1、Flink概述
Apache Flink 是一个框架和分布式处理引擎,用于在, 无边界和有边界数据流上进行有状态的计算 ,Flink 能在所有常见集群环境中运行,并能以内存速度和任意规模进行计算。
Apache Flink 功能强大,支持开发和运行多种不同种类的应用程序。它的主要特性包括: 批流一体化、精密的状态管理、事件时间支持以及精确一次的状态一致性保障等 。
Flink 不仅可以运行在包括 YARN、 Mesos、Kubernetes 在内的多种资源管理框架上,还支持在裸机集群上独立部署。在启用高可用选项的情况下,它不存在单点失效问题,适用于大规模数据处理和实时数据分析。
1.1、Flink 的源起和设计理念
Flink 起源于一个叫作 Stratosphere 的项目,它是由 3 所地处柏林的大学和欧洲其他一些大
学在 2010~2014 年共同进行的研究项目,由柏林理工大学的教授沃克尔·马尔科(Volker Markl)
领衔开发。2014 年 4 月,Stratosphere 的代码被复制并捐赠给了 Apache 软件基金会,Flink 就
是在此基础上被重新设计出来的。
在德语中,“flink”一词表示“快速、灵巧”。项目的 logo 是一只彩色的松鼠,当然了,
这不仅是因为 Apache 大数据项目对动物的喜好(是否联想到了 Hadoop、Hive?),更是因为
松鼠这种小动物完美地体现了“快速、灵巧”的特点。
关于 logo 的颜色,还一个有趣的缘由:柏林当地的松鼠非常漂亮,颜色是迷人的红棕色;而 Apache 软件基金会的 logo,刚好也是一根以红棕色为主的渐变色羽毛。于是,Flink 的松鼠 Logo 就设计成了红棕色,而且拥有一个漂亮的渐变色尾巴,尾巴的配色与 Apache 软件基金会的 logo 一致。这只松鼠色彩炫目,既呼应了 Apache 的风格,似乎也预示着 Flink 未来将要大放异彩。

从命名上,我们也可以看出 Flink 项目对于自身特点的定位,那就是对于大数据处理,要
做到快速和灵活。
- 2014 年 8 月,Flink 第一个版本 0.6 正式发布(至于 0.5 之前的版本,那就是在
Stratosphere 名下的了)。与此同时 Fink 的几位核心开发者创办了 Data Artisans 公司,
主要做 Fink 的商业应用,帮助企业部署大规模数据处理解决方案。 - 2014 年 12 月,Flink 项目完成了孵化,一跃成为 Apache 软件基金会的顶级项目。
- 2015 年 4 月,Flink 发布了里程碑式的重要版本 0.9.0,很多国内外大公司也正是从这
时开始关注、并参与到 Flink 社区建设的。 - 2019 年 1 月,长期对 Flink 投入研发的阿里巴巴,以 9000 万欧元的价格收购了 Data
Artisans 公司;之后又将自己的内部版本 Blink 开源,继而与 8 月份发布的 Flink 1.9.0版本进行了合并。自此之后,Flink 被越来越多的人所熟知,成为当前最火的新一代大数据处理框架。
并且Flink 就拥有一个非常活跃的社区,而且一直在快速成长。到目前为止,Flink的代码贡献者(Contributors)已经超过 800 人,并且 Flink 已经发展成为最复杂的开源流处理引擎之一,得到了广泛的应用。
根据 Apache 软件基金会发布的 2020 年度报告,Flink 项目的社区参与和贡献依旧非常活跃,在 Apache 旗下的众多项目中保持着多项领先。
在 Flink 官网主页的顶部可以看到,项目的核心目标,是“数据流上的有状态计算”(Stateful
Computations over Data Streams)。
