12、Flink CEP
12.1、基本概念
12.1.1、CEP 是什么
所谓 CEP,其实就是“复杂事件处理(Complex Event Processing)”的缩写;而 Flink CEP,就是 Flink 实现的一个用于复杂事件处理的库(library)。
那到底什么是“复杂事件处理”呢?就是可以在事件流里,检测到特定的事件组合并进行处理,比如说“连续登录失败”,或者“订单支付超时”等等。具体的处理过程是,把事件流中的一个个简单事件,通过一定的规则匹配组合起来,这就是“复杂事件”;然后基于这些满足规则的一组组复杂事件进行转换处理,得到想要的结果进行输出。
总结起来,复杂事件处理(CEP)的流程可以分成三个步骤:
- 定义一个匹配规则
- 将匹配规则应用到事件流上,检测满足规则的复杂事件
- 对检测到的复杂事件进行处理,得到结果进行输出
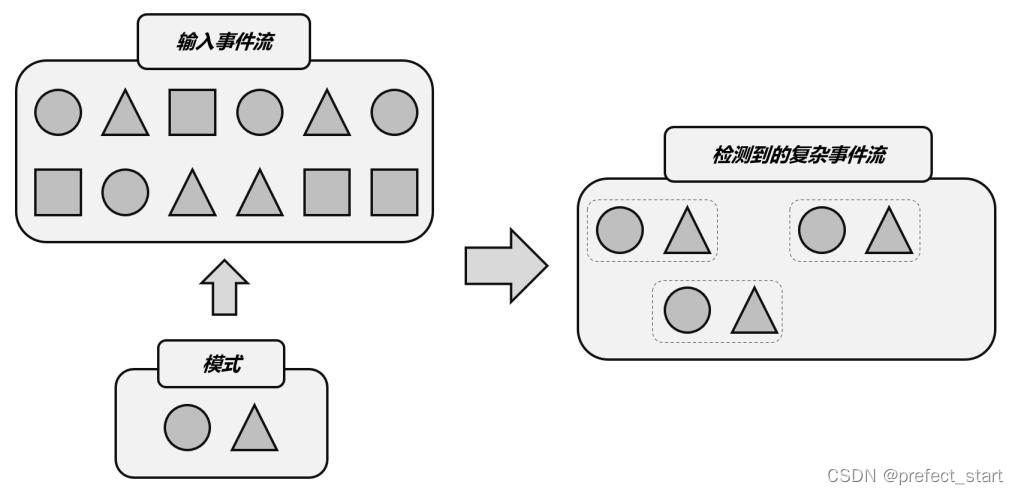
如上图所示,输入是不同形状的事件流,我们可以定义一个匹配规则:在圆形后面紧跟着三角形。那么将这个规则应用到输入流上,就可以检测到三组匹配的复杂事件。它们构成了一个新的“复杂事件流”,流中的数据就变成了一组一组的复杂事件,每个数据都包含了一个圆形和一个三角形。接下来,我们就可以针对检测到的复杂事件,处理之后输出一个提示或报警信息了。
所以,CEP 是针对流处理而言的,分析的是低延迟、频繁产生的事件流。它的主要目的,就是在无界流中检测出特定的数据组合,让我们有机会掌握数据中重要的高阶特征。
12.1.2、模式(Pattern)
CEP 的第一步所定义的匹配规则,我们可以把它叫作“模式”(Pattern)。模式的定义主要就是两部分内容:
- 每个简单事件的特征
- 简单事件之间的组合关系
当然,我们也可以进一步扩展模式的功能。比如,匹配检测的时间限制;每个简单事件是否可以重复出现;对于事件可重复出现的模式,遇到一个匹配后是否跳过后面的匹配;等等。
所谓“事件之间的组合关系”,一般就是定义“谁后面接着是谁”,也就是事件发生的顺序。我们把它叫作“近邻关系”。可以定义严格的近邻关系,也就是两个事件之前不能有任何其他事件;也可以定义宽松的近邻关系,即只要前后顺序正确即可,中间可以有其他事件。另外,还可以反向定义,也就是“谁后面不能跟着谁”。CEP 做的事其实就是在流上进行模式匹配。根据模式的近邻关系条件不同,可以检测连续的事件或不连续但先后发生的事件;模式还可能有时间的限制,如果在设定时间范围内没有满足匹配条件,就会导致模式匹配超时(timeout)。
12.1.3、应用场景
- 风险控制
设定一些行为模式,可以对用户的异常行为进行实时检测。当一个用户行为符合了异常行为模式,比如短时间内频繁登录并失败、大量下单却不支付(刷单),就可以向用户发送通知信息,或是进行报警提示、由人工进一步判定用户是否有违规操作的嫌疑。这样就可以有效地控制用户个人和平台的风险。 - 用户画像
利用 CEP 可以用预先定义好的规则,对用户的行为轨迹进行实时跟踪,从而检测出具有特定行为习惯的一些用户,做出相应的用户画像。基于用户画像可以进行精准营销,即对行为匹配预定义规则的用户实时发送相应的营销推广;这与目前很多企业所做的精准推荐原理是一样的。 - 运维监控
对于企业服务的运维管理,可以利用 CEP 灵活配置多指标、多依赖来实现更复杂的监控模式。
CEP 的应用场景非常丰富。很多大数据框架,如 Spark、Samza、Beam 等都提供了不同的CEP 解决方案,但没有专门的库(library)。而 Flink 提供了专门的 CEP 库用于复杂事件处理,可以说是目前 CEP 的最佳解决方案。
12.2、快速上手
12.2.1、需要引入的依赖
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-cep_${
scala.binary.version}</artifactId>
<version>${
flink.version}</version>
</dependency>
为了精简和避免依赖冲突,Flink 会保持尽量少的核心依赖。所以核心依赖中并不包括任何的连接器(conncetor)和库,这里的库就包括了 SQL、CEP 以及 ML 等等。所以如果想要在 Flink 集群中提交运行 CEP 作业,应该向 Flink SQL 那样将依赖的 jar 包放在/lib 目录下。
12.2.2、一个简单实例
接下来我们考虑一个具体的需求:检测用户行为,如果连续三次登录失败,就输出报警信息。很显然,这是一个复杂事件的检测处理,我们可以使用 Flink CEP 来实现。
我们首先定义数据的类型。所以应该单独定义一个登录事件 POJO 类。具体实现如下:
ublic class LoginEvent {
public String userId;
public String ipAddress;
public String eventType;
public Long timestamp;
public LoginEvent(String userId, String ipAddress, String eventType, Long timestamp) {
this.userId = userId;
this.ipAddress = ipAddress;
this.eventType = eventType;
this.timestamp = timestamp;
}
public LoginEvent() {
}
@Override
public String toString() {
return "LoginEvent{" +
"userId='" + userId + '\'' +
", ipAddress='" + ipAddress + '\'' +
", eventType='" + eventType + '\'' +
", timestamp=" + timestamp +
'}';
}
}
接下来就是业务逻辑的编写。Flink CEP 在代码中主要通过 Pattern API 来实现。之前我们已经介绍过,CEP 的主要处理流程分为三步,对应到 Pattern API 中就是:
- 定义一个模式(Pattern);
- 将Pattern应用到DataStream上,检测满足规则的复杂事件,得到一个PatternStream;
- 对 PatternStream 进行转换处理,将检测到的复杂事件提取出来,包装成报警信息输出
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
// 1. 获取登录事件流,并提取时间戳、生成水位线
KeyedStream<LoginEvent, String> stream = env
.fromElements(
new LoginEvent("user_1", "192.168.0.1", "fail", 2000L),
new LoginEvent("user_1", "192.168.0.2", "fail", 3000L),
new LoginEvent("user_2", "192.168.1.29", "fail", 4000L),
new LoginEvent("user_1", "171.56.23.10", "fail", 5000L),
new LoginEvent("user_2", "192.168.1.29", "fail", 7000L),
new LoginEvent("user_2", "192.168.1.29", "fail", 8000L),
new LoginEvent("user_2", "192.168.1.29", "success", 6000L)
)
.assignTimestampsAndWatermarks(
WatermarkStrategy.<LoginEvent>forBoundedOutOfOrderness(Duration.ofSeconds(3))
.withTimestampAssigner(
new SerializableTimestampAssigner<LoginEvent>() {
@Override
public long extractTimestamp(LoginEvent loginEvent, long l) {
return loginEvent.timestamp;
}
}
)
)
.keyBy(r -> r.userId);
// 2. 定义Pattern,连续的三个登录失败事件
Pattern<LoginEvent, LoginEvent> pattern = Pattern.<LoginEvent>begin("first") // 以第一个登录失败事件开始
.where(new SimpleCondition<LoginEvent>() {
@Override
public boolean filter(LoginEvent loginEvent) throws Exception {
return loginEvent.eventType.equals("fail");
}
})
.next("second") // 接着是第二个登录失败事件
