如何使用自增ID
在传统关系型数据库中设计主键时,自增ID经常被使用。不仅能够保证主键的唯一,同时也能简化业务层实现。Phoenix怎么使用自增ID,是我们这篇文章的重点。
一.语法说明
1. 创建自增序列
CREATE SEQUENCE [IF NOT EXISTS] SCHEMA.SEQUENCE_NAME [START WITH number] [INCREMENT BY number] [MINVALUE number] [MAXVALUE number] [CYCLE] [CACHE number]
start用于指定第一个值。如果不指定默认为1.increment指定每次调用next value for后自增大小。 如果不指定默认为1。minvalue和maxvalue一般与cycle连用, 让自增数据形成一个环,从最小值到最大值,再从最大值到最小值。cache默认为100, 表示server端生成100个自增序列缓存在客户端,可以减少rpc次数。此值也可以通过phoenix.sequence.cacheSize来配置。
示例
CREATE SEQUENCE my_sequence;-- 创建一个自增序列,初始值为1,自增间隔为1,将有100个自增值缓存在客户端。CREATE SEQUENCE my_sequence START WITH -1000CREATE SEQUENCE my_sequence INCREMENT BY 10CREATE SEQUENCE my_cycling_sequence MINVALUE 1 MAXVALUE 100 CYCLE;CREATE SEQUENCE my_schema.my_sequence START 0 CACHE 10
2. 删除自增序列
DROP SEQUENCE [IF EXISTS] SCHEMA.SEQUENCE_NAME
示例
DROP SEQUENCE my_sequenceDROP SEQUENCE IF EXISTS my_schema.my_sequence
二.案例
1. 需求
对现有的书籍进行编号并存储,要求编号是惟一的。存储书籍信息的建表语句如下:
create table books( id integer not null primary key, name varchar, author varchar)SALT_BUCKETS = 8;
由于自增ID作为rowkey, 容易造成集群热点问题,所以在创建表时最好通过加盐的方式解决这个问题
2.通过自增ID,实现唯一编码,并简化实现。
创建自增序列,初始值为10000,自增间隔为1,缓存大小为1000.
CREATE SEQUENCE book_sequence START WITH 10000 INCREMENT BY 1 CACHE 1000;
通过自增序列,写入数据信息。
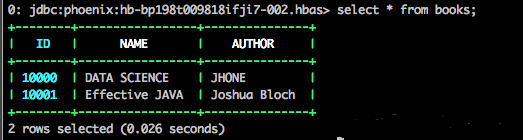
UPSERT INTO books(id, name, author) VALUES( NEXT VALUE FOR book_sequence,'DATA SCIENCE', 'JHONE'); UPSERT INTO books(id, name, author) VALUES( NEXT VALUE FOR book_sequence,'Effective JAVA','Joshua Bloch');
查看结果
三.References
https://phoenix.apache.org/sequences.html
动态列
一.概要
动态列是指在查询中新增字段,操作创建表时未指定的列。传统关系型数据要实现动态列目前常用的方法有:设计表结构时预留新增字段位置、设计更通用的字段、列映射为行和利用json/xml存储字段扩展字段信息等,这些方法多少都存在一些缺陷,动态列的实现只能依赖逻辑层的设计实现。由于Phoenix是HBase上的SQL层,借助HBase特性实现的动态列,避免了传统关系型数据库动态列实现存在的问题。
二.动态列使用
示例表(用于语法说明)
CREATE TABLE EventLog ( eventId BIGINT NOT NULL, eventTime TIME NOT NULL, eventType CHAR(3) CONSTRAINT pk PRIMARY KEY (eventId, eventTime)) COLUMN_ENCODED_BYTES=0
1. Upsert
在插入数据时指定新增列字段名和类型,并在values对应的位置设置相应的值。语法如下:
upsert into <tableName> (exists_col1, exists_col2, ... (new_col1 time, new_col2 integer, ...)) VALUES (v1, v2, ... (v1, v2, ...))
动态列写入示例:
UPSERT INTO EventLog (eventId, eventTime, eventType, lastGCTime TIME, usedMemory BIGINT, maxMemory BIGINT) VALUES(1, CURRENT_TIME(), 'abc', CURRENT_TIME(), 512, 1024);
我们来查询看结果
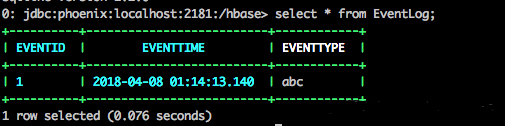
查询发现并没新增列的数据,也就是通过动态列插入值时并没有对表的schema直接改变。HBase表中发生了怎么样的变化呢?实际上HBase表中已经新增列以及数据。那通过动态列添加的数据怎么查询呢?

