使用背景:
多GPU情况下选择指定部分GPU使用
很多服务器在进行配备时会装配多块GPU,那么我们在使用服务器时,有时可能会多个终端对服务器进行操控,因此有时需要对特定的GPU进行指定操作,才不会使用户之间使用GPU时相互影响;或者需要指定特定数量的GPU才能达到训练效果。
操作步骤:
1、首先在终端输入nvidia-smi查看我们的主机有几块GPU,并查看工作状态:
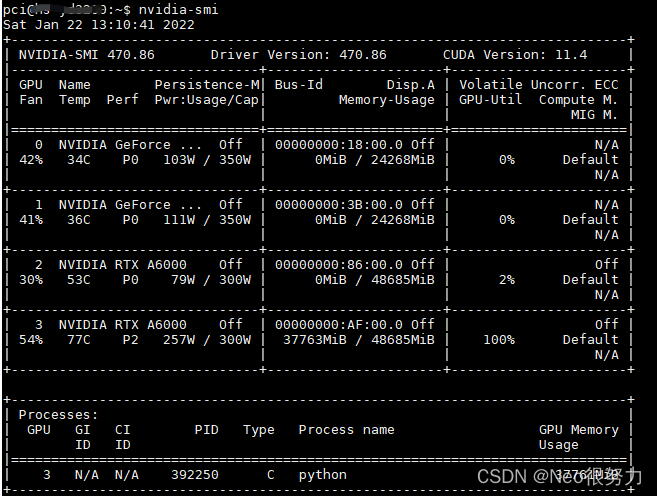
如上图所示,我们的主机中一共有4块GPU,其中第4块GPU(3号GPU)已经有人在满载运行当中,如果这时我们如果四块默认同时运行的话可能会提示out of memory报错,或者提示显卡不平衡imblance的warning警告。
注意!注意!注意!
有时候通过nvidia-smi查看的显卡标号可能会和实际显卡标号不一样!
因此我们可以print一下显卡的真实标号:
a = torch.cuda.get_device_name(0) # 返回GPU名字
print("a is ",a)
b = torch.cuda.get_device_name(1)
print("b is ", b)
c = torch.cuda.get_device_name(2)
print("c is ", c)
d = torch.cuda.get_device_name(3)
print("d is ", d)

如上图所示,我们真实的GPU标号其实和通过nvidia-smi查看的显卡标号不一样,因此我们需要对真实的GPU标号进行操作。
所以这时我们需要选择部分GPU进行使用,譬如在这里我们选择nvidia-smi查看的0号GPU和1号GPU进行使用,那我们需要在我们的网络开始训练前加入如下一行代码:
(注:放在网络net开始训练的代码之前即可)
os.environ["CUDA_VISIBLE_DEVICES"] = ','.join(map(str, [2,3]))
该行代码的意思是只选择指定标号GPU进行使用,执行完该行代码之后python环境无法检测到指定GPU之外的其他GPU。
最后我们只需要执行训练文件就可以对其中指定的两块GPU进行使用了!
############如果各位同学觉得有帮助还请点个赞支持下哈################