.where(new SimpleCondition<LoginEvent>() {
@Override
public boolean filter(LoginEvent loginEvent) throws Exception {
return loginEvent.eventType.equals("fail");
}
})
.next("third") // 接着是第三个登录失败事件
.where(new SimpleCondition<LoginEvent>() {
@Override
public boolean filter(LoginEvent loginEvent) throws Exception {
return loginEvent.eventType.equals("fail");
}
});
// 3. 将Pattern应用到流上,检测匹配的复杂事件,得到一个PatternStream
PatternStream<LoginEvent> patternStream = CEP.pattern(stream, pattern);
// 4. 将匹配到的复杂事件选择出来,然后包装成字符串报警信息输出
patternStream
.select(new PatternSelectFunction<LoginEvent, String>() {
@Override
public String select(Map<String, List<LoginEvent>> map) throws Exception {
LoginEvent first = map.get("first").get(0);
LoginEvent second = map.get("second").get(0);
LoginEvent third = map.get("third").get(0);
return first.userId + " 连续三次登录失败!登录时间:" + first.timestamp + ", " + second.timestamp + ", " + third.timestamp;
}
})
.print("warning");
env.execute();
}
在上面的程序中,模式中的每个简单事件,会用一个.where()方法来指定一个约束条件,指明每个事件的特征,这里就是 eventType 为“fail”。
而模式里表示事件之间的关系时,使用了 .next() 方法。next 是“下一个”的意思,表示紧挨着、中间不能有其他事件(比如登录成功),这是一个严格近邻关系。第一个事件用.begin()方法表示开始。所有这些“连接词”都可以有一个字符串作为参数,这个字符串就可以认为是当前简单事件的名称。所以我们如果检测到一组匹配的复杂事件,里面就会有连续的三个登录失败事件,它们的名称分别叫作“first”“second”和“third”。
在第三步处理复杂事件时,调用了PatternStream的.select()方法,传入一个PatternSelectFunction 对检测到的复杂事件进行处理。而检测到的复杂事件,会放在一个 Map中;PatternSelectFunction 内.select()方法有一个类型为 Map<String, List>的参数map,里面就保存了检测到的匹配事件。这里的 key 是一个字符串,对应着事件的名称,而 value是 LoginEvent 的一个列表,匹配到的登录失败事件就保存在这个列表里。最终我们提取 userId和三次登录的时间戳,包装成字符串输出一个报警信息。
运行代码可以得到结果如下:
warning> user_1 连续三次登录失败!登录时间:2000, 3000, 5000
可以看到,user_1 连续三次登录失败被检测到了;而 user_2 尽管也有三次登录失败,但中间有一次登录成功,所以不会被匹配到。
12.3、模式 API(Pattern API)
12.3.1、个体模式
模式(Pattern)其实就是将一组简单事件组合成复杂事件的“匹配规则”。由于流中事件的匹配是有先后顺序的,因此一个匹配规则就可以表达成先后发生的一个个简单事件,按顺序串联组合在一起。
这里的每一个简单事件并不是任意选取的,也需要有一定的条件规则;所以我们就把每个简单事件的匹配规则,叫作“个体模式”(Individual Pattern)。
12.3.1.1、基本形式
每一个登录失败事件的选取规则,就都是一个个体模式。比如:
.<LoginEvent>begin("first") // 以第一个登录失败事件开始
.where(new SimpleCondition<LoginEvent>() {
@Override
public boolean filter(LoginEvent loginEvent) throws Exception {
return loginEvent.eventType.equals("fail");
}
})
或者后面的:
.next("second") // 接着是第二个登录失败事件
.where(new SimpleCondition<LoginEvent>() {
@Override
public boolean filter(LoginEvent loginEvent) throws Exception {
return loginEvent.eventType.equals("fail");
}
})
这些都是个体模式。个体模式一般都会匹配接收一个事件。
每个个体模式都以一个“连接词”开始定义的,比如 begin、next 等等,这是 Pattern 对象的一个方法(begin 是 Pattern 类的静态方法),返回的还是一个 Pattern。这些“连接词”方法有一个 String 类型参数,这就是当前个体模式唯一的名字,比如这里的“first”、“second”。在之后检测到匹配事件时,就会以这个名字来指代匹配事件。个体模式需要一个“过滤条件”,用来指定具体的匹配规则。这个条件一般是通过调用.where()方法来实现的,具体的过滤逻辑则通过传入的 SimpleCondition 内的.filter()方法来定义。
另外,个体模式可以匹配接收一个事件,也可以接收多个事件。这听起来有点奇怪,一个单独的匹配规则可能匹配到多个事件吗?这是可能的,我们可以给个体模式增加一个“量词”(quantifier),就能够让它进行循环匹配,接收多个事件。接下来我们就对量词和条件(condition)进行展开说明。
12.3.1.2、量词(Quantifiers )
个体模式后面可以跟一个“量词”,用来指定循环的次数。从这个角度分类,个体模式可以包括“单例(singleton)模式”和“循环(looping)模式”。默认情况下,个体模式是单例模式,匹配接收一个事件;当定义了量词之后,就变成了循环模式,可以匹配接收多个事件。
在循环模式中,对同样特征的事件可以匹配多次。比如我们定义个体模式为“匹配形状为三角形的事件”,再让它循环多次,就变成了“匹配连续多个三角形的事件”。注意这里的“连续”,只要保证前后顺序即可,中间可以有其他事件,所以是“宽松近邻”关系。在 Flink CEP 中,可以使用不同的方法指定循环模式,主要有:
- oneOrMore()
匹配事件出现一次或多次,假设 a 是一个个体模式,a.oneOrMore()表示可以匹配 1 个或多个 a 的事件组合。我们有时会用 a+来简单表示。 - .times(times)
匹配事件发生特定次数(times),例如 a.times(3)表示 aaa; - .times(fromTimes,toTimes)
指定匹配事件出现的次数范围,最小次数为fromTimes,最大次数为toTimes。例如a.times(2, 4)可以匹配 aa,aaa 和 aaaa。 - .greedy()
只能用在循环模式后,使当前循环模式变得“贪心”(greedy),也就是总是尽可能多地去匹配。例如 a.times(2, 4).greedy(),如果出现了连续 4 个 a,那么会直接把 aaaa 检测出来进行处理,其他任意 2 个 a 是不算匹配事件的。 - .optional()
使当前模式成为可选的,也就是说可以满足这个匹配条件,也可以不满足。对于一个个体模式 pattern 来说,后面所有可以添加的量词如下:
// 匹配事件出现 4 次
pattern.times(4);
// 匹配事件出现 4 次,或者不出现
pattern.times(4).optional();
// 匹配事件出现 2, 3 或者 4 次
pattern.times(2, 4);
// 匹配事件出现 2, 3 或者 4 次,并且尽可能多地匹配
pattern.times(2, 4).greedy();
// 匹配事件出现 2, 3, 4 次,或者不出现
pattern.times(2, 4).optional();
// 匹配事件出现 2, 3, 4 次,或者不出现;并且尽可能多地匹配
pattern.times(2, 4).optional().greedy();
// 匹配事件出现 1 次或多次
pattern.oneOrMore();
