Priority |
+======================+=========================+
| LrUpdaterHook | VERY_HIGH (10) |
+----------------------+-------------------------+
| MomentumUpdaterHook | HIGH (30) |
+----------------------+-------------------------+
| OptimizerStepperHook | ABOVE_NORMAL (40) |
+----------------------+-------------------------+
| CheckpointSaverHook | NORMAL (50) |
+----------------------+-------------------------+
| IterTimerHook | LOW (70) |
+----------------------+-------------------------+
| LoggerHook(s) | VERY_LOW (90) |
+----------------------+-------------------------+
| CustomHook(s) | defaults to NORMAL (50) |
+----------------------+-------------------------+
If custom hooks have same priority with default hooks, custom hooks
will be triggered after default hooks.
"""
self.register_lr_hook(lr_config)
self.register_momentum_hook(momentum_config)
self.register_optimizer_hook(optimizer_config)
self.register_checkpoint_hook(checkpoint_config)
self.register_timer_hook(timer_config)
self.register_logger_hooks(log_config)
self.register_custom_hooks(custom_hooks_config)
具体到单个注册函数,比如register_checkpoint_hook(),hook作为一个模块,还是使用build_from_cfg进行实例获取,然后调用BaseRunner类的register_hook()进行注册,这样所有Hook实例就都被纳入到runner中的一个list中。
def register_checkpoint_hook(self, checkpoint_config):
hook = mmcv.build_from_cfg(checkpoint_config, HOOKS)
self.register_hook(hook, priority='NORMAL')
def register_hook(self, hook, priority='NORMAL'):
priority = get_priority(priority)
hook.priority = priority
# 按照priority大小插入当前hook列表
inserted = False
for i in range(len(self._hooks) - 1, -1, -1):
if priority >= self._hooks[i].priority:
self._hooks.insert(i + 1, hook)
inserted = True
break
if not inserted:
self._hooks.insert(0, hook)
3.3 调用
在runner执行过程中,会在特定的程序位点通过call_hook()函数调用相应的Hook。
def train(self, data_loader, **kwargs):
self.model.train()
self.mode = 'train'
self.data_loader = data_loader
self._max_iters = self._max_epochs * len(self.data_loader)
self.call_hook('before_train_epoch')
time.sleep(2) # Prevent possible deadlock during epoch transition
for i, data_batch in enumerate(self.data_loader):
self._inner_iter = i
self.call_hook('before_train_iter')
self.run_iter(data_batch, train_mode=True, **kwargs)
self.call_hook('after_train_iter')
self._iter += 1
self.call_hook('after_train_epoch')
self._epoch += 1
前面调用register_hook()注册Hook的时候,会根据优先级将Hook加入到self._hooks这个列表中,在执行call_hook()时候,使用for循环就可以很简单的实现按照优先级依次调用指定的Hook了。
def call_hook(self, fn_name):
for hook in self._hooks:
getattr(hook, fn_name)(self)