数据仓库Hive的安装与使用
JunLeon——go big or go home

目录
前言:
为什么要学习Hive?
Hive的优点是学习成本低,可以通过类似SQL语句实现快速MapReduce统计,使MapReduce变得更加简单,而不必开发专门的MapReduce应用程序。
hive是十分适合数据仓库的统计分析,处理一些大型数据集,比传统数据仓库更加高效快捷。
一、Hive的概述
1、什么是Hive?
Hive是基于Hadoop的数据仓库工具。可以用于存储在Hadoop集群中的HDFS文件数据集进行数据整理、特殊查询和分析处理。Hive提供了类似于关系型数据库SQL语言的HiveQL工具,通过HiveQL可以快速实现简单的MapReduce统计。
Hive的本质就是将HiveQL语句转换为MapReduce任务后运行,非常适合做数据仓库的数据分析。
2、Hive的应用场景
Hive构建在Hadoop文件系统之上,Hive不提供实时的查询和基于行级的数据更新操作,不适合需要低延迟的应用,如联机事务处理(On-line Transaction Processing,OLTP)相关应用。
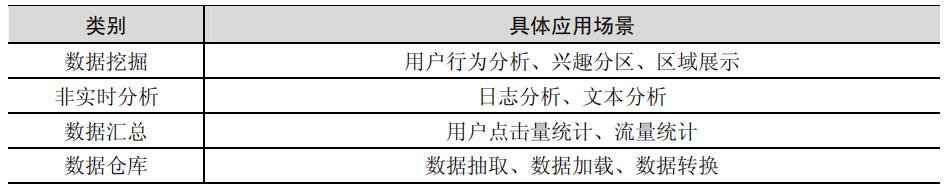
Hive适用于联机分析处理(On-Line Analytical Processing,OLAP),应用场景如图所示:
3、Hive的特性
Hive作为数据仓库软件,使用类SQL的HiveQL语言实现数据查询,所有Hive数据均存储在Hadoop文件系统中,Hive具有以下特性。
1)使用HiveQL以类SQL查询的方式轻松访问数据,将HiveQL查询转换为MapReduce的任务在Hadoop集群上执行,完成ETL(Extract、Transform、Load,提取、转换、加载)、报表、数据分析等数据仓库任务。HiveQL内置大量UDF(User Defined Function)来操作时间、字符串和其他的数据挖掘工具,支持用户扩展UDF函数来完成内置函数无法实现的操作。
2)多种文件格式的元数据服务,包括TextFile、SequenceFile、RCFile和ORCFile,其中TextFile为默认格式,创建SequenceFile、RCFile和ORCFile格式的表需要先将文件数据导入到TextFile格式的表中,然后再把TextFile表的数据导入SequenceFile、RCFile和ORCFile表中。
3)直接访问HDFS文件或其他数据存储系统(如HBase)中的文件。 ·
4)支持MapReduce、Tez、Spark等多种计算引擎,可根据不同的数据处理场景选择合适的计算引擎。
5)支持HPL/SQL程序语言,HPL/SQL是一种混合异构的语言,可以理解几乎任何现有的过程性SQL语言(如Oracle PL/SQL、Transact-SQL)的语法和语义,有助于将传统数据仓库的业务逻辑迁移到Hadoop上,是在Hadoop中实现ETL流程的有效方式。
6)可以通过HiveLLAP(Live Long and Process)、Apache YARN和Apache Slider(动态YARN应用,可按需动态调整分布式应用程序的资源)进行秒级的查询检索。LLAP结合了持久查询服务器和优化的内存缓存,使Hive能够立即启动查询,避免不必要的磁盘开销,提供较佳的查询检索效率。
4、Hive与传统数据仓库的区别
Hive是用于查询分布式大型数据集的数据仓库,相比于传统数据仓库,在大数据的查询上有其独特的优势,但同时也牺牲了一部分性能,如下图:

二、Hive的架构与数据存储
1、Hive的架构原理
Hive架构中主要包括客户端(Client)、Hive Server、元数据存储(MetaStore)、驱动器(Driver)。

1) Hive架构
Hive有多种接口供客户端使用,其中包括Thrift(Apache的一种软件框架,用于可扩展的跨语言服务开发)接口、数据库接口、命令行接口和Web接口。
数据库接口包括ODBC(Open Database Connectivity,开放数据库连接)和JDBC(Java DataBase Connectivity,Java数据库连接)。
客户端通过Thrift接口及数据库接口访问Hive时,用户需连接到Hive Server,通过Hive Server与Driver通信。命令行接口CLI是和Hive交互的最简单方式,可以直接调用Driver进行工作。CLI只能支持单用户,可用于管理员工作,但不适用于高并发的生产环境。用户也可使用Web接口通过浏览器直接访问Driver并调用其进行工作。
Hive Server作为JDBC和ODBC的服务端,提供Thrift接口,可以将Hive和其他应用程序集成起来。Hive Server基于Thrift软件开发,又被称为Thrift Server。Hive Server有两个版本,包括HiveServer和HiveServer2。HiveServer2本身自带了一个命令行工具BeeLine,方便用户对HiveServer2进行管理。
MetaStore存储Hive的元数据,Hive的元数据包括表的名字、表的属性、表的列和分区及其属性、表的数据所在目录等。元数据被存储在单独的关系数据库中,常用的数据库有MySQL和Apache Derby(Java数据库)。MetaStore提供Thrift界面供用户查询和管理元数据。