// 匹配事件出现 1 次或多次,并且尽可能多地匹配
pattern.oneOrMore().greedy();
// 匹配事件出现 1 次或多次,或者不出现
pattern.oneOrMore().optional();
// 匹配事件出现 1 次或多次,或者不出现;并且尽可能多地匹配
pattern.oneOrMore().optional().greedy();
// 匹配事件出现 2 次或多次
pattern.timesOrMore(2);
// 匹配事件出现 2 次或多次,并且尽可能多地匹配
pattern.timesOrMore(2).greedy();
// 匹配事件出现 2 次或多次,或者不出现
pattern.timesOrMore(2).optional()
// 匹配事件出现 2 次或多次,或者不出现;并且尽可能多地匹配
pattern.timesOrMore(2).optional().greedy();
正是因为个体模式可以通过量词定义为循环模式,一个模式能够匹配到多个事件,所以之前代码中事件的检测接收才会用 Map 中的一个列表(List)来保存。而之前代码中没有定义量词,都是单例模式,所以只会匹配一个事件,每个 List 中也只有一个元素:
LoginEvent first = map.get("first").get(0);
12.3.1.3、条件(Conditions)
对于每个个体模式,匹配事件的核心在于定义匹配条件,也就是选取事件的规则。FlinkCEP 会按照这个规则对流中的事件进行筛选,判断是否接受当前的事件。对于条件的定义,主要是通过调用 Pattern 对象的.where()方法来实现的,主要可以分为简单条件、迭代条件、复合条件、终止条件几种类型。此外,也可以调用 Pattern 对象的.subtype()方法来限定匹配事件的子类型。接下来我们就分别进行介绍。
- 限定子类型
调用.subtype()方法可以为当前模式增加子类型限制条件。例如:pattern.subtype(SubEvent.class);
这里 SubEvent 是流中数据类型 Event 的子类型。这时,只有当事件是 SubEvent 类型时,才可以满足当前模式 pattern 的匹配条件。 - 简单条件(Simple Conditions)
简单条件是最简单的匹配规则,只根据当前事件的特征来决定是否接受它。这在本质上其实就是一个 filter 操作。
代码中我们为.where()方法传入一个 SimpleCondition 的实例作为参数。SimpleCondition 是表示“简单条件”的抽象类,内部有一个.filter()方法,唯一的参数就是当前事件。所以它可以当作 FilterFunction 来使用。下面是一个具体示例:
pattern.where(new SimpleCondition<Event>() {
@Override
public boolean filter(Event value) {
return value.user.startsWith("A");
}
});
这里我们要求匹配事件的 user 属性以“A”开头。
- 迭代条件(Iterative Conditions)
简单条件只能基于当前事件做判断,能够处理的逻辑比较有限。在实际应用中,我们可能需要将当前事件跟之前的事件做对比,才能判断出要不要接受当前事件。这种需要依靠之前事件来做判断的条件,就叫作“迭代条件”(Iterative Condition)。
在 Flink CEP 中,提供了 IterativeCondition 抽象类。这其实是更加通用的条件表达,查看源码可以发现, .where()方法本身要求的参数类型就是 IterativeCondition;而之前 的SimpleCondition 是它的一个子类。
在 IterativeCondition 中同样需要实现一个 filter()方法,不过与 SimpleCondition 中不同的是,这个方法有两个参数:除了当前事件之外,还有一个上下文 Context。调用这个上下文的.getEventsForPattern()方法,传入一个模式名称,就可以拿到这个模式中已匹配到的所有数据了。下面是一个具体示例:
middle.oneOrMore()
.where(new IterativeCondition<Event>() {
@Override
public boolean filter(Event value, Context<Event> ctx) throws Exception {
// 事件中的 user 必须以 A 开头
if (!value.user.startsWith("A")) {
return false;
}
int sum = value.amount;
// 获取当前模式之前已经匹配的事件,求所有事件 amount 之和
for (Event event : ctx.getEventsForPattern("middle")) {
sum += event.amount;
}
// 在总数量小于 100 时,当前事件满足匹配规则,可以匹配成功
return sum < 100;
}
});
上面代码中当前模式名称就叫作“middle”,这是一个循环模式,可以接受事件发生一次或多次。于是下面的迭代条件中,我们通过 ctx.getEventsForPattern(“middle”)获取当前模式已经接受的事件,计算它们的数量(amount)之和;再加上当前事件中的数量,如果总和小于100,就接受当前事件,否则就不匹配。当然,在迭代条件中我们也可以基于当前事件做出判断,比如代码中要求 user 必须以 A 开头。最终我们的匹配规则就是:事件的 user 必须以 A 开头;并且循环匹配的所有事件 amount 之和必须小于 100。这里的 Event 与之前定义的 POJO 不同,增加了 amount 属性。
可以看到,迭代条件能够获取已经匹配的事件,如果自身又是循环模式(比如量词oneOrMore),那么两者结合就可以捕获自身之前接收的数据,据此来判断是否接受当前事件。这个功能非常强大,我们可以由此实现更加复杂的需求,比如可以要求“只有大于之前数据的平均值,才接受当前事件”。另外迭代条件中的上下文 Context 也可以获取到时间相关的信息,比如事件的时间戳和当前的处理时间(processing time)。
- 组合条件(Combining Conditions)
最简单的组合条件,就是.where()后面再接一个.where()。因为前面提到过,一个条件就像是一个 filter 操作,所以每次调用.where()方法都相当于做了一次过滤,连续多次调用就表示多重过滤,最终匹配的事件自然就会同时满足所有条件。这相当于就是多个条件的“逻辑与”(AND)。
而多个条件的逻辑或(OR),则可以通过.where()后加一个.or()来实现。这里的.or()方法与.where()一样,传入一个 IterativeCondition 作为参数,定义一个独立的条件;它和之前.where()定义的条件只要满足一个,当前事件就可以成功匹配。当然,子类型限定条件(subtype)也可以和其他条件结合起来,成为组合条件,如下所示:
pattern.subtype(SubEvent.class)
.where(new SimpleCondition<SubEvent>() {
@Override
public boolean filter(SubEvent value) {
return ... // some condition
}
});
这里可以看到,SimpleCondition 的泛型参数也变成了 SubEvent,所以匹配出的事件就既满足子类型限制,又符合过滤筛选的简单条件;这也是一个逻辑与的关系。
- 终止条件(Stop Conditions)
对于循环模式而言,还可以指定一个“终止条件”(Stop Condition),表示遇到某个特定事件时当前模式就不再继续循环匹配了。终 止 条 件 的 定 义 是 通 过 调 用 模 式 对 象 的 .until() 方 法 来 实 现 的 , 同 样 传 入 一 个IterativeCondition 作为参数。需要注意的是,终止条件只与 oneOrMore() 或 者
oneOrMore().optional()结合使用。因为在这种循环模式下,我们不知道后面还有没有事件可以匹配,只好把之前匹配的事件作为状态缓存起来继续等待,这等待无穷无尽;如果一直等下去,缓存的状态越来越多,最终会耗尽内存。所以这种循环模式必须有个终点,当.until()指定的条件满足时,循环终止,这样就可以清空状态释放内存了。
12.3.2、组合模式
有了定义好的个体模式,就可以尝试按一定的顺序把它们连接起来,定义一个完整的复杂事件匹配规则了。这种将多个个体模式组合起来的完整模式,就叫作“组合模式”(Combining Pattern),为了跟个体模式区分有时也叫作“模式序列”(Pattern Sequence)。一个组合模式有以下形式:
Pattern<Event, ?> pattern = Pattern
.<Event>begin("start").where(...)