具体定位是: Apache Flink 是一个框架和分布式处理引擎,用于对无界和有界数据流进行有状态计算。Flink 被设计在所有常见的集群环境中运行,以内存执行速度和任意规模来执行计算。
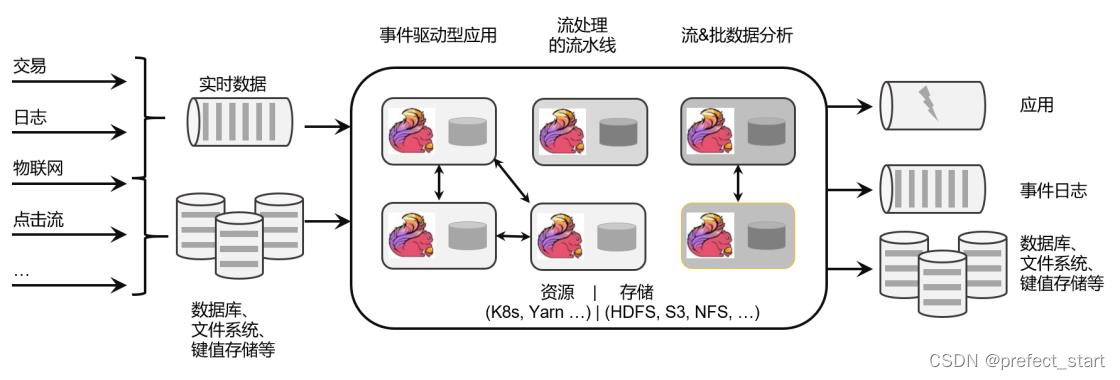
1.2、Flink 的应用
Flink 是一个大数据流处理引擎,它可以为不同的行业提供大数据实时处理的解决方案。随着 Flink 的快速发展完善,如今在世界范围许多公司都可以见到 Flink 的身影。
Flink 在国内热度尤其高,一方面是因为阿里的贡献和带头效应,另一方面也跟中国的应用场景密切相关。中国的人口规模与互联网使用普及程度,决定了对大数据处理的速度要求越来越高,也迫使中国的互联网企业去追逐更高的数据处理效率。
1.2.1、Flink 在企业中的应用
使用Flink的公司主要有以下知名企业用户等

1.2.2、Flink 主要的应用场景
Flink 本身的定位,它是一个大数据流式处理引擎,处理的是流式数据,也就是“数据流”(Data Flow)。顾名思义,数据流的含义是,数据并不是收集好的,而是像水流一样,是一组有序的数据序列,逐个到来、逐个处理。由于数据来到之后就会被即刻处理,所以流处理的一大特点就是“快速”,也就是良好的实时性。Flink 适合的场景,其实也就是需要实时处理数据流的场景。
1.2.2.1、电商和市场营销
举例:实时数据报表、广告投放、实时推荐在电商行业中,网站点击量是统计 PV、UV 的重要来源,也是如今“流量经济”的最主要数据指标。
很多公司的营销策略,比如广告的投放,也是基于点击量来决定的。另外,在网站上提供给用户的实时推荐,往往也是基于当前用户的点击行为做出的。网站获得的点击数据可能是连续且不均匀的,还可能在同一时间大量产生,这是典型的数据流。
如果我们希望把它们全部收集起来,再去分析处理,就会面临很多问题:
- 首先,我们需要很大的空间来存储数据;
- 其次,收集数据的过程耗去了大量时间,统计分析结果的实时性就大大降低了;
- 另外,分布式处理无法保证数据的顺序,如果我们只以数据进入系统的时间为准,可能导致最终结果计算错误。
我们需要的是直接处理数据流,而 Flink 就可以做到这一点。
1.2.2.2、物联网(IOT)
举例:传感器实时数据采集和显示、实时报警,交通运输业物联网是流数据被普遍应用的领域。各种传感器不停获得测量数据,并将它们以流的形式传输至数据中心。而数据中心会将数据处理分析之后,得到运行状态或者报警信息,实时地显示在监控屏幕上。所以在物联网中,低延迟的数据传输和处理,以及准确的数据分析通常很关键。
交通运输业也体现了流处理的重要性。比如说,如今高铁运行主要就是依靠传感器检测数据,测量数据包括列车的速度和位置,以及轨道周边的状况。这些数据会从轨道传给列车,再从列车传到沿途的其他传感器;与此同时,数据报告也被发送回控制中心。因为列车处于高速行驶状态,因此数据处理的实时性要求是极高的。如果流数据没有被及时正确处理,调整意见和警告就不能相应产生,后果可能会非常严重。
1.2.2.3、物流配送和服务业
举例:订单状态实时更新、通知信息推送在很多服务型应用中,都会涉及订单状态的更新和通知的推送。这些信息基于事件触发,不均匀地连续不断生成,处理之后需要及时传递给用户。这也是非常典型的数据流的处理。
1.2.2.4、银行和金融业
举例:实时结算和通知推送,实时检测异常行为银行和金融业是另一个典型的应用行业。
用户的交易行为是连续大量发生的,银行面对的是海量的流式数据。由于要处理的交易数据量太大,以前的银行是按天结算的,汇款一般都要隔天才能到账。所以有一个说法叫作“银行家工作时间”,说的就是银行家不仅不需要 996,甚至下午早早就下班了:因为银行需要早点关门进行结算,这样才能保证第二天营业之前算出准确的账。
