文章目录
1 函数
1.1 系统内置函数
1. 查看系统自带的函数
hive (default)> show functions;
2. 显示自带的函数的用法
hive (default)> desc function upper;
3. 详细显示自带的函数的用法
hive (default)> desc function extended upper;
1.2 常用内置函数
1.2.1 空字段赋值
(1)函数说明
NVL:给值为 NULL的数据赋值,它的格式是 NVL(value,default_value)。它的功能是如果 value为 NULL,则 NVL函数返回 default_value 的值,否则返回 value 的值。如果两个参数都为 NULL,则返回 NULL。
(2)数据准备:采用员工表
(3)查询:如果员工的 comm为 NULL,则用 -1代替
hive (default)> select comm, nvl(comm, -1) from emp;
OK
comm _c1
NULL -1.0
300.0 300.0
500.0 500.0
NULL -1.0
1400.0 1400.0
NULL -1.0
NULL -1.0
NULL -1.0
NULL -1.0
0.0 0.0
NULL -1.0
NULL -1.0
NULL -1.0
NULL -1.0
NULL -1.0
Time taken: 2.891 seconds, Fetched: 15 row(s)
(4)查询:如果员工的 comm 为 NULL,则用领导 id 代替
hive (default)> select comm, nvl(comm, mgr) from emp;
OK
comm _c1
NULL 7902.0
300.0 300.0
500.0 500.0
NULL 7839.0
1400.0 1400.0
NULL 7839.0
NULL 7839.0
NULL 7566.0
NULL NULL
0.0 0.0
NULL 7788.0
NULL 7698.0
NULL 7566.0
NULL 7782.0
NULL 7782.0
1.2.2 CASE WHEN THEN ELSE END
(1)数据准备(人名来自电视剧《将夜》)
name dept_id sex
夫子 A 男
观主 B 男
李慢慢 A 男
余帘 A 女
叶红鱼 B 女
君陌 A 男
叶青 B 男
宁缺 A 男
木柚 A 女
(2)需求:求出不同部门男女各多少人。
(3)创建 hive 表并导入数据
hive (default)> create table emp_sex(
> name string,
> dept_id string,
> sex string)
> row format delimited fields terminated by "\t";
OK
Time taken: 0.64 seconds
(4)按需求查询数据
hive (default)> select dept_id,
> sum(case sex when '男' then 1 else 0 end) male_count,
> sum(case sex when '女' then 1 else 0 end) female_count
> from emp_sex
> group by dept_id;
OK
dept_id male_count female_count
A 4 2
B 2 1
Time taken: 9.155 seconds, Fetched: 2 row(s)
1.2.3 行转列
1. 相关函数说明
CONCAT(string A/col, string B/col…):返回输入字符串连接后的结果,支持任意个输入字符串 ;
CONCAT_WS(separator, str1, str2,…):它是一个特殊形式的 CONCAT()。第一个参数表示剩余参数间的分隔符。分隔符可以是与剩余参数一样的字符串。如果分隔符是 NULL ,返回值也将为 NULL 。这个函数会跳过分隔符参数后的任何 NULL 和空字符串。分隔符将被加到被连接的字符串之间;
注意: CONCAT_WS must be string or array<string>
COLLECT_SET(col):函数只接受基本数据类型,它的主要作用是将某字段的值进行去重汇总,产生 Array类型字段。
2. 数据准备(人名来自于电视剧《将夜》)
name constellation blood_type
柳白 白羊座 A
讲经首座 射手座 A
陈某 白羊座 B
陈皮皮 白羊座 A
莫山山 射手座 A
熊初墨 白羊座 B
柯浩然 射手座 A
3. 需求
把星座和血型一样的人归类到一起。
4. 创建hive表并导入数据
hive (default)> create table person_info(
> name string,
> constellation string,
> blood_type string)
> row format delimited fields terminated by '\t';
OK
Time taken: 0.848 seconds
hive (default)> load data local inpath "/opt/module/hive-3.1.2/data/person_info.txt" into table person_info;
Loading data to table default.person_info
OK
Time taken: 0.682 seconds
5. 按需求查询数据
hive (default)> select t1.c_b, concat_ws("|", collect_set(t1.name))
> from (select name,concat_ws(',', constellation,blood_type) c_b
> from person_info) t1
> group by t1.c_b;
OK
t1.c_b _c1
射手座,A 讲经首座|莫山山|柯浩然
白羊座,A 柳白|陈皮皮
白羊座,B 陈某|熊初墨
Time taken: 24.49 seconds, Fetched: 3 row(s)
1.2.4 列转行
1. 函数说明
EXPLODE( 将 hive 一 列中复杂的 Array 或者 Map 结构拆分成多行。
LATERAL VIEW