.next("next").where(...)
.followedBy("follow").where(...)
...
可以看到,组合模式确实就是一个“模式序列”,是用诸如 begin、next、followedBy 等表示先后顺序的“连接词”将个体模式串连起来得到的。在这样的语法调用中,每个事件匹配的条件是什么、各个事件之间谁先谁后、近邻关系如何都定义得一目了然。每一个“连接词”方法调用之后,得到的都仍然是一个 Pattern 的对象;所以从 Java 对象的角度看,组合模式与个体模式是一样的,都是 Pattern。
12.3.2.1、初始模式(Initial Pattern)
所有的组合模式,都必须以一个“初始模式”开头;而初始模式必须通过调用 Pattern 的静态方法.begin()来创建。如下所示:
Pattern<Event, ?> start = Pattern.<Event>begin("start");
这里我们调用 Pattern 的.begin()方法创建了一个初始模式。传入的 String 类型的参数就是模式的名称;而 begin 方法需要传入一个类型参数,这就是模式要检测流中事件的基本类型,这里我们定义为 Event。调用的结果返回一个 Pattern 的对象实例。Pattern 有两个泛型参数,第一个就是检测事件的基本类型 Event,跟 begin 指定的类型一致;第二个则是当前模式里事件的子类型,由子类型限制条件指定。我们这里用类型通配符(?)代替,就可以从上下文直接推断了。
12.3.2.2、近邻条件(Contiguity Conditions)
在初始模式之后,我们就可以按照复杂事件的顺序追加模式,组合成模式序列了。模式之间的组合是通过一些“连接词”方法实现的,这些连接词指明了先后事件之间有着怎样的近邻关系,这就是所谓的“近邻条件”(Contiguity Conditions,也叫“连续性条件”)。Flink CEP 中提供了三种近邻关系:
-
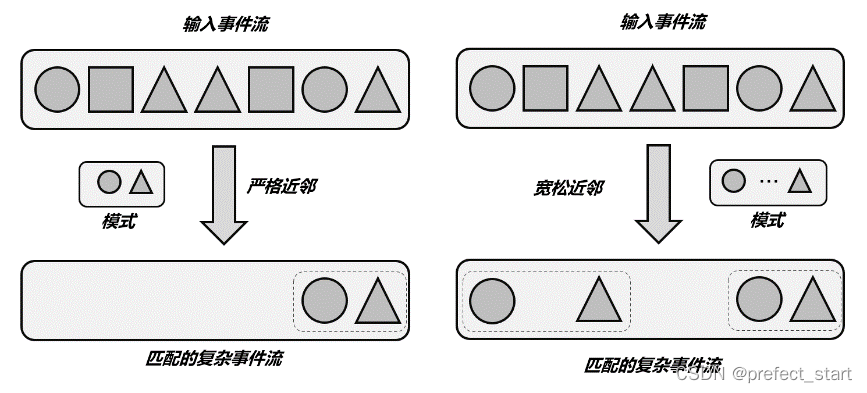
严格近邻(Strict Contiguity)
如下图所示,匹配的事件严格地按顺序一个接一个出现,中间不会有任何其他事件。代码中对应的就是 Pattern 的.next()方法,名称上就能看出来,“下一个”自然就是紧挨着的。 -
宽松近邻(Relaxed Contiguity)
如下图所示,宽松近邻只关心事件发生的顺序,而放宽了对匹配事件的“距离”要求,也就是说两个匹配的事件之间可以有其他不匹配的事件出现。代码中对应.followedBy()方法,很明显这表示“跟在后面”就可以,不需要紧紧相邻。
- 非确定性宽松近邻(Non-Deterministic Relaxed Contiguity)
这种近邻关系更加宽松。所谓“非确定性”是指可以重复使用之前已经匹配过的事件;这种近邻条件下匹配到的不同复杂事件,可以以同一个事件作为开始,所以匹配结果一般会比宽松近邻更多,如下图所示。代码中对应.followedByAny()方法。
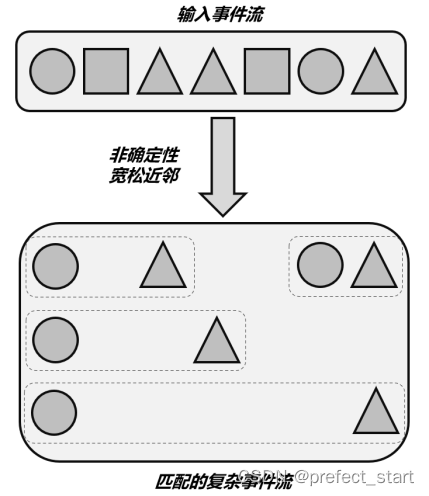
从图中可以看到,我们定义的模式序列中有两个个体模式:一是“选择圆形事件”,一是“选择三角形事件”;这时它们之间的近邻条件就会导致匹配出的复杂事件有所不同。很明显,严格近邻由于条件苛刻,匹配的事件最少;宽松近邻可以匹配不紧邻的事件,匹配结果会多一些;而非确定性宽松近邻条件最为宽松,可以匹配到最多的复杂事件。
12.3.2.3、其他限制条件
除了上面提到的 next()、followedBy()、followedByAny()可以分别表示三种近邻条件,我们还可以用否定的“连接词”来组合个体模式。主要包括:
- .notNext()
表示前一个模式匹配到的事件后面,不能紧跟着某种事件。 - .notFollowedBy()
表示前一个模式匹配到的事件后面,不会出现某种事件。这里需要注意,由于notFollowedBy()是没有严格限定的;流数据不停地到来,我们永远不能保证之后“不会出现某种事件”。所以一个模式序列不能以 notFollowedBy()结尾,这个限定条件主要用来表示“两个事件中间不会出现某种事件”。
另外,Flink CEP 中还可以为模式指定一个时间限制,这是通过调用.within()方法实现的。方法传入一个时间参数,这是模式序列中第一个事件到最后一个事件之间的最大时间间隔,只有在这期间成功匹配的复杂事件才是有效的。一个模式序列中只能有一个时间限制,调用.within()的位置不限;如果多次调用则会以最小的那个时间间隔为准。
下面是模式序列中所有限制条件在代码中的定义:
// 严格近邻条件
Pattern<Event, ?> strict = start.next("middle").where(...);
// 宽松近邻条件
Pattern<Event, ?> relaxed = start.followedBy("middle").where(...);
// 非确定性宽松近邻条件
Pattern<Event, ?> nonDetermin =
start.followedByAny("middle").where(...);
// 不能严格近邻条件
Pattern<Event, ?> strictNot = start.notNext("not").where(...);
// 不能宽松近邻条件
Pattern<Event, ?> relaxedNot = start.notFollowedBy("not").where(...);
// 时间限制条件
middle.within(Time.seconds(10));
12.3.2.4、循环模式中的近邻条件
在循环模式中,近邻关系同样有三种:严格近邻、宽松近邻以及非确定性宽松近邻。对于定义了量词(如 oneOrMore()、times())的循环模式,默认内部采用的是宽松近邻。也就是说,当循环匹配多个事件时,它们中间是可以有其他不匹配事件的;相当于用单例模式分别定义、再用 followedBy()连接起来。这就解释了为什么我们检测连续三次登录失败用了三个单例模式来分别定义,而没有直接指定 times(3):因为我们需要三次登录失败必须是严格连续的,中间不能有登录成功的事件,而 times()默认是宽松近邻关系。不过把多个同样的单例模式组合在一起,这种方式还是显得有些笨拙了。不过它默认匹配事件之间是宽松近邻关系,我们可以通过调用额外的方法来改变这一点。
- .consecutive()
为循环模式中的匹配事件增加严格的近邻条件,保证所有匹配事件是严格连续的。也就是说,一旦中间出现了不匹配的事件,当前循环检测就会终止。这起到的效果跟模式序列中的next()一样,需要与循环量词 times()、oneOrMore()配合使用。于是,检测连续三次登录失败的代码可以改成:
// 1. 定义 Pattern,登录失败事件,循环检测 3 次
Pattern<LoginEvent, LoginEvent> pattern = Pattern
.<LoginEvent>begin("fails")
.where(new SimpleCondition<LoginEvent>() {
@Override
public boolean filter(LoginEvent loginEvent) throws Exception {
return loginEvent.eventType.equals("fail");
}
}).times(3).consecutive();
这样显得更加简洁;而且即使要扩展到连续 100 次登录失败,也只需要改动一个参数而已。
- .allowCombinations()
除严格近邻外,也可以为循环模式中的事件指定非确定性宽松近邻条件,表示可以重复使用 已 经 匹 配 的 事 件 。 这 需 要 调 用 .allowCombinations() 方 法 来 实 现 , 实 现 的 效 果与.followedByAny()相同。
12.3.3、模式组