这显然不能满足我们快速交易的需求。在全球化经济中,能够提供 24 小时服务变得越来越重要。现在交易和报表都会快速准确地生成,我们跨行转账也可以做到瞬间到账,还可以接到实时的推送通知。这就需要我们能够实时处理数据流。
另外,信用卡欺诈的检测也需要及时的监控和报警。一些金融交易市场,对异常交易行为的及时检测可以更好地进行风险控制;还可以对异常登录进行检测,从而发现钓鱼式攻击,从而避免巨大的损失。
1.3、流式数据处理的发展和演变
1.3.1、流处理和批处理
数据处理有不同的方式。
- 对于具体应用来说,有些场景数据是一个一个来的,是一组有序的数据序列,我们把它叫作“数据流”;
- 而有些场景的数据,本身就是一批同时到来,是一个有限的数据集,这就是批量数据(有时也直接叫数据集)。
处理数据流,当然应该“来一个就处理一个”,这种数据处理模式就叫作流处理,因为这种处理是即时的,所以也叫实时处理。
与之对应,处理批量数据自然就应该一批读入、一起计算,这种方式就叫作批处理,也叫作离线处理。
1.3.2、传统事务处理
IT 互联网公司往往会用不同的应用程序来处理各种业务。比如内部使用的企业资源规划(ERP)系统、客户关系管理(CRM)系统,还有面向客户的 Web 应用程序。
这些系统一般都会进行分层设计:“计算层”就是应用程序本身,用于数据计算和处理;而“存储层”往往是传统的关系型数据库,用于数据存储。
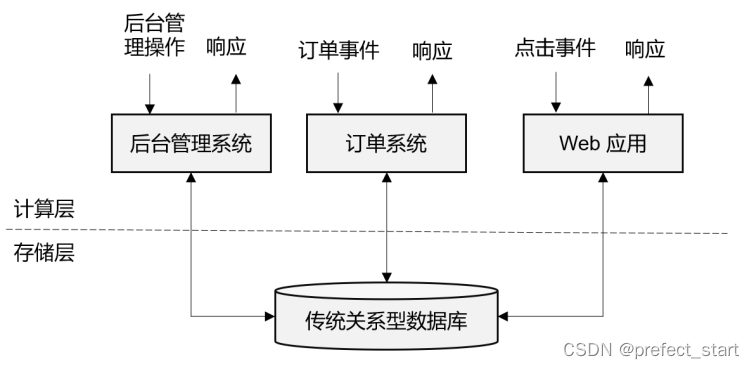
这里的应用程序在处理数据的模式上有共同之处:接收的数据是持续生成的事件,比如用户的点击行为,客户下的订单,或者操作人员发出的请求。处理事件时,应用程序需要先读取远程数据库的状态,然后按照处理逻辑得到结果,将响应返回给用户,并更新数据库状态。一般来说,一个数据库系统可以服务于多个应用程序,它们有时会访问相同的数据库或表。这就是传统的“事务处理”架构,系统所处理的连续不断的事件,其实就是一个数据流,而对于每一个事件,系统都在收到之后进行相应的处理,这也是符合流处理的原则的。
所以可以说,传统的事务处理,就是最基本的流处理架构。对于各种事件请求,事务处理的方式能够保证实时响应,好处是一目了然的。但是我们知道,这样的架构对表和数据库的设计要求很高;当数据规模越来越庞大、系统越来越复杂时,可能需要对表进行重构,而且一次联表查询也会花费大量的时间,甚至不能及时得到返回结果。
1.3.3、有状态的流处理
不难想到,如果我们对于事件流的处理非常简单,例如收到一条请求就返回一个“收到”,那就可以省去数据库的查询和更新了,但是这样的处理是没什么实际意义的。
在现实的应用中,往往需要还其他一些额外数据。我们可以把需要的额外数据保存成一个“状态”,然后针对这条数据进行处理,并且更新状态。在传统架构中,这个状态就是保存在数据库里的。这就是所谓的“有状态的流处理”。
为了加快访问速度,我们可以直接将状态保存在本地内存,如下图所示,当应用收到一个新事件时,它可以从状态中读取数据,也可以更新状态。而当状态是从内存中读写的时候,这就和访问本地变量没什么区别了,实时性可以得到极大的提升。另外,数据规模增大时,我们也不需要做重构,只需要构建分布式集群,各自在本地计算就可以了,可扩展性也变得更好。
因为采用的是一个分布式系统,所以还需要保护本地状态,防止在故障时数据丢失。我们可以定期地将应用状态的一致性检查点(checkpoint)存盘,写入远程的持久化存储,遇到故障时再去读取进行恢复,这样就保证了更好的容错性。
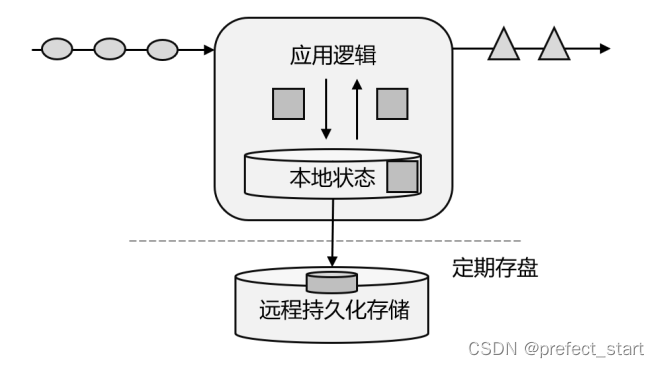
有状态的流处理是一种通用而且灵活的设计架构,可用于许多不同的场景。具体来说,有
以下几种典型应用。
1.3.3.1、事件驱动型(Event-Driven)应用