用法:LATERAL VIEW udtf(expression) tableAlias AS columnAlias
解释:用于和 split, explode 等 UDTF 一起使用 它能够将一列数据拆成多行数据,在此基础上可以对拆分后的数据进行聚合。
2. 数据准备
movies category
《流浪地球》 悬疑,动作,科幻,剧情
《警察故事》 悬疑,警匪,动作,心理,剧情
《战狼2》 战争,动作,灾难
3. 需求:将电影分类中的数组数据展开。
4. 创建 hive 表并导入数据
hive (default)> create table movie_info(
> movie string,
> category string)
> row format delimited fields terminated by '\t';
OK
Time taken: 0.143 seconds
hive (default)> load data local inpath "/opt/module/hive-3.1.2/data/movie_info.txt" into table movie_info;
Loading data to table default.movie_info
OK
Time taken: 0.518 seconds
5. 按需求查询数据
hive (default)> select movie, category_name
> from movie_info
> lateral view
> explode(split(category, ",")) movie_info_tmp as category_name;
OK
movie category_name
《流浪地球》 悬疑
《流浪地球》 动作
《流浪地球》 科幻
《流浪地球》 剧情
《警察故事》 悬疑
《警察故事》 警匪
《警察故事》 动作
《警察故事》 心理
《警察故事》 剧情
《战狼2》 战争
《战狼2》 动作
《战狼2》 灾难
Time taken: 0.132 seconds, Fetched: 12 row(s)
1.2.5 窗口函数(开窗函数)
1. 相关函数说明
OVER():指定分析函数工作的数据窗口大小,这个数据窗口大小可能会随着行的变而变化。
CURRENT ROW:当前行
n PRECEDING :往前 n 行数据
n FOLLOWING :往后 n 行数据
UNBOUNDED:起点,UNBOUNDED PRECEDING 表示从前面的起点,UNBOUNDED FOLLOWING 表示到后面的终点。
LAG(col,n,default_val):往前第 n 行数据
LEAD(col,n,default_val )):往后第 n 行数据
NTILE(n):把有序窗口的行分发到指定数据的组中,各个组有编号,编号从 1 开始,对于每一行, NTILE 返回此行所属的组的编号。 注意: n 必须为 int 类型。
2. 数据准备: name,orderdate,cost
jack,2017-01-01,10
tony,2017-01-02,15
jack,2017-02-03,23
tony,2017-01-04,29
jack,2017-01-05,46
jack,2017-04-06,42
tony,2017-01-07,50
jack,2017-01-08,55
mart,2017-04-08,62
mart,2017-04-09,68
neil,2017-05-10,12
mart,2017-04-11,75
neil,2017-06-12,80
mart,2017-04-13,94
3. 创建 hive表并导入数据
hive (default)> create table business(
> name string,
> orderdate string,
> cost int
> ) row format delimited fields terminated by ',';
OK
Time taken: 0.864 seconds
hive (default)> load data local inpath "/opt/module/hive-3.1.2/data/business.txt" into table business;
Loading data to table default.business
OK
Time taken: 0.777 seconds
4. 按需求查询数据
(1)查询在 2017 年 4 月份购买过的顾客及总人数
hive (default)> select name, count(*) over()
> from business
> where substring(orderdate,1,7)='2017-04'
> group by name;
OK
name count_window_0
jack 2
mart 2
(2)查询顾客的购买明细及月购买总额
hive (default)> select name, orderdate, cost, sum(cost) over(partition by month(orderdate))
> from business;
OK
name orderdate cost sum_window_0
jack 2017-01-01 10 205
tony 2017-01-02 15 205
tony 2017-01-04 29 205
jack 2017-01-05 46 205
tony 2017-01-07 50 205
jack 2017-01-08 55 205
jack 2017-02-03 23 23
mart 2017-04-13 94 341
mart 2017-04-08 62 341
mart 2017-04-09 68 341
mart 2017-04-11 75 341
jack 2017-04-06 42 341
neil 2017-05-10 12 12
neil 2017-06-12 80 80
Time taken: 31.353 seconds, Fetched: 14 row(s)
(3)将每个顾客的 cost 按照日期进行累加
hive (default)> select name, orderdate, cost,
> sum(cost) over() as sample,
> sum(cost) over(partition by name) as sample2,