一般来说,代码中定义的模式序列,就是我们在业务逻辑中匹配复杂事件的规则。不过在有些非常复杂的场景中,可能需要划分多个“阶段”,每个“阶段”又有一连串的匹配规则。为了应对这样的需求,Flink CEP 允许我们以“嵌套”的方式来定义模式。
之前在模式序列中,我们用 begin()、next()、followedBy()、followedByAny()这样的“连接词”来组合个体模式,这些方法的参数就是一个个体模式的名称;而现在它们可以直接以一个模式序列作为参数,就将模式序列又一次连接组合起来了。这样得到的就是一个“模式组”(Groups of Patterns)。
在模式组中,每一个模式序列就被当作了某一阶段的匹配条件,返回的类型是一个GroupPattern。而 GroupPattern 本身是 Pattern 的子类;所以个体模式和组合模式能调用的方法,比如 times()、oneOrMore()、optional()之类的量词,模式组一般也是可以用的。具体在代码中的应用如下所示:
// 以模式序列作为初始模式
Pattern<Event, ?> start = Pattern.begin(
Pattern.<Event>begin("start_start").where(...)
.followedBy("start_middle").where(...)
);
// 在 start 后定义严格近邻的模式序列,并重复匹配两次
Pattern<Event, ?> strict = start.next(
Pattern.<Event>begin("next_start").where(...)
.followedBy("next_middle").where(...)
).times(2);
// 在 start 后定义宽松近邻的模式序列,并重复匹配一次或多次
Pattern<Event, ?> relaxed = start.followedBy(
Pattern.<Event>begin("followedby_start").where(...)
.followedBy("followedby_middle").where(...)
).oneOrMore();
//在 start 后定义非确定性宽松近邻的模式序列,可以匹配一次,也可以不匹配
Pattern<Event, ?> nonDeterminRelaxed = start.followedByAny(
Pattern.<Event>begin("followedbyany_start").where(...)
.followedBy("followedbyany_middle").where(...)
).optional();
12.3.4、匹配后跳过策略
在 Flink CEP 中,由于有循环模式和非确定性宽松近邻的存在,同一个事件有可能会重复利用,被分配到不同的匹配结果中。这样会导致匹配结果规模增大,有时会显得非常冗余。当然,非确定性宽松近邻条件,本来就是为了放宽限制、扩充匹配结果而设计的;我们主要是针对循环模式来考虑匹配结果的精简。
在 Flink CEP 中,提供了模式的“匹配后跳过策略”(After Match Skip Strategy),专门用来精准控制循环模式的匹配结果。这个策略可以在 Pattern 的初始模式定义中,作为 begin()的第二个参数传入:
Pattern.begin("start", AfterMatchSkipStrategy.noSkip())
.where(...)
...
匹配后跳过策略 AfterMatchSkipStrategy 是一个抽象类,它有多个具体的实现,可以通过调用对应的静态方法来返回对应的策略实例。这里我们配置的是不做跳过处理,这也是默认策略。
下面我们举例来说明不同的跳过策略。例如我们要检测的复杂事件模式为:开始是用户名为 a 的事件(简写为事件 a,下同),可以重复一次或多次;然后跟着一个用户名为 b 的事件,a 事件和 b 事件之间可以有其他事件(宽松近邻)。用简写形式可以直接写作:“a+ followedBy b”。在代码中定义 Pattern 如下:
Pattern.<Event>begin("a").where(new SimpleCondition<Event>() {
@Override
public boolean filter(Event value) throws Exception {
return value.user.equals("a");
}
}).oneOrMore()
.followedBy("b").where(new SimpleCondition<Event>() {
@Override
public boolean filter(Event value) throws Exception {
return value.user.equals("b");
}
});
我们如果输入事件序列“a a a b”——这里为了区分前后不同的 a 事件,可以记作“a1 a2 a3 b”——那么应该检测到 6 个匹配结果:(a1 a2 a3 b),(a1 a2 b),(a1 b),(a2 a3 b),(a2 b),
(a3 b)。如果在初始模式的量词.oneOrMore()后加上.greedy()定义为贪心匹配,那么结果就是:(a1 a2 a3 b),(a2 a3 b),(a3 b),每个事件作为开头只会出现一次。
接下来我们讨论不同跳过策略对匹配结果的影响:
- 不跳过(NO_SKIP)
代码调用 AfterMatchSkipStrategy.noSkip()。这是默认策略,所有可能的匹配都会输出。所以这里会输出完整的 6 个匹配。 - 跳至下一个(SKIP_TO_NEXT)
代码调用 AfterMatchSkipStrategy.skipToNext()。找到一个 a1 开始的最大匹配之后,跳过a1 开始的所有其他匹配,直接从下一个 a2 开始匹配起。当然 a2 也是如此跳过其他匹配。最终得到(a1 a2 a3 b),(a2 a3 b),(a3 b)。可以看到,这种跳过策略跟使用.greedy()效果是相同的。 - 跳过所有子匹配(SKIP_PAST_LAST_EVENT)
代码调用 AfterMatchSkipStrategy.skipPastLastEvent()。找到 a1 开始的匹配(a1 a2 a3 b)之后,直接跳过所有 a1 直到 a3 开头的匹配,相当于把这些子匹配都跳过了。最终得到(a1 a2 a3 b),这是最为精简的跳过策略。 - 跳至第一个(SKIP_TO_FIRST[a])代码调用 AfterMatchSkipStrategy.skipToFirst(“a”),这里传入一个参数,指明跳至哪个模式的第一个匹配事件。找到 a1 开始的匹配(a1 a2 a3 b)后,跳到以最开始一个 a(也就是 a1)为开始的匹配,相当于只留下 a1 开始的匹配。最终得到(a1 a2 a3 b),(a1 a2 b),(a1 b)。
- 跳至最后一个(SKIP_TO_LAST[a])
代码调用 AfterMatchSkipStrategy.skipToLast(“a”),同样传入一个参数,指明跳至哪个模式的最后一个匹配事件。找到 a1 开始的匹配(a1 a2 a3 b)后,跳过所有 a1、a2 开始的匹配,跳到以最后一个 a(也就是 a3)为开始的匹配。最终得到(a1 a2 a3 b),(a3 b)。
12.4、模式的检测处理
Pattern API 是 Flink CEP 的核心,也是最复杂的一部分。不过利用 Pattern API 定义好模式还只是整个复杂事件处理的第一步,接下来还需要将模式应用到事件流上、检测提取匹配的复杂事件并定义处理转换的方法,最终得到想要的输出信息。
12.4.1、将模式应用到流上
将模式应用到事件流上的代码非常简单,只要调用 CEP 类的静态方法.pattern(),将数据流(DataStream)和模式(Pattern)作为两个参数传入就可以了。最终得到的是一个 PatternStream:
DataStream<Event> inputStream = ...