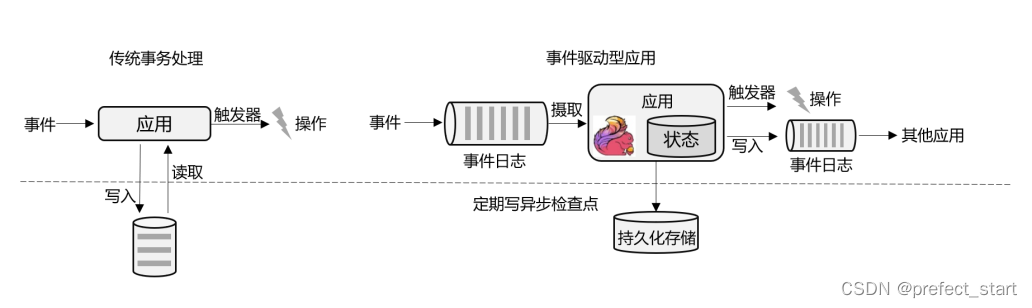
事件驱动型应用是一类具有状态的应用,它从一个或多个事件流提取数据,并根据到来的事件触发计算、状态更新或其他外部动作。比较典型的就是以 Kafka 为代表的消息队列几乎都是事件驱动型应用。
这其实跟传统事务处理本质上是一样的,区别在于基于有状态流处理的事件驱动应用,不再需要查询远程数据库,而是在本地访问它们的数据,如上图所示,这样在吞吐量和延迟方面就可以有更好的性能。
另外远程持久性存储的检查点保证了应用可以从故障中恢复。检查点可以异步和增量地完成,因此对正常计算的影响非常小。
1.3.3.2、数据分析(Data Analysis)型应用
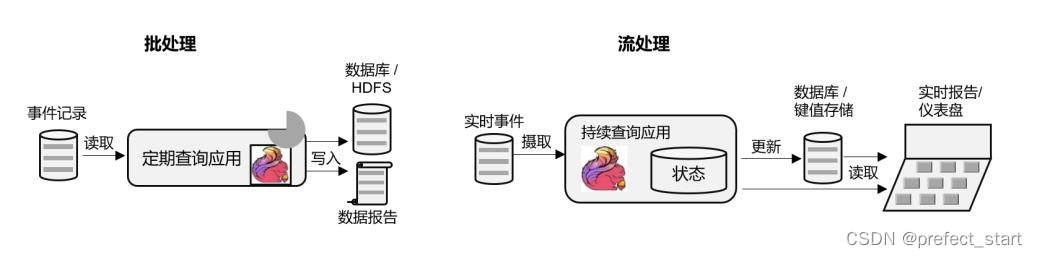
所谓的数据分析,就是从原始数据中提取信息和发掘规律。传统上,数据分析一般是先将数据复制到数据仓库(Data Warehouse),然后进行批量查询。如果数据有了更新,必须将最新数据添加到要分析的数据集中,然后重新运行查询或应用程序。
如今,Apache Hadoop 生态系统的组件,已经是许多企业大数据架构中不可或缺的组成部分。现在的做法一般是将大量数据(如日志文件)写入 Hadoop 的分布式文件系统(HDFS)、S3 或 HBase 等批量存储数据库,以较低的成本进行大容量存储。然后可以通过 SQL-on-Hadoop类的引擎查询和处理数据,比如大家熟悉的 Hive。这种处理方式,是典型的批处理,特点是可以处理海量数据,但实时性较差,所以也叫离线分析。
如果我们有了一个复杂的流处理引擎,数据分析其实也可以实时执行。流式查询或应用程序不是读取有限的数据集,而是接收实时事件流,不断生成和更新结果。结果要么写入外部数据库,要么作为内部状态进行维护。
Apache Flink 同事支持流式与批处理的数据分析应用,如上图所示。与批处理分析相比,流处理分析最大的优势就是低延迟,真正实现了实时。另外,流处理不需要去单独考虑新数据的导入和处理,实时更新本来就是流处理的基本模式。当前企业对流式数据处理的一个热点应用就是实时数仓,很多公司正是基于 Flink 来实现的。
1.3.3.3、数据管道(Data Pipeline)型应用
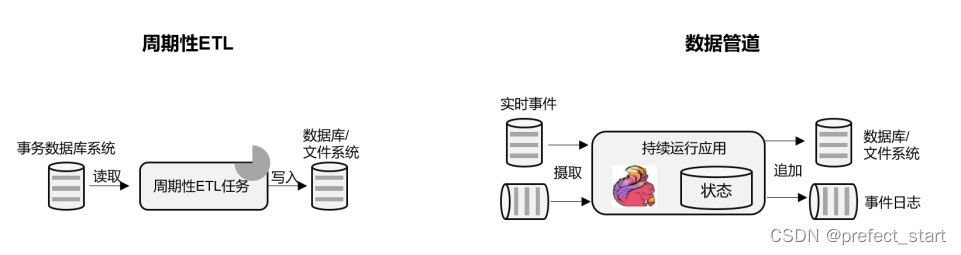
ETL 也就是数据的提取、转换、加载,是在存储系统之间转换和移动数据的常用方法。在数据分析的应用中,通常会定期触发 ETL 任务,将数据从事务数据库系统复制到分析数据库或数据仓库。
所谓数据管道的作用与 ETL 类似。它们可以转换和扩展数据,也可以在存储系统之间移动数据。不过如果我们用流处理架构来搭建数据管道,这些工作就可以连续运行,而不需要再去周期性触发了。比如,数据管道可以用来监控文件系统目录中的新文件,将数据写入事件日志。连续数据管道的明显优势是减少了将数据移动到目的地的延迟,而且更加通用,可以用于更多的场景。
有状态的流处理架构上其实并不复杂,很多用户基于这种思想开发出了自己的流处理系统,这就是第一代流处理器。Apache Storm 就是其中的代表。Storm 可以说是开源流处理的先锋,最早是由 Nathan Marz 和创业公司 BackType 的一个团队开发的,后来才成为 Apache 软件基金会下属的项目。Storm 提供了低延迟的流处理,但是它也为实时性付出了代价:很难实现高吞吐,而且无法保证结果的正确性。用更专业的话说,它并不能保证“精确一次”(exactly-once);即便是它能够保证的一致性级别,开销也相当大。
1.3.3.4、Lambda 架构
对于有状态的流处理,当数据越来越多时,我们必须用分布式的集群架构来获取更大的吞吐量。但是分布式架构会带来另一个问题: 怎样保证数据处理的顺序是正确的呢?