> sum(cost) over(partition by name order by orderdate) as sample3,
> sum(cost) over(partition by name order by orderdate rows between unbounded preceding and current row) as sample4,
> sum(cost) over(partition by name order by orderdate rows between 1 preceding and current row) as sample5,
> sum(cost) over(partition by name order by orderdate rows between 1 preceding and 1 following) as sample6,
> sum(cost) over(partition by name order by orderdate rows between current row and unbounded following) as sample7
> from business;
OK
name orderdate cost sample sample2 sample3 sample4 sample5 sample6 sample7
jack 2017-01-01 10 661 176 10 10 10 56 176
jack 2017-01-05 46 661 176 56 56 56 111 166
jack 2017-01-08 55 661 176 111 111 101 124 120
jack 2017-02-03 23 661 176 134 134 78 120 65
jack 2017-04-06 42 661 176 176 176 65 65 42
mart 2017-04-08 62 661 299 62 62 62 130 299
mart 2017-04-09 68 661 299 130 130 130 205 237
mart 2017-04-11 75 661 299 205 205 143 237 169
mart 2017-04-13 94 661 299 299 299 169 169 94
neil 2017-05-10 12 661 92 12 12 12 92 92
neil 2017-06-12 80 661 92 92 92 92 92 80
tony 2017-01-02 15 661 94 15 15 15 44 94
tony 2017-01-04 29 661 94 44 44 44 94 79
tony 2017-01-07 50 661 94 94 94 79 79 50
Time taken: 26.212 seconds, Fetched: 14 row(s)
sample表示所有行相加,sample2表示按name分组,组内数据相加,sample3表示按name分组,组内数据累加,sample4和sample3一样,由起点到当前行的聚合,sample5表示当前行和前面一行聚合,sample表示当前行和前边一行及后面一行聚合,sample7表示当前行及后面所有行聚合。
rows必须跟在 order by 子句之后,对排序的结果进行限制,使用固定的行数来限制分区中的数据行数量。
(4)查看顾客上次的购买时间
hive (default)> select name, orderdate, cost,
> lag(orderdate, 1, '1900-01-01') over(partition by name order by orderdate)
> as time1, lag(orderdate, 2) over (partition by name order by orderdate) as time2
> from business;
OK
name orderdate cost time1 time2
jack 2017-01-01 10 1900-01-01 NULL
jack 2017-01-05 46 2017-01-01 NULL
jack 2017-01-08 55 2017-01-05 2017-01-01
jack 2017-02-03 23 2017-01-08 2017-01-05
jack 2017-04-06 42 2017-02-03 2017-01-08
mart 2017-04-08 62 1900-01-01 NULL
mart 2017-04-09 68 2017-04-08 NULL
mart 2017-04-11 75 2017-04-09 2017-04-08
mart 2017-04-13 94 2017-04-11 2017-04-09
neil 2017-05-10 12 1900-01-01 NULL
neil 2017-06-12 80 2017-05-10 NULL
tony 2017-01-02 15 1900-01-01 NULL
tony 2017-01-04 29 2017-01-02 NULL
tony 2017-01-07 50 2017-01-04 2017-01-02
time1表示顾客上次购买的时间,没有的话用’1900-01-01’代替,time2表示顾客前两次购买的时间。
(5)查询前 20% 时间的订单信息
hive (default)> select * from(
> select name, orderdate, cost, ntile(5) over(order by orderdate) sorted
> from business
> ) t
> where sorted = 1;
OK
t.name t.orderdate t.cost t.sorted
jack 2017-01-01 10 1
tony 2017-01-02 15 1
tony 2017-01-04 29 1
将数据按时间分为5个组,取第一个组的数据。
1.2.6 Rank
1. 函数说明
RANK():排序相同时会重复,总数不会变
DENSE_RANK():排序相同时会重复,总数会减少
ROW_NUMBER():会根据顺序计算
2. 数据准备(人名来自电视剧《将夜》)
柯浩然 语文 87
柯浩然 数学 95
柯浩然 英语 68
余帘 语文 94
余帘 数学 58
余帘 英语 84
颜瑟 语文 64