Pattern<Event, ?> pattern = ...
PatternStream<Event> patternStream = CEP.pattern(inputStream, pattern);
这里的 DataStream,也可以通过 keyBy 进行按键分区得到 KeyedStream,接下来对复杂事件的检测就会针对不同的 key 单独进行了。
模式中定义的复杂事件,发生是有先后顺序的,这里“先后”的判断标准取决于具体的时间语义。默认情况下采用事件时间语义,那么事件会以各自的时间戳进行排序;如果是处理时间语义,那么所谓先后就是数据到达的顺序。对于时间戳相同或是同时到达的事件,我们还可以在 CEP.pattern()中传入一个比较器作为第三个参数,用来进行更精确的排序:
// 可选的事件比较器
EventComparator<Event> comparator = ...
PatternStream<Event> patternStream = CEP.pattern(input, pattern, comparator);
得到 PatternStream 后,接下来要做的就是对匹配事件的检测处理了。
12.4.2、处理匹配事件
基于 PatternStream 可以调用一些转换方法,对匹配的复杂事件进行检测和处理,并最终得到一个正常的 DataStream。这个转换的过程与窗口的处理类似:将模式应用到流上得到PatternStream,就像在流上添加窗口分配器得到 WindowedStream;而之后的转换操作,就像定义具体处理操作的窗口函数,对收集到的数据进行分析计算,得到结果进行输出,最后回到DataStream 的类型来。
PatternStream 的转换操作主要可以分成两种:简单便捷的选择提取(select)操作,和更加通用、更加强大的处理(process)操作。与 DataStream 的转换类似,具体实现也是在调用API 时传入一个函数类:选择操作传入的是一个 PatternSelectFunction,处理操作传入的则是一
个 PatternProcessFunction。
12.4.2.1、 匹配事件的选择提取(select)
处理匹配事件最简单的方式,就是从 PatternStream 中直接把匹配的复杂事件提取出来,
包装成想要的信息输出,这个操作就是“选择”(select)。
- PatternSelectFunction
代码中基于 PatternStream 直接调用.select()方法,传入一个 PatternSelectFunction 作为参数。
PatternStream<Event> patternStream = CEP.pattern(inputStream, pattern);
DataStream<String> result = patternStream.select(new MyPatternSelectFunction());
这 里 的 MyPatternSelectFunction 是 PatternSelectFunction 的 一 个 具 体 实 现 。PatternSelectFunction 是 Flink CEP 提供的一个函数类接口,它会将检测到的匹配事件保存在一个 Map 里,对应的 key 就是这些事件的名称。这里的“事件名称”就对应着在模式中定义的每个个体模式的名称;而个体模式可以是循环模式,一个名称会对应多个事件,所以最终保存在 Map 里的 value 就是一个事件的列表(List)。下面是 MyPatternSelectFunction 的一个具体实现:
class MyPatternSelectFunction implements PatternSelectFunction<Event, String>{
@Override
public String select(Map<String, List<Event>> pattern) throws Exception {
Event startEvent = pattern.get("start").get(0);
Event middleEvent = pattern.get("middle").get(0);
return startEvent.toString() + " " + middleEvent.toString();
}
}
PatternSelectFunction 里需要实现一个 select()方法,这个方法每当检测到一组匹配的复杂事件时都会调用一次。它以保存了匹配复杂事件的 Map 作为输入,经自定义转换后得到输出信息返回。这里我们假设之前定义的模式序列中,有名为“start”和“middle”的两个个体模式,于是可以通过这个名称从 Map 中选择提取出对应的事件。注意调用 Map 的.get(key)方法后得到的是一个事件的 List;如果个体模式是单例的,那么 List 中只有一个元素,直接调用.get(0)就可以把它取出。
当然,如果个体模式是循环的,List 中就有可能有多个元素了。例如我们在对连续登录失败检测的改进,我们可以将匹配到的事件包装成 String 类型的报警信息输出,代码如下:
// 1. 定义 Pattern,登录失败事件,循环检测 3 次
Pattern<LoginEvent, LoginEvent> pattern = Pattern.<LoginEvent>begin("fails")
.where(new SimpleCondition<LoginEvent>() {
@Override
public boolean filter(LoginEvent loginEvent) throws Exception {
return loginEvent.eventType.equals("fail");
}
}).times(3).consecutive();
// 2. 将 Pattern 应用到流上,检测匹配的复杂事件,得到一个 PatternStream
PatternStream<LoginEvent> patternStream = CEP.pattern(stream, pattern);
// 3. 将匹配到的复杂事件选择出来,然后包装成报警信息输出
patternStream.select(new PatternSelectFunction<LoginEvent, String>() {
@Override
public String select(Map<String, List<LoginEvent>> map) throws Exception {
//只有一个模式,匹配到了 3 个事件,放在 List 中
LoginEvent first = map.get("fails").get(0);
LoginEvent second = map.get("fails").get(1);
LoginEvent third = map.get("fails").get(2);
return first.userId + " 连续三次登录失败!登录时间:" + first.timestamp + ", " + second.timestamp + ", " + third.timestamp;
}
})
.print("warning");
我们定义的模式序列中只有一个循环模式 fails,它会将检测到的 3 个登录失败事件保存到一个列表(List)中。所以第三步处理匹配的复杂事件时,我们从 map 中获取模式名 fails 对应的事件,拿到的是一个 List,从中按位置索引依次获取元素就可以得到匹配的三个登录失败事件。运行程序进行测试,会发现结果与之前完全一样。
- PatternFlatSelectFunction
除此之外,PatternStream 还有一个类似的方法是.flatSelect(),传入的参数是一个PatternFlatSelectFunction。从名字上就能看出,这是 PatternSelectFunction 的“扁平化”版本;内部需要实现一个 flatSelect()方法,它与之前 select()的不同就在于没有返回值,而是多了一个收集器(Collector)参数 out,通过调用 out.collet()方法就可以实现多次发送输出数据了。
例如上面的代码可以写成:
// 3. 将匹配到的复杂事件选择出来,然后包装成报警信息输出
patternStream.flatSelect(new PatternFlatSelectFunction<LoginEvent, String>() {
@Override
public void flatSelect(Map<String, List<LoginEvent>> map,
Collector<String> out) throws Exception {
LoginEvent first = map.get("fails").get(0);
LoginEvent second = map.get("fails").get(1);
LoginEvent third = map.get("fails").get(2);
out.collect(first.userId + " 连续三次登录失败!登录时间:" + first.timestamp +
", " + second.timestamp + ", " + third.timestamp);