对于批处理来说,这并不是一个问题。因为所有数据都已收集完毕,我们可以根据需要选择、排列数据,得到想要的结果。
可如果我们采用“来一个处理一个”的流处理,就可能出现“乱序”的现象:本来先发生的事件,因为分布处理的原因滞后了,怎么解决这个问题呢?以 Storm 为代表的第一代分布式开源流处理器,主要专注于具有毫秒延迟的事件处理,特点就是一个字“快”;而对于准确性和结果的一致性,是不提供内置支持的,因为结果有可能取决于到达事件的时间和顺序。另外,第一代流处理器通过检查点来保证容错性,但是故障恢复的时候,即使事件不会丢失,也有可能被重复处理——所以无法保证 exactly-once。
与批处理器相比,可以说第一代流处理器牺牲了结果的准确性,用来换取更低的延迟。而批处理器恰好反过来,牺牲了实时性,换取了结果的准确。如果可以让二者做个结合,不就可以同时提供快速和准确的结果了吗?正是基于这样的思想,Lambda 架构被设计出来,如下图所示。我们可以认为这是第二代流处理架构,但事实上,它只是第一代流处理器和批处理器的简单合并。
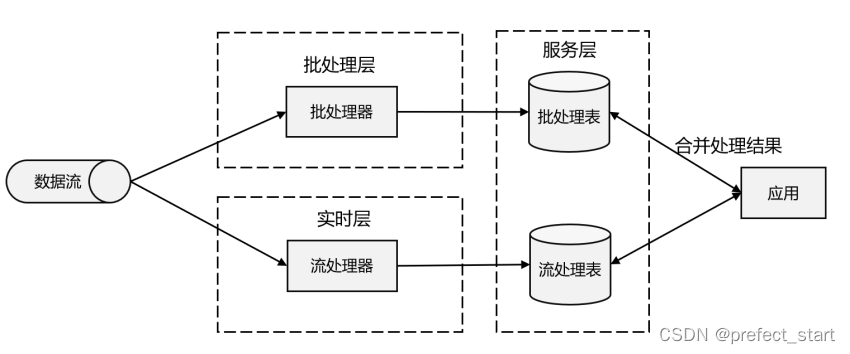
Lambda 架构主体是传统批处理架构的增强。它的“批处理层”(Batch Layer)就是由传统的批处理器和存储组成,而“实时层”(Speed Layer)则由低延迟的流处理器实现。数据到达之后,两层处理双管齐下,一方面由流处理器进行实时处理,另一方面写入批处理存储空间,等待批处理器批量计算。流处理器快速计算出一个近似结果,并将它们写入“流处理表”中。而批处理器会定期处理存储中的数据,将准确的结果写入批处理表,并从快速表中删除不准确的结果。最终,应用程序会合并快速表和批处理表中的结果,并展示出来。
Lambda 架构现在已经不再是最先进的,但仍在许多地方使用。它的优点非常明显,就是兼具了批处理器和第一代流处理器的特点,同时保证了低延迟和结果的准确性。
而它的缺点同样非常明显。首先,Lambda 架构本身就很难建立和维护;而且,它需要我们对一个应用程序,做出两套语义上等效的逻辑实现,因为批处理和流处理是两套完全独立的系统,它们的 API也完全不同。为了实现一个应用,付出了双倍的工作量,这对程序员显然不够友好。
1.3.3.5、新一代流处理器
之前的分布式流处理架构,都有明显的缺陷,人们也一直没有放弃对流处理器的改进和完善。终于,在原有流处理器的基础上,新一代分布式开源流处理器诞生了。为了与之前的系统区分,我们一般称之为第三代流处理器,代表当然就是 Flink。
第三代流处理器通过巧妙的设计,完美解决了乱序数据对结果正确性的影响。这一代系统还做到了精确一次(exactly-once)的一致性保障,是第一个具有一致性和准确结果的开源流处理器。另外,先前的流处理器仅能在高吞吐和低延迟中二选一,而新一代系统能够同时提供这两个特性。所以可以说,这一代流处理器仅凭一套系统就完成了 Lambda 架构两套系统的工作,它的出现使得 Lambda 架构黯然失色。
除了低延迟、容错和结果准确性之外,新一代流处理器还在不断添加新的功能,例如高可用的设置,以及与资源管理器(如 YARN 或 Kubernetes)的紧密集成等等。
1.4、 Flink 的特性总结
1.4.1、 Flink 的核心特性
Flink 区别与传统数据处理框架的特性如下。
- 高吞吐和低延迟。每秒处理数百万个事件,毫秒级延迟。
- 结果的准确性。Flink 提供了事件时间(event-time)和处理时间(processing-time)语义。对于乱序事件流,事件时间语义仍然能提供一致且准确的结果。
- 精确一次(exactly-once)的状态一致性保证。
- 可以连接到最常用的存储系统,如 Apache Kafka、Apache Cassandra、Elasticsearch、JDBC、Kinesis 和(分布式)文件系统,如 HDFS 和 S3。
- 高可用。本身高可用的设置,加上与 K8s,YARN 和 Mesos 的紧密集成,再加上从故障中快速恢复和动态扩展任务的能力,Flink 能做到以极少的停机时间 7×24 全天候运行。
- 能够更新应用程序代码并将作业(jobs)迁移到不同的 Flink 集群,而不会丢失应用程序的状态。
1.4.2、 分层 API
除了上述这些特性之外,Flink 还是一个非常易于开发的框架,因为它拥有易于使用的分
层 API,整体 API 分层如下图所示。
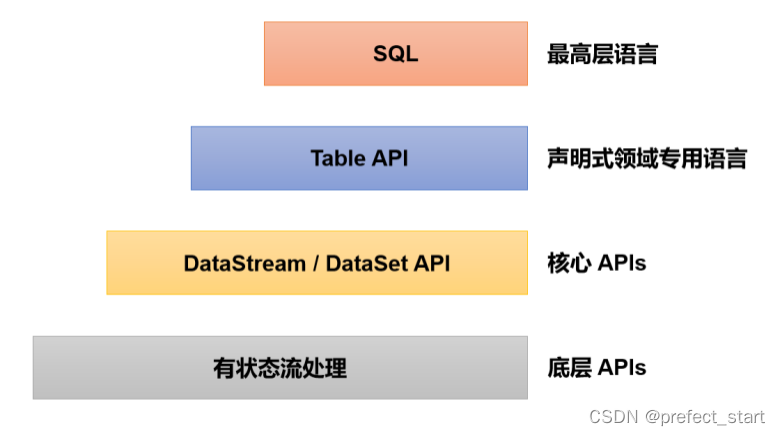
最底层级的抽象仅仅提供了有状态流,它将处理函数(Process Function)嵌入到了DataStream API 中。底层处理函数(Process Function)与 DataStream API 相集成,可以对某些操作进行抽象,它允许用户可以使用自定义状态处理来自一个或多个数据流的事件,且状态具有一致性和容错保证。除此之外,用户可以注册事件时间并处理时间回调,从而使程序可以处理复杂的计算。
实际上,大多数应用并不需要上述的底层抽象,而是直接针对核心 API(Core APIs) 进行编程,比如 DataStream API(用于处理有界或无界流数据)以及 DataSet API(用于处理有界数据集)。这些 API 为数据处理提供了通用的构建模块,比如由用户定义的多种形式的转换(transformations)、连接(joins)、聚合(aggregations)、窗口(windows)操作等。
DataSet API 为有界数据集提供了额外的支持,例如循环与迭代。这些 API 处理的数据类型以类(classes)的形式由各自的编程语言所表示。
Table API 是以表为中心的声明式编程,其中表在表达流数据时会动态变化。Table API 遵循关系模型:表有二维数据结构(schema)(类似于关系数据库中的表),同时 API 提供可比较的操作,例如 select、join、group-by、aggregate 等。尽管 Table API 可以通过多种类型的用户自定义函数(UDF)进行扩展,仍不如核心 API更具表达能力,但是使用起来代码量更少,更加简洁。除此之外,Table API 程序在执行之前会使用内置优化器进行优化。
我们可以在表与 DataStream/DataSet 之间无缝切换,以允许程序将 Table API 与DataStream 以及 DataSet 混合使用。