颜瑟 数学 86
颜瑟 英语 84
王景略 语文 65
王景略 数学 85
王景略 英语 78
3. 创建 hive 表并导入数据
hive (default)> create table score(
> name string,
> subject string,
> score int)
> row format delimited fields terminated by "\t";
OK
Time taken: 0.672 seconds
hive (default)> load data local inpath '/opt/module/hive-3.1.2/data/score.txt' into table score;
Loading data to table default.score
OK
Time taken: 0.48 seconds
4. 计算每门学科成绩排名
hive (default)> select name, subject, score,
> rank() over(partition by subject order by score desc) rp,
> dense_rank() over(partition by subject order by score desc) drp,
> row_number() over(partition by subject order by score desc) rmp
> from score;
OK
name subject score rp drp rmp
柯浩然 数学 95 1 1 1
颜瑟 数学 86 2 2 2
王景略 数学 85 3 3 3
余帘 数学 58 4 4 4
余帘 英语 84 1 1 1
颜瑟 英语 84 1 1 2
王景略 英语 78 3 2 3
柯浩然 英语 68 4 3 4
余帘 语文 94 1 1 1
柯浩然 语文 87 2 2 2
王景略 语文 65 3 3 3
颜瑟 语文 64 4 4 4
Time taken: 18.441 seconds, Fetched: 12 row(s)
1.3 自定义函数
(1)Hive 自带了一些函数,比如 max/min等,但是数量有限,自己可以通过自定义 UDF 来方便的扩展。
(2)当 Hive提供的内置函数无法满足你的业务处理需要时 此时就可以考虑使用用户自定义函数(UDF:user-defined function)。
(3)根据用户自定义函数类别分为以下三种:
UDF(User-Defined-Function):一进一出
UDAF(User-Defined Aggregation Function):聚集函数,多进一出,类似于 count/max/min
UDTF(User-Defined Table-Generating Functions):一进多出,如 lateral view explode()
(4)官方文档地址
https://cwiki.apache.org/confluence/display/Hive/HivePlugins
(5)编程步骤:
1)继承 Hive 提供的类
org.apache.hadoop.hive.ql.udf.generic.GenericUDF
org.apache.hadoop.hive.ql.udf.generic.GenericUDTF;
2)实现类中的抽象方法
3)在 hive 的命令行窗口创建函数
添加jar,add jar linux_jar_path
创建function,create [temporary] function [dbname.]function_name AS class_name;
4)在 hive 的命令行窗口删除函数
drop [temporary] function [if exists] [dbname.]function_name;
1.4 自定义 UDF函数
1. 需求:自定义一个UDF 实现计算给定字符串的长度
如:
hive(default)> select my_len("abcd")
4
2. 创建一个 Maven 工程 Hive
3. 导入依赖
<dependencies>
<dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-exec</artifactId>
<version>3.1.2</version>
</dependency>
</dependencies>
4. 创建一个类
package com.Tom.udf;
import org.apache.hadoop.hive.ql.exec.UDFArgumentException;
import org.apache.hadoop.hive.ql.exec.UDFArgumentLengthException;
import org.apache.hadoop.hive.ql.exec.UDFArgumentTypeException;
import org.apache.hadoop.hive.ql.metadata.HiveException;
import org.apache.hadoop.hive.ql.udf.generic.GenericUDF;
import org.apache.hadoop.hive.serde2.objectinspector.ObjectInspector;
import org.apache.hadoop.hive.serde2.objectinspector.primitive.PrimitiveObjectInspectorFactory;
public class MyUDF extends GenericUDF {
@Override
public ObjectInspector initialize(ObjectInspector[] arguments) throws UDFArgumentException {
// 判断输入参数的个数
if(arguments.length != 1){
throw new UDFArgumentLengthException("Input Args Length Error!!!");
}
// 判断输入参数的类型
if(!arguments[0].getCategory().equals(ObjectInspector.Category.PRIMITIVE)){