2. Select
动态列查询语法
select [*|table.*|[table.]colum_name_1[AS alias1][,[table.]colum_name_2[AS alias2] …], <dy_colum_name_1>] FROM tableName (<dy_colum_name_1, type> [,<dy_column_name_2, type> ...]) [where clause] [group by clause] [having clause] [order by clause]
动态列查询示例
SELECT eventId, eventTime, lastGCTime, usedMemory, maxMemory FROM EventLog(lastGCTime TIME, usedMemory BIGINT, maxMemory BIGINT) where eventId=1
查询结果如下

三.总结
Phoneix的动态列功能是非SQL标准语法,它给我们带来更多的灵活性,不再为静态schema的字段扩展问题而困扰。然而我们在实际应用中,应该根据自己的业务需求决定是否真的使用动态列,因为动态列的滥用会大幅度的增加我们的维护成本。
四.References
https://phoenix.apache.org/dynamic_columns.html
分页查询
一.概要
所谓分页查询就是从符合条件的起始记录,往后遍历“页大小”的行。数据库的分页是在server端完成的,避免客户端一次性查询到大量的数据,让查询数据数据分段展示在客户端。对于Phoenix的分页查询,怎么使用?性能怎么样?需要注意什么?将会在文章中通过示例和数据说明。
二.分页查询
1. 语法说明
[ LIMIT { count } ]
[ OFFSET start [ ROW | ROWS ] ]
[ FETCH { FIRST | NEXT } [ count ] { ROW | ROWS } ONLY ]
Limit或者Fetch在order by子句后转化为为top-N的查询,其中offset子句表示从开始的位置跳过多少行开始扫描。
对于以下的offsset使用示例, 我们可发现当offset的值为0时,查询结果从第一行记录开始扫描limit指定的行数,当offset值为1时查询结果从第二行记录开始开始扫描limit指定的行数。
0: jdbc:phoenix:localhost> select SS_CUSTOMER_SK from STORE_SALES where SS_ITEM_SK < 3600order by SS_ITEM_SK limit 6; +-----------------+| SS_CUSTOMER_SK |+-----------------+| 109734 || null || 168740 || 344372 || 249078 || 241017 |+-----------------+6 rows selected (0.025 seconds)0: jdbc:phoenix:localhost> select SS_CUSTOMER_SK from STORE_SALES where SS_ITEM_SK < 3600 order by SS_ITEM_SK limit 3 offset 0; +-----------------+| SS_CUSTOMER_SK |+-----------------+| 109734 || null || 168740 |+-----------------+3 rows selected (0.034 seconds)0: jdbc:phoenix:localhost> select SS_CUSTOMER_SK from STORE_SALES where SS_ITEM_SK < 3600 order by SS_ITEM_SK limit 3 offset 1; +-----------------+| SS_CUSTOMER_SK |+-----------------+| null || 168740 || 344372 |+-----------------+3 rows selected (0.026 seconds)0: jdbc:phoenix:localhost> select SS_CUSTOMER_SK from STORE_SALES where SS_ITEM_SK < 3600 order by SS_ITEM_SK limit 3 offset 2; +-----------------+| SS_CUSTOMER_SK |+-----------------+| 168740 || 344372 || 249078 |+-----------------+3 rows selected (0.017 seconds)0: jdbc:phoenix:localhost> select SS_CUSTOMER_SK from STORE_SALES where SS_ITEM_SK < 3600 order by SS_ITEM_SK limit 3 offset 3; +-----------------+| SS_CUSTOMER_SK |+-----------------+| 344372 || 249078 || 241017 |+-----------------+3 rows selected (0.024 seconds)
2. 语法示例
SELECT * FROM TEST LIMIT 1000;SELECT * FROM TEST LIMIT 1000 OFFSET 100;SELECT * FROM TEST FETCH FIRST 100 ROWS ONLY;
三.性能测评
我们对如下SQL的limit子句进行性能得到以下结论。
select SS_CUSTOMER_SK from STORE_SALESwhere SS_ITEM_SK < 3600 order by SS_ITEM_SK limit <m> offset <n>
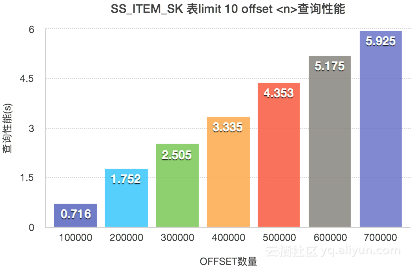
结论1:当limit的值一定时,随着offset N的值越大,查询性基本会线性下降。
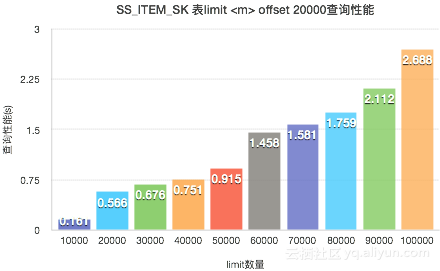
结论2:当offset的值一定时,随着Limit的值越大,查询性能逐步下降。当limit的值相差一个数量级时,查询性能也会有几十倍的差距。
四.最后
大多数场景中分页查询都是和order by子句一起使用的, 在这里需要注意的是,order by的排序字段最好是主键,否则查询性能会比较差。(这部分最好是在做业务层设计时就能考虑到)分页查询需要根据用户的实际需求来设计,在现实产品中,一般很少有上万行每页的需求,页数太大是不合理的,同时页数太多也是不合理的。度量是否合理,仍需要根据实际需求出发。
参考
https://phoenix.apache.org/language/index.html#select
https://phoenix.apache.org/paged.html