Flink 提供的最高层级的抽象是 SQL。这一层抽象在语法与表达能力上与 Table API 类似,但是是以 SQL 查询表达式的形式表现程序。SQL 抽象与 Table API 交互密切,同时 SQL 查询可以直接在 Table API 定义的表上执行。目前 Flink SQL 和 Table API 还在开发完善的过程中,很多大厂都会二次开发符合自己需要的工具包。
而 DataSet 作为批处理 API 实际应用较少,2020 年 12 月 8 日发布的新版本 1.12.0, 已经完全实现了真正的流批一体,DataSet API 已处于软性弃用(soft deprecated)的状态。用Data Stream API 写好的一套代码, 即可以处理流数据, 也可以处理批数据,只需要设置不同的执行模式。这与之前版本处理有界流的方式是不一样的,Flink 已专门对批处理数据做了优化处理。
1.5、 Flink vs Spark
Apache Spark 是一个通用大规模数据分析引擎。它提出的内存计算概念让大家耳目一新,得以从 Hadoop 繁重的 MapReduce 程序中解脱出来,可以说是划时代的大数据处理框架。除了计算速度快、可扩展性强,Spark 还为批处理(SparkSQL)、流处理(Spark Streaming)、机器学习(Spark MLlib)、图计算(Spark GraphX)提供了统一的分布式数据处理平台,整个生态经过多年的蓬勃发展已经非常完善。
1.5.1、 Flink vs Spark
数据处理的基本方式,可以分为 批处理和流处理 两种。
- 批处理针对的是有界数据集,非常适合需要访问海量的全部数据才能完成的计算工作,一般用于离线统计。
- 流处理主要针对的是数据流,特点是无界、实时, 对系统传输的每个数据依次执行操作,一般用于实时统计。
从根本上说,Spark 和 Flink 采用了完全不同的数据处理方式。可以说,两者的世界观是截然相反的。
Spark 以批处理为根本,并尝试在批处理之上支持流计算;在 Spark 的世界观中,万物皆批次,离线数据是一个大批次,而实时数据则是由一个一个无限的小批次组成的。所以对于流处理框架 Spark Streaming 而言,其实并不是真正意义上的“流”处理,而是“微批次”(micro-batching)处理,如下图所示。

而 Flink 则认为,流处理才是最基本的操作,批处理也可以统一为流处理。在 Flink 的世界观中,万物皆流,实时数据是标准的、没有界限的流,而离线数据则是有界限的流。如下图所示,就是所谓的无界流和有界流。
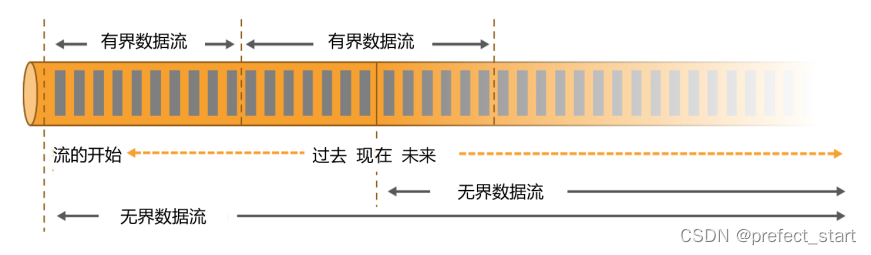
- 无界数据流(Unbounded Data Stream)
所谓无界数据流,就是有头没尾,数据的生成和传递会开始但永远不会结束,如上图所示。我们无法等待所有数据都到达,因为输入是无界的,永无止境,数据没有“都到达”的时候。所以对于无界数据流,必须连续处理,也就是说必须在获取数据后立即处理。在处理无界流时,为了保证结果的正确性,我们必须能够做到按照顺序处理数据。 - 有界数据流(Bounded Data Stream)
有界数据流有明确定义的开始和结束,如上图所示,所以我们可以通过获取所有数据来处理有界流。处理有界流就不需要严格保证数据的顺序了,因为总可以对有界数据集进行排序。有界流的处理也就是批处理。
正因为这种架构上的不同,Spark 和 Flink 在不同的应用领域上表现会有差别。一般来说,Spark 基于微批处理的方式做同步总有一个“攒批”的过程,所以会有额外开销,因此无法在流处理的低延迟上做到极致。在低延迟流处理场景,Flink 已经有明显的优势。而在海量数据的批处理领域,Spark 能够处理的吞吐量更大,加上其完善的生态和成熟易用的 API,目前同样优势比较明显。
1.5.2、 数据模型和运行架构
Spark 和 Flink 在底层实现最主要的差别就在于数据模型不同。
-
Spark 底层数据模型是弹性分布式数据集(RDD),Spark Streaming 进行微批处理的底层接口 DStream,实际上处理的也是一组组小批数据 RDD 的集合。可以看出,Spark 在设计上本身就是以批量的数据集作为基准的,更加适合批处理的场景。
-
Flink 的基本数据模型是数据流(DataFlow),以及事件(Event)序列。Flink 基本上是完全按照 Google 的 DataFlow 模型实现的,所以从底层数据模型上看,Flink 是以处理流式数据作为设计目标的,更加适合流处理的场景。
数据模型不同,对应在运行处理的流程上,自然也会有不同的架构。
- Spark 做批计算,需要将任务对应的 DAG 划分阶段(Stage),一个完成后经过 shuffle 再进行下一阶段的计算。
- Flink 是标准的流式执行模式,一个事件在一个节点处理完后可以直接发往下一个节点进行处理。
1.5.3、 Spark 还是 Flink
如果在工作中需要从 Spark 和 Flink 这两个主流框架中选择一个来进行实时流处理,我们更加推荐使用 Flink,主要的原因有:
- Flink 的延迟是毫秒级别,而 Spark Streaming 的延迟是秒级延迟。
- Flink 提供了严格的精确一次性语义保证。
- Flink 的窗口 API 更加灵活、语义更丰富。
- Flink 提供事件时间语义,可以正确处理延迟数据。
- Flink 提供了更加灵活的对状态编程的 API。
2、Flink 快速上手
2.1、环境准备
- 系统环境为 Windows 10。
- 需提前安装 Java 8。
- 集成开发环境(IDE)使用 IntelliJ IDEA。
- Maven 和 Git,Maven 用来管理项目依赖;通过 Git 可以轻松获取我们的示例代码,并进行本地代码的版本控制。
2.2、WordCount编写
2.2.1、环境准备
- pom
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>org.song</groupId>
<artifactId>flink_demo</artifactId>
<version>1.0-SNAPSHOT</version>
<properties>
<flink.version>1.13.0</flink.version>
<java.version>1.8</java.version>
<scala.binary.version>2.12</scala.binary.version>
<slf4j.version>1.7.30</slf4j.version>
</properties>
<dependencies>
<!-- 引入 Flink 相关依赖-->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-java</artifactId>