throw new UDFArgumentTypeException(0, "Input Args Type Error!!!");
}
//函数本身返回值为int,需要返回int类型的鉴别器对象
return PrimitiveObjectInspectorFactory.javaIntObjectInspector;
}
@Override
public Object evaluate(DeferredObject[] arguments) throws HiveException {
if(arguments[0].get() == null){
return 0;
}
return arguments[0].get().toString().length();
}
@Override
public String getDisplayString(String[] children) {
return "";
}
}
5. 打成 jar包上传到服务器 /opt/module/hive-3.1.2/myudf.jar
6. 将 jar包添加到 hive 的 classpath
hive (default)> add jar /opt/module/hive-3.1.2/hiveDemo-1.0-SNAPSHOT.jar;
7. 创建临时函数与开发好的 java class 关联
hive (default)> create temporary function my_len as "com.Tom.udf.MyUDF";
8. 即可在 hql中使用自定义的函数
hive (default)> select ename, my_len(ename) ename_len from emp;
OK
ename ename_len
SMITH 5
ALLEN 5
WARD 4
JONES 5
MARTIN 6
BLAKE 5
CLARK 5
SCOTT 5
KING 4
TURNER 6
ADAMS 5
JAMES 5
FORD 4
MILLER 6
MILLER 6
Time taken: 0.807 seconds, Fetched: 15 row(s)
1.5 自定义 UDTF 函数
1. 需求:自定义一个UDTF 实现将一个任意分割符的字符串切割成独立的单词
例如:
hive(default)> select myudtf ("hello,world,hadoop,hive",",");
hello
world
hadoop
hive
2. 代码实现
package com.Tom.udtf;
import org.apache.hadoop.hive.ql.exec.UDFArgumentException;
import org.apache.hadoop.hive.ql.metadata.HiveException;
import org.apache.hadoop.hive.ql.udf.generic.GenericUDTF;
import org.apache.hadoop.hive.serde2.objectinspector.ObjectInspector;
import org.apache.hadoop.hive.serde2.objectinspector.ObjectInspectorFactory;
import org.apache.hadoop.hive.serde2.objectinspector.StructObjectInspector;
import org.apache.hadoop.hive.serde2.objectinspector.primitive.PrimitiveObjectInspectorFactory;
import java.util.ArrayList;
import java.util.List;
public class MyUDTF extends GenericUDTF {
private ArrayList<String> outList = new ArrayList<String>();
@Override
public StructObjectInspector initialize(StructObjectInspector argOIs) throws UDFArgumentException {
// 1.定义输出数据的列名和类型
List<String> fieldsNames = new ArrayList<String>();
List<ObjectInspector> fieldOIs = new ArrayList<ObjectInspector>();
//2.添加输出数据的列名和类型
fieldsNames.add("lineToWord");
fieldOIs.add(PrimitiveObjectInspectorFactory.javaStringObjectInspector);
return ObjectInspectorFactory.getStandardStructObjectInspector(fieldsNames, fieldOIs);
}
@Override
public void process(Object[] args) throws HiveException {
//1. 获取原始数据
String arg = args[0].toString();
//2.获取数据传入的第二个参数,此处为分隔符
String splitKey = args[1].toString();
//3.将原始数据按照传入的分隔符进行切分
String[] fields = arg.split(splitKey);
//4.遍历切分后的结果,并写出
for (String field : fields){
//集合为复用的, 首先清空集合
outList.clear();
// 将每一个单词添加至集合
outList.add(field);
//将集合内容写出
forward(outList);
}
}
@Override
public void close() throws HiveException {
}
}
3. 打成 jar包上传到服务器 /opt/module/hive-3.1.2/myudf.jar
4. 将 jar包添加到 hive 的 classpath下
hive (default)> add jar /opt/module/hive-3.1.2/myudtf.jar;