Driver接收客户端发来的请求,管理HiveQL命令执行的生命周期,并贯穿Hive任务整个执行期间。Driver中有编译器(Compiler)、优化器(Optimizer)和执行器(Executor)三个角色。Compiler编译HiveQL并将其转化为一系列相互依赖的Map/Reduce任务。Optimizer分为逻辑优化器和物理优化器,分别对HiveQL生成的执行计划和MapReduce任务进行优化。Executor按照任务的依赖关系分别执行Map/Reduce任务。
2)HCatalog
HCatalog用于Hadoop的表和元数据管理,使用户可以使用不同的数据处理工具(如Pig、MapReduce等)更轻松地读取和写入元数据。HCatalog基于Hive的MetaStore为数据处理工具提供服务。
下图中,HCatalog通过Hive提供的HiveMetaStoreClient对象来间接访问MetaStore,对外提供HCatLoader、HCatInputFormat来读取数据;提供HCatStorer、HCatOutputFormat来写入数据。

3)WebHCat
WebHCat是HCatalog的REST(Representational State Transfer,表现状态传输)接口,可以使用户能够通过安全的HTTPS协议执行操作。如图6-3所示,用户可以通过WebHCat访问Hadoop MapReduce(或YARN)、Pig(Apache的大型数据集分析平台)、Hive和HCatalog DDL(Data Definition Language,数据库模式定义语言)。WebHCat所使用的数据和代码在HDFS中维护,执行操作时需从HDFS读取。HCatalog DLL命令在接收请求时直接执行;MapReduce、Pig和Hive作业则由WebHCat服务器排队执行,可以根据需要监控或停止。 
2、Hive的数据存储模型
Hive主要包括三类数据模型:表(Table)、分区(Partition)和桶(Bucket)。
Hive中的表类似于关系数据库中的表。表可以进行过滤、投影、连接和联合等操作。表的数据一般存储在HDFS的目录中,Hive的表实质上对应Hadoop文件系统上的一个目录。Hive将表的元数据存储在关系型数据库中,实现了元数据与数据的分离存储。
Hive根据分区列(Partition Column)的值将表以分区的形式进行划分,例如具有“日期”分区列的表可以根据日期划分为多个分区。表中的一个分区对应表所在目录下的一个子目录。
1)Hive的分区和分桶
Hive将数据组织成数据库表的形式供用户进行较高效的查询分析。Hive处理的数据集一般较大,为了提高查询的效率,Hive会在表的基础上进一步对数据的划分进行细化。
当表数据量较大时,Hive通过列值(如日期、地区等)对表进行分区处理(Partition),便于局部数据的查询操作。每个分区是一个目录,将相同属性的数据放在同个目录下,可提高查询效率。分区数量不固定,分区下可再有分区或者进一步细化为桶。
Hive可将表或分区进一步组织成桶,桶是比分区粒度更细的数据划分方式。每个桶是一个文件,用户可指定划分桶的个数。在分桶的过程中,Hive针对某一列进行哈希计算,根据哈希值将这一列中的数据划分到不同的桶中。分桶为表提供了额外的结构,Hive在处理某些查询(如join、表的合并)时利用这个结构可以提高效率,使数据抽样更高效。
2)Hive的托管表和外部表
Hive中的表分为两种,分别为托管表和外部表,托管表又称为内部表。Hive默认创建托管表,托管表由Hive来管理数据,意味着Hive会将数据移动到数据仓库的目录中。若创建外部表,Hive仅记录数据所在路径,不将其移动到数据仓库目录中。在读取外部表时,Hive会在数据仓库之外读取数据。在做删除表的操作时,托管表的元数据和数据会被一起删除,而外部表仅删除元数据,处于数据仓库外部的数据则被保留。外部表相对于托管表要更为安全,也利于数据的共享。
选择使用外部表还是托管表组织数据取决于用户对数据的处理方式,如果一个数据集的数据处理操作都由Hive完成,则使用托管表;当需要使用桶时,则必须使用托管表。如果需要用Hive和其他工具一起处理同一个数据集,或者需要将同一个数据集组织成不同的表,则使用外部表。
三、Hive的安装使用
1、环境准备
MySQL下载:mysql-5.7.33-1.el7.x86_64.rpm-bundle.tar
官方下载:MySQL :: MySQL Community Downloads
MySQL安装采用rpm管理安装,故下载rpm包。
Hive下载:apache-hive-2.3.3-bin.tar.gz
官方下载:Index of /dist/hive
2、安装MySQL
1.上传下载好的MySQL包到Linux的/opt目录下
2.解压MySQL的压缩包
cd /opt
mkdir mysql
tar -xvf mysql-5.7.33-1.el7.x86_64.rpm-bundle.tar -C mysql/
cd myql3.安装
安装时按照 common--libs--clients--server的顺序安装
安装之前先查看是否安装MySQL
rpm -qa | grep mysql
# 如果有自带或者其他版本的mysql就卸载掉,卸载命令如下:
rpm -e --nodeps mysql包名还需要卸载自带的mariadb和安装mysql-libs需要的依赖包:
# 查询mariadb
rpm -qa | grep mariadb
# 卸载
rpm -e --nodeps mariadb-xxx(这是查询出来的包名)
# 安装依赖包,安装时输入y即可
yum install perl(1)安装common