<version>${
flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java_${
scala.binary.version}</artifactId>
<version>${
flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients_${
scala.binary.version}</artifactId>
<version>${
flink.version}</version>
</dependency>
<!-- 引入日志管理相关依赖-->
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-api</artifactId>
<version>${
slf4j.version}</version>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
<version>${
slf4j.version}</version>
</dependency>
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-to-slf4j</artifactId>
<version>2.14.0</version>
</dependency>
</dependencies>
</project>
- 日志
log4j.rootLogger=error, stdout
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern=%-4r [%t] %-5p %c %x - %m%n
2.2.2、批处理的方式运行WordCount
- 代码实现
package com.song.wc;
import org.apache.flink.api.common.typeinfo.Types;
import org.apache.flink.api.java.ExecutionEnvironment;
import org.apache.flink.api.java.operators.AggregateOperator;
import org.apache.flink.api.java.operators.DataSource;
import org.apache.flink.api.java.operators.FlatMapOperator;
import org.apache.flink.api.java.operators.UnsortedGrouping;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.util.Collector;
/**
* 批处理的方式运行WordCount
*/
public class BatchWordCount {
public static void main(String[] args) throws Exception {
// 1. 创建执行环境
ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
// 2. 从文件读取数据 按行读取(存储的元素就是每行的文本)
DataSource<String> lineDS = env.readTextFile("input/words.txt");
// 3. 转换数据格式
FlatMapOperator<String, Tuple2<String, Long>> wordAndOne = lineDS
.flatMap((String line, Collector<Tuple2<String, Long>> out) -> {
String[] words = line.split(" ");
for (String word : words) {
out.collect(Tuple2.of(word, 1L));
}
}).returns(Types.TUPLE(Types.STRING, Types.LONG));
//当 Lambda 表达式使用 Java 泛型的时候, 由于泛型擦除的存在, 需要显示的声明类型信息
// 4. 按照 word 进行分组
UnsortedGrouping<Tuple2<String, Long>> wordAndOneUG = wordAndOne.groupBy(0);
// 5. 分组内聚合统计
AggregateOperator<Tuple2<String, Long>> sum = wordAndOneUG.sum(1);
// 6. 打印结果
sum.print();
}
}
- 运行结果
(flink,1)
(world,1)
(java,1)
(hello,3)
- 代码说明和注意事项:
- Flink 在执行应用程序前应该获取执行环境对象,也就是运行时上下文环境。ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
- 直接调用执行环境的 readTextFile 方法,可以从文件中读取数据。
- 我们的目标是将每个单词对应的个数统计出来,所以调用 flatmap 方法可以对一行文字进行分词转换。将文件中每一行文字拆分成单词后,要转换成(word,count)形式的二元组,初始 count 都为 1。returns 方法指定的返回数据类型 Tuple2,就是 Flink 自带的二元组数据类型。
- 在分组时调用了 groupBy 方法,它不能使用分组选择器,只能采用位置索引或属性名称进行分组。
// 使用索引定位
dataStream.groupBy(0)
// 使用类属性名称
dataStream.groupBy("id")
- 在分组之后调用 sum 方法进行聚合,同样只能指定聚合字段的位置索引或属性名称。
这种代码的实现方式,是基于 DataSet API 的,也就是我们对数据的处理转换,是看作数据集来进行操作的。事实上 Flink 本身是流批统一的处理架构,批量的数据集本质上也是流,没有必要用两套不同的 API 来实现。所以从 Flink 1.12 开始,官方推荐的做法是直接使用 DataStream API,在提交任务时通过将执行模式设为 BATCH 来进行批处理,并且DataSet API 就已经处于“软弃用”(soft deprecated)的状态,在实际应用中我们只要维护一套 DataStream API 就可以了。