5. 创建临时函数与开发好的 java class 关联
hive (default)> create temporary function myudtf as "com.Tom.udtf.MyUDTF";
6. 使用自定义的函数
hive (default)> select myudtf("hello, world, hadoop, hive", ",");
OK
linetoword
hello
world
hadoop
hive
Time taken: 0.704 seconds, Fetched: 4 row(s)
2 压缩和存储
2.1 Hadoop 压缩配置
1. MR支持的压缩编码
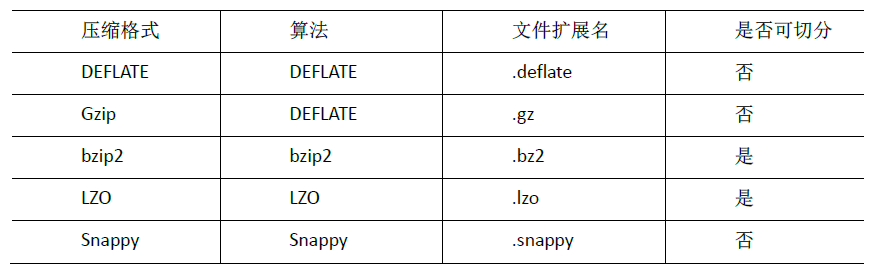
为了支持多种压缩/解压缩算法,Hadoop引入了编码/解码器,如下表所示:
| 压缩格式 | 对应的编码/解码器 |
|---|---|
| DEFLATE | org.apache.hadoop.io.compress.DefaultCodec |
| gzip | org.apache.hadoop.io.compress.GzipCodec |
| bzip2 | org.apache.hadoop.io.compress.BZip2Codec |
| LZO | com.hadoop.compression.lzo.LzopCodec |
| Snappy | org.apache.hadoop.io.compress.SnappyCodec |
压缩性能的比较:

2. 压缩参数配置
要在 Hadoop 中启用压缩 可以配置如下参数( mapred-site.xml文件中):
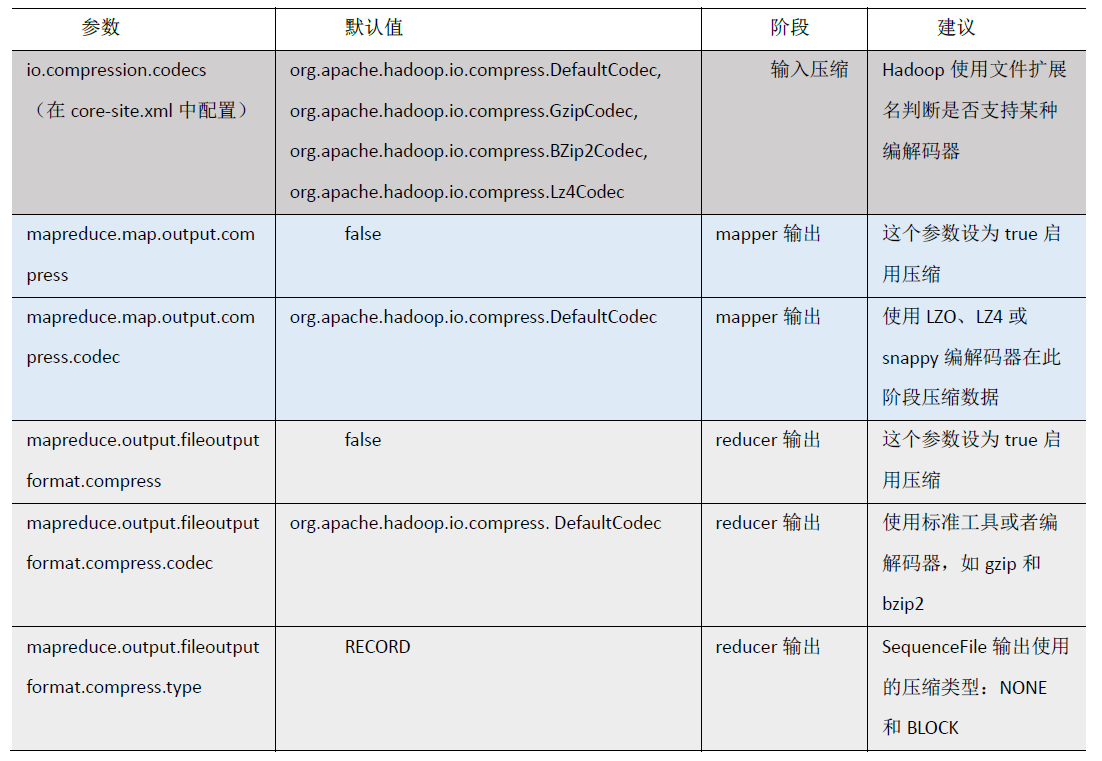
2.2 开启 Map 输出阶段压缩(MR引擎)
开启 map 输出阶段压缩可以减少 job 中 map 和 Reduce task 间数据传输量。具体配置如下:
案例实操
(1)开启 hive 中间传输数据压缩功能
hive (default)> set hive.exec.compress.intermediate=true;
(2)开启 mapreduce中 map输出压缩功能
hive (default)> set mapreduce.map.output.compress=true;
(3)设置 mapreduce中 map输出数据的压缩方式
hive (default)> set mapreduce.map.output.compress.codec=org.apache.hadoop.io.compress.SnappyCodec;
(4)执行查询语句
hive (default)> select count(ename) name from emp;
OK
name
15
Time taken: 33.563 seconds, Fetched: 1 row(s)
2.3 开启 Reduce输出阶段压缩
当 Hive 将输出写入到表中时,输出内容同样可以进行压缩。属性hive.exec.compress.output 控制着这个功能。用户可能需要保持默认设置文件中的默认值 false,这样默认的输出就是非压缩的纯文本文件了。用户可以通过在查询语句或执行脚本中设置这个值为 true ,来开启输出结果压缩功能。
案例实操
(1)开启 hive 最终输出数据压缩功能
hive (default)> set hive.exec.compress.output=true;
(2)开启 mapreduce 最终输出数据压缩
hive (default)> set mapreduce.output.fileoutputformat.compress=true;
(3)设置 mapreduce 最终数据输出压缩方式
hive (default)> set mapreduce.output.fileoutputformat.compress.codec=org.apache.hadoop.io.compress.SnappyCodec;
(4)设置 mapreduce 最终数据输出压缩为块压缩
hive (default)> set mapreduce.output.fileoutputformat.compress.type=BLOCK;
(5)测试一下输出结果是否是压缩文件
hive (default)> insert overwrite local directory
> '/opt/module/hive-3.1.2/data/distribute-result' select * from emp distribute by deptno sort by empno desc;
[Tom@hadoop102 distribute-result]$ ll
总用量 4
-rw-r--r--. 1 Tom Tom 470 9月 5 10:43 000000_0.snappy
2.4 文件存储格式
1. 列式存储和行式存储
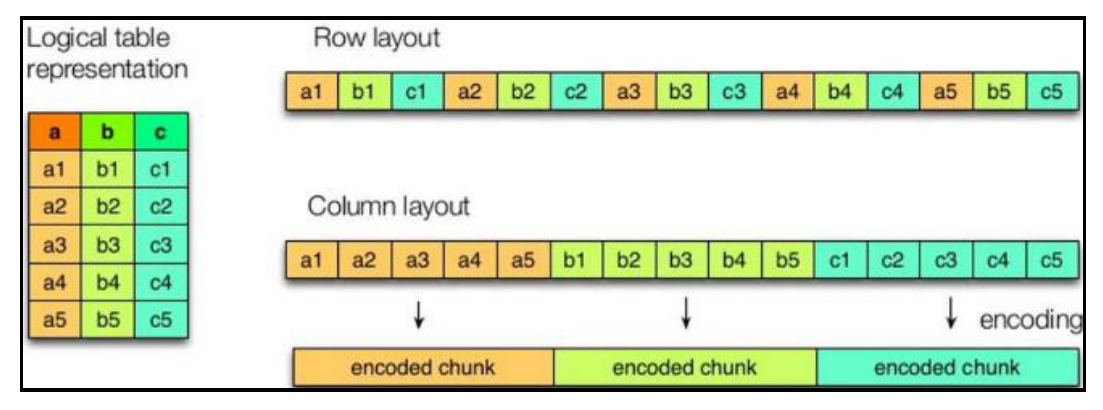
如图所示左边为逻辑表,右边第一个为行式存储,第二个为列式存储。
(1)行存储的特点
查询满足条件的一整行数据的时候,列存储则需要去每个聚集的字段找到对应的每个列的值,行存储只需要找到其中一个值,其余的值都在相邻地方,所以此时行存储查询的速度更快。
(2)列存储的特点
因为每个字段的数据聚集存储,在查询只需要少数几个字段的时候,能大大减少读取的数据量;每个字段的数据类型一定是相同的,列式存储可以针对性的设计更好的设计压缩算法。
TEXTFILE和 SEQUENCEFILE 的存储格式都是基于行存储的;
ORC 和 PARQUET 是基于列式存储的。
2. TextFile格式
默认格式,数据不做压缩,磁盘开销大,数据解析开销大。可结合Gzip、Bzip2使用,但使用 Gzip 这种方式,hive 不会对数据进行切分,从而无法对数据进行并行操作。
3. Orc 格式
Orc (Optimized Row Columnar)是Hive 0.11版里引入的新的存储格式。
如下图所示,可以看到每个Orc文件由1个或多个stripe组成,每个stripe一般为 HDFS 的块大小,每一个stripe 包含多条记录,这些记录按照列进行独立存储,对应到 Parquet 中的 row group 的概念。每个Stripe 里有三部分组成,分别是 Index Data,Row Data,Stripe Footer:
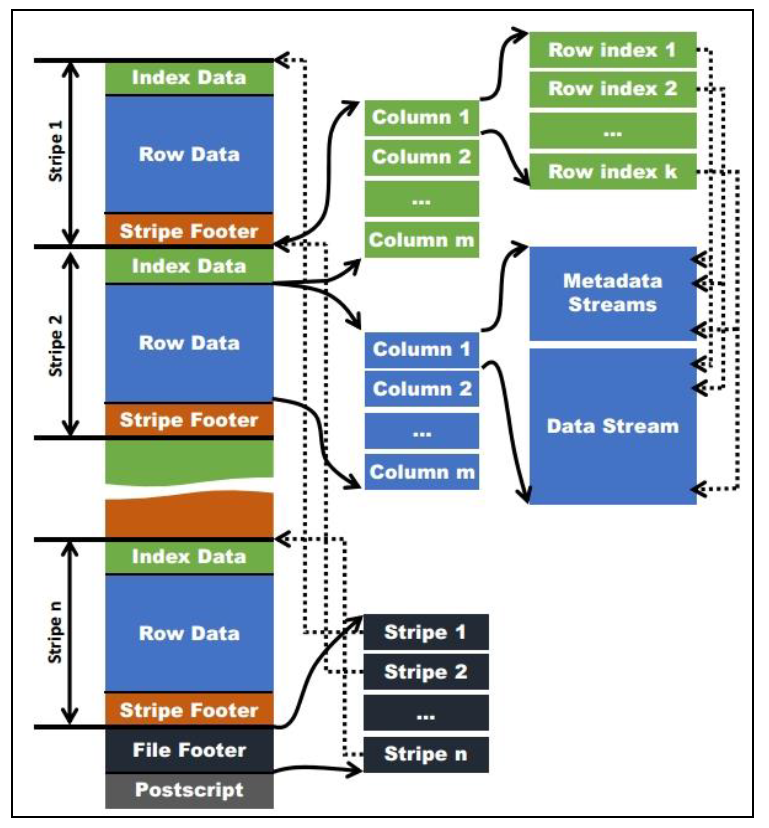
(1)Index Data :一个轻量级的 index ,默认是 每隔 1W 行做一个索引 。这里做的索引应该只是记录某行的各字段在 Row Data 中的 offset 。
(2)Row Data :存的是具体的数据,先取部分行,然后对这些行按列进行存储 。 对每个列进行了编码,分成多个 Stream 来存储 。
(3)Stripe Footer :存的是各个 Stream 的类型,长度等信息。
每个文件有一个 File Footer ,这里面存的是每个 Stripe 的行数,每个 Column 的数据类型信息等;每个文件的尾部是一个 PostScript ,这里面记录了整个文件的压缩类型以及 FileFooter 的长度信息等。在读取文件时,会 seek 到文件尾部读 PostScript ,从里面解析到 File Footer 长度,再读 FileFooter ,从里面解析到各个 Stripe 信息,再读各个 Stripe ,即从后往前读。
4. Parquet格式
Parquet 文件是以二进制方式存储的,所以是不可以直接读取的,文件中包括该文件的数据和元数据, 因此 Parquet 格式文件是自解析的。
(1)行组 (Row Group):每一个行组包含一定的行数,在一个 HDFS 文件中至少存储一个行组 ,类似于 orc 的 stripe 的概念。
(2)列块 (Column Chunk):在一个行组中每一列保存在一个列块中,行组中的所有列连续的存储在这个行组文件中。一个列块中的值都是相同类型的,不同的列块可能使用不同的算法进行压缩。
(3)页 ( Page):每一个列块划分为多个页,一个页是最小的编码的单位,在同一个列块的不同页可能使用不同的编码方式。
通常情况下,在存储 Parquet 数据的时候会按照 Block 大小设置行组的大小,由于一般情况下每一个 Mapper 任务处理数据的最小单位是一个 Block ,这样可以把 每一个行组由一个 Mapper 任务处理,增大任务执行并行度 。 Parquet 文件的格式:
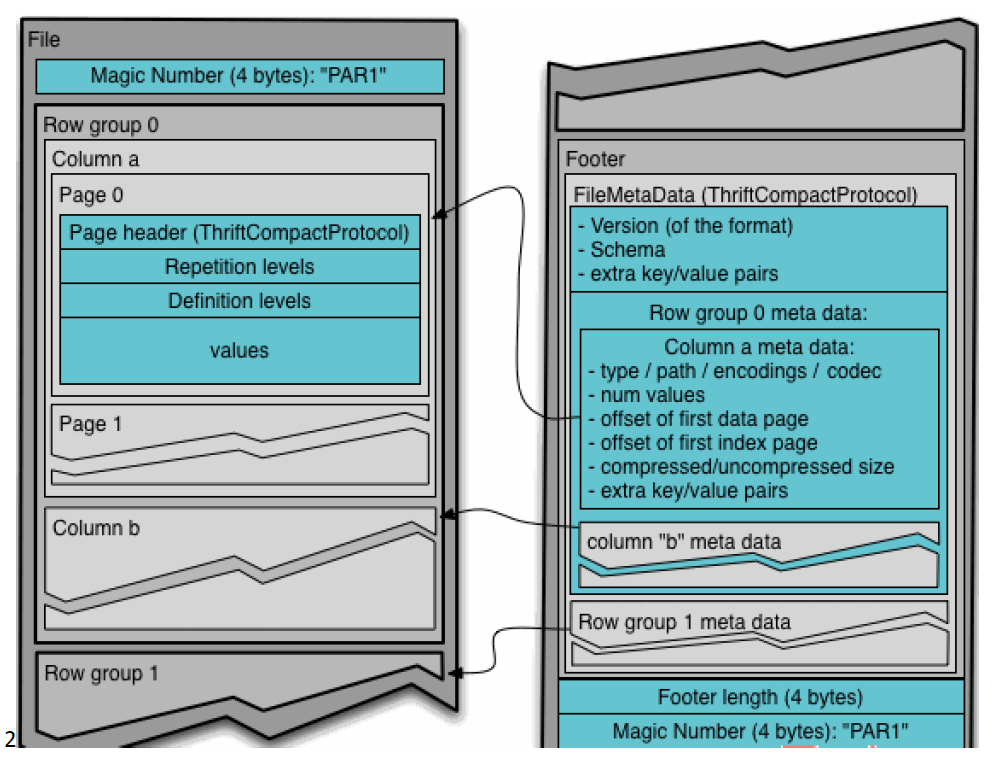
上图展示了一个 Parquet 文件的内容,一个文件中可以存储多个行组,文件的首位都是该文件的 Magic Code ,用于校验它是否是一个 Parquet 文件, Footer length 记录了文件元数据的大小,通过该值和文件长度可以计算出元数据的偏移量,文件的元数据中包括每一个行组的元数据信息和该文件存储数据的Schema 信息。除了文件中每一个行组的元数据,每一页的开始都会存储该页的元数据,在Parquet 中,有三种类型的页:数据页、字典页和索引页。数据页用于存储当前行组中该列的值,字典页存储该列值的编码字典,每一个列块中最多包含一个字典页,索引页用来存储当前行组下该列的索引,目前Parquet 中还不支持索引页。
5. 主流文件存储格式对比实验
从存储文件的压缩比和查询速度两个角度对比。
存储文件的压缩比测试:
(1)TextFile,首先创建表,指定存储格式,然后加载数据,最后查看表中数据大小
hive (default)> create table log_text(
> track_time string,
> url string,
> session_id string,
> referer string,
> ip string,
> end_user_id string,
> city_id string
> )
> row format delimited fields terminated by "\t"
> stored as textfile;
OK
Time taken: 0.241 seconds
hive (default)> load data local inpath '/opt/module/hive-3.1.2/data/log.data' into table log_text;
Loading data to table default.log_text
OK
Time taken: 2.62 seconds
hive (default)> dfs -du -h /user/hive/warehouse/log_text;
18.1 M 54.4 M /user/hive/warehouse/log_text/log.data
(2)Orc(设置 orc 存储不使用压缩)
hive (default)> create table log_orc(
> track_time string,
> url string,
> session_id string,
> referer string,
> ip string,
> end_user_id string,
> city_id string
> )
> row format delimited fields terminated by '\t'
> stored as orc
> tblproperties("orc.compress"="NONE");
OK
Time taken: 0.149 seconds
hive (default)> insert into table log_orc select * from log_text;
hive (default)> dfs -du -h /user/hive/warehouse/log_orc/;
7.7 M 23.1 M /user/hive/warehouse/log_orc/000000_0
(3)Parquet
hive (default)> create table log_parquet(
> track_time string,
> url string,
> session_id string,
> referer string,
> ip string,
> end_user_id string,
> city_id string
> )
> row format delimited fields terminated by '\t'
> stored as parquet;
OK
Time taken: 0.164 seconds
hive (default)> insert into table log_parquet select * from log_text;