rpm -ivh mysql-community-common-5.7.33-1.el7.x86_64.rpm(2)安装libs
rpm -ivh mysql-community-libs-5.7.33-1.el7.x86_64.rpm(3) 安装clients
rpm -ivh mysql-community-client-5.7.33-1.el7.x86_64.rpm(4)安装server
rpm -ivh mysql-community-server-5.7.33-1.el7.x86_64.rpm(5)启动MySQL服务
[root@localhost mysql]# systemctl start mysqld
[root@localhost mysql]# systemctl status mysqld
[root@localhost mysql]# ps -ef | grep mysql(6) 进入MySQL
grep 'temporary password' /var/log/mysqld.log # 获取初始密码
mysql -u root -p(7)修改初始密码
mysql> set global validate_password_policy=0;
mysql> set global validate_password_length=1;
mysql> alter user root@localhost identified by 'root123456';(8)创建hive元数据存储数据库
create database hive character set latin1;(9) 创建数据库用户hive及分配权限
create user 'hive'@'%' identified by 'hive123456';
grant all privileges on hive . * to 'hive'@'%' with grant option;
flush privileges;
show grants;(10)增加从本地查看数据库用户信息的权限
grant all privileges on hive . * to 'hive'@'localhost' identified by 'hive123456';
flush privileges;
use mysql;
select host,user password from user;3、安装Hive
(1)上传hive的压缩包到/opt目录下
(2)解压压缩包到opt目录下
cd /opt
tar -zxvf apache-hive-2.3.3-bin.tar.gz
mv apache-hive-2.3.3-bin hive-2.3.3(3)配置hive的环境变量
export HIVE_HOME=/opt/hive-2.3.3
export HIVE_CONF_DIR=$HIVE_HOME/conf
export HCAT_HOME=$HIVE_HOME/hcatalog
export PATH=$HIVE_HOME/bin:$PATH使配置文件生效
source /etc/profile(4)配置hive
cd /opt/hive-2.3.3/confcp hive-env.sh.template hive-env.sh
vi hive-env.sh在文件48行,配置hadoop路径
HADOOP_HOME=/opt/hadoop-2.7.3保存hive-env.sh文件后,进入hive-site.xml文件复制以下配置进去
vi hive-site.xml<?xml version="1.0" encoding="UTF-8" standalone="no"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?><!--
Licensed to the Apache Software Foundation (ASF) under one or more
contributor license agreements. See the NOTICE file distributed with
this work for additional information regarding copyright ownership.
The ASF licenses this file to You under the Apache License, Version 2.0
(the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
-->
<configuration>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://localhost:3306/hive?createDatabaseIfNotExist=true</value>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>hive</value>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>hive123456</value>
</property>
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/user/hive/warehouse</value>
</property>
<property>