2.2.3、有界流的方式运行WordCount
- 代码实现
package com.song.wc;
import org.apache.flink.api.common.typeinfo.Types;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.KeyedStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;
import java.util.Arrays;
/**
* 有界流的方式运行WordCount
*/
public class BoundedStreamWordCount {
public static void main(String[] args) throws Exception {
// 1. 创建流式执行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 2. 读取文件
DataStreamSource<String> lineDSS = env.readTextFile("input/words.txt");
// 3. 转换数据格式
SingleOutputStreamOperator<Tuple2<String, Long>> wordAndOne = lineDSS
.flatMap((String line, Collector<String> words) -> Arrays.stream(line.split(" ")).forEach(words::collect))
.returns(Types.STRING)
.map(word -> Tuple2.of(word, 1L))
.returns(Types.TUPLE(Types.STRING, Types.LONG));
// 4. 分组
KeyedStream<Tuple2<String, Long>, String> wordAndOneKS = wordAndOne.keyBy(t -> t.f0);
// 5. 求和
SingleOutputStreamOperator<Tuple2<String, Long>> result = wordAndOneKS.sum(1);
// 6. 打印
result.print();
// 7. 执行
env.execute();
}
}
- 运行结果
4> (java,1)
6> (hello,1)
16> (flink,1)
6> (hello,2)
11> (world,1)
6> (hello,3)
与批处理的结果是完全不同的。
- 批处理针对每个单词,只会输出一个最终的统计个数;
- 在流处理的打印结果中,“hello”这个单词每出现一次,都会有一个频次统计数据输出。这就是流处理的特点,数据逐个处理,每来一条数据就会处理输出一次。
在开发环境里,会通过多线程来模拟 Flink 集群运行。所以这里结果前的数字,其实就指示了本地执行的不同线程,对应着 Flink 运行时不同的并行资源。
另外需要说明,这里显示的编号为 1~16,是由于运行电脑的 CPU 是 16 核,所以默认模拟的并行线程有 16 个。这段代码不同的运行环境,得到的结果会是不同的。
2.2.4、无界流的方式运行WordCount
- 代码实现
package com.song.wc;
import org.apache.flink.api.common.typeinfo.Types;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.KeyedStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;
import java.util.Arrays;
/**
* 无界流的方式运行WordCount
*/
public class StreamWordCount {
public static void main(String[] args) throws Exception {
// 1. 创建流式执行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 2. 读取文本流
DataStreamSource<String> lineDSS = env.socketTextStream("hadoop100",
7777);
// 3. 转换数据格式
SingleOutputStreamOperator<Tuple2<String, Long>> wordAndOne = lineDSS.flatMap((String line, Collector<String> words) -> {
Arrays.stream(line.split(" ")).forEach(words::collect);
})
.returns(Types.STRING)
.map(word -> Tuple2.of(word, 1L))
.returns(Types.TUPLE(Types.STRING, Types.LONG));
// 4. 分组
KeyedStream<Tuple2<String, Long>, String> wordAndOneKS = wordAndOne.keyBy(t -> t.f0);
// 5. 求和
SingleOutputStreamOperator<Tuple2<String, Long>> result = wordAndOneKS.sum(1);
// 6. 打印
result.print();
// 7. 执行
env.execute();
}
}
- 运行结果
输入数据
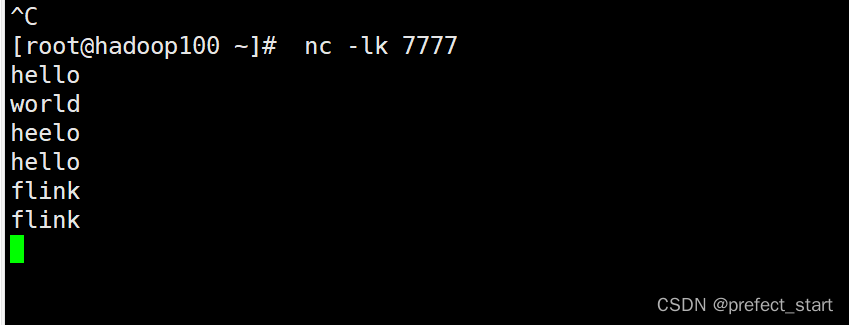
输出结果
6> (hello,1)
11> (world,1)
19> (heelo,1)
6> (hello,2)
16> (flink,1)
16> (flink,2)
- 代码说明
代码说明和注意事项:
- socket 文本流的读取需要配置两个参数:发送端主机名和端口号。这里代码中指定了主机“hadoop100”的 7777 端口作为发送数据的 socket 端口,读者可以根据测试环境自行配置。
- 在实际项目应用中,主机名和端口号这类信息往往可以通过配置文件,或者传入程序运行参数的方式来指定。
- socket文本流数据的发送,可以通过Linux系统自带的netcat工具进行模拟。