}
}).print("warning");
可见 PatternFlatSelectFunction 使用更加灵活,完全能够覆盖 PatternSelectFunction 的功能。这跟 FlatMapFunction 与 MapFunction 的区别是一样的。
- 匹配事件的通用处理(process)
自 1.8 版本之后,Flink CEP 引入了对于匹配事件的通用检测处理方式,那就是直接调用
PatternStream 的.process()方法,传入一个 PatternProcessFunction。这看起来就像是我们熟悉的
处理函数(process function),它也可以访问一个上下文(Context),进行更多的操作。
所以 PatternProcessFunction 功能更加丰富、调用更加灵活,可以完全覆盖其他接口,也就
成为了目前官方推荐的处理方式。事实上,PatternSelectFunction 和 PatternFlatSelectFunction
在 CEP 内部执行时也会被转换成 PatternProcessFunction。
我们可以使用 PatternProcessFunction 将之前的代码重写如下:
// 3. 将匹配到的复杂事件选择出来,然后包装成报警信息输出
patternStream.process(new PatternProcessFunction<LoginEvent, String>() {
@Override
public void processMatch(Map<String, List> map, Context ctx,
Collector out) throws Exception {
LoginEvent first = map.get(“fails”).get(0);
LoginEvent second = map.get(“fails”).get(1);
LoginEvent third = map.get(“fails”).get(2);
out.collect(first.userId + " 连续三次登录失败!登录时间:" + first.timestamp +
", " + second.timestamp + ", " + third.timestamp);
}
}).print(“warning”);
可以看到,PatternProcessFunction 中必须实现一个 processMatch()方法;这个方法与之前
的 flatSelect()类似,只是多了一个上下文 Context 参数。利用这个上下文可以获取当前的时间
信息,比如事件的时间戳(timestamp)或者处理时间(processing time);还可以调用.output()
方法将数据输出到侧输出流。侧输出流的功能是处理函数的一大特性,我们已经非常熟悉;而
在 CEP 中,侧输出流一般被用来处理超时事件,我们会在下一小节详细讨论。
393
394
12.4.3 处理超时事件
复杂事件的检测结果一般只有两种:要么匹配,要么不匹配。检测处理的过程具体如下:
(1)如果当前事件符合模式匹配的条件,就接受该事件,保存到对应的 Map 中;
(2)如果在模式序列定义中,当前事件后面还应该有其他事件,就继续读取事件流进行
检测;如果模式序列的定义已经全部满足,那么就成功检测到了一组匹配的复杂事件,调用
PatternProcessFunction 的 processMatch()方法进行处理;
(3)如果当前事件不符合模式匹配的条件,就丢弃该事件;
(4)如果当前事件破坏了模式序列中定义的限制条件,比如不满足严格近邻要求,那么
当前已检测的一组部分匹配事件都被丢弃,重新开始检测。
不过在有时间限制的情况下,需要考虑的问题会有一点特别。比如我们用.within()指定了
模式检测的时间间隔,超出这个时间当前这组检测就应该失败了。然而这种“超时失败”跟真
正的“匹配失败”不同,它其实是一种“部分成功匹配”;因为只有在开头能够正常匹配的前
提下,没有等到后续的匹配事件才会超时。所以往往不应该直接丢弃,而是要输出一个提示或
报警信息。这就要求我们有能力捕获并处理超时事件。 - 使用 PatternProcessFunction 的侧输出流
在 Flink CEP 中 , 提 供 了 一 个 专 门 捕 捉 超 时 的 部 分 匹 配 事 件 的 接 口 , 叫 作
TimedOutPartialMatchHandler。这个接口需要实现一个 processTimedOutMatch()方法,可以将
超时的、已检测到的部分匹配事件放在一个 Map 中,作为方法的第一个参数;方法的第二个
参数则是 PatternProcessFunction 的上下文 Context。所以这个接口必须与 PatternProcessFunction
结合使用,对处理结果的输出则需要利用侧输出流来进行。
代码中的调用方式如下:
class MyPatternProcessFunction extends PatternProcessFunction<Event, String>
implements TimedOutPartialMatchHandler {
// 正常匹配事件的处理
@Override
public void processMatch(Map<String, List> match, Context ctx,
Collector out) throws Exception{
…
}
// 超时部分匹配事件的处理
@Override
public void processTimedOutMatch(Map<String, List> match, Context ctx)
throws Exception{
Event startEvent = match.get(“start”).get(0);
OutputTag outputTag = new OutputTag(“time-out”){};
ctx.output(outputTag, startEvent);
}
}
我们在 processTimedOutMatch()方法中定义了一个输出标签(OutputTag)。调用 ctx.output()
方法,就可以将超时的部分匹配事件输出到标签所标识的侧输出流了。
12.4.2.2、. 使用 PatternTimeoutFunction
上文提到的PatternProcessFunction通过实现TimedOutPartialMatchHandler接口扩展出了处理超时事件的能力,这是官方推荐的做法。此外,Flink CEP 中也保留了简化版的PatternSelectFunction,它无法直接处理超时事件,不过我们可以通过调用 PatternStream的.select()方法时多传入一个 PatternTimeoutFunction 参数来实现这一点。
PatternTimeoutFunction 是早期版本中用于捕获超时事件的接口。它需要实现一个 timeout()方法,同样会将部分匹配的事件放在一个 Map 中作为参数传入,此外还有一个参数是当前的时间戳。提取部分匹配事件进行处理转换后,可以将通知或报警信息输出。
由于调用.select()方法后会得到唯一的 DataStream,所以正常匹配事件和超时事件的处理结果不应该放在同一条流中。正常匹配事件的处理结果会进入转换后得到的 DataStream,而超时事件的处理结果则会进入侧输出流;这个侧输出流需要另外传入一个侧输出标签(OutputTag)来指定。
所以最终我们在调用 PatternStream 的.select()方法时需要传入三个参数:侧输出流标签( OutputTag ), 超 时 事 件 处 理 函 数 PatternTimeoutFunction , 匹 配 事 件 提 取 函 数PatternSelectFunction。下面是一个代码中的调用方式:
// 定义一个侧输出流标签,用于标识超时侧输出流
OutputTag<String> timeoutTag = new OutputTag<String>("timeout"){
};
// 将匹配到的,和超时部分匹配的复杂事件提取出来,然后包装成提示信息输出
SingleOutputStreamOperator<String> resultStream = patternStream
.select(timeoutTag,
// 超时部分匹配事件的处理
new PatternTimeoutFunction<Event, String>() {
@Override
public String timeout(Map<String, List<Event>> pattern, long
timeoutTimestamp) throws Exception {
Event event = pattern.get("start").get(0);
return "超时:" + event.toString();
}
},
// 正常匹配事件的处理
new PatternSelectFunction<Event, String>() {
@Override
public String select(Map<String, List<Event>> pattern) throws Exception
{
...