<name>hive.hbase.snapshot.restoredir</name>
<value>/tmp</value>
</property>
<property>
<name>system:java.io.tmpdir</name>
<value>/opt/hive-2.3.3/iotmp</value>
</property>
<property>
<name>system:user.name</name>
<value>hive</value>
</property>
<property>
<name>hive.exec.local.scratchdir</name>
<value>${system:java.io.tmpdir}/${system:user.name}</value>
</property>
<property>
<name>hive.downloaded.resources.dir</name>
<value>${system:java.io.tmpdir}/${hive.session.id}_resources</value>
</property>
</configuration>修改hive-log4j2.properties文件和hive-exec-log4j2.properties文件
cp hive-log4j2.properties.template hive-log4j2.properties
cp hive-exec-log4j2.properties.template hive-exec-log4j2.properties(5)在HDFS中创建hive的目录
保证hadoop节点开启,能够访问HDFS
hadoop fs -mkdir -p /user/hive/warehouse(6)将MySQL的JDBC驱动包文件复制到$HIVE_HOME/lib
先将MySQL的驱动包下载上传至/opt/目录中
cd /opt
mv mysql-connector-java-5.1.49.jar hive-2.3.3/lib/(7)Hive的初始化
schematool -dbType mysql -initSchema(8)进入hive环境
hive四、HiveQL语句
hive下运行其他命令:
hive> set -v; # 查看系统配置信息
hive> quit; # 退出hive
hive> exit; # 同上(1)创建数据库、表、视图
① 创建数据库
语法格式:
create database [if not exists] <数据库名>;
hive> create database if not exists student_db; # 创建数据库student_db
hive> use student_db; # 使用student_db② 创建表
语法格式:
create table [if not exists] <表名> row format delimited fields terminated by '分隔符' ;
注:如果不指定分隔符,hive表默认分隔符为 ^A (\001) ,这是一种特殊的分隔符,使用的是 ASCII 编码的值,键盘是打不出来的,故一般需要手动添加分隔符。
hive> create table if not exists student(id bigint,name string, age int); # 创建一张学生表
desc student; # 查看student表结构创建外部表:
hive> create external table if not exists stu_external(id bigint,username string,userpwd string)
> row format delimited fields terminated by ','
> location 'user/hive/warehouse/student_db.db/stu_external';
# 创建一张外部表,指定地址为'user/hive/warehouse/student_db.db/stu_external'注: 如果不指定location地址,则会默认存储到该数据库中。
③ 创建视图
语法格式:
create view <视图名> as select <视图的列,使用逗号隔开> from <表名>;
hive> create view viewStudent as select name,age from student; # 创建视图(2)删除数据库、表、视图
① 删除数据库
语法格式:
drop database [if exists] <数据库名>
注:如果该数据不是一个空的数据库,则需要删除数据库内的内容方可删除,或者强制删除数据库
强制删除(慎用):
drop database <数据库名> cascade;
hive> drop database if exists student_db; # 删除数据库student_db② 删除表
语法格式:
drop table [if exists] <表名>
hive> drop table if exists stu; # 删除表stu③ 删除视图
语法格式:
drop view [if exists] <视图名>
hive> drop view if exists viewstudnet; # 删除视图viewstudent(3)修改数据库、表、视图
① 修改数据库
语法格式:
alter database <数据库名> ....
hive> alter database student_db set dbprtperties('edited-by'='steven'); # 修改数据库属性② 修改表
语法格式:
alter table <表名> ....
hive> alter table student rename to studentinfo; # 将student表名更改为studentinfo(重命名)
hive> alter table studentinfo add columns(address string); # 为studentinfo添加一列address(4) 查看数据库、表、视图
① 查看数据库表
hive> show databases;
hive> show databases like 'h.*' # 查看和h开头的所有数据库② 查看表和视图
hive> show tables; # 查看表和视图
hive> show tables in student_db like 'v.*'; # 查看在student_db中的所有以u开头的表和视图③ 查看数据库、表、视图的信息
hive> desc database student_db; # 查看数据的描述性信息
hive> desc extended student; # 查看表信息
hive> desc extended stu_external; # 查看外部表信息
hive> desc viewstudent; # 查看视图(5)向表装载数据
语法格式:
load data [local] inpath '数据路径' [overwrite] into table <表名>;
local--从本地虚拟机中获取数据,不过不使用local,则从HDFS中获取数据。
overwrite--覆盖表的原数据,如果不使用overwrite,则会在表末尾追加数据。
本地数据的准备:/root/userinfo.txt
1001 张三
1002 李四
1003 王五
1004 赵六
1005 吴七
准备一个追加的文件:/root/userinfo_append.txt
hive> load data local inpath '/root/userinfo.txt' overwrite into table student; # 将userinfo.txt的数据覆盖到student表中
hive> load data local inpath '/root/userinfo_append.txt' into table student; # 将userinfo_append.txt数据追加到student表中注:如果在加载数据时不使用 'overwrite' ,则会将数据追加到元数据的末尾。如果加上 ‘overwrite’ ,则会将元数据覆盖。
查询表数据:
hive> select * from student;五、Hive应用简单示例:WorldCount
1、创建一个data目录准备worldcount计算的文件file1.txt、file2.txt
[root@BigData01 ~]# mkdir data
[root@BigData01 ~]# cd data
[root@BigData01 data]# vi file1.txt
hello world
hello hadoop
hello java
hello python
[root@BigData01 data]# vi file2.txt
welcome to hadoop
python java hadoop
2、进入hive环境,编写HiveQL语句实现WordCount算法
[root@BigData01 data]# hive
hive> create database if not exists testdb;
hive> use testdb;
hive> create table if not exists docs(line string);
hive> load data local inpath '/root/data/' overwrite into table docs;
# 编写HiveQL语句实现WordCount算法
hive> create table wordcount as
> select word,count(1) as count from
> (select explode(split(line,' ')) as word from docs) w
> group by word
> order by word;说明:语句中先使用split以空格进行分割得到一数组,再使用explode将数组拆分成单列多行,然后使用count统计数量即可。
3、查看运行结果:

输入命令查看hive执行查询后再集群上产生的文件,输出结果位于wordcount/000000_0目录中:

下一篇:数据转换工具Sqoop的实战(超详细)
如果你喜欢、对你有帮助,点赞+收藏,跟着军哥学知识……