hive (default)> dfs -du -h /user/hive/warehouse/log_parquet/;
13.1 M 39.3 M /user/hive/warehouse/log_parquet/000000_0
存储文件的对比总结:ORC > Parquet > textFile
存储文件的查询速度测试:
(1)TextFile
hive (default)> insert overwrite local directory '/opt/module/hive-3.1.2/data/log_text' select substring(url,1,4) from log_text;
OK
_c0
Time taken: 18.312 seconds
(2)Orc
hive (default)> insert overwrite local directory '/opt/module/hive-3.1.2/data/log_orc' select substring(url,1,4) from log_orc;
OK
_c0
Time taken: 10.412 seconds
(3)Parquet
hive (default)> insert overwrite local directory '/opt/module/hive-3.1.2/data/log_parquet' select substring(url,1,4) from log_parquet;
OK
_c0
Time taken: 9.799 seconds
存储文件的查询速度总结:查询速度相近。
2.5 存储和压缩结合
官网:https://cwiki.apache.org/confluence/display/Hive/LanguageManual+ORC
ORC存储方式的压缩:
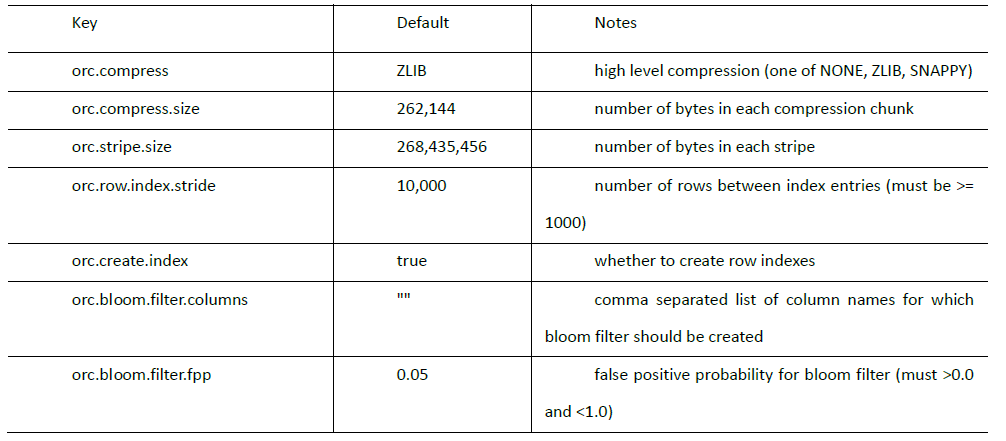
注意:所有关于ORCFile 的参数都是在 HQL 语句的 TBLPROPERTIES 字段里面出现
1. 创建一个 ZLIB 压缩的 ORC 存储方式
(1)建表语句
hive (default)> create table log_orc_zlib(
> track_time string,
> url string,
> session_id string,
> referer string,
> ip string,
> end_user_id string,
> city_id string
> )
> row format delimited fields terminated by '\t'
> stored as orc
> tblproperties("orc.compress"="ZLIB");
OK
Time taken: 0.118 seconds
(2)插入数据
hive (default)> insert into log_orc_zlib select * from log_text;
(3)查看插入后数据
hive (default)> dfs -du -h /user/hive/warehouse/log_orc_zlib/;
2.8 M 8.3 M /user/hive/warehouse/log_orc_zlib/000000_0
2. 创建一个 SNAPPY 压缩的 ORC 存储方式
(1)建表语句
hive (default)> create table log_orc_snappy(
> track_time string,
> url string,
> session_id string,
> referer string,
> ip string,
> end_user_id string,
> city_id string
> )
> row format delimited fields terminated by '\t'
> stored as orc
> tblproperties("orc.compress"="SNAPPY");
OK
Time taken: 0.138 seconds
(2)插入数据
hive (default)> insert into log_orc_snappy select * from log_text;
(3)查看插入后数据
hive (default)> dfs -du -h /user/hive/warehouse/log_orc_snappy/;
3.7 M 11.2 M /user/hive/warehouse/log_orc_snappy/000000_0
ZLIB比 Snappy压缩的还小。原因是 ZLIB采用的是 deflate压缩算法 。比 snappy压缩的压缩率高。
3. 创建一个 SNAPPY 压缩的 parquet 存储方式
(1)建表语句
hive (default)> create table log_parquet_snappy(
> track_time string,
> url string,
> session_id string,
> referer string,
> ip string,
> end_user_id string,
> city_id string
> )
> row format delimited fields terminated by '\t'
> stored as parquet
> tblproperties("parquet.compression"="snappy");
OK
Time taken: 0.972 seconds
(2)插入数据
hive (default)> insert into log_parquet_snappy select * from log_text;
(3)查看插入后数据
hive (default)> dfs -du -h /user/hive/warehouse/log_parquet_snappy/;
6.4 M 19.2 M /user/hive/warehouse/log_parquet_snappy/000000_0
4. 存储方式和压缩总结
在实际的项目开发当中,hive 表的数据存储格式一般选择 orc 或 parquet 。压缩方式一般选择 snappy 或 lzo 。
参考:
https://www.bilibili.com/video/BV1EZ4y1G7iL?spm_id_from=333.788.b_636f6d6d656e74.11