}
}
);
// 将正常匹配和超时部分匹配的处理结果流打印输出
resultStream.print("matched");
resultStream.getSideOutput(timeoutTag).print("timeout");
这里需要注意的是,在超时事件处理的过程中,从 Map 里只能取到已经检测到匹配的那些事件;如果取可能未匹配的事件并调用它的对象方法,则可能会报空指针异常(NullPointerException)。另外,超时事件处理的结果进入侧输出流,正常匹配事件的处理结果进入主流,两者的数据类型可以不同。
12.4.2.3、应用实例
例如:在电商平台中,最终创造收入和利润的是用户下单购买的环节。用户下单的行为可以表明用户对商品的需求,但在现实中,并不是每次下单都会被用户立刻支付。当拖延一段时间后,用户支付的意愿会降低。所以为了让用户更有紧迫感从而提高支付转化率,同时也为了防范订单支付环节的安全风险,电商网站往往会对订单状态进行监控,设置一个失效时间(比如 15分钟),如果下单后一段时间仍未支付,订单就会被取消。
首先定义出要处理的数据类型。我们面对的是订单事件,主要包括用户对订单的创建(下单)和支付两种行为。因此可以定义 POJO 类 OrderEvent 如下,其中属性字段包括用户 ID、订单 ID、事件类型(操作类型)以及时间戳。
public class OrderEvent {
public String userId;
public String orderId;
public String eventType;
public Long timestamp;
public OrderEvent() {
}
public OrderEvent(String userId, String orderId, String eventType, Long timestamp) {
this.userId = userId;
this.orderId = orderId;
this.eventType = eventType;
this.timestamp = timestamp;
}
@Override
public String toString() {
return "OrderEvent{" +
"userId='" + userId + '\'' +
"orderId='" + orderId + '\'' +
", eventType='" + eventType + '\'' +
", timestamp=" + timestamp +
'}';
}
}
当前需求的重点在于对超时未支付的用户进行监控提醒,也就是需要检测有下单行为、但15 分钟内没有支付行为的复杂事件。在下单和支付之间,可以有其他操作(比如对订单的修改),所以两者之间是宽松近邻关系。可以定义 Pattern 如下:
Pattern<OrderEvent, ?> pattern = Pattern
.<OrderEvent>begin("create") // 首先是下单事件
.where(new SimpleCondition<OrderEvent>() {
@Override
public boolean filter(OrderEvent value) throws Exception {
return value.eventType.equals("create");
}
})
.followedBy("pay") // 之后是支付事件;中间可以修改订单,宽松近邻
.where(new SimpleCondition<OrderEvent>() {
@Override
public boolean filter(OrderEvent value) throws Exception {
return value.eventType.equals("pay");
}
})
.within(Time.minutes(15)); // 限制在 15 分钟之内
很明显,我们重点要处理的是超时的部分匹配事件。对原始的订单事件流按照订单 ID 进行分组,然后检测每个订单的“下单-支付”复杂事件,如果出现超时事件需要输出报警提示信息。整体代码实现如下:
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
// 获取订单事件流,并提取时间戳、生成水位线
KeyedStream<OrderEvent, String> stream = env
.fromElements(
new OrderEvent("user_1", "order_1", "create", 1000L),
new OrderEvent("user_2", "order_2", "create", 2000L),
new OrderEvent("user_1", "order_1", "modify", 10 * 1000L),
new OrderEvent("user_1", "order_1", "pay", 60 * 1000L),
new OrderEvent("user_2", "order_3", "create", 10 * 60 * 1000L),
new OrderEvent("user_2", "order_3", "pay", 20 * 60 * 1000L)
)
.assignTimestampsAndWatermarks(
WatermarkStrategy.<OrderEvent>forMonotonousTimestamps()
.withTimestampAssigner(
new SerializableTimestampAssigner<OrderEvent>() {
@Override
public long extractTimestamp(OrderEvent event, long l) {
return event.timestamp;
}
}
)
)
.keyBy(order -> order.orderId); // 按照订单ID分组
// 1. 定义Pattern
Pattern<OrderEvent, ?> pattern = Pattern
.<OrderEvent>begin("create") // 首先是下单事件
.where(new SimpleCondition<OrderEvent>() {
@Override
public boolean filter(OrderEvent value) throws Exception {
return value.eventType.equals("create");
}
})
.followedBy("pay") // 之后是支付事件;中间可以修改订单,宽松近邻
.where(new SimpleCondition<OrderEvent>() {
@Override
public boolean filter(OrderEvent value) throws Exception {
return value.eventType.equals("pay");
}
})
.within(Time.minutes(15)); // 限制在15分钟之内
// 2. 将Pattern应用到流上,检测匹配的复杂事件,得到一个PatternStream
PatternStream<OrderEvent> patternStream = CEP.pattern(stream, pattern);
// 3. 将匹配到的,和超时部分匹配的复杂事件提取出来,然后包装成提示信息输出
SingleOutputStreamOperator<String> payedOrderStream = patternStream.process(new OrderPayPatternProcessFunction());
// 4. 定义一个测输出流标签,用于标识超时测输出流
OutputTag<String> timeoutTag = new OutputTag<String>("timeout") {
};
// 5. 将正常匹配和超时部分匹配的处理结果流打印输出
payedOrderStream.print("payed");
payedOrderStream.getSideOutput(timeoutTag).print("timeout");
env.execute();
}
// 实现自定义的PatternProcessFunction,需实现TimedOutPartialMatchHandler接口
public static class OrderPayPatternProcessFunction extends PatternProcessFunction<OrderEvent, String> implements TimedOutPartialMatchHandler<OrderEvent> {
// 处理正常匹配事件
@Override
public void processMatch(Map<String, List<OrderEvent>> match, Context ctx, Collector<String> out) throws Exception {
OrderEvent payEvent = match.get("pay").get(0);
out.collect("订单 " + payEvent.orderId + " 已支付!");
}
// 处理超时未支付事件
@Override
public void processTimedOutMatch(Map<String, List<OrderEvent>> match, Context ctx) throws Exception {
OrderEvent createEvent = match.get("create").get(0);
ctx.output(new OutputTag<String>("timeout"){
}, "订单 " + createEvent.orderId + " 超时未支付!用户为:" + createEvent.userId);
}
}
运行代码,控制台打印结果如下:
payed> 订单 order_1 已支付!
payed> 订单 order_3 已支付!
timeout> 订单 order_2 超时未支付!用户为:user_2
分析测试数据可以很直观地发现,订单 1 和订单 3 都在 15 分钟进行了支付,订单 1 中间的修改行为不会影响结果;而订单 2 未能支付,因此侧输出流输出了一条报警信息。且同一用户可以下多个订单,最后的判断只是基于同一订单做出的。这与我们预期的效果完全一致。用处理函数进行状态编程,结合定时器也可以实现同样的功能,但明显 CEP 的实现更加方便,也更容易迁移和扩展。
12.4.2.4、处理迟到数据
CEP 主要处理的是先后发生的一组复杂事件,所以事件的顺序非常关键。事件先后顺序的具体定义与时间语义有关。如果是处理时间语义,那比较简单,只要按照数据处理的系统时间算就可以了;而如果是事件时间语义,需要按照事件自身的时间戳来排序。这就有可能出现时间戳大的事件先到、时间戳小的事件后到的现象,也就是所谓的“乱序数据”或“迟到数据”。
在 Flink CEP 中沿用了通过设置水位线(watermark)延迟来处理乱序数据的做法。当一个事件到来时,并不会立即做检测匹配处理,而是先放入一个缓冲区(buffer)。缓冲区内的数据,会按照时间戳由小到大排序;当一个水位线到来时,就会将缓冲区中所有时间戳小于水位线的事件依次取出,进行检测匹配。这样就保证了匹配事件的顺序和事件时间的进展一致,处理的顺序就一定是正确的。这里水位线的延迟时间,也就是事件在缓冲区等待的最大时间。这样又会带来另一个问题:水位线延迟时间不可能保证将所有乱序数据完美包括进来,总会有一些事件延迟比较大,以至于等它到来的时候水位线早已超过了它的时间戳。这时之前的数据都已处理完毕,这样的“迟到数据”就只能被直接丢弃了——这与窗口对迟到数据的默认处理一致。
我们自然想到,如果不希望迟到数据丢掉,应该也可以借鉴窗口的做法。Flink CEP 同样提 供 了 将 迟 到 事 件 输 出 到 侧 输 出 流 的 方 式 : 我 们 可 以 基 于 PatternStream 直接调.sideOutputLateData()方法,传入一个 OutputTag,将迟到数据放入侧输出流另行处理。代码
中调用方式如下:
PatternStream<Event> patternStream = CEP.pattern(input, pattern);
// 定义一个侧输出流的标签
OutputTag<String> lateDataOutputTag = new OutputTag<String>("late-data"){
};
SingleOutputStreamOperator<ComplexEvent> result = patternStream
.sideOutputLateData(lateDataOutputTag) // 将迟到数据输出到侧输出流
.select(
// 处理正常匹配数据
new PatternSelectFunction<Event, ComplexEvent>() {
...}
);
// 从结果中提取侧输出流
DataStream<String> lateData = result.getSideOutput(lateDataOutputTag);
可以看到,整个处理流程与窗口非常相似。经处理匹配数据得到结果数据流之后,可以调用.getSideOutput()方法来提取侧输出流,捕获迟到数据进行额